1、编译器对OpenMP的支持
目前支持OpenMP的C/C++编译器主要有微软的VC和Intel的C/C++编译器。
在微软的VC8.0中,要将项目的属性对话框中“配置属性”下的“C/C++”下的“语言”页里,将“OpenMP支持”由否改为“是/(openmp)”即可。
2、OpenMP指令和库函数介绍
前面提到的parallel for就是一条指令,有些书中也将OpenMP的“指令”叫做“编译指导语句”,后面的子句是可选的。例如:
#pragma omp parallel private(i, j)
parallel 就是指令, private是子句。为叙述方便把包含#pragma和OpenMP指令的一行叫做语句,如上面那行叫parallel语句。
OpenMP的指令有以下一些:
parallel,用在一个代码段之前,表示这段代码将被多个线程并行执行
for,用于for循环之前,将循环分配到多个线程中并行执行,必须保证每次循环之间无相关性。
parallel for, parallel 和 for语句的结合,也是用在一个for循环之前,表示for循环的代码将被多个线程并行执行。
sections,用在可能会被并行执行的代码段之前
parallel sections,parallel和sections两个语句的结合
critical,用在一段代码临界区之前
single,用在一段只被单个线程执行的代码段之前,表示后面的代码段将被单线程执行。
flush, 用来保证线程的内存临时视图和实际内存保持一致,即各个线程看到的共享变量是一致的
barrier,用于并行区内代码的线程同步,所有线程执行到barrier时要停止,直到所有线程都执行到barrier时才继续往下执行。
atomic,用于指定一块内存区域被制动更新
master,用于指定一段代码块由主线程执行
ordered, 用于指定并行区域的循环按顺序执行
threadprivate, 用于指定一个变量是线程私有的。
OpenMP除上述指令外,还有一些库函数,OpenMP运行时库函数原本用以设置和获取执行环境相关的信息.其也包含一系列用以同步的API.要使用运行时函数库所包含的函数,应该在相应的源文件中包含OpenMP头文件omp.h.OpenMP的运行时库函数的使用类似于相应编程语言内部的函数调用.
由编译指导语句和运行时库函数可见,OpenMP同时结合了两种并行编程的方式,通过编译指导语句,可以将串行的程序逐步地改造成一个并行程序,达到增量更新程序的目的,从而减少程序编写人员的一定负担。同时,这样的方式也能将串行程序和并行程序保存在同一个源代码文件当中,减少了维护的负.OpenMP在运行的时候,需要运行函数库的支持,并会获取一些环境变量来控制运行的过程。环境变量是动态函数库中用来控制函数运行的一些参数.
下面列出几个常用的库函数:
omp_get_num_procs, 返回运行本线程的多处理机的处理器个数。
omp_get_num_threads, 返回当前并行区域中的活动线程个数。
omp_get_thread_num, 返回线程号
omp_set_num_threads, 设置并行执行代码时的线程个数
omp_init_lock, 初始化一个简单锁
omp_set_lock, 上锁操作
omp_unset_lock, 解锁操作,要和omp_set_lock函数配对使用。
omp_destroy_lock, omp_init_lock函数的配对操作函数,关闭一个锁
OpenMP的子句有以下一些
private, 指定每个线程都有它自己的变量私有副本。
firstprivate,指定每个线程都有它自己的变量私有副本,并且变量要被继承主线程中的初值。
lastprivate,主要是用来指定将线程中的私有变量的值在并行处理结束后复制回主线程中的对应变量。
reduce,用来指定一个或多个变量是私有的,并且在并行处理结束后这些变量要执行指定的运算。
nowait,忽略指定中暗含的等待
num_threads,指定线程的个数
schedule,指定如何调度for循环迭代
shared,指定一个或多个变量为多个线程间的共享变量
ordered,用来指定for循环的执行要按顺序执行
copyprivate,用于single指令中的指定变量为多个线程的共享变量
copyin,用来指定一个threadprivate的变量的值要用主线程的值进行初始化。
default,用来指定并行处理区域内的变量的使用方式,缺省是shared
3、 parallel 指令的用法
parallel 是用来构造一个并行块的,也可以使用其他指令如for、sections等和它配合使用。
在C/C++中,parallel的使用方法如下:
#pragma omp parallel [for | sections] [子句[子句]…]
{
//代码
}parallel语句后面要跟一个大括号对将要并行执行的代码括起来。
void main(int argc, char *argv[]) {
#pragma omp parallel
{
printf(“Hello, World!n”);
}
}执行以上代码将会打印出以下结果
Hello, World!
Hello, World!
Hello, World!
Hello, World!
可以看得出parallel语句中的代码被执行了四次,说明总共创建了4个线程去执行parallel语句中的代码。
也可以指定使用多少个线程来执行,需要使用num_threads子句:
void main(int argc, char *argv[]) {
#pragma omp parallel num_threads(8)
{
printf(“Hello, World!, ThreadId=%dn”, omp_get_thread_num() );
}
}执行以上代码,将会打印出以下结果:
Hello, World!, ThreadId = 2
Hello, World!, ThreadId = 6
Hello, World!, ThreadId = 4
Hello, World!, ThreadId = 0
Hello, World!, ThreadId = 5
Hello, World!, ThreadId = 7
Hello, World!, ThreadId = 1
Hello, World!, ThreadId = 3
从ThreadId的不同可以看出创建了8个线程来执行以上代码。所以parallel指令是用来为一段代码创建多个线程来执行它的。parallel块中的每行代码都被多个线程重复执行。
和传统的创建线程函数比起来,相当于为一个线程入口函数重复调用创建线程函数来创建线程并等待线程执行完。
4、使用并行思想计算三维点阵两两之间的距离之和
这里不再赘述openmp的进阶用法,但是可以直接从我的代码中学习写方法,建议在参照别人介绍的基础上进行学习
#include <iostream>
#include <omp.h>
#include <time.h>
#include <math.h>
#define maxs 30
clock_t start, end = 0;
struct pointsSquare
{
int x,y,z;
};
int check(int threadnum) {
if (threadnum < 1) {
std::cout << "输入违规请重新输入: ";
return 0;
}
else return 1;
}
bool ifformmer(int i, int j, int k, int l, int m, int n) {//将三个坐标看成个位十位百位来进行判断
if (i > m) return true;
else if (i < m) return false;
else if (j > n) return true;
else if (j < n) return false;
else if (k > l) return true;
else return false;
}
int main()
{
pointsSquare ps[maxs+1][maxs+1][maxs+1];//建立点阵,由于后面循环是从1开始需要多开一位
int threadnum;
double temp;
double sum[maxs];
int iAddThread[maxs];
//给每个点赋初值坐标
for (int i = 1; i <= maxs; i++) {
for (int j = 1; j <= maxs; j++) {
for(int k = 1;k <= maxs;k++){
ps[i][j][k].x = i;
ps[i][j][k].y = j;
ps[i][j][k].z = k;
}
}
}
std::cout << "输入要并行的线程数: ";
while (std::cin >> threadnum) {
if (!check(threadnum)) continue;//防止出现负数
start = clock();//开始计时
for (int i = 0; i < threadnum; i++) sum[i] = 0;
for (int i = 0; i < threadnum; i++) iAddThread[i] = 0;
omp_set_num_threads(threadnum);//根据输入的线程数设定并行的线程数
int tnum = threadnum;//不明原因threadnum在循环之后会失效
int iThread;
#pragma omp parallel private(iThread,temp)
{
for (int i = 1; i <= maxs; i++) {
for (int j = 1; j <= maxs; j++) {
for (int k = 1; k <= maxs; k++) {
//上面是外层坐标循环,下面是该点与其他点的循环
iThread = omp_get_thread_num(); //获取线程号
if (iAddThread[iThread] % threadnum == iThread) {
for (int m = 1; m <= maxs; m++) {
for (int n = 1; n <= maxs; n++) {
for (int l = 1; l <= maxs; l++) {
if (ifformmer(i, j, k, l, m, n)) { //ifformer将判断坐标点之间的唯一顺序,减少一半计算量,最后再翻倍
int d1 = (ps[i][j][k].x - ps[m][n][l].x)*(ps[i][j][k].x - ps[m][n][l].x);//三个坐标之差
int d2 = (ps[i][j][k].y - ps[m][n][l].y)*(ps[i][j][k].y - ps[m][n][l].y);
int d3 = (ps[i][j][k].z - ps[m][n][l].z)*(ps[i][j][k].z - ps[m][n][l].z);
//temp = sqrt(d1 + d2 + d3) * 10000 + 0.5;
temp = sqrt(d1 + d2 + d3);
sum[iThread] += temp; //距离求和
}
}
}
}
}
iAddThread[iThread]++;
}
}
}
}
double sumx = 0;
for (int i = 0; i < tnum; i++) {//各线程总和
sumx += sum[i];
}
end = clock();//结束计时
printf("time=%fn", (double)(end - start) / CLOCKS_PER_SEC);
//printf("Sum: %fn", (double)sumx / 5000);
printf("Sum: %fn", (double)sumx *2);
std::cout << "输入要并行的线程数: ";
}
return 0;
}我来讲解一下重点并行区域
#pragma omp parallel
这句语句下的{}区域内,openmp会按照线程数目进行并行,由于简单的自动for循环只能简单的拆分最外层循环,并不能一直满足我们的需求,所以我这里选择自己进行分配
iThread = omp_get_thread_num(); //获取线程号
if (iAddThread[iThread] % threadnum == iThread) 这两句话便是对并行程序是否需要进行计算的判断(取余),使用数组防止线程之间互相修改。
这样就能自己来对并行进行分配了。
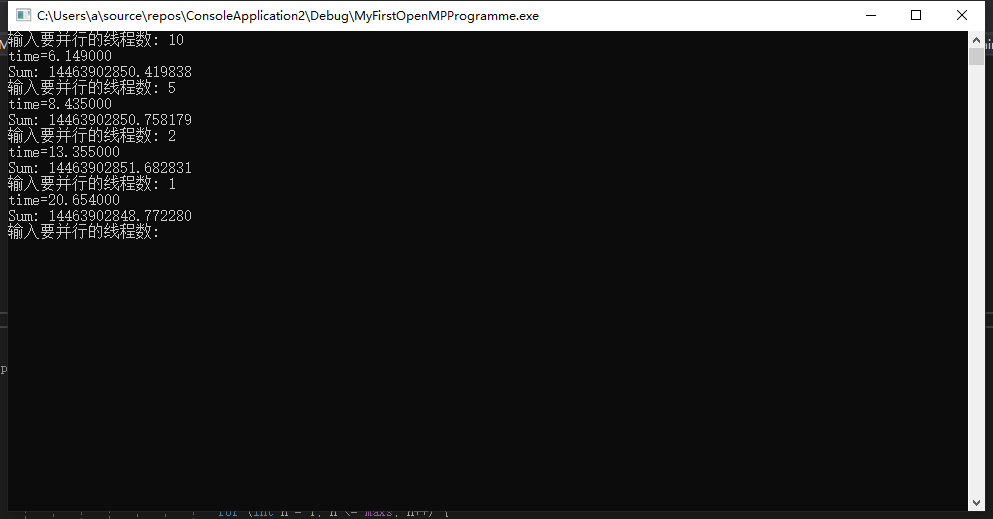
运行结果由于浮点数计算的原因不太稳定,将其转化为long就能稳定下来,算是在误差范围内
最后
以上就是隐形翅膀最近收集整理的关于OpenMP基础知识与使用并行思想计算三维点阵两两之间的距离之和的全部内容,更多相关OpenMP基础知识与使用并行思想计算三维点阵两两之间内容请搜索靠谱客的其他文章。








发表评论 取消回复