1 电梯算法之deadline
1.1简介
deadline,顾名思义是说有个最后期限控制。通过调研也发现对于每一个读请求和写请求都会赋予一个时间戳,用来控制一个最大的延迟处理时间点。超过该时间戳是一定要处理的。它是通过一个链表(first in first out)来将这些request串联起来的。
但是如果一直这样按照链表的顺序来处理,又会造成磁盘抖动的问题。所以又很灵巧的引入了一个batch的概念。它利用rbtree可以找到连续的request,这些连续的request被称为一个batch。一旦处理一个request,就会开始处理该request所在的batch,直到batch处理完毕,或者发现处理batch的个数已经超过预先设置的阈值(16)
这是一个互相依存的设计。如果batch这个集合的个数设置太大,就会造成IO延迟。如果想要尽量减小IO延迟,deadline也允许动态修改batch集合个数,最小值修改为1,这样就变成了真正的fifo。
1.2数据结构
struct deadline_data
| 名称 | 类型 | 说明 |
| sort_list[2] | struct rb_root | 这是一个含有两个元素的数组,读、写各占一个。是两棵rbtree,一棵树上是read request,另一棵是write request |
| fifo_list[2] | struct list_head | 先进先出链表,一个链表上挂载的是read request,另一个链表上挂载的是write request |
| batch相关 | ||
| next_rq[2] | struct request * | 当处理完一个request之后,会在rbtree中查找该request相邻的下一个request。如果能找到便赋值给对应的next_rq。所谓对应,也就是读写分开。和前边讲述的两项一样。 |
| batching | unsigned int | 已经处理batch集合中的个数 |
| last_sector | sector_t | 上次处理request的结束位置。目前算法中没有用到该项。只是在将request派发时,修改下该项。 |
| starved | unsigned int | Deadline优先处理读请求,假如现在写链表上有请求,但是现在要优先处理读链表上的请求,此时该值要加1。 |
| 用来控制的一些阈值 | ||
| fifo_expire[2] | Int | 最大延迟处理时间戳。读请求最大延迟处理时间戳设置为:jiffies+ HZ / 2;写请求设置为:jiffies+ 5 * HZ |
| fifo_batch | Int | Batch集合最大值,初始为16 |
| writes_starved | Int | 写请求最大忍受挨饿的次数。所谓的挨饿就是读请求优先处理的次数。初始为2。 |
| front_merges | Int | Deadline只允许向前merge。如果这个开关关闭,deadline不允许Merge。 |
1.3deadline注册接口
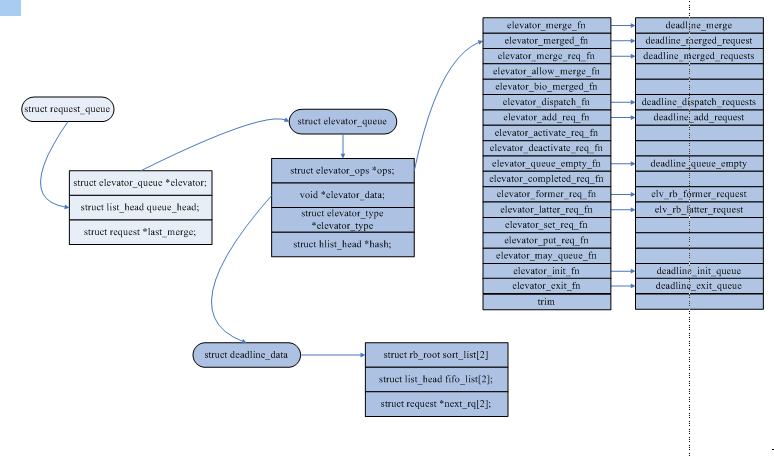
其中属于deadline组织数据的数据结构有两棵rbtree,两个先进先出链表,以及两个用来进行批处理的集合。
1.4deadline初始化与注销
1.4.1 模块初始化
模块的初始化比较简单,需要准备一个structelevator_type类型的变量。其中包括deadline支持的操作函数elevator_ops;名字“deadline”;sys目录下创建的文件列表。
然后调用elv_register函数进行电梯算法的注册。它会将具体的电梯算法挂载到一个链表中。
1.4.2 模块注销
调用elv_unregister完成注销工作。注销工作没有想象的那么简单,只是从链表上摘下电梯算法的数据结构。还需要完成一个清理工作:
遍历系统中所有的内核进程,如果发现内核线程指向的io_context不为空,则调用电梯算法注册的trim函数。deadline没有注册该函数。(现在还不清楚,为什么要遍历所有的内核进程。而且也不检查电梯算法是否注册了trim函数)什么是trim
1.4.3 deadline data初始化
动态切换
在创建等待队列时会调用deadline_init_queue函数,来完成该工作。
1、 动态分配内存给deadline_data
2、 初始化两棵rbtree,两个fifo链表,
3、 初始化一些阈值:读写请求最大延迟,读请求最大延迟被初始化为HZ/2(500ms),写请求被初始化为5HZ(5s);写请求允许读请求优先处理的次数(挨饿的次数)被初始化为2;批处理集合的个数被初始化为16;
1.4.4 deadline data注销
1、 检查fifo读写链表是否为空,如果不为空会panic。
2、 如果为空,释放掉分配的缓存。
1.5deadline处理流程
对于3.1.2小节提到的elevator_ops,deadline并没有注册所有的操作函数。只注册了如下提到的几个操作函数。输入、输出以及函数的功能在3.1.2小节中已经大概讲述过,在这儿着重讲下各个函数的内部实现。
1.5.1 deadline_add_request
1.5.1.1 函数声明:
static void deadline_add_request(struct request_queue *q, structrequest *rq)
1.5.1.2 流程说明:
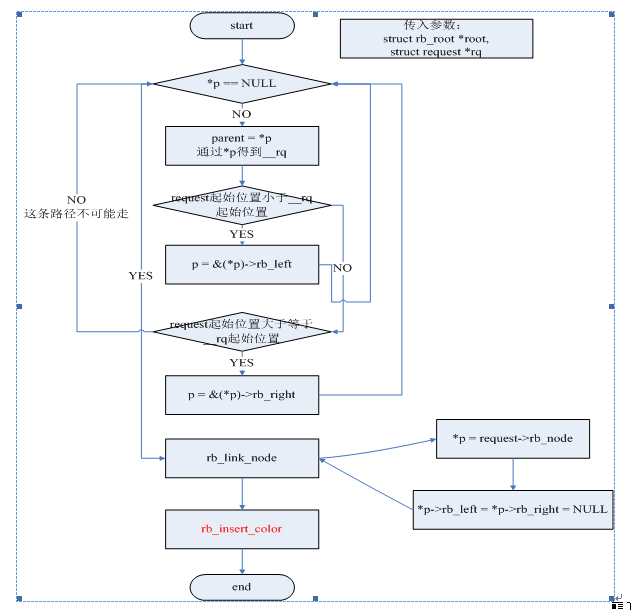
1、 添加request到rbtree中,该功能通过elv_rb_add函数来实现。在描述该过程前先申明该过程中需要用到的变量:
structrb_node **p = &root->rb_node; //用来记录查找的当前位置
structrb_node *parent = NULL;//父节点
structrequest *__rq;//和rb_node相对应的request
2、 给request标记一个最大延迟处理时间,读请求最大延迟处理时间戳设置为:jiffies+ HZ / 2;写请求设置为:jiffies+ 5 * HZ
3、 将request添加到fifo链表的尾部
1.5.2 deadline_merge
1.5.2.1 函数声明:
static int deadline_merge(struct request_queue*q, struct request **req, struct bio *bio)
1.5.2.2 流程说明:
1、 首先判断deadline目前是否为向前merge,如果不是,则直接返回ELEVATOR_NO_MERGE。
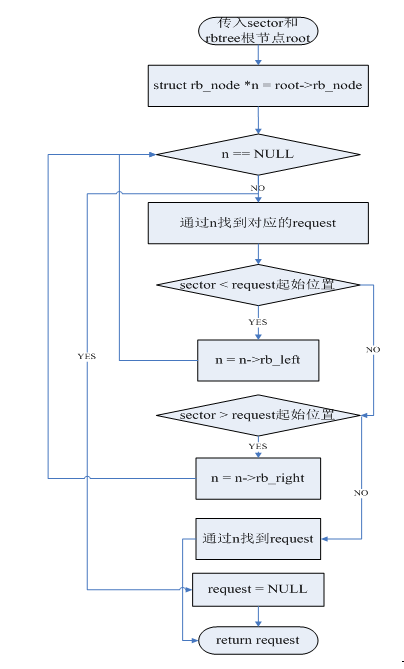
2、 以bio的终止位置为键值在rbtree中寻找request,如果能找到则试图merge bio。如果merge成功返回ELEVATOR_FRONT_MERGE。如果找不到,或者merge失败都返回ELEVATOR_NO_MERGE
需找过程如下:
1.5.3 deadline_merged_requests
1.5.3.1 函数声明:
static void deadline_merged_requests(structrequest_queue *q, struct request *req, struct request *next)
1.5.3.2 流程说明:
1、 判断next记录的最大延迟处理时间戳是否比req的早,如果早,那就将req移动到next在fifo链表的后边,并且设置req的最大延迟处理时间戳为next的时间戳。
2、 如果next记录的最大延迟处理时间戳不比req的早,则直接将next从fifo链表中删除,并从rbtree中删除。从rbtree中删除的过程待补充。
1.5.4 deadline_merged_request
1.5.4.1 函数声明:
static voiddeadline_merged_request(struct request_queue *q, struct request *req, int type)
1.5.4.2 流程说明:
1、 如果type表明是向前merge,此时需要更新request在rbtree中的位置。否则直接退出。更新操作便是将request从rbtree中删除,删除的过程rbtree待补充。
1.5.5 deadline_dispatch_requests
1.5.5.1 函数声明:
static intdeadline_dispatch_requests(struct request_queue *q, int force)
1.5.5.2 流程说明:
在流程图中用到的概念:
batch集合:在4.2小节已经解释过。
next_rq[data_dir]:用来表示batch集合中下一个元素。
batching:目前batch集合中处理的个数
fifo_batch:初始化时设置batch集合的个数
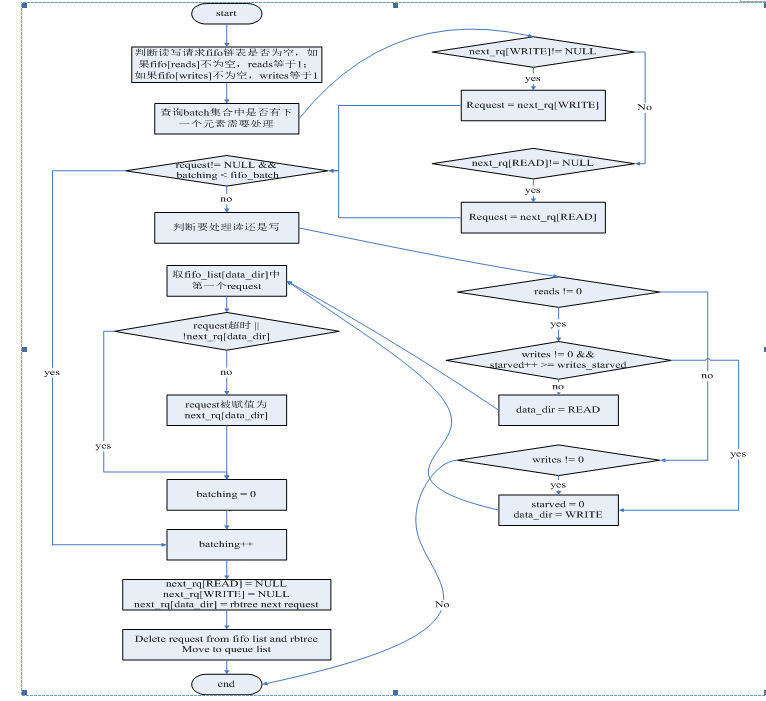
1、 通过batch机制,deadline可以保证在一个io方向上有持续性。并且在该基础上保证读优先。因为当batch集合处理结束后,首先选择读请求来处理。
2、 一旦读请求获得了处理权限,对写请求的延迟是比较大的。因为当处理一个读请求后,便开始处理该读请求所在的batch集合。当该集合处理结束后,又选择了处理读请求,虽然在此时如果发现有写请求,会将starved加1。deadline初始化时写请求挨饿的次数默认设置为2。也就是说要处理两个读batch集合才会处理写请求。而写请求处理一个batch集合便要处理读请求。
3、 这样虽然保证了在读方向或者写方向一定的连续性,但是也只是很小的一段。很有可能在写了磁盘的100G这个位置,切换到读请求又要读1G那个位置。这样仍然会造成磁头的抖动。
1.5.6 deadline_queue_empty
1.5.6.1 函数声明
static int deadline_queue_empty(structrequest_queue *q)
1.5.6.2 流程说明
该过程比较简单,只是判断fifo链表是否为空。如果为空返回1,如果不为空返回0。
1.5.7 elv_rb_former_request
1.5.7.1 函数声明
struct request*elv_rb_former_request(struct request_queue *q, struct request *rq)
1.5.7.2 流程说明
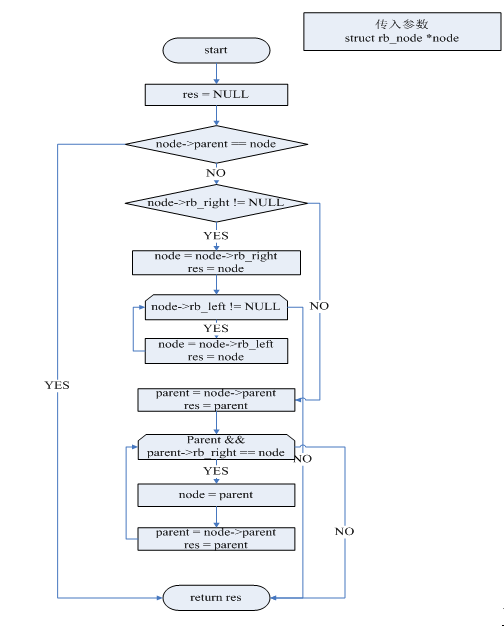
1.5.8 elv_rb_latter_request
1.5.8.1 函数声明
struct request*elv_rb_latter_request(struct request_queue *q, struct request *rq)
1.5.8.2 流程说明
找到rq在rbtree中的后一个reqeust。找不到返回NULL。
最后
以上就是追寻白羊最近收集整理的关于内核IO电梯调度算法-Deadline追踪1 电梯算法之deadline的全部内容,更多相关内核IO电梯调度算法-Deadline追踪1 电梯算法之deadline内容请搜索靠谱客的其他文章。








发表评论 取消回复