人工智能
第五章 车辆评级分类与cart分类树
一、决策树分类
1. 算法核心原理
- 决策树的核心思想:相似的输入产生相似的输出。
2. 决策树的关键问题
- 这么多特征,使用哪个特征先进行子表划分?
3. CART 分类树
- CART 分类树算法对每个特征进行二分,寻找分割点时使用基尼系数来表达数据集的不纯度,基尼系数越小,不纯度越低,数据集划分的效果越好。
- CART 分类树划分子表的过程:
- 针对每个特征,基于基尼系数计算最优分割值。在计算出来的各个特征的每个分割值对数据集 D D D的基尼系数中,选择基尼系数最小的特征A和对应的分割值a。根据这个最优特征和最优分割值,把数据集划分成两部分 D 1 D_1 D1和 D 2 D_2 D2,同时建立当前节点的左右节点,左节点的数据集 D D D为 D 1 D_1 D1,右节点的数据集 D D D为 D 2 D_2 D2.对左右节点的子节点递归调用这个过程,生成决策树。
- 而 CART 分类树也基于基尼系数来决定子表划分所选特征的次序。
4. 基尼系数
- 对于样本D,个数为|D|,假设K个类别,第k个类别的数量为
C
k
C_k
Ck,则样本D的基尼系数表达式:
G i n i ( D ) = 1 − ∑ i = 1 K ( ∣ C k ∣ ∣ D ∣ ) 2 Gini(D) = 1 - sum_{i=1}^K left(frac{|C_k|}{|D|}right)^2 Gini(D)=1−i=1∑K(∣D∣∣Ck∣)2 - 有100个样本(
D
1
D_1
D1)包含A与B两个类别,数量分别为40与60,Gini(
D
1
D_1
D1) = ?
1 − ( ( ∣ 40 ∣ ∣ 100 ∣ ) 2 + ( ∣ 60 ∣ ∣ 100 ∣ ) 2 ) = 1 − ( 0.16 + 0.36 ) = 0.48 1 - left( left(frac{|40|}{|100|}right)^2 + left( frac{|60|}{|100|}right)^2 right) = 1 - (0.16 + 0.36) = 0.48 1−((∣100∣∣40∣)2+(∣100∣∣60∣)2)=1−(0.16+0.36)=0.48 - 有100个样本(
D
2
D_2
D2)包含A与B两个类别,数量分别为10与90,Gini(
D
2
D_2
D2) = ?
1 − ( ( ∣ 10 ∣ ∣ 100 ∣ ) 2 + ( ∣ 90 ∣ ∣ 100 ∣ ) 2 ) = 1 − ( 0.01 + 0.81 ) = 0.18 1 - left( left( frac{|10|}{|100|}right)^2 + left( frac{|90|}{|100|}right)^2 right) = 1 - (0.01 + 0.81) = 0.18 1−((∣100∣∣10∣)2+(∣100∣∣90∣)2)=1−(0.01+0.81)=0.18 - 对于样本D,个数为|D|,根据特征A的某个值a,把D分成
D
1
D_1
D1和
D
2
D_2
D2,则在特征A的条件下,样本D的基尼系数表达式为:
G i n i ( D , A ) = ∣ D 1 ∣ ∣ D ∣ G i n i ( D 1 ) + ∣ D 2 ∣ ∣ D ∣ G i n i ( D 2 ) Gini(D,A) = frac{|D_1|}{|D|} Gini(D_1) + frac{|D_2|}{|D|} Gini(D_2) Gini(D,A)=∣D∣∣D1∣Gini(D1)+∣D∣∣D2∣Gini(D2)
5. 决策树的生成过程
- 算法输入训练集D,基尼系数的阈值,样本个数阈值。输出决策树T。
- 对于当前节点的数据集为D,如果样本个数小于阈值,则返回决策子树,当前节点停止递归。
- 计算样本集D的基尼系数,如果基尼系数小于阈值,则返回决策树子树,当前节点停止递归。
- 计算当前节点现有的各个特征的各个特征值对数据集D的基尼系数。
- 在计算出来的各个特征的各个特征值对数据集D的基尼系数中,选择基尼系数最小的特征A和对应的特征值a。根据这个最优特征和最优特征值,把数据集划分成两部分 D 1 D_1 D1和 D 2 D_2 D2,同时建立当前节点的左右节点,左节点的数据集D为 D 1 D_1 D1,右节点的数据集D为 D 2 D_2 D2。
- 对左右的子节点递归的调用1-4步,生成决策树。
- 预测过程:对生成的决策树做预测的时候,假如测试集里的样本A落到了某个叶子节点,而节点里有多个训练样本。则对于A的类别预测采用的是这个叶子节点里概率最大的类别。
6. 决策树分类实现
- 决策树分类器模型相关 API:
import sklearn.tree as st
# 决策树分类器
model = st.DecisionTreeClassifier(
max_depth=6, min_samples_split=3, random_state=7)
model.fit(train_x, train_y)
7. 鸢尾花案例
import sklearn.tree as st
model = st.DecisionTreeClassifier(max_depth=4, min_samples_split=3)
model.fit(train_x, train_y)
# 评估 模型准确率
pred_test_y = model.predict(test_x)
print((pred_test_y==test_y).sum() / test_y.size)
print(test_y.values)
"""
0.8666666666666667
[2 0 0 1 0 2 2 2 1 1 2 1 1 0 0]
"""
8. 集合模型分类实现
- 集合模型提供的常用分类器
import sklearn.ensemble as se
model = se.RandomForestClassifier(...) # 随机森林分类器
model = se.AdaBoostClassifier(...) # AdaBoost分类器
model = se.GridientBoostingClassifier(...) # GBDT分类器
二、预测小汽车等级
- car.txt 样本文件中统计了小汽车的常见特征信息及小汽车的分类,使用这些数据基于决策树分类算法训练模型预测小汽车等级。
- 汽车价格 维修费用 车门数量 载客数 后备箱 安全性 汽车级别
- 分析实现思路:
- 加载数据。
- 特征分析与特征工程。
- 数据预处理(标签编码)。
- 训练模型。
- 模型测试。
import numpy as np
import pandas as pd
data = pd.read_csv('car.txt', header=None) # 不想把第一行当做表头
data.head()

data[0].value_counts() # 汽车价格分成4类,按类别划分每个类别有432个样本
"""
vhigh
432
low
432
med
432
high
432
Name: 0, dtype: int64
"""
- 确定:是分类问题,还是回归问题?答:分类
- 选哪一个分类模型:逻辑回归、决策树、RF、GBDT、AdaBoost?答:RF(当然也可以尝试其他模型)
# 针对当前这组数据完成标签编码预处理
import sklearn.preprocessing as sp
# 遍历每一列数据
train_data = pd.DataFrame([])
encoders = {}
for col_ind, col_val in data.items():
encoder = sp.LabelEncoder()
train_data[col_ind] = encoder.fit_transform(col_val)
encoders[col_ind] = encoder
train_data

# 整理输入集与输出集
x, y = train_data.iloc[:, :-1], train_data[6]
x.shape, y.shape
"""
((1728, 6), (1728,))
"""
# 创建分类模型
model = se.RandomForestClassifier(max_depth=6, n_estimators=400, random_state=7)
# 做5次交叉验证,验证一下这个模型是否可用
scores = ms.cross_val_score(model, x, y, cv=5, scoring='f1_weighted')
# 如果分数还可以,再正儿八经的训练模型
print(scores.mean())
"""
0.7537201013972693
"""
# 模型评估(先用训练样本进行模型评估)
model.fit(x, y)
pred_y = model.predict(x)
print(sm.classification_report(y, pred_y))
print(sm.confusion_matrix(y,pred_y)) # 把1类别的全归到0类别里了
"""
precision
recall
f1-score
support
0
0.77
0.82
0.79
384
1
0.00
0.00
0.00
69
2
0.95
0.99
0.97
1210
3
1.00
0.77
0.87
65
accuracy
0.91
1728
macro avg
0.68
0.65
0.66
1728
weighted avg
0.87
0.91
0.89
1728
[[ 315
0
69
0]
[
69
0
0
0]
[
11
0 1199
0]
[
15
0
0
50]]
"""
data = [
['high', 'med', '5more', '4', 'big', 'low', 'unacc'],
['high', 'high', '4', '4', 'med', 'med', 'acc'],
['low', 'low', '2', '4', 'small', 'high', 'good'],
['low', 'med', '3', '4', 'med', 'high', 'vgood']
]
test_data = pd.DataFrame(data)
for col_ind, col_val in test_data.items():
encoder = encoders[col_ind]
encoded_col = encoder.transform(col_val)
test_data[col_ind] = encoded_col
# 整理输入集与输出集
test_x, test_y = test_data.iloc[:,:-1], test_data[6]
pred_test_y = model.predict(test_x)
pred_test_y
"""
array([2, 0, 0, 0])
"""
encoders[6].inverse_transform(pred_test_y)
"""
array(['unacc', 'acc', 'acc', 'acc'], dtype=object)
"""
三、验证曲线与学习曲线
1. 验证曲线
- 验证曲线描述的关系即是模型性能关于模型超参数的函数关系:
- 模型性能 = f(超参数)
2. 验证曲线实现
- sklearn 提供的验证曲线 API:
train_scores, test_scores = ms.validation_curve(
model,
# 模型
输入集, 输出集,
'n_estimators',
# 超参数名
np.arange(50, 550, 50), # 超参数序列
cv=5 # 折叠数
)
- 返回train_scores与test_scores为每个超参数取值下的每次交叉验证结果组成的得分矩阵。
3. 案例:预测小汽车等级调整参数
import numpy as np
import pandas as pd
data = pd.read_csv('car.txt', header=None) # 不想把第一行当做表头
# 针对当前这组数据完成标签编码预处理
import sklearn.preprocessing as sp
import sklearn.ensemble as se
import sklearn.model_selection as ms
import sklearn.metrics as sm
# 遍历每一列数据
train_data = pd.DataFrame([])
encoders = {}
for col_ind, col_val in data.items():
encoder = sp.LabelEncoder()
train_data[col_ind] = encoder.fit_transform(col_val)
encoders[col_ind] = encoder
# 整理输入集与输出集
x, y = train_data.iloc[:, :-1], train_data[6]
# 创建分类模型(调参之后设定的参数值)
model = se.RandomForestClassifier(max_depth=9, n_estimators=140, random_state=7)
# 验证曲线,选取最优超参数
import matplotlib.pyplot as plt
# params =
np.arange(50, 550, 50)
params = np.arange(100, 200, 10)
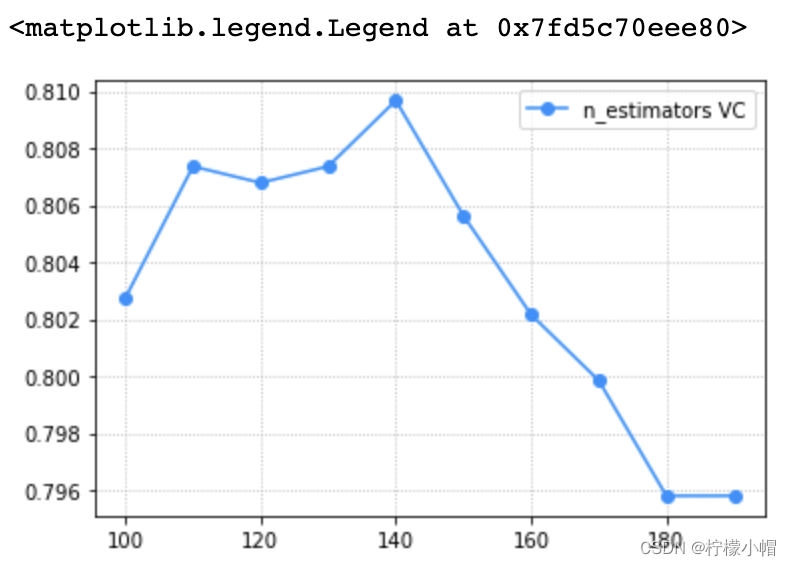
train_scores, test_scores = ms.validation_curve(model, x, y, param_name='n_estimators', param_range=params, cv=5)
scores = test_scores.mean(axis=1)
# 验证曲线可视化
plt.grid(linestyle=':')
plt.plot(params, scores, 'o-', color='dodgerblue', label='n_estimators VC')
plt.legend()
# 调整max_depth
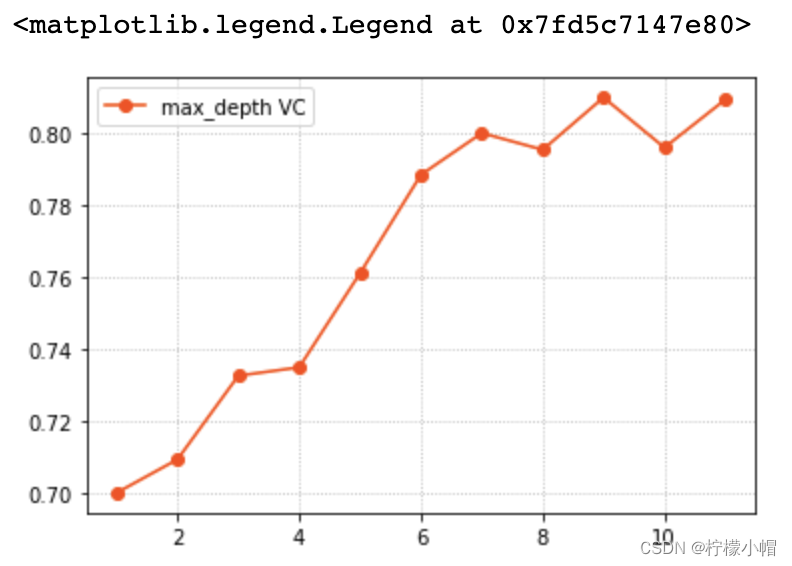
params = np.arange(1, 12)
train_scores, test_scores = ms.validation_curve(model, x, y, param_name='max_depth', param_range=params, cv=5)
scores = test_scores.mean(axis=1)
# 验证曲线可视化
plt.grid(linestyle=':')
plt.plot(params, scores, 'o-', color='orangered', label='max_depth VC')
plt.legend()
model.fit(x, y)
pred_y = model.predict(x)
print(sm.classification_report(y, pred_y))
print(sm.confusion_matrix(y,pred_y))
"""
precision
recall
f1-score
support
0
0.96
1.00
0.98
384
1
1.00
0.75
0.86
69
2
1.00
1.00
1.00
1210
3
0.94
1.00
0.97
65
accuracy
0.99
1728
macro avg
0.97
0.94
0.95
1728
weighted avg
0.99
0.99
0.99
1728
[[ 383
0
0
1]
[
14
52
0
3]
[
3
0 1207
0]
[
0
0
0
65]]
"""
data = [
['high', 'med', '5more', '4', 'big', 'low', 'unacc'],
['high', 'high', '4', '4', 'med', 'med', 'acc'],
['low', 'low', '2', '4', 'small', 'high', 'good'],
['low', 'med', '3', '4', 'med', 'high', 'vgood']
]
test_data = pd.DataFrame(data)
for col_ind, col_val in test_data.items():
encoder = encoders[col_ind]
encoded_col = encoder.transform(col_val)
test_data[col_ind] = encoded_col
# 整理输入集与输出集
test_x, test_y = test_data.iloc[:,:-1], test_data[6]
pred_test_y = model.predict(test_x)
encoders[6].inverse_transform(pred_test_y)
"""
array(['unacc', 'acc', 'good', 'vgood'], dtype=object)
"""
4. 学习曲线
- 学习曲线描述的关系即是模型性能关于训练样本量大小的函数关系:
- 模型性能 = f(训练集大小)
5. 学习曲线实现
- sklearn 提供的学习曲线 API:
train_scores, test_scores = ms.learning_curve(
model,
# 模型
输入集, 输出集,
train_sizes=[0.9, 0.8, 0.7], # 训练集大小序列
cv=5 # 折叠数
)
- 返回train_scores与test_scores为每个超参数取值下的每次交叉验证结果组成的得分矩阵。
6. 案例:预测小汽车等级调整参数
params = np.arange(0.1, 1.1, 0.1)
_, train_scores, test_scores = ms.learning_curve(model, x, y, train_sizes=params, cv=5)
scores = test_scores.mean(axis = 1)
# 学习曲线可视化
plt.grid(linestyle=':')
plt.plot(params, scores, 'o-', color='green', label='Learning Curve')
plt.legend()

四、完整案例
import numpy as np
import pandas as pd
data = pd.read_csv('car.txt', header=None) # 不想把第一行当做表头
data.head()
"""
0
1
2 3 4
5
6
0 vhigh vhigh 2 2 small low
unacc
1 vhigh vhigh 2 2 small med
unacc
2 vhigh vhigh 2 2 small high unacc
3 vhigh vhigh 2 2 med
low
unacc
4 vhigh vhigh 2 2 med
med
unacc
"""
# 确定:是分类问题,还是回归问题? 分类
#
选哪一个分类模型:逻辑回归、决策树、RF、GBDT、AdaBoost? RF
# 针对当前这组数据完成标签编码预处理
import sklearn.preprocessing as sp
import sklearn.ensemble as se
import sklearn.model_selection as ms
import sklearn.metrics as sm
# 遍历每一列数据
train_data = pd.DataFrame([])
encoders = {}
for col_ind, col_val in data.items():
encoder = sp.LabelEncoder()
train_data[col_ind] = encoder.fit_transform(col_val)
encoders[col_ind] = encoder
# 整理输入集与输出集
x, y = train_data.iloc[:, :-1], train_data[6]
# 创建分类模型
model = se.RandomForestClassifier(max_depth=9, n_estimators=140, random_state=7)
# 验证曲线,选取最优超参数
import matplotlib.pyplot as plt
# params =
np.arange(50, 550, 50)
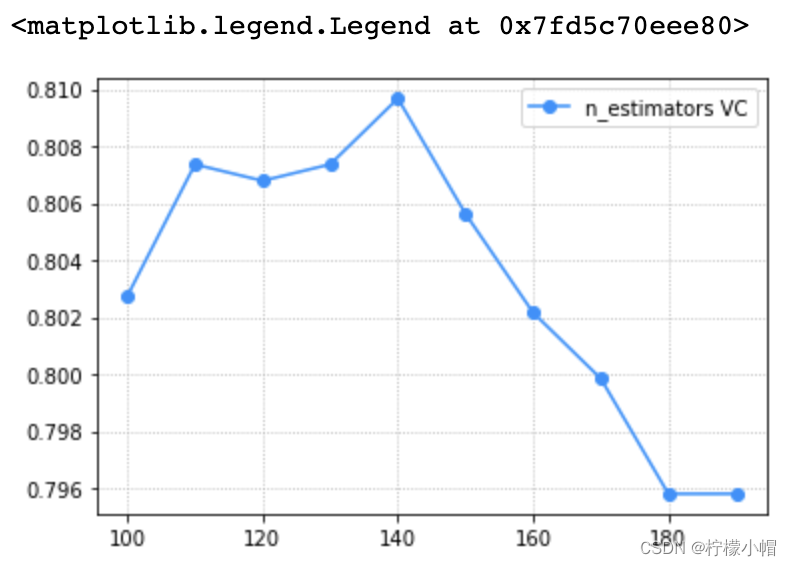
params = np.arange(100, 200, 10)
train_scores, test_scores = ms.validation_curve(model, x, y, param_name='n_estimators', param_range=params, cv=5)
scores = test_scores.mean(axis=1)
# 验证曲线可视化
plt.grid(linestyle=':')
plt.plot(params, scores, 'o-', color='dodgerblue', label='n_estimators VC')
plt.legend()
# 调整max_depth
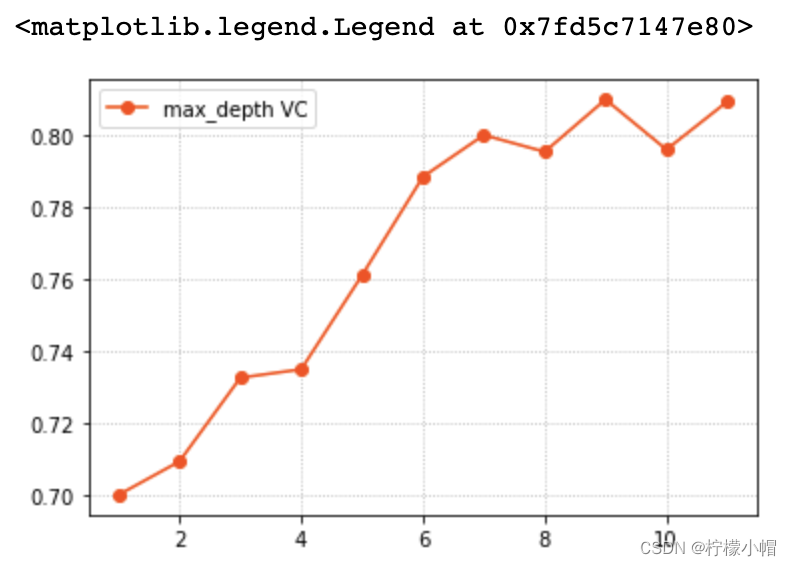
params = np.arange(1, 12)
train_scores, test_scores = ms.validation_curve(model, x, y, param_name='max_depth', param_range=params, cv=5)
scores = test_scores.mean(axis=1)
# 验证曲线可视化
plt.grid(linestyle=':')
plt.plot(params, scores, 'o-', color='orangered', label='max_depth VC')
plt.legend()
# 学习曲线,选取最优训练集大小
params = np.arange(0.1, 1.1, 0.1)
_, train_scores, test_scores = ms.learning_curve(model, x, y, train_sizes=params, cv=5)
scores = test_scores.mean(axis = 1)
# 学习曲线可视化
plt.grid(linestyle=':')
plt.plot(params, scores, 'o-', color='green', label='Learning Curve')
plt.legend()

# 模型评估(先用训练样本进行模型评估)
model.fit(x, y)
pred_y = model.predict(x)
print(sm.classification_report(y, pred_y))
print(sm.confusion_matrix(y,pred_y)) # 把1类别的全归到0类别里了
"""
precision
recall
f1-score
support
0
0.96
1.00
0.98
384
1
1.00
0.75
0.86
69
2
1.00
1.00
1.00
1210
3
0.94
1.00
0.97
65
accuracy
0.99
1728
macro avg
0.97
0.94
0.95
1728
weighted avg
0.99
0.99
0.99
1728
[[ 383
0
0
1]
[
14
52
0
3]
[
3
0 1207
0]
[
0
0
0
65]]
"""
data = [
['high', 'med', '5more', '4', 'big', 'low', 'unacc'],
['high', 'high', '4', '4', 'med', 'med', 'acc'],
['low', 'low', '2', '4', 'small', 'high', 'good'],
['low', 'med', '3', '4', 'med', 'high', 'vgood']
]
test_data = pd.DataFrame(data)
for col_ind, col_val in test_data.items():
encoder = encoders[col_ind]
encoded_col = encoder.transform(col_val)
test_data[col_ind] = encoded_col
# 整理输入集与输出集
test_x, test_y = test_data.iloc[:,:-1], test_data[6]
pred_test_y = model.predict(test_x)
encoders[6].inverse_transform(pred_test_y)
"""
array(['unacc', 'acc', 'good', 'vgood'], dtype=object)
"""
最后
以上就是调皮镜子最近收集整理的关于【Python人工智能】Python全栈体系(十七)人工智能的全部内容,更多相关【Python人工智能】Python全栈体系(十七)人工智能内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复