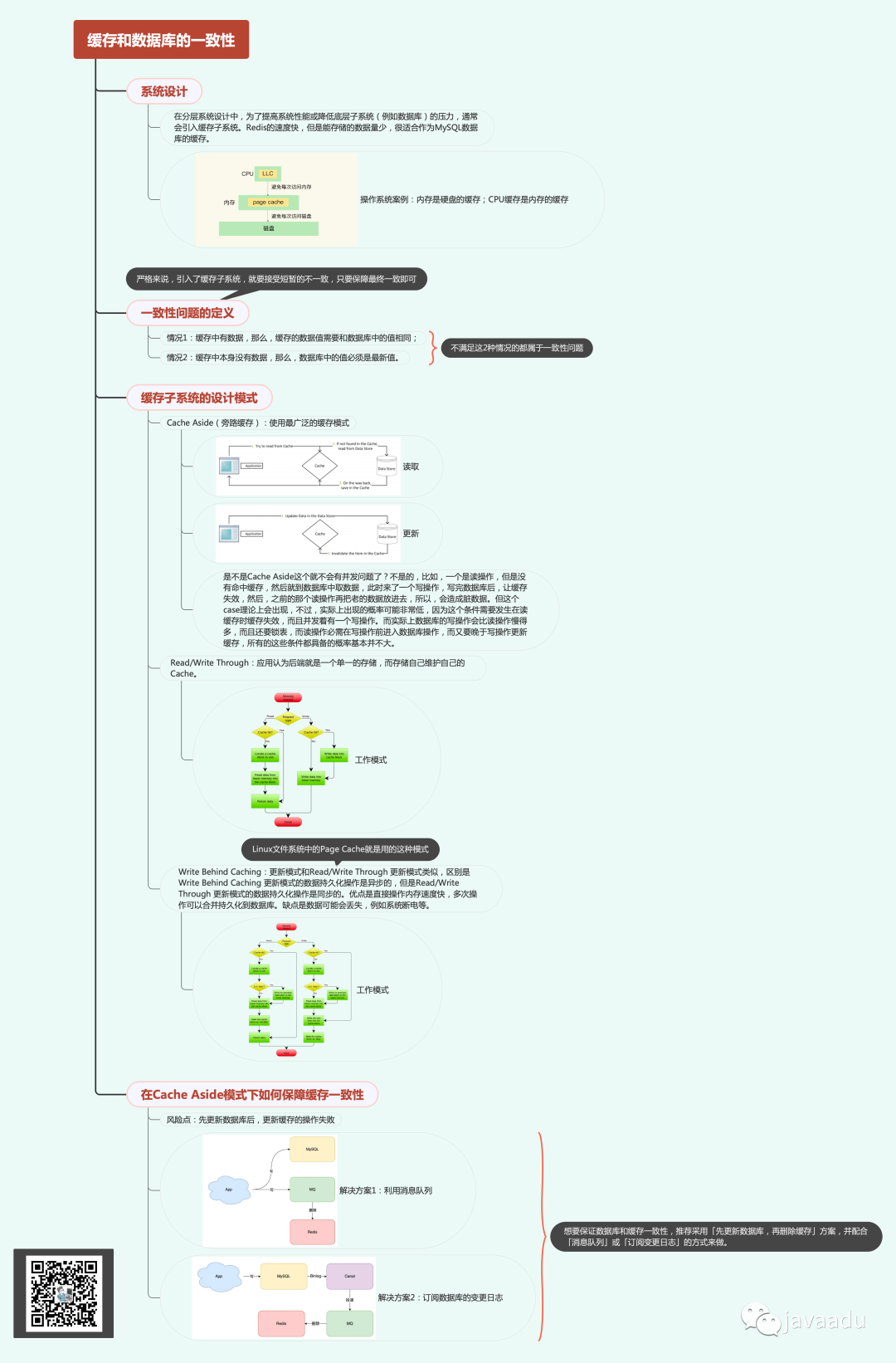
缓存的作用
在大型软件系统的构建中,分层是一种很好的设计思路,我们通过抽象思维,将同一个抽象层次的概念放在同一层次交互,上层以来下层的接口,下层对上层隐藏复杂的实现细节。操作系统、rpc框架、大型应用系统都有类似的分层的概念在里面。
操作系统中的缓存应用
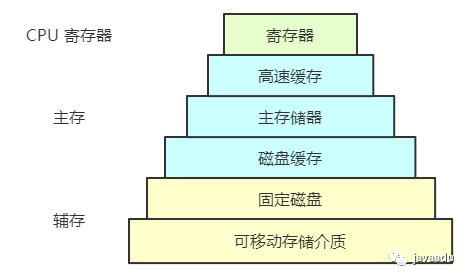
不同的存储介质的存储容量和存取速度是各不相同的,在操作系统的存储架构中,从CPU寄存器到外部磁盘存储,存取速度逐步降低,但是存储容量逐步上升。在这个体系中,高速缓存是内存在CPU侧的缓存,磁盘缓存是磁盘在内存侧的缓存。
分布式系统中的缓存架构
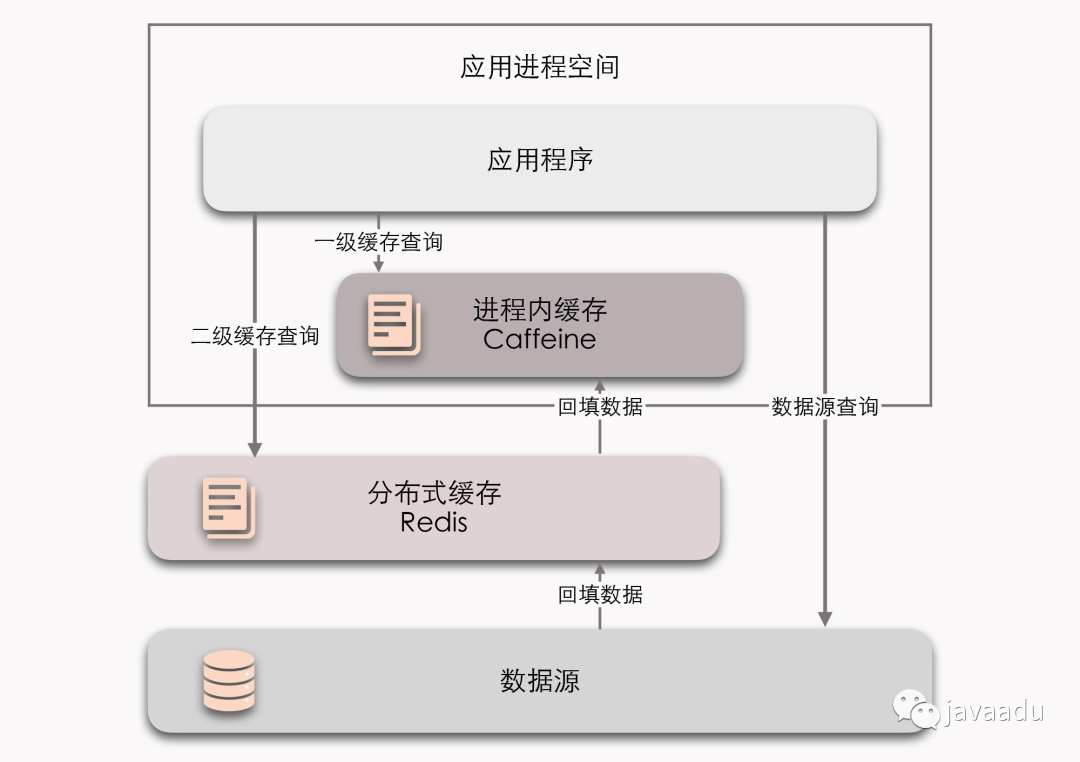
同样的思想,也用在了电商、游戏、云计算等分布式系统中,对于那些高并发、高性能读取要求的业务功能,我们会将这些数据(商品、属性等等)放到不同层级的缓存中。下面这个体系中,进程内存作为分布式缓存的缓存,分布式缓存作为MySQL数据源的缓存。
缓存的设计模式
一般来说,如果没有必要,我们是不会引入缓存的,引入缓存之后,我们就需要考虑缓存的更新模式,以及缓存的数据一致性问题。更新缓存的的设计有四种:Cache aside, Read through, Write through, Write behind caching,我们一一看下。
Cache Aside(旁路缓存)
如果缓存存储器没有提供原生的写直通或读直通能力,并且我们也不清楚需要将哪些数据存入缓存,希望能够根据应用的需要(时间或空间局部性)来缓存数据,则比较适合用这种模式。整个业务逻辑没有缓存也可以完成,无非就是效率低一些,旁路缓存的作用就是用来提效。
读取:如果缓存命中则直接返回,如果没有则从数据库中读取,并且将读取的数据写回缓存。
更新:先更新数据库,再删除缓存。
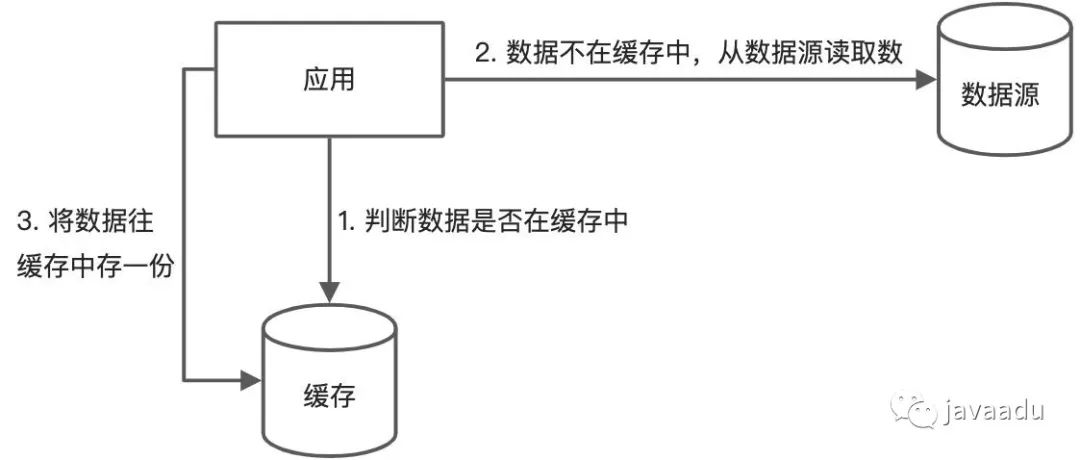
旁路缓存中的缓存和数据源是两个不同的实体,因此存在一致性问题,为了降低数据不一致的概率,我们讨论下集中更新数据时候的模式:
“先更新数据库,再更新缓存”是有问题的,在并发写的情况下会导致缓存中存在脏数据,缓存和DB存在不一致的数据
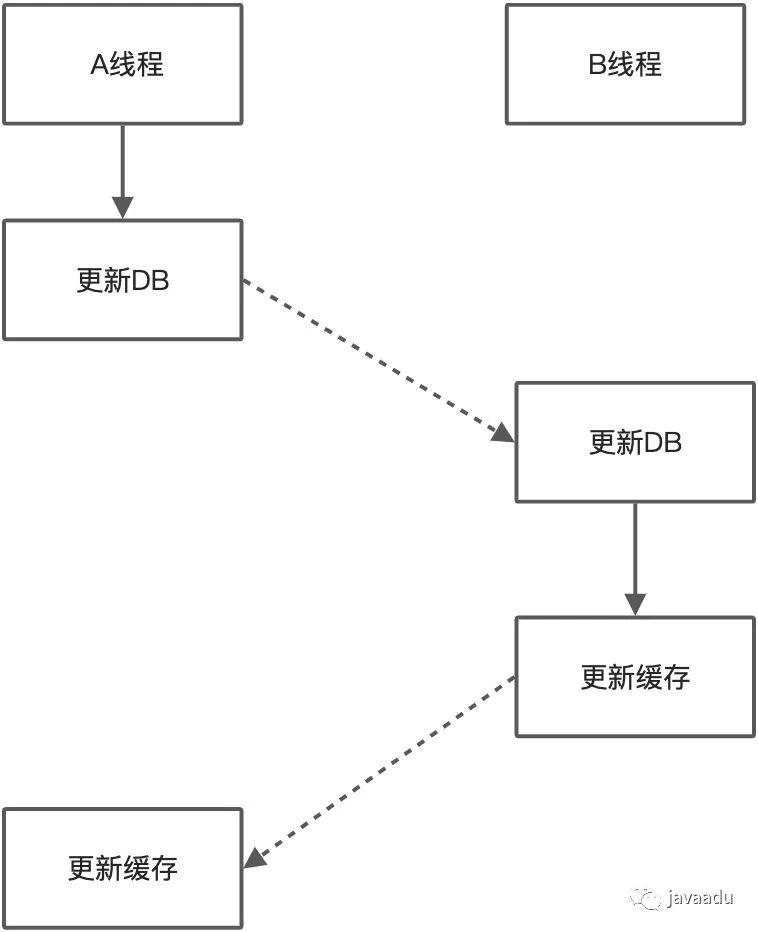
“先更新缓存,再更新数据库”也是有问题的,在并发写情况下可能会导致缓存中存在脏数据,缓存和DB存在不一致的数据
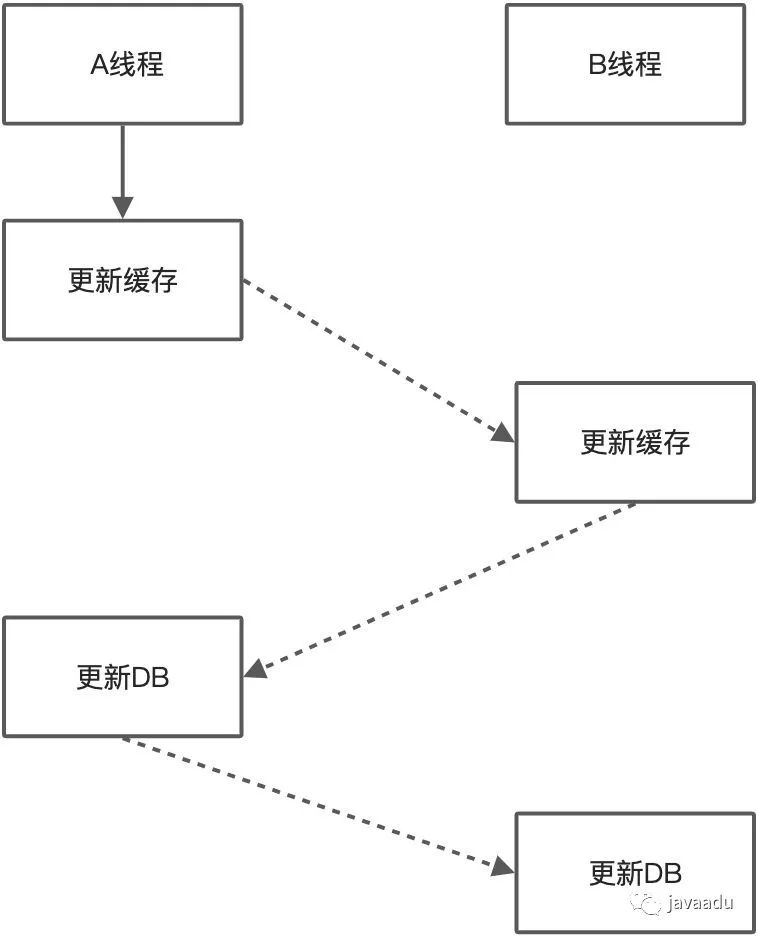
“先更新数据库,再删除缓存”是不是就没问题呢?理论上,可能出现一种情况,A线程读取缓存未命中,然后去读数据库,这时候读到老的数据,同时一个B线程去更新数据库,更新完后还要将缓存失效,然后A线程读到老的数据并将其放入缓存,造成脏数据,但在实际中这种情况的概率极低——要求读取数据库的操作慢于写数据的操作,因此,标准的做法就是“先更新数据库,再失效缓存”,如果担心操作缓存失败,则可以将缓存设计一个过期时间,或者进行同步重试或异步重试。
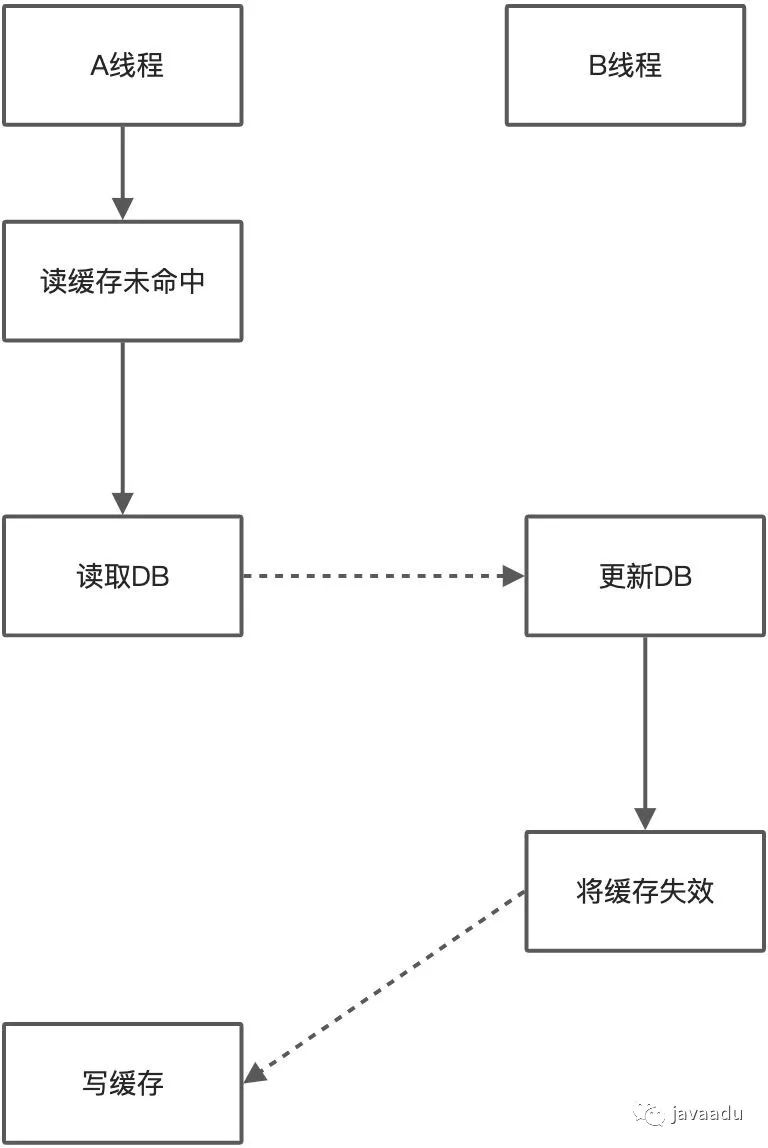
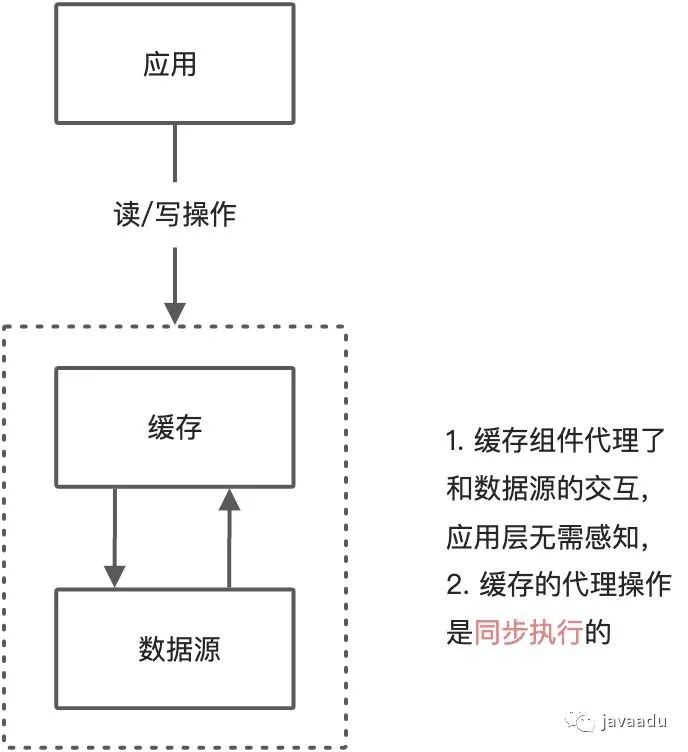
Read/Write Through(读/写直通)
在上面的 Cache Aside 更新模式中,应用代码需要维护两个数据存储,一个是缓存(Cache),一个是数据库(Repository)。而在Read/Write Through 更新模式中,应用程序只需要维护缓存,数据库的维护工作由缓存代理了。
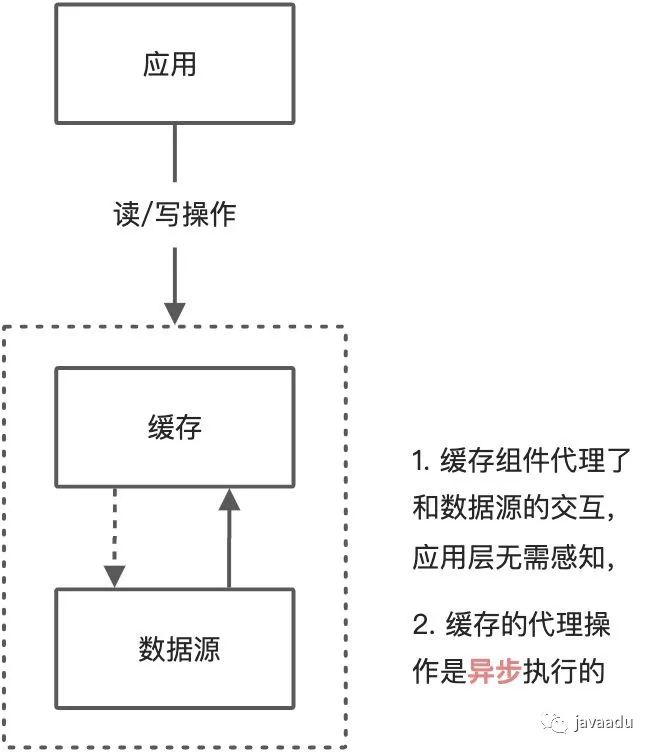
Write Behind Cache
Write Behind Caching 更新模式和Read/Write Through 更新模式类似,区别是Write Behind Caching 更新模式的数据持久化操作是异步的,但是Read/Write Through 更新模式的数据持久化操作是同步的。Linux中的文件系统里的Page Cache算法,使用的就是Write Behind Cache模式。
优点:直接操作内存速度快,多次操作可以合并持久化到数据库。
缺点:数据可能会丢失,例如系统断电等。
参考资料
https://coolshell.cn/articles/17416.html
https://mp.weixin.qq.com/s/4W7vmICGx6a_WX701zxgPQ
知识卡片
最后
以上就是精明枕头最近收集整理的关于Redis的缓存应用——缓存模式和一致性问题的全部内容,更多相关Redis内容请搜索靠谱客的其他文章。








发表评论 取消回复