我是靠谱客的博主 烂漫黑夜,这篇文章主要介绍【APScheduler + scrapy定时爬虫】ValueError: signal only works in main thread,现在分享给大家,希望可以做个参考。
之前一直用shell写的crontab来跑爬虫脚本
最近换了apscheduler来管理定时任务
代码大概是这个样子
import sys, os
from scrapy.cmdline import execute
from apscheduler.schedulers.blocking import BlockingScheduler
def start_scrapy():
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute(['scrapy', 'crawl', 'spider_name'])
sched.add_job(start_scrapy, 'interval', seconds=10)
sched.start()
结果signal报错了:
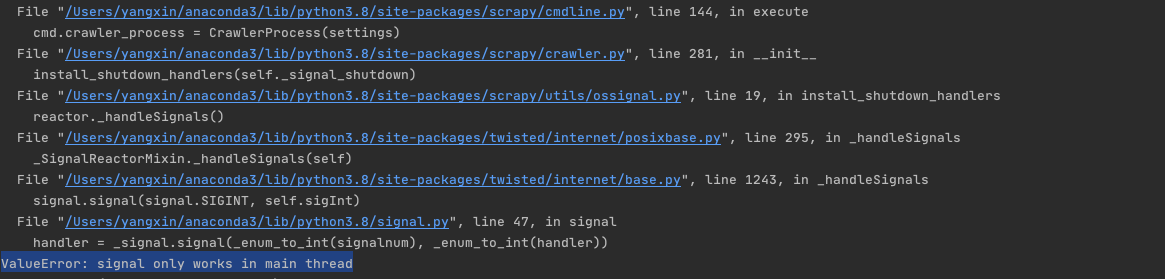
百度了很久也没找到这个错怎么搞
后来发现了一个帖子pyinstaller,scrapy和apscheduler

于是改用subprocess执行scrapy脚本
import sys, os
# from scrapy.cmdline import execute
import subprocess
from apscheduler.schedulers.blocking import BlockingScheduler
def start_scrapy():
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
# execute(['scrapy', 'crawl', 'spider_name'])
subprocess.Popen('scrapy crawl spider_name')
sched.add_job(start_scrapy, 'interval', seconds=10)
sched.start()
结果报错:
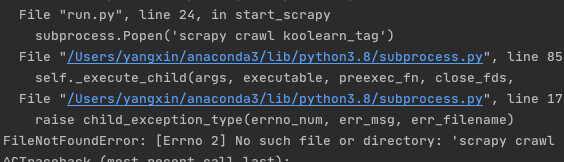
原因是没有加上shell=True这个参数,加上之后运行成功
import sys, os
import subprocess
from apscheduler.schedulers.blocking import BlockingScheduler
def start_scrapy():
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
subprocess.Popen('scrapy crawl spider_name', shell=True)
# 或者用run方法也行,Popen有安全隐患
#subprocess.run(['scrapy', 'crawl', 'spider_name'])
sched.add_job(start_scrapy, 'interval', seconds=10)
sched.start()
最后
以上就是烂漫黑夜最近收集整理的关于【APScheduler + scrapy定时爬虫】ValueError: signal only works in main thread的全部内容,更多相关【APScheduler内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复