论文地址:https://www.ixueshu.com/document/9cd210e04def3c2b318947a18e7f9386.html
硬件背景:
传统的HDD盘具有高数据密度,价格低廉,持久化稳定的优点,但也无法摆脱机械盘寻道带来的开销,而且顺序访问和随机访问的性能差异巨大。
SSD相比HDD来说具备更加好的读写性能,其读写时延相比HDD来说低3个数量级。但针对DBMS系统来说,SSD也存在三个问题:
- 仅支持面向block的访问模式
- SSD的NAND只有固定的擦写次数,存在寿命问题
- SSD的成本过于高昂,每GB的价格是HDD的3-10倍
SSD/HDD的读写速度限制了使用它们来存储log的DBMS系统的性能,主要是因为DRAM和SSD/HDD存在巨大的随机与顺序访问延迟差异,以及两者的数据访问粒度也存在差异(即粗粒度的面向块的访问模式,细粒度的面向字节的访问模式)。
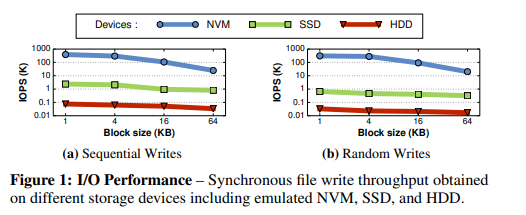
新生的NVM技术,如PCM,STT-MRAM以及RRAM,提供更快的读写访问速度,且提供细粒度的面向字节的访问模式。与使用SATA接口的SSD/HDD相比,NVM设备可以插入DIMM插槽,通过PCIE接口进行访问,为CPU提供了更高的带宽和更低的访问时延。且如下图所示,NVM设备的顺序访问和随机访问的差异相对SSD/HDD来说非常小。
如图所示,分别是基于WBL和WAL的DBMS的性能统计,由图可得,WBL在吞吐,故障恢复延迟,以及log存储空间占用方面,都远远处于优势,尤其是在DBMS故障恢复时,WBL具有非常快的恢复速度。
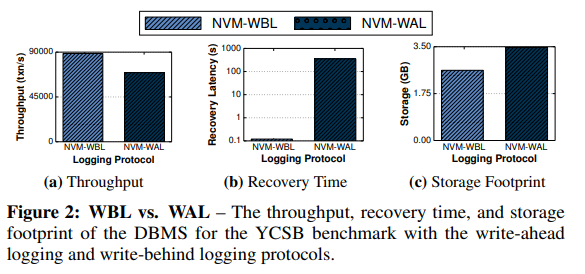
提升了DBMS系统事务吞吐大约1.3倍,其故障恢复速度提升了2个数量级,并在同样的NVM设备上,节省了大约1.5倍的空间。
WBL 流程
WBL机制完美利用了NVM设备的高读写性能,按字节存储等优点,WBL的特点是在数据成功flush到持久化存储设备之后,才记录一条log。相比于WAL,WBL具备更好的写入性能和更快的故障恢复速度,主要原因有:
- NVM设备的写入带宽相比SSD/HDD来说高出了数量级的差距
- 相比SDD/HDD来说,NVM设备的随机访问能力和顺序访问能力间的差距很小
- NVM设备提供了按字节存储的特性,这使得CPU可以直接访问NVM设备中的字节,从而不需要将数据组织成page或通过IO系统访问。

Runtime Operation
WBL相比WAL来说有很多方面的不同之处,最主要的是WBL不会在log中记录数据库元组的修改信息,因为在记录log的时候,事务已经完成了提交,且对数据库的更改都已经全部同步到了持久化存储设备中。当一个事务去修改数据库中的值时,DBMS会将其写入到一个dirty tuple table (DTT) 中去追踪这个事务的执行过程,每一条在DTT中的记录都包含了事务ID,类型等数据,类似于WAL中log中记录的数据。对于Insert和Delete操作,DTT中的记录会包含插入和删除的tuple的位置,针对Update操作,需要包含新值和旧值的位置,但DTT中的记录从来不会包含after-images的tuple。在事务提交时,会将DTT中的数据进行清空,DTT中的数据都在内存中,从来都不会写入到NVM或者其他持久化存储设备中。
在事务执行过程中,WBL中主要完成了:
- 执行事务操作
- 将对数据库的修改写入到内存中
- 将数据修改记录写入到DTT中,且一定不包含after-images的tuple
Commit Protocol
WBL放宽了数据写入到持久化存储设备中的顺序,即先将修改后的数据写入到持久化存储,再记录log的模式,会使得WBL的事务提交和故障恢复变得很复杂。DBMS在故障恢复过程中,必须要确定在故障的那一刻,哪些事务的数据是需要redo操作来进行回放的,而哪些数据又是需要undo操作来进行丢弃的。而在WBL的模式下,很可能会因为数据刷写到了持久化存储设备,但还未有对应的log来记录这一操作而导致数据的回放无法正确的辨识这些修改,故而在回放过程中可能需要扫描整个数据库来鉴别哪些数据是正确的,这对于DBMS的故障恢复来说是不可承受的。
即WBL场景下,Log的作用只剩下undo操作,redo操作的功能由NVM实现了。
在事务Commit阶段,为了解决如何通过log去记录从DRAM中将事务对数据库的修改flush到持久化存储设备的过程,设计了新的WBL的log entry结构,并且通过两个事务提交的时间戳来记录对数据修改的tuple的可见性,log entry结构如下图所示:

LSN:唯一的日志序列号
Log Record Type:当前log的操作类型(Insert,Update或者Delete)
Persisted Commit Timestamp(Cp):最后一条事务提交的时间戳
Dirty Commit Timestamp(Cd):DBMS分配给当次事务提交时,所产生的最大事务提交时间戳
在WBL中,也是采用group commit的模式来flush数据,在当前事务提交时,实际可能已经有很多个事务的数据已经flush到持久化存储设备中了,因此选取最后一个提交事务的提交时间戳作为Cp,表示在Cp这个时间戳以前的数据都是有效修改,都已经持久化在了存储设备中。同时,DBMS会分配出一个在此次事务提交完成之前的一个时间戳作为Cd,DBMS保证了当前所有flush到持久化存储设备中的数据所对应的事务的提交时间戳都小于Cd。即当前早于Cp的数据是已经确定可见了,故障恢复时不需要清理这些数据,处于(Cp,Cd)之间的数据是不可见的,故障恢复时需要将这些数据进行清理,且DBMS保证在此次事务提交完成之前,不可能产生比Cd还大的事务提交时间戳。只有事务提交时间戳早于Cp的事务才会通知应用程序为事务提交完成,而处于(Cp,Cd)之间的的事务提交,还需要等待下一轮的group commit来完成。
事务在commit阶段的过程:
- DBMS检查DTT中的条目,确定事务所关联的所有修改后的脏tuple
- 为本次group commit计算Cp和Cd
- 执行sync操作将DRAM中修改之后的脏数据块flush到持久化存储设备中
- 执行sync操作将包含Cp和Cd的log flush到NVM设备中
- 通知worker线程进行group commit
- 通知应用程序commit完成
在事务group commit过程中,可能会存在有些长事务,即可能在本次group commit完成时,还会有事务没有完成提交,这些未完成提交事务的时间戳会被记录在下一轮group commit的log中,私以为将这种事务的时间戳称之为Cl,则实际log中需要记录的事务提交窗口为(Cl,(Cp,Cd)),直到这个长事务提交完成后,才将Cl不记录在下一轮的group commit的log中。
在事务group commit过程中,可能会出现一个事务中修改的数据处于两个不同的Table中,即刷写到持久化存储设备中的tuple的位置实际上并不连续,这样一来如果使用NVM设备作为持久化存储设备,可以充分利用NVM设备的高性能随机访问能力。
对于那些未完成提交的事务,即中止的事务,会依据在DRAM中的DTT中记录的信息,完成这些事务对数据修改的撤销操作。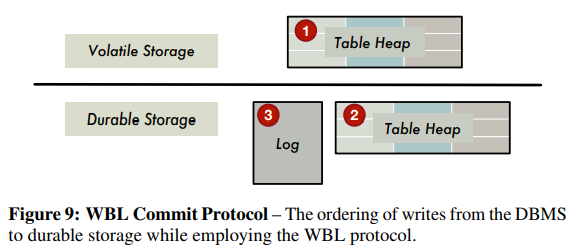
如上图所示,WBL的写入模式为先写入DRAM中的Table Heap,在其中完成对数据库数据的修改和索引信息,在事务提交时,DBMS会将内存中的所有此事务关联的数据全部flush到持久化存储设备中,最后在NVM设备中记录log。
Recovery Protocol
在WBL中,故障恢复过程只需要Undo操作。作者设计了commit timestamp gap的一种数据结构来控制在故障恢复阶段的数据处理,即在上文中所提到的(Cp,Cd)。在恢复过程中,针对事务提交时间戳位于(Cp,Cd)中的数据,都会视为事务未提交完成,即对这些数据进行清理,DBMS有专门的垃圾收集器线程去扫描处于(Cp,Cd)的tuple的数据修改,并将其撤销,当垃圾收集器完成对所有处于(Cp,Cd)的tuple数据的修改撤销,页会把这条log也做清除处理。
使用WBL机制时,不需要定期构建类似于WAL的Checkpoint机制来加快故障恢复速度,因为每个WBL log中已经包含了所有故障恢复所需要的数据,即commit timestamp gap (Cp,Cd),和长时间未提交完成的事务提交时间戳Cl,即提交窗口(Cl,(Cp,Cd)),在故障恢复过程中,只需要对处于这个间隔的数据进行undo操作即可,并且在每次log最新纪录时,既可以删除以前较老的log,以保证log实际的大小永远都很小,这极大的加快了故障恢复的速度。
最后
以上就是朴素小海豚最近收集整理的关于Write-Behind-Logging硬件背景:WBL 流程的全部内容,更多相关Write-Behind-Logging硬件背景:WBL内容请搜索靠谱客的其他文章。








发表评论 取消回复