(一)数据结构
栈
栈:stack,又称堆栈,它是运算受限的线性表,其限制是仅允许在标的一端进行插入和删除操作,不允许在其
他任何位置进行添加、查找、删除等操作。
简单的说:采用该结构的集合,对元素的存取有如下的特点
先进后出(即,存进去的元素,要在后它后面的元素依次取出后,才能取出该元素)。例如,子弹压进弹
夹,先压进去的子弹在下面,后压进去的子弹在上面,当开枪时,先弹出上面的子弹,然后才能弹出下面的
子弹。
栈的入口、出口的都是栈的顶端位置。
这里两个名词需要注意:
压栈:就是存元素。即,把元素存储到栈的顶端位置,栈中已有元素依次向栈底方向移动一个位置。
弹栈:就是取元素。即,把栈的顶端位置元素取出,栈中已有元素依次向栈顶方向移动一个位置。
队列
队列:queue,简称队,它同堆栈一样,也是一种运算受限的线性表,其限制是仅允许在表的一端进行插入,
而在表的另一端进行删除。
简单的说,采用该结构的集合,对元素的存取有如下的特点:
先进先出(即,存进去的元素,要在后它前面的元素依次取出后,才能取出该元素)。例如,小火车过山
洞,车头先进去,车尾后进去;车头先出来,车尾后出来。
队列的入口、出口各占一侧。例如,下图中的左侧为入口,右侧为出口
链表
链表:linked list,由一系列结点node(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每
个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。我们常说的
链表结构有单向链表与双向链表,那么这里给大家介绍的是单向链表。
简单的说,采用该结构的集合,对元素的存取有如下的特点:
多个结点之间,通过地址进行连接。例如,多个人手拉手,每个人使用自己的右手拉住下个人的左手,依次
类推,这样多个人就连在一起了。
查找元素慢:想查找某个元素,需要通过连接的节点,依次向后查找指定元素
增删元素快:
增加元素:只需要修改连接下个元素的地址即可。
删除元素:只需要修改连接下个元素的地址即可。
红黑树
二叉树:binary tree ,是每个结点不超过2的有序树(tree) 。
简单的理解,就是一种类似于我们生活中树的结构,只不过每个结点上都最多只能有两个子结点。
二叉树是每个节点最多有两个子树的树结构。顶上的叫根结点,两边被称作“左子树”和“右子树”。
红黑树本身就是一颗二叉查找树,将节点插入后,该树仍然
是一颗二叉查找树。也就意味着,树的键值仍然是有序的。
红黑树的约束:
1. 节点可以是红色的或者黑色的
2. 根节点是黑色的
3. 叶子节点(特指空节点)是黑色的
4. 每个红色节点的子节点都是黑色的
5. 任何一个节点到其每一个叶子节点的所有路径上黑色节点数相同
红黑树的特点:
速度特别快,趋近平衡树,查找叶子元素最少和最多次数不多于二倍
(二)设计模式
代理模式:见“反射机制和代理模式”一篇
单例模式:
1、饿汉式:

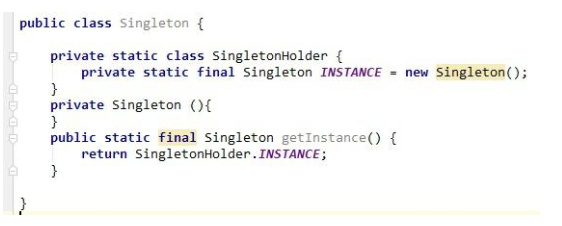
2、静态内部类
适配器模式:主要有两种,类适配器和对象适配器
使用场景:通过增加一个新的适配器类来解决接口不兼容的问题,使得原本没有任何关系的类可以协同工作。将一个类的接口变换成客户端所期待的另一种接口,从而使原本因接口不匹配而无法在一起工作的两个类能够在一起工作。修改一个已经投产中的接口时,适配器模式可能是最适合你的模式。
(1)类适配器主要是使用继承的方式连接两个接口。
类适配器主要是使用继承的方式连接两个接口。我们假设对接接口A和接口B。
先写接口B
public interface MP4{
void play();
}
接口B的实现类
public class ExpensiveMP4 implement MP4{
public void play(){
// todo
}
}
接口A
public interface Player{
void action();
}
假如你的工程中有这几个类,然后你发现,action()方法中要写的操作,就是ExpensiveMP4的play()中的操作“//todo”,所以你没必要重复再写一次,想个办法让他们适配。所以,你想让外部调用Player的时候去调用ExpensiveMP4的play,如果用类适配器的话可以这样写
public class ExpensiveAdapter extends ExpensiveMP4 implement Player{
public void action(){
play();
}
}
(2)对象适配器用的是“组合”的方式
这时候我们使用对象适配器的话可以这样写。
public class PlayerAdapter implement Player{
public MP4 mp4;
public PlayerAdapter (MP4 mp4){
this.mp4 = mp4;
}
public void action(){
if(mp4!= null){
mp4.play();
}
}
}
(三)算法
排序算法:
(1)、插入排序:直接插入排序、二分法插入排序、希尔排序。
(2)、选择排序:简单选择排序、堆排序。
(3)、交换排序:冒泡排序、快速排序。
(4)、归并排序
(5)、线性时间排序:计数排序、基数排序、桶排序
直接插入排序:
使用场景:适合少量数据的排序,或者数据基本已经有序的情况
public static int[] insertionSort(int[] array) {
if (array.length == 0 || array.length <= 1)
return array;
int current;
for (int i = 0; i < array.length - 1; i++) {
current = array[i + 1];
int preIndex = i;
while (preIndex >= 0 && current < array[preIndex]) {
array[preIndex + 1] = array[preIndex];
preIndex--;
}
array[preIndex + 1] = current;
}
return array;
}
二分插入排序(折半插入)
特征分析: 折半插入排序仅减少了关键字间的比较次数,而记录的移动次数不变。
使用场景: 如果元素的比较的操作比较耗时,可以对直接插入排序的性能进行提升。
public static void binaryInsertSort(int[] arr){
if(arr == null || arr.length <= 1) return;
for(int i=1;i<arr.length ;i++){
int temp=arr[i];
int start=0,end=i;
while(start<end){
int mid=start+(end-start)/2;
if(arr[mid]<=temp){
start=mid+1;
}else{
end=mid;
}
}
int p=i;
while(p>end){
arr[p]=arr[p-1];
p--;
}
arr[p]=temp;
}
}
希尔排序:希尔排序是基于插入排序的一种算法, 在此算法基础之上增加了一个新的特性,提高了效率。
public static void shellSort(int[] arr){
if(arr == null || arr.length <= 1) return;
int gap=arr.length/2;
while(gap>0){
for(int i=gap;i<arr.length ;i++){
int temp=arr[i];
int p=i;
while(p>=gap&&arr[p-gap]>temp){
arr[p]=arr[p-gap];
p-=gap;
}
arr[p]=temp;
}
gap/=2;
}
}
选择排序:
简单选择排序:它的工作原理是每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。
public static int[] selectionSort(int[] array) {
if (array.length == 0 || array.length<2)
return array;
for (int i = 0; i < array.length; i++) {
int minIndex = i;
for (int j = i; j < array.length; j++) {
if (array[j] < array[minIndex]) //找到最小的数
minIndex = j; //将最小数的索引保存
}
int temp = array[minIndex];
array[minIndex] = array[i];
array[i] = temp;
}
return array;
}
特征分析:
1、空间复杂度O(1),最好/最坏/平均时间复杂度都是O(n^2),比较次数O(n^2),移动次数O(n)。
2、选择排序是不稳定的排序方法(比如序列[5, 5, 3]第一次就将第一个[5]与[3]交换,导致第一个5挪动到第二个5后面)。
冒泡排序
基本思想:
比较相邻的元素,如果前者比后者大,就交换他们两个,对从前往后对每一对相邻元素作同样的工作,这样一趟冒泡后,最后的元素就是最大的数。这样每一趟冒泡确定一个元素的位置,n趟后数组即有序。同样也可以从后往前冒泡,依次确定最小值。
public static int[] bubbleSort(int[] array) {
if (array.length == 0 || array.length<2)
return array;
for (int i = 0; i < array.length; i++)
for (int j = 0; j < array.length - 1 - i; j++)
if (array[j + 1] < array[j]) {
int temp = array[j + 1];
array[j + 1] = array[j];
array[j] = temp;
}
return array;
}
特征分析:
1、空间复杂度O(1),最好时间复杂度O(n),最坏时间复杂度O(n^2),平均时间复杂度O(n^2)。
2、冒泡排序时稳定的。
归并排序
基本思想:
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
public static int[] MergeSort(int[] array) {
if (array.length < 2) return array;
int mid = array.length / 2;
int[] left = Arrays.copyOfRange(array, 0, mid);
int[] right = Arrays.copyOfRange(array, mid, array.length);
return merge(MergeSort(left), MergeSort(right));
}
public static int[] merge(int[] left, int[] right) {
int[] result = new int[left.length + right.length];
for (int index = 0, i = 0, j = 0; index < result.length; index++) {
if (i >= left.length)
result[index] = right[j++];
else if (j >= right.length)
result[index] = left[i++];
else if (left[i] > right[j])
result[index] = right[j++];
else
result[index] = left[i++];
}
return result;
}
特征分析:
1、空间复杂度O(n),时间复杂度O(1)。
2、归并排序是稳定的排序。
最后
以上就是明理小伙最近收集整理的关于七、基本算法,数据结构和设计模式的全部内容,更多相关七、基本算法内容请搜索靠谱客的其他文章。








发表评论 取消回复