Optimal ANN-SNN Conversion for High-accuracy and Ultra-low-latency Spiking Neural Networks 阅读总结
- 运行结果演示
- Abstract
- 1.Introduction
- 2.Preliminaries
- 2.1 ANN中的神经元模型:
- 2.2 SNN中的神经元模型:
- 2.3 ANN-SNN转换
- 3.Conversion error analysis
- 3.1Clipping error
- 3.2Quantization error(flooring error)
- 3.3Unevenness error
- 4.Optimal ANN-SNN conversion
- 4.1Quantization clip-floor activation function
- 4.2Quantization clip-floor-shift activation function
- 4.3 Algorithm for training quantization clip-floor-shift activation function
- 5.Related work
- 6.Experiments
- 6.1 比较ANN使用Relu、clip-floor与clip-floor-shift的表现
- 6.2和世界最先进的方法比较
- 6.3比较ANN转换得到的SNN使用clip-floor与clip-floor-shift的表现
- 6.4比较量化步长L对实验结果的影响
- 7.Discussion and conclusion
运行结果演示
我将该论文发布于此处的代码进行了阅读与运行,得到结果如下:
训练过程(以CIFAR-10为例子使用VGG16模型进行训练)
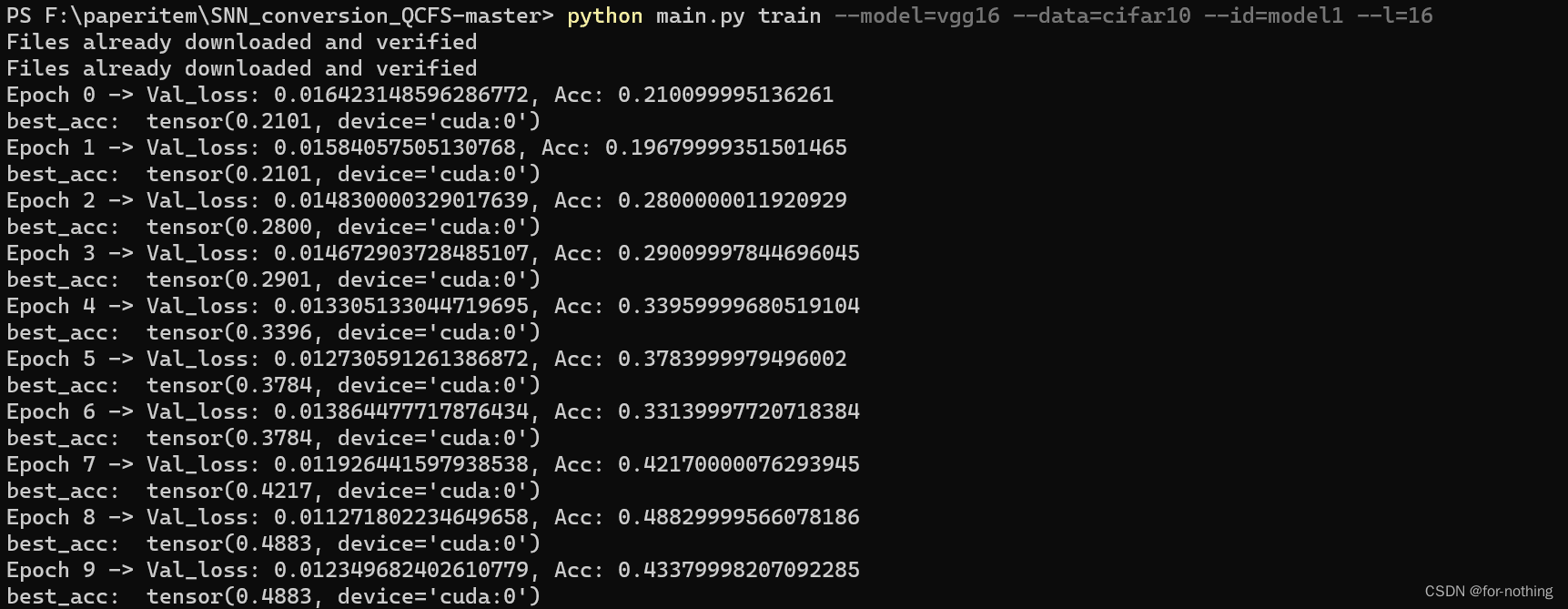
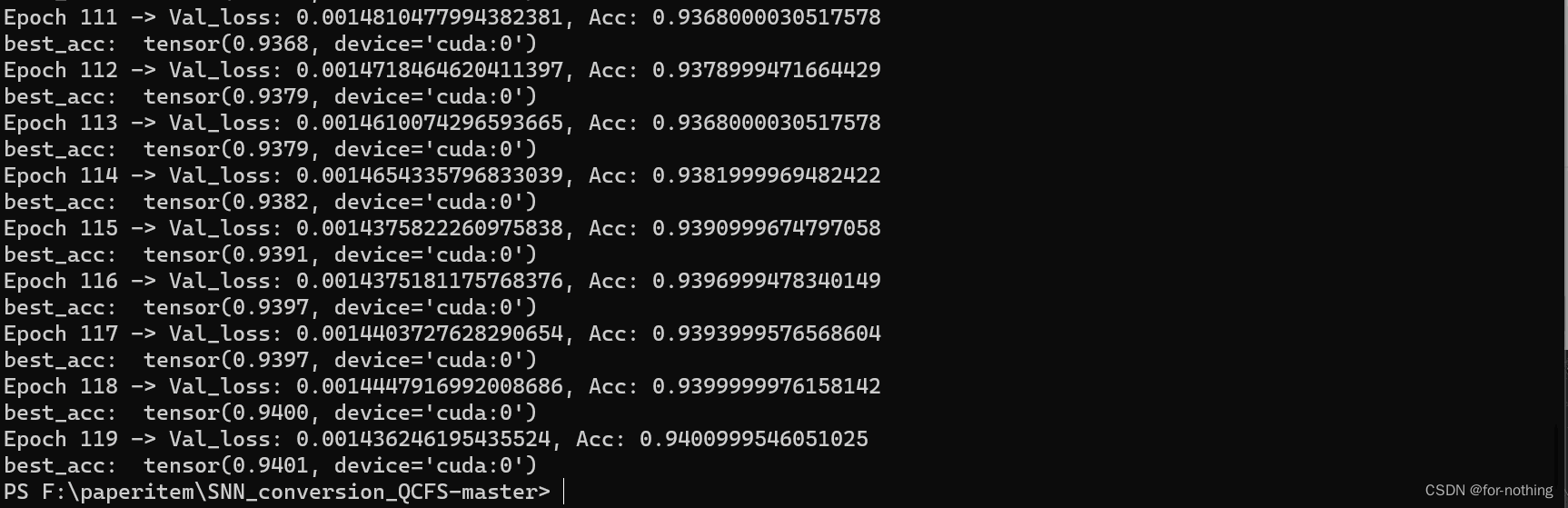
结果测试:
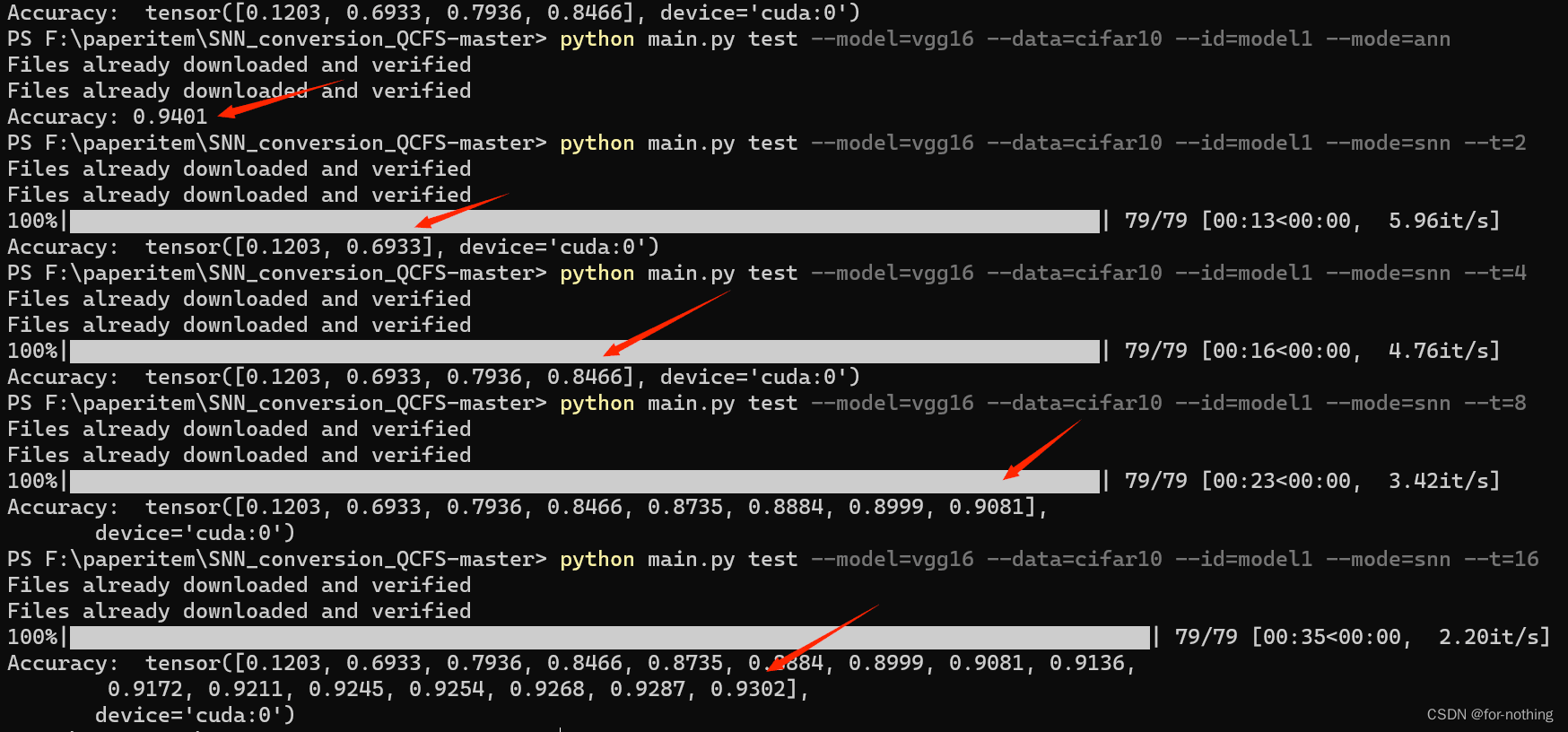
可以看到,随着T的增加,SNN的准确度越来越接近ANN的准确度,但是运行时间也随之增加,尽管如此,已经可以在较短的时间步长内达到十分优秀的准确率。
Abstract
为了解决传统的ANN-SNN转换中存在的时间步长过长会影响推理时间,而过短会导致性能倒退的问题,这篇论文从理论上分析了ANN-SNN转换中的误差,并提出了clip-floor-shift 激活函数用于ANN的训练,使得ANN-SNN的期望转换误差为0,从而得到高精度低延迟的脉冲神经网络。(是第一次高精度低延迟ANN-SNN转换的探索)
1.Introduction
目前ANN-SNN转换得到的SNN在大规模数据集上性能已经可以和ANN相当,相比于原始的ANN,转换得到的SNN速度快,功耗低更加实用。
在转换过程中SNN的时间步长T取得越大,得到的结果就越接近原始的ANN,然而这会导致巨大的运算量,从而阻碍SNN的实际应用。若是SNN的时间步长T取得过小,会使得产生的剩余势能
V
l
(
t
)
−
V
l
(
0
)
T
frac{V^l(t)-V^l(0)}{T}
TVl(t)−Vl(0)无法忽视,影响模型的精度。
创新之处:目前现有的文章都需要几十到几百的时间步长,而这篇论文中的方案将其缩短到了更少的时间步长(eg.4个时间步长)。
主要贡献:
- 将误差分为clipping error、quantization error、unevenness error
- 提出了用clip-floor-shift激活函数代替ANN中的Relu激活函数
- 在CIRAR-10,CIFAR-100以及ImageNet数据集上进行了测试,所提出的方法在更小的步长上超过了目前最先进的精度。
2.Preliminaries
2.1 ANN中的神经元模型:
α
l
=
h
(
W
l
α
l
−
1
)
bm alpha^l=h(bm W^lbm alpha^{l-1})
αl=h(Wlαl−1)
其中
α
l
alpha^l
αl为第
l
l
l层的输出,
W
l
W^l
Wl是
l
l
l和
l
−
1
l-1
l−1层之间的权重矩阵,
h
h
h 是Relu激活函数
2.2 SNN中的神经元模型:
由Integrate-and-Fire(IF)模型:
m
l
(
t
)
=
v
l
(
t
−
1
)
+
W
l
x
l
−
1
(
t
)
bm m^l(t)=bm v^l(t-1)+bm W^lbm x^{l-1}(t)
ml(t)=vl(t−1)+Wlxl−1(t)
s
l
(
t
)
=
H
(
m
l
(
t
)
−
θ
l
)
bm s^l(t)=H(bm m^l(t)-bm theta^l)
sl(t)=H(ml(t)−θl)
v
l
(
t
)
=
m
l
(
t
)
−
s
l
(
t
)
θ
l
bm v^l(t)=bm m^l(t)-bm s^l(t)theta^l
vl(t)=ml(t)−sl(t)θl
x
l
(
t
)
=
s
l
(
t
)
θ
l
bm x^l(t)=bm s^l(t)theta^l
xl(t)=sl(t)θl
其中
m
l
(
t
)
m^l(t)
ml(t)为t时刻脉冲产生前的电位,
v
l
(
t
)
v^l(t)
vl(t)为t时刻脉冲产生后的电位,
θ
l
bm theta^l
θl是点火阈值
θ
l
theta^l
θl的向量,H(*)是阶跃函数,
x
l
−
1
(
t
)
bm x^{l-1}(t)
xl−1(t)是l-1层向l层的输入
2.3 ANN-SNN转换
由2.2节四个式子推导得到
v
l
(
t
)
−
v
l
(
t
−
1
)
=
W
l
x
l
−
1
(
t
)
−
s
l
(
t
)
θ
l
bm v^l(t)-bm v^l(t-1)=bm W^lbm x^{l-1}(t)-bm s^l(t)theta^l
vl(t)−vl(t−1)=Wlxl−1(t)−sl(t)θl
同除时间步长T(time step),并累加0-T时间得到:
v
l
(
T
)
−
v
l
(
0
)
T
=
W
l
∑
i
=
1
T
x
l
−
1
(
t
)
T
−
∑
i
=
1
T
s
l
(
i
)
θ
l
T
frac{bm v^l(T)-bm v^l(0)}T=frac{bm W^lsum_{i=1}^Tbm x^{l-1}(t)}T-frac{sum_{i=1}^Tbm s^l(i)theta^l}T
Tvl(T)−vl(0)=TWl∑i=1Txl−1(t)−T∑i=1Tsl(i)θl
令
ϕ
l
−
1
(
T
)
=
∑
i
=
1
T
x
l
−
1
(
t
)
T
phi^{l-1}(T)=frac{sum_{i=1}^Tbm x^{l-1}(t)}T
ϕl−1(T)=T∑i=1Txl−1(t)
有:
ϕ
l
(
T
)
=
W
l
ϕ
l
−
1
(
T
)
−
v
l
(
T
)
−
v
l
(
0
)
T
phi^l(T)=bm W^lphi^{l-1}(T)-frac{bm v^l(T)-bm v^l(0)}T
ϕl(T)=Wlϕl−1(T)−Tvl(T)−vl(0)
当令T足够大时该等式就几乎等同于2.1节中ANN的等式,即此时的SNN公式和ANN公式几乎相等,此时可以进行ANN-SNN的转化。
由于需要较大的T的限制条件,而较大的T会导致运算时间的增加,于是便产生了需要优化的问题:该如何减少T带来的影响。
3.Conversion error analysis
假设ANN和SNN中T时刻来自l-1层的输入相同,即
α
l
−
1
=
ϕ
l
−
1
(
T
)
bm alpha^{l-1}=phi^{l-1}(T)
αl−1=ϕl−1(T)
令
z
l
=
W
l
ϕ
l
−
1
(
T
)
=
W
l
α
l
−
1
bm z^l=bm W^lphi^{l-1}(T)=bm W^lbmalpha^{l-1}
zl=Wlϕl−1(T)=Wlαl−1
误差公式:
E
r
r
l
=
ϕ
l
(
T
)
−
α
l
=
z
l
−
v
l
(
T
)
−
v
l
(
0
)
T
−
h
(
z
l
)
bm{Err}^l=phi^l(T)-bmalpha^l=bm z^l-frac{bm v^l(T)-bm v^l(0)}T-h(bm z^l)
Errl=ϕl(T)−αl=zl−Tvl(T)−vl(0)−h(zl)
3.1Clipping error
由于
ϕ
l
(
T
)
=
∑
i
=
1
T
x
l
(
t
)
T
=
∑
i
=
1
T
s
l
(
t
)
T
θ
l
phi^l(T)=frac{sum_{i=1}^Tbm x^{l}(t)}T=frac{sum_{i=1}^Tbm s^{l}(t)}Ttheta^l
ϕl(T)=T∑i=1Txl(t)=T∑i=1Tsl(t)θl在区间
[
0
,
θ
l
]
[0,theta^l]
[0,θl]
建立
α
l
bmalpha^l
αl到
ϕ
l
(
T
)
phi^l(T)
ϕl(T)的映射函数:
ϕ
l
(
T
)
=
c
l
i
p
(
θ
l
T
⌊
α
l
T
λ
l
⌋
,
0
,
θ
l
)
phi^l(T)=clip(frac{theta^l}Tlfloor frac{bmalpha^lT}{lambda^l}rfloor,0,theta^l)
ϕl(T)=clip(Tθl⌊λlαlT⌋,0,θl)
clip函数表示当x < a 时结果为a,x > b时结果为b,b<=x<=b时结果为x.
考虑到99.9%的
α
l
bmalpha^l
αl在区间
[
0
,
α
m
a
x
l
3
]
[0,frac{bmalpha^l_{max}}3]
[0,3αmaxl]里,可以根据这个设置
λ
l
lambda^l
λl
如下图(a),可以看出在
z
l
>
λ
l
bm z^l>lambda^l
zl>λl的时候,全部被映射为
θ
l
theta^l
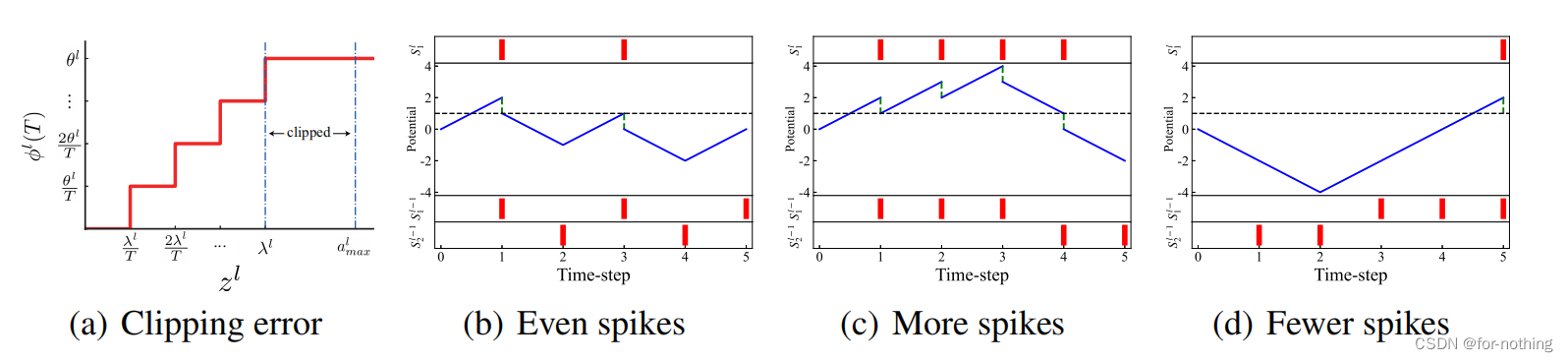
θl,由此产生的误差即是Clipping error.
3.2Quantization error(flooring error)
由连续值映射到离散值不可避免的存在一些量化误差,比如在ANN中区间 [ λ l T , 2 λ l T ) [frac{lambda^l}T,frac{2lambda^l}T) [Tλl,T2λl)的 α l bmalpha^l αl全部被映射成了SNN中 ϕ l ( T ) phi^l(T) ϕl(T)的 θ l T frac{theta^l}T Tθl
3.3Unevenness error
不均匀误差是由于输入脉冲的不均匀造成的。
如上图(b)~(d),最上方一栏是输出的脉冲,下方两栏是输入的脉冲。虽然脉冲数量相同,但是由于脉冲到达的时间不一样,所以产生的输出也不同,可能会产生比预期更多或更少的输出。
当
v
l
(
T
)
bm v^l(T)
vl(T)在
[
0
,
θ
l
]
[0,theta^l]
[0,θl]的时候不均匀误差就会退化为量化误差,由于0<
v
i
l
(
t
)
θ
l
frac{v_i^l(t)}{theta^l}
θlvil(t)<1,此时:
ϕ
l
(
T
)
=
W
l
ϕ
l
−
1
(
T
)
−
v
l
(
T
)
−
v
l
(
0
)
T
=
θ
l
T
z
l
T
+
v
l
(
0
)
θ
l
−
θ
l
T
v
l
(
t
)
θ
l
≈
θ
l
c
l
i
p
(
1
T
⌊
z
l
T
+
v
l
(
0
)
θ
l
⌋
,
0
,
1
)
phi^l(T)=bm W^lphi^{l-1}(T)-frac{bm v^l(T)-bm v^l(0)}T= frac{theta^l}Tfrac{z^lT+bm v^l(0)}{theta^l}-frac{theta^l}Tfrac{bm v^l(t)}{theta^l}approxtheta^lclip(frac1Tlfloor frac{bm z^lT+bm v^l(0)}{theta^l}rfloor,0,1)
ϕl(T)=Wlϕl−1(T)−Tvl(T)−vl(0)=TθlθlzlT+vl(0)−Tθlθlvl(t)≈θlclip(T1⌊θlzlT+vl(0)⌋,0,1)
带入
E
r
r
l
bm{Err}^l
Errl得:
E
r
r
~
l
=
θ
l
c
l
i
p
(
1
T
⌊
z
l
T
+
v
l
(
0
)
θ
l
⌋
,
0
,
1
)
−
h
(
z
l
)
≈
E
r
r
l
widetilde{bm{Err}}^l=theta^lclip(frac1Tlfloor frac{bm z^lT+bm v^l(0)}{theta^l}rfloor,0,1)-h(bm z^l)approxbm{Err}^l
Err
l=θlclip(T1⌊θlzlT+vl(0)⌋,0,1)−h(zl)≈Errl
4.Optimal ANN-SNN conversion
4.1Quantization clip-floor activation function
当ANN使用如下clip-floor激活函数的时候:
α
l
=
h
‾
(
z
l
)
=
λ
l
c
l
i
p
(
1
L
⌊
z
l
L
λ
l
⌋
,
0
,
1
)
bm alpha^l=overline h(z^l)=lambda^lclip(frac{1}Llfloorfrac{z^lL}{lambda^l}rfloor,0,1)
αl=h(zl)=λlclip(L1⌊λlzlL⌋,0,1)
有定理1:
当
T
=
L
,
θ
l
=
λ
l
,
v
(
0
)
=
0
T=L,theta^l=lambda^l,v(0)=0
T=L,θl=λl,v(0)=0的时候有
E
r
r
~
=
ϕ
l
(
T
)
−
α
l
=
0
widetilde{Err}=phi^l(T)-bmalpha^l=0
Err
=ϕl(T)−αl=0
证明:
E
r
r
l
=
ϕ
l
(
T
)
−
α
l
=
θ
l
c
l
i
p
(
1
T
⌊
z
l
T
+
v
l
(
0
)
θ
l
⌋
,
0
,
1
)
−
λ
l
c
l
i
p
(
1
L
⌊
z
l
L
λ
l
⌋
,
0
,
1
)
=
0
bm{Err}^l=phi^l(T)-bmalpha^l=theta^lclip(frac1Tlfloor frac{bm z^lT+bm v^l(0)}{theta^l}rfloor,0,1)-lambda^lclip(frac{1}Llfloorfrac{z^lL}{lambda^l}rfloor,0,1)=0
Errl=ϕl(T)−αl=θlclip(T1⌊θlzlT+vl(0)⌋,0,1)−λlclip(L1⌊λlzlL⌋,0,1)=0
然而实际应用中不能保证T=L,4.2节将介绍如何扩展到T不等于L的时候也使得期望为0
4.2Quantization clip-floor-shift activation function
当ANN使用如下clip-floor-shift激活函数的时候:
α
l
=
h
^
(
z
l
)
=
λ
l
c
l
i
p
(
1
L
⌊
z
l
L
λ
l
+
φ
⌋
,
0
,
1
)
bm alpha^l=hat h(z^l)=lambda^lclip(frac{1}Llfloorfrac{z^lL}{lambda^l}+varphirfloor,0,1)
αl=h^(zl)=λlclip(L1⌊λlzlL+φ⌋,0,1)
有定理2:
当
θ
l
=
λ
l
,
v
l
(
0
)
=
θ
l
φ
theta^l=lambda^l,bm v^l(0)=theta^lvarphi
θl=λl,vl(0)=θlφ的时候,对任意的T,L有
E
z
(
E
r
r
~
)
∣
φ
=
1
2
=
0
E_z(widetilde{Err})|_{varphi=frac12}=0
Ez(Err
)∣φ=21=0:
证明:
引理1:设
x
∈
[
0
,
θ
]
xin[0,theta]
x∈[0,θ]以
p
t
p_t
pt的概率均匀分布在每个
[
m
t
,
m
t
+
1
]
[m_t,m_{t+1}]
[mt,mt+1]的区间内,其中
m
0
=
0
,
m
T
+
1
=
θ
,
m
t
=
(
t
−
1
)
θ
T
,
t
=
1
,
2
,
.
.
.
,
T
,
p
0
=
p
T
m_0=0,m_{T+1}=theta,m_t=frac{(t-1)theta}{T},t=1,2,...,T,p_0=p_T
m0=0,mT+1=θ,mt=T(t−1)θ,t=1,2,...,T,p0=pT。
可以证明
E
x
(
x
−
θ
T
⌊
T
x
θ
+
1
2
⌋
)
=
0
E_x(x-frac theta Tlfloorfrac{Tx}{theta}+frac12rfloor)=0
Ex(x−Tθ⌊θTx+21⌋)=0 (直接通过积分直接证明即可,详见论文)
(正是由于这个引理默认x均匀分布,而实际并非均匀分布,所以最后即使L=T,ANN与SNN的精度仍然存在差异)
由于
E
z
(
E
r
r
~
)
∣
φ
=
1
2
=
E
z
(
θ
l
c
l
i
p
(
1
T
⌊
z
l
T
+
v
l
(
0
)
θ
l
⌋
,
0
,
1
)
−
λ
l
c
l
i
p
(
1
L
⌊
z
l
L
λ
l
+
φ
⌋
,
0
,
1
)
)
E_z(widetilde{Err})|_{varphi=frac12}=E_z(theta^lclip(frac1Tlfloor frac{bm z^lT+bm v^l(0)}{theta^l}rfloor,0,1)-lambda^lclip(frac{1}Llfloorfrac{z^lL}{lambda^l}+varphirfloor,0,1))
Ez(Err
)∣φ=21=Ez(θlclip(T1⌊θlzlT+vl(0)⌋,0,1)−λlclip(L1⌊λlzlL+φ⌋,0,1))
对每个
z
i
z_i
zi有:
E
z
i
(
E
r
r
~
)
∣
φ
=
1
2
=
E
z
i
(
θ
l
T
c
l
i
p
(
⌊
z
i
l
T
+
v
l
(
0
)
θ
l
⌋
,
0
,
1
)
−
λ
l
T
c
l
i
p
(
⌊
z
i
l
L
λ
l
+
φ
i
⌋
,
0
,
1
)
)
=
E
z
i
(
θ
l
T
c
l
i
p
(
⌊
z
i
l
T
+
v
l
(
0
)
θ
l
⌋
,
0
,
1
)
−
z
i
l
)
+
E
z
i
(
z
i
l
−
λ
l
T
c
l
i
p
(
⌊
z
i
l
L
λ
l
+
φ
i
⌋
,
0
,
1
)
)
=
0
+
0
(
由引理
1
)
=
0
begin{aligned} E_{z_i}(widetilde{Err})|_{varphi=frac12}&=E_{z_i}(frac{theta^l}Tclip(lfloor frac{bm {z_i}^lT+bm v^l(0)}{theta^l}rfloor,0,1)-frac{lambda^l}Tclip(lfloorfrac{{z_i}^lL}{lambda^l}+varphi_irfloor,0,1))\ &=E_{z_i}(frac{theta^l}Tclip(lfloorfrac{bm {z_i}^lT+bm v^l(0)}{theta^l}rfloor,0,1)-z_i^l)+E_{z_i}(z_i^l-frac{lambda^l}Tclip(lfloorfrac{{z_i}^lL}{lambda^l}+varphi_irfloor,0,1))\ &=0+0(由引理1)\&=0\ end{aligned}
Ezi(Err
)∣φ=21=Ezi(Tθlclip(⌊θlzilT+vl(0)⌋,0,1)−Tλlclip(⌊λlzilL+φi⌋,0,1))=Ezi(Tθlclip(⌊θlzilT+vl(0)⌋,0,1)−zil)+Ezi(zil−Tλlclip(⌊λlzilL+φi⌋,0,1))=0+0(由引理1)=0
这样便有了对任意T,L的都可以使得转换误差的期望为0的激活函数以及转换方法
4.3 Algorithm for training quantization clip-floor-shift activation function
使用随机梯度下降法以转换误差为代价函数,学习
W
l
bm W^l
Wl(由zl得到)和
λ
l
lambda^l
λl参数
其中
∂
h
^
i
(
z
l
)
∂
z
i
l
=
{
1
i
f
−
λ
l
2
L
<
z
i
l
<
λ
l
−
λ
l
2
L
0
o
t
h
e
r
w
i
s
e
frac{partial hat h_i(bm z^l)}{partial z_i^l}=left {begin{aligned} 1 quad &if quad-frac{lambda^l}{2L}<z_i^l<lambda^l-frac{lambda^l}{2L}\ 0 quad &otherwise\ end{aligned}right.
∂zil∂h^i(zl)=⎩
⎨
⎧10if−2Lλl<zil<λl−2Lλlotherwise
∂
h
^
i
(
z
l
)
∂
λ
i
l
=
{
1
2
L
i
f
−
λ
l
2
L
<
z
i
l
<
λ
l
−
λ
l
2
L
−
z
i
l
(
λ
l
)
2
o
t
h
e
r
w
i
s
e
frac{partial hat h_i(bm z^l)}{partial lambda_i^l}=left {begin{aligned} frac1{2L} quad &if quad-frac{lambda^l}{2L}<z_i^l<lambda^l-frac{lambda^l}{2L}\ -frac{z_i^l}{(lambda^l)^2} quad &otherwise\ end{aligned}right.
∂λil∂h^i(zl)=⎩
⎨
⎧2L1−(λl)2zilif−2Lλl<zil<λl−2Lλlotherwise
5.Related work
由于该内容较少且不是论文重点,这里便不详细进行阐述。
6.Experiments
这篇论文在CIFAR-10、CIFAR-100以及ImageNet数据集上进行了实验,验证了该方法的有效性,并且与世界最先进的方法进行了比较。
6.1 比较ANN使用Relu、clip-floor与clip-floor-shift的表现

其中顶端虚线是使用Relu作为激活函数的ANN的准确率,绿色和蓝色的实线分别是使用clip-floor和clip-floor-shift作为ANN的准确率随量化间距L变化的函数函数。可以看出在L>4时都已经非常接近甚至超越Relu的准确率,由此可见使用该函数不会对性能造成较大影响。
6.2和世界最先进的方法比较
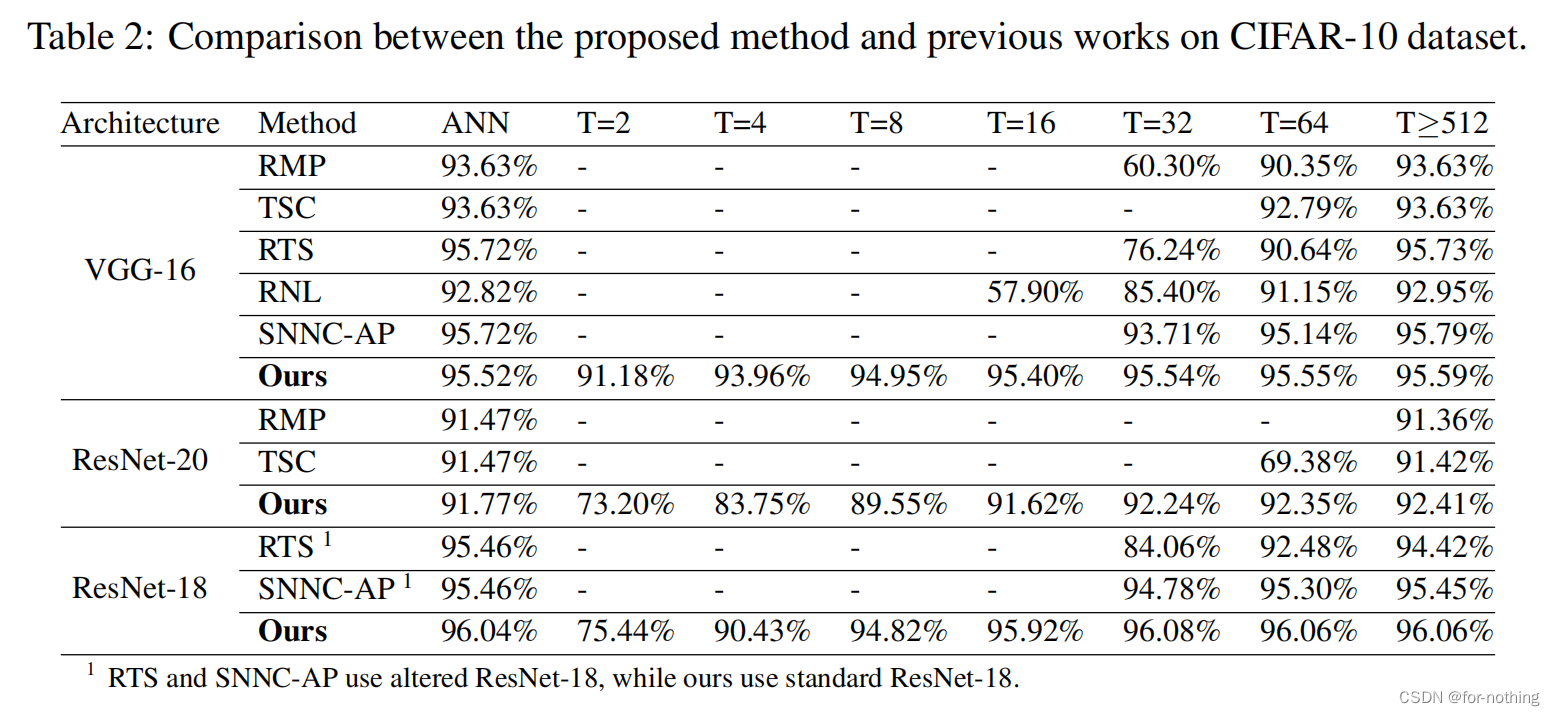
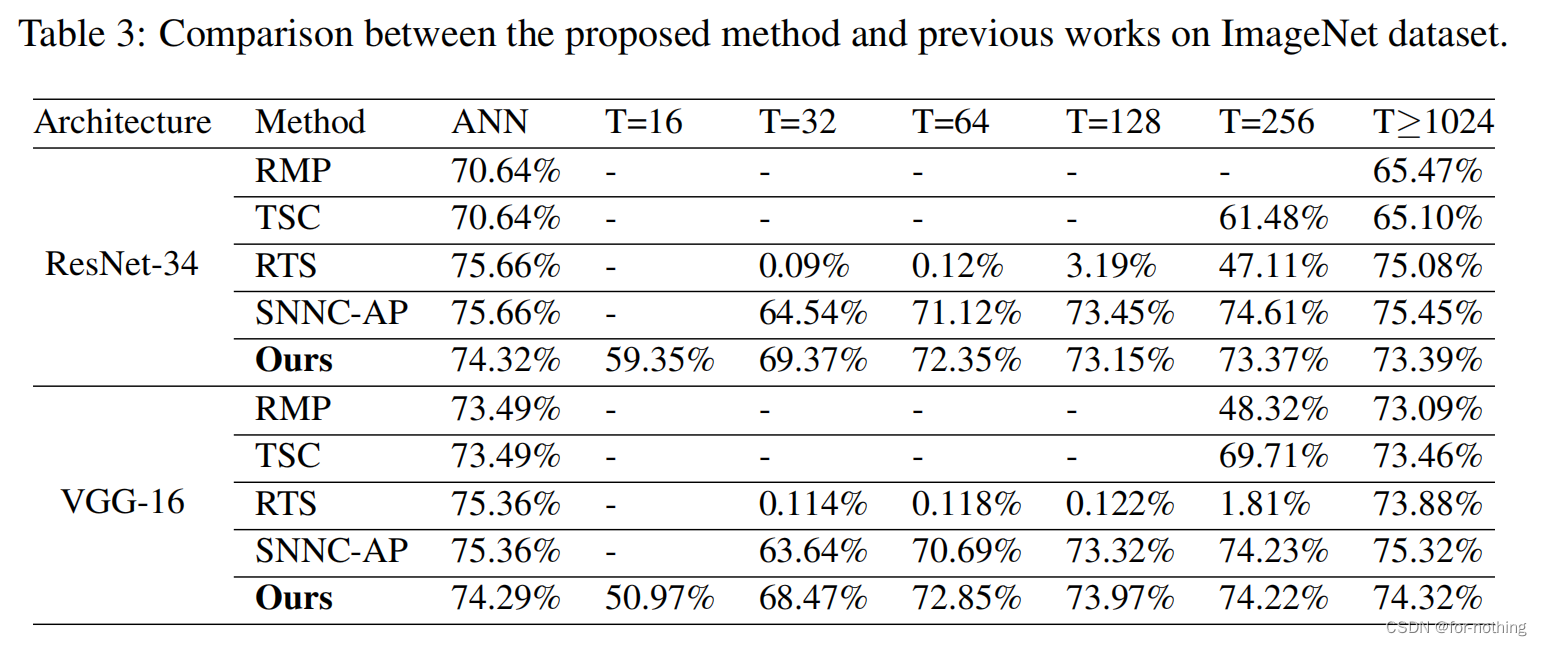
AN那一列指的是是ANN各个算法的ANN的准确率,后面的每一列指的是采用不同的时间步长下ANN转换为SNN之后的准确率,可以看出这篇论文的方法相比于其他方法可以在更短的时间内快速完成高准确率的转换。
6.3比较ANN转换得到的SNN使用clip-floor与clip-floor-shift的表现
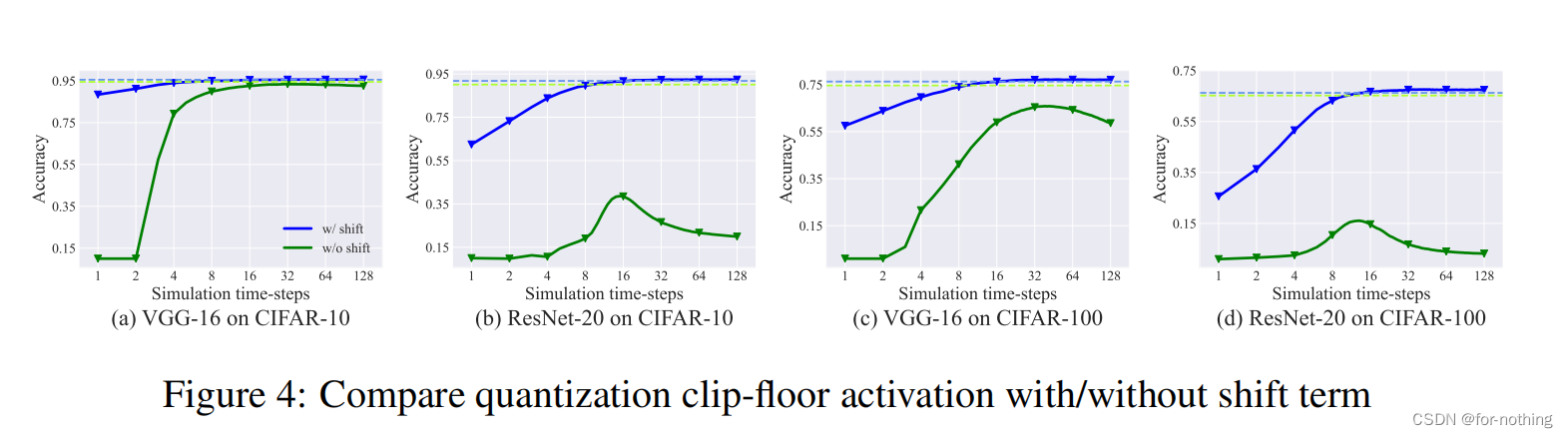
其中顶端虚线是该方法使用的ANN转换得到SNN的最高准确率,绿色和蓝色的实线分别是使用clip-floor和clip-floor-shift作为ANN转换得到的SNN的准确率随时间步长T变化的函数函数(量化步长L取固定值4)。
可以看出随着T的增大clip-floor-shift的性能逐渐接近于最优性能,符合clip-floor-shift期望误差为0的理论。
6.4比较量化步长L对实验结果的影响
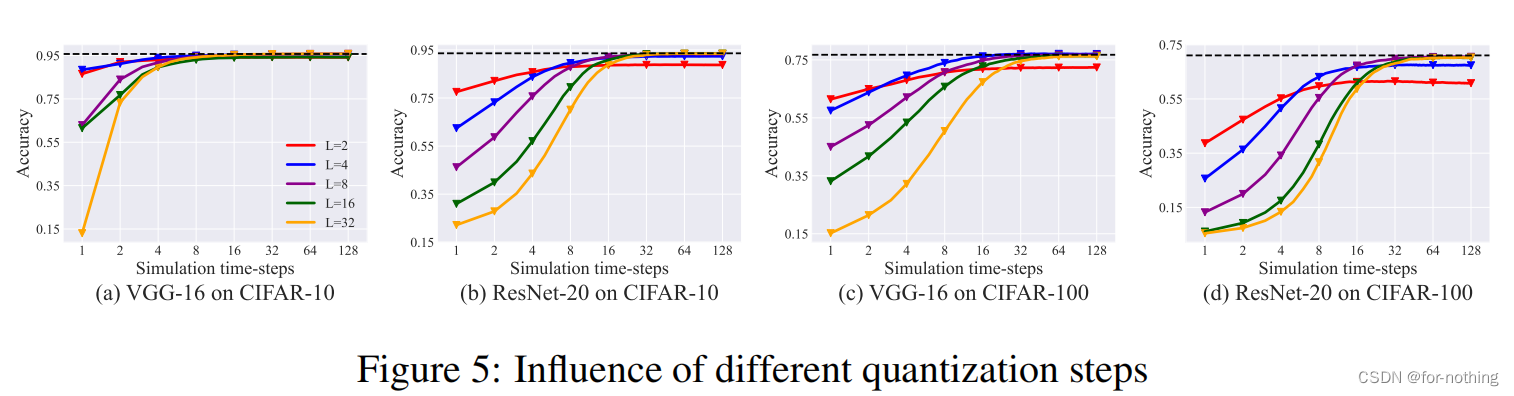
可以看出如果量化步长L取得太小,虽然可以使用较短的时间步长T取得较高的转化结果,但是继续增加T也难以达到的与最优准确率接近的结果。如果量化步长L取得太大,则需要较大的时间步长T才可以使其准确率接近最优准确率。所以综合考虑要取一个适中的L值,一般取4或者8。
7.Discussion and conclusion
优点:这篇论文提出了clip-floor-shift 激活函数代替Relu用于ANN的训练,这样训练出来的ANN可以在快速转换为SNN的同时保持有较高的准确率。这样转换得到SNN相比原先的ANN具有相当的性能却只需要更少的计算成本。
值得深究之处:1.由于均匀误差的存在使得ANN与SNN的准确率始终存在差距。2.当时间步长为1的时候很难实现高性能转换。
此外,论文附录中的证明相关内容已经结合在上述部分中进行了介绍,附录中的其余实验结果这里详细阐述了。
最后
以上就是秀丽白云最近收集整理的关于Optimal ANN-SNN Conversion for High-accuracy and Ultra-low-latency Spiking Neural Networks 阅读总结运行结果演示Abstract1.Introduction2.Preliminaries3.Conversion error analysis4.Optimal ANN-SNN conversion5.Related work6.Experiments7.Discussion and conclusion的全部内容,更多相关Optimal内容请搜索靠谱客的其他文章。








发表评论 取消回复