
作者:mrguozp
https://www.cnblogs.com/guozp/p/10597327.html
基础
内存泄露(Memory Leak)
java中内存都是由jvm管理,垃圾回收由gc负责,所以一般情况下不会出现内存泄露问题,所以容易被大家忽略。
内存泄漏是指无用对象(不再使用的对象)持续占有内存或无用对象的内存得不到及时释放,从而造成内存空间的浪费称为内存泄漏。内存泄露有时不严重且不易察觉,这样开发者就不知道存在内存泄露,需要自主观察,比较严重的时候,没有内存可以分配,直接oom。
主要和溢出做区分。
内存泄露现象
heap或者perm/metaspace区不断增长, 没有下降趋势, 最后不断触发FullGC, 甚至crash.
如果低频应用,可能不易发现,但是最终情况还是和上述描述一致,内存一致增长
perm/metaspace泄露
这里存放class,method相关对象,以及运行时常量对象. 如果一个应用加载了大量的class, 那么Perm区存储的信息一般会比较大.另外大量的intern String对象也会导致该区不断增长。
比较常见的一个是Groovy动态编译class造成泄露。这里就不展开了
heap泄露
比较常见的内存泄露
静态集合类引起内存泄露
监听器:但往往在释放对象的时候却没有记住去删除这些监听器,从而增加了内存泄漏的机会。
各种连接,数据库、网络、IO等
内部类和外部模块等的引用:内部类的引用是比较容易遗忘的一种,而且一旦没释放可能导致一系列的后继类对象没有释放。非静态内部类的对象会隐式强引用其外围对象,所以在内部类未释放时,外围对象也不会被释放,从而造成内存泄漏
单例模式:不正确使用单例模式是引起内存泄露的一个常见问题,单例对象在被初始化后将在JVM的整个生命周期中存在(以静态变量的方式),如果单例对象持有外部对象的引用,那么这个外部对象将不能被jvm正常回收,导致内存泄露
其它第三方类
本例(线程泄露)
本例现象
内存占用率达80%+左右,并且持续上涨,最高点到94%
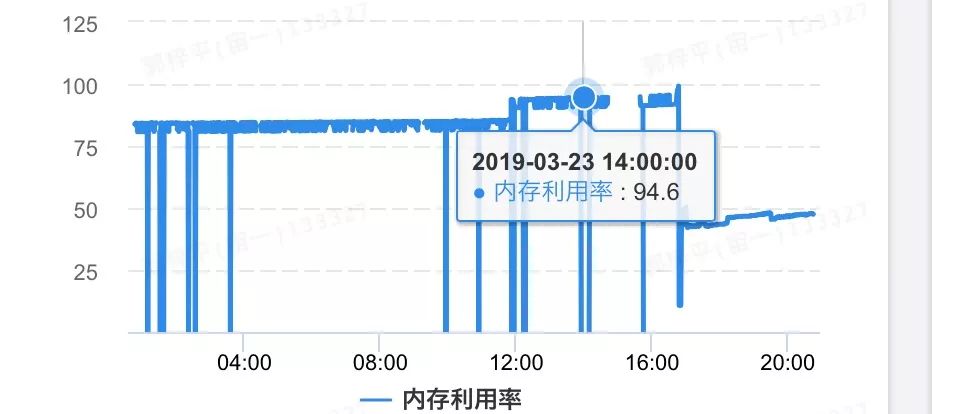
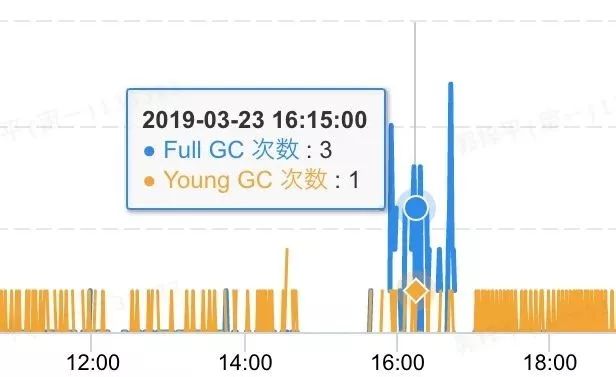
yongGC比较频繁,在内存比较高的时候,伴有FullGC
线程个个数比较多,最高点达到2w+(这个比较重要,可惜是后面才去关注这点)

日志伴有大量异常,主要是三类
fastJosn error

调用翻译接口识别语种服务错误
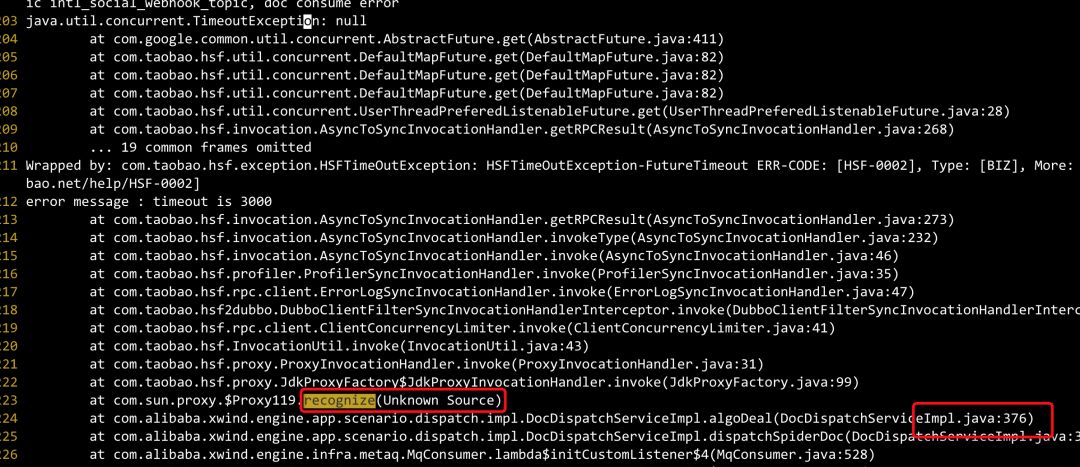

对接算法提供的二方包请求错误

刚开始走的错误弯路
刚开始发现机器内存占用比较多,超过80%+,这个时候思考和内存相关的逻辑
这个时候并没有去观察线程数量,根据现象 1、2、4,这个过程没有发现现象3,排查无果后,重新定位问题发现现象3
由于现象4中的错误日志比较多,加上内存占用高,产生了如下想法(由于本例中很多服务通过mq消费开始)
现象4中的错误导致mq重试队列任务增加,积压的消息导致mq消费队列任务增加,最终导致内存上升
由于异常,逻辑代码中的异常重试线程池中的任务增加,最终导致任务队列的长度一直增加,导致内存上升
解决弯路中的疑惑
定位异常
fastJson解析异常,光看错误会觉得踩到了fastJson的bug(fastJson在之前的版本中,写入Long类型到Map中,在解析的时候默认是用Int解析器解析,导致溢出错误。但是这个bug在后面的版本修复了,目前即使是放入Long类型,如果小于int极限值,默认是int解析,超过int极限,默认long。类中的变量为Long。直接parse,直接为Long类型),但是业务代码中使用的是类直接parse,发现二方包中的类使用了int,但是消息值有的超过int值
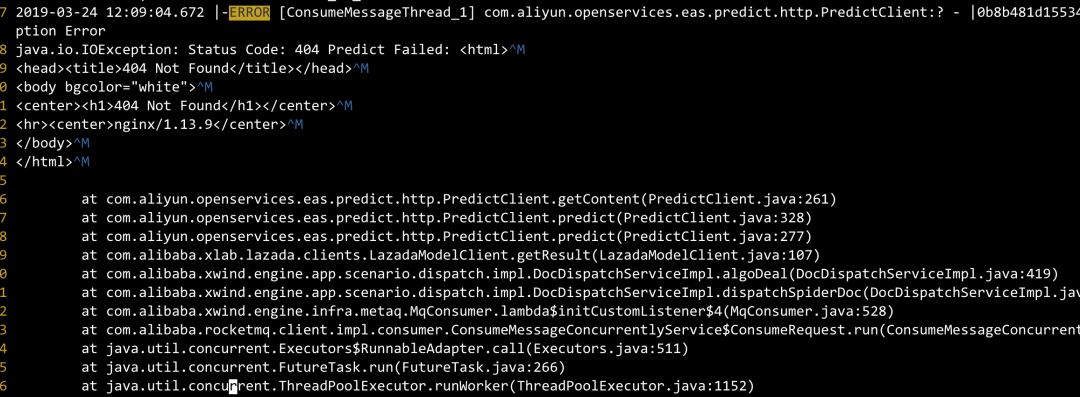
eas算法链路调用错误,之前就有(404),但是没有定位到具体原因,有知道的望指点下,这里用try catch做了处理
翻译服务异常,这里没定位到具体原因,重启应用后恢复,这里忘记了做try catch,看来依赖外部服务需要全部try下
确认是否是业务逻辑中错误重试队列问题
否,和业务相关才会走入重试流程,还在后面
确认是否是Mq消息队列积压,以及Mq重试队列消息积压导致,确认是否是线程自动调整(metaq/rocketmq)
否,Mq做了消费队列安全保护
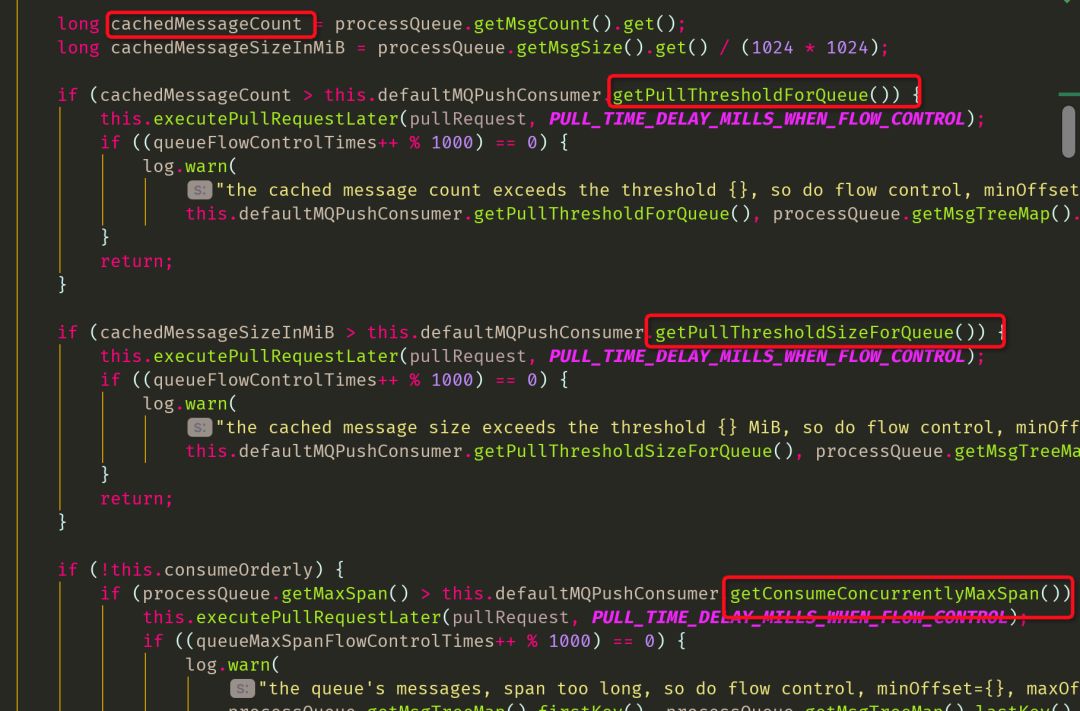
consumer异步拉取broker中的消息,processQueue中消息过多就会控制拉取的速率。对于并发的处理场景, 存在三种控制的策略:
1. queue中的个数是否超过1000
2. 估算msg占用的内存大小是否超过100MB
3. queue中仍然存在的msg(多半是消费失败的,且回馈broker失败的)的offset的间隔,过大可能表示会有更多的重复,默认最大间隔是2000。流控源码类:com.alibaba.rocketmq.client.impl.consumer.DefaultMQPushConsumerImpl#pullMessage,圈中的变量在默认的类中都有初始值
metaq也会自己做动态线程调整,理论上当线程不够用时,增加线程,adjustThreadPoolNumsThreshold默认值10w,当线程比较多时,减少线程,但是代码被注释了,理论上应该没有自动调整过程,所以这里也不会因为任务过多增加过多线程
在start启动的时候,启动了一批定时任务
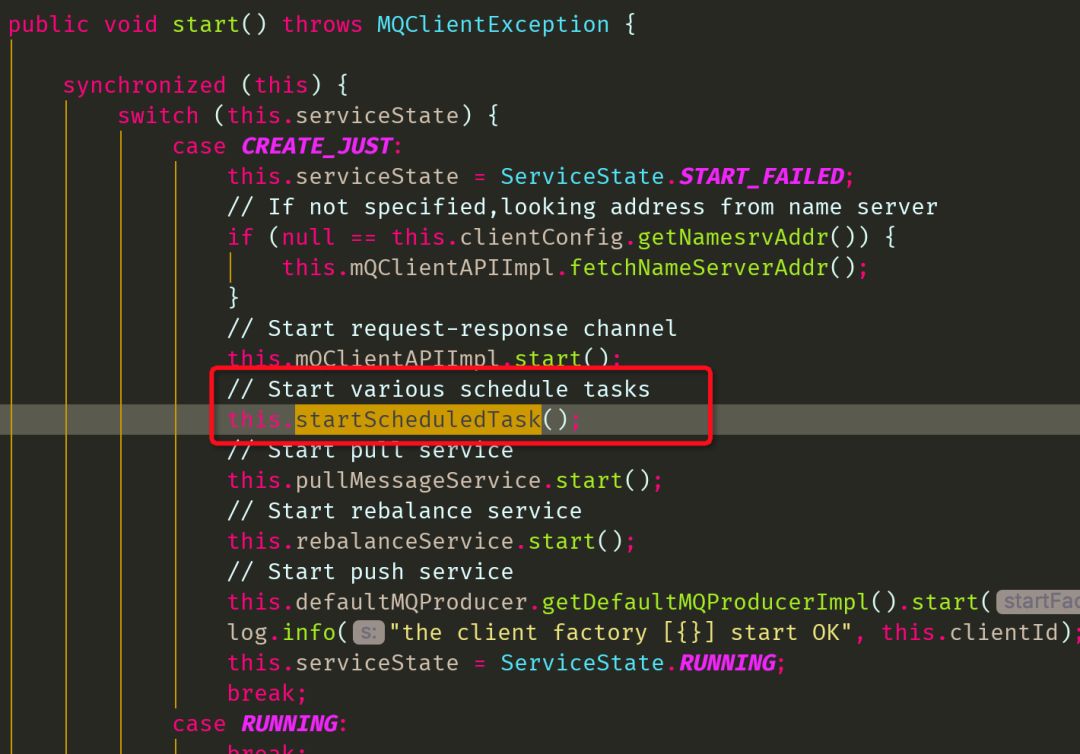
定时任务中启动了调整线程的定时任务
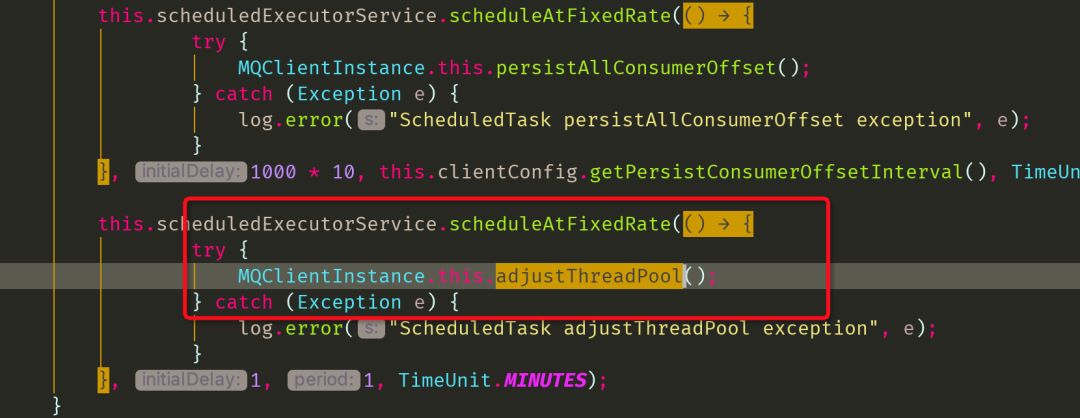
启动调整任务
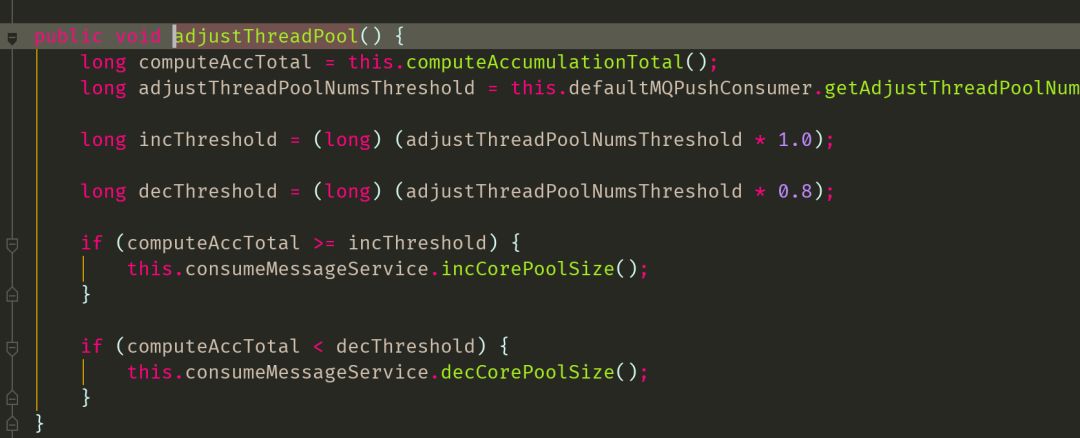
回归正途的处理逻辑
经过上述分析,发现并不是因为异常导致的任务队列增加过多导致,这个时候,发现了现象3,活动线程数明显过多,肯定是线程泄露,gc不能回收,导致内存一直在增长,所以到这里,基本上就已经确认是问题由什么导致,接下来要做的就是确认是这个原因导致,以及定位到具体的代码块
如果没有具体的监控,一般就是看机器内存状况,cpu,以及jvm的heap,gc,有明显线程状况的,可jstack相关线程等,最终依然无法定位到具体代码块的可以dump后分析
登录涉事机器
top,观察内存占用率(这里图是重启之后一段时间的)但是cpu占用率比较高,很快就降下去了,这里耽误了一下时间,top -Hp pid,确认那个线程占用率高,jstack看了下对应的线程在作甚
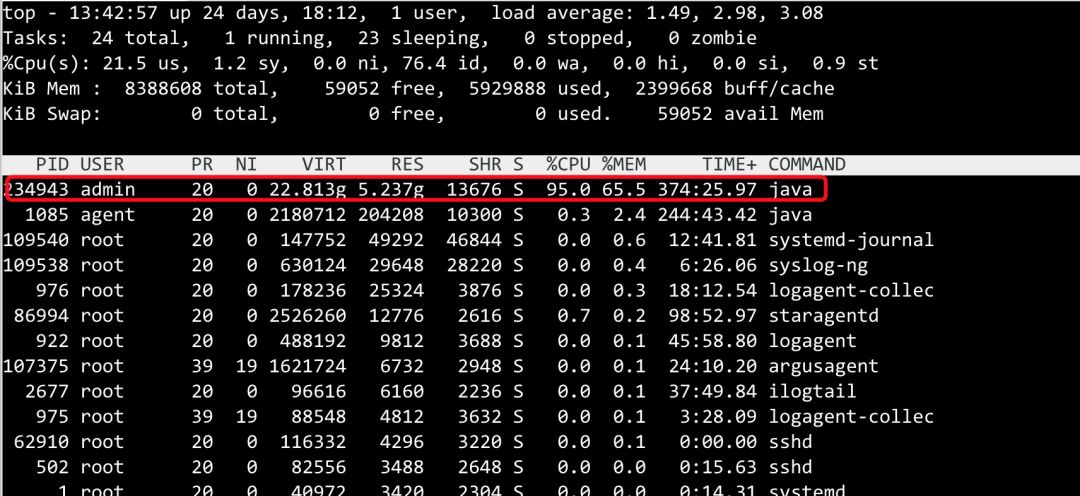
确认线程是否指定大小,未发现指定,使用的默认值大小

查看heap,gc状况
查看线程状况,可jstack线程,发现线程较多,也能定位到,但是为了方便,遂dump一份数据详细观察堆栈
a.线程个数
cat /proc/{pid}/status (线程数竟然这么多)
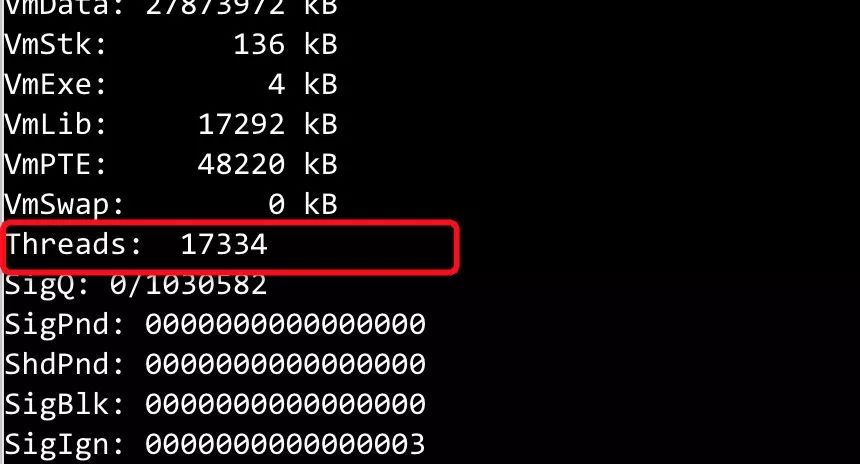
由于线程数比较多,而依然可以创建,查看Linux普通用户所允许创建的进程数,使用命令:cat /etc/security/limits.d/90-nproc.conf ,值比较到,远超当前的个数
b.线程信息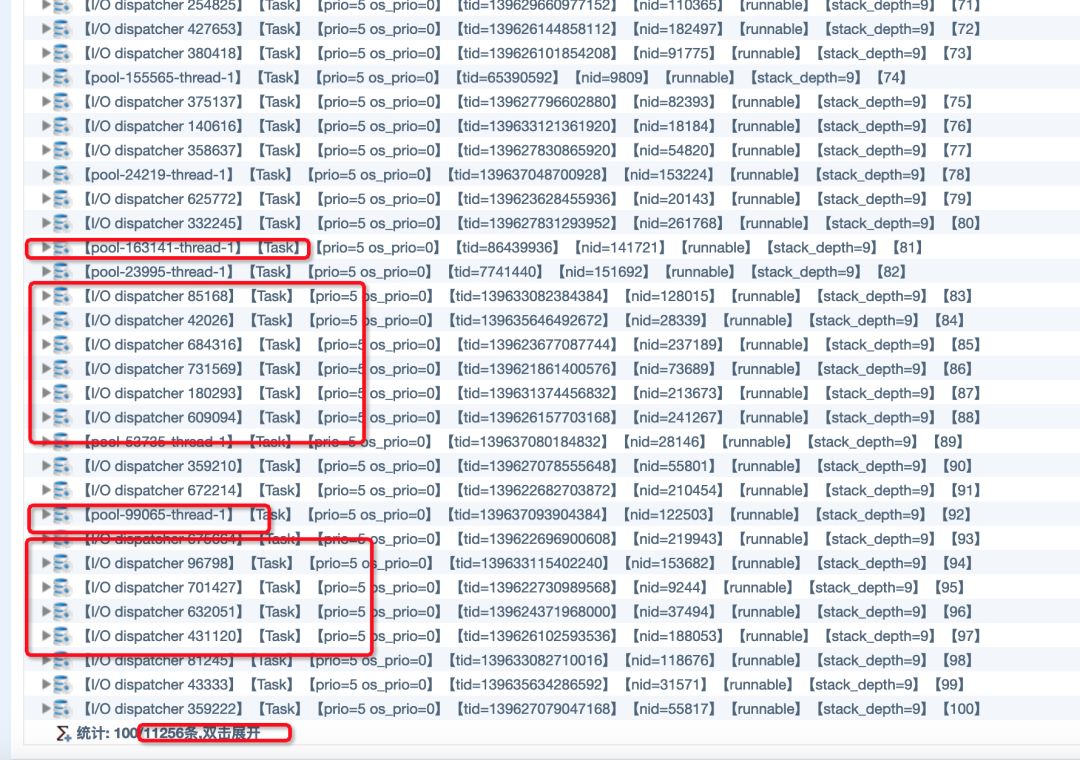
c.线程状态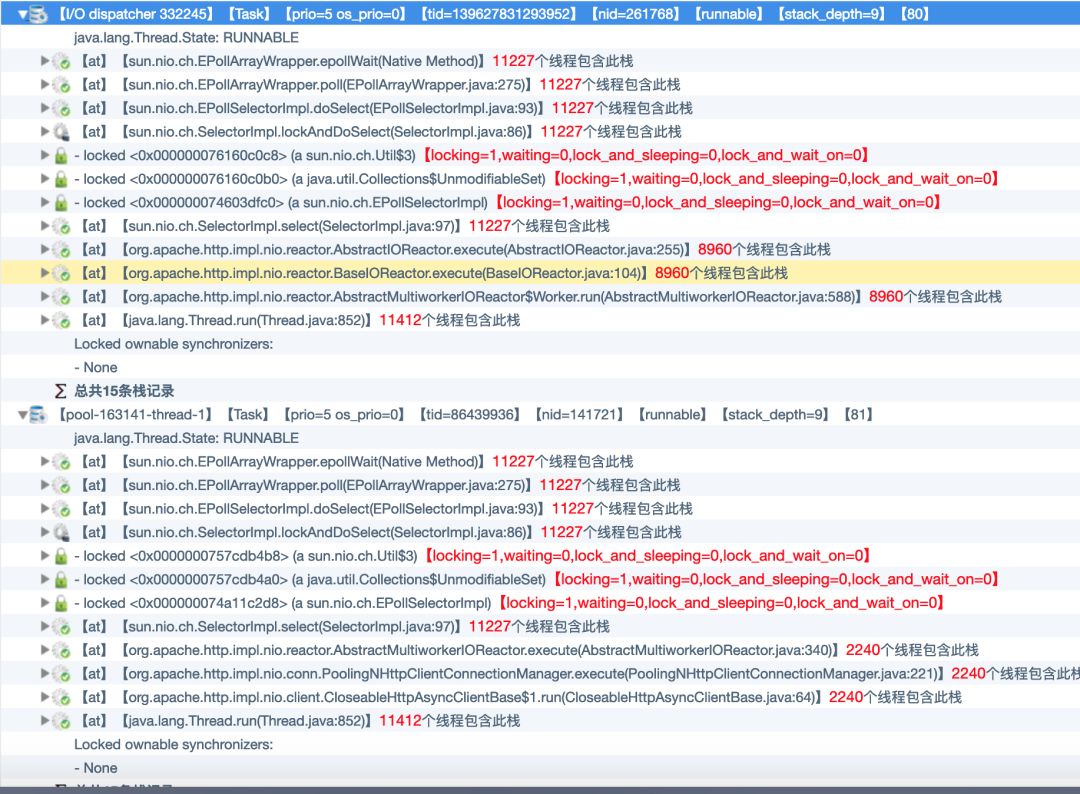
d.定位到问题线程
AbstractMultiworkerIOReactor ==》 httpAsycClient ==》如图所示不能直接定位到代码块,所以maven定位引用jar的服务 ==> 具体二方包
如果每次都new线程而不结束,gc中线程是root节点,如果线程没有结束,不会被回收,所以如果创建大量运行的线程,会导致内存占用量上升,但是线上到底能创建多少线程呢?
问题代码块
方法开始(每次都初始化一个新的客户端,底层封装使用httpAsyncClient,httpAsyncClient使用NIO模型,初始化包含一个boss,10个work线程)
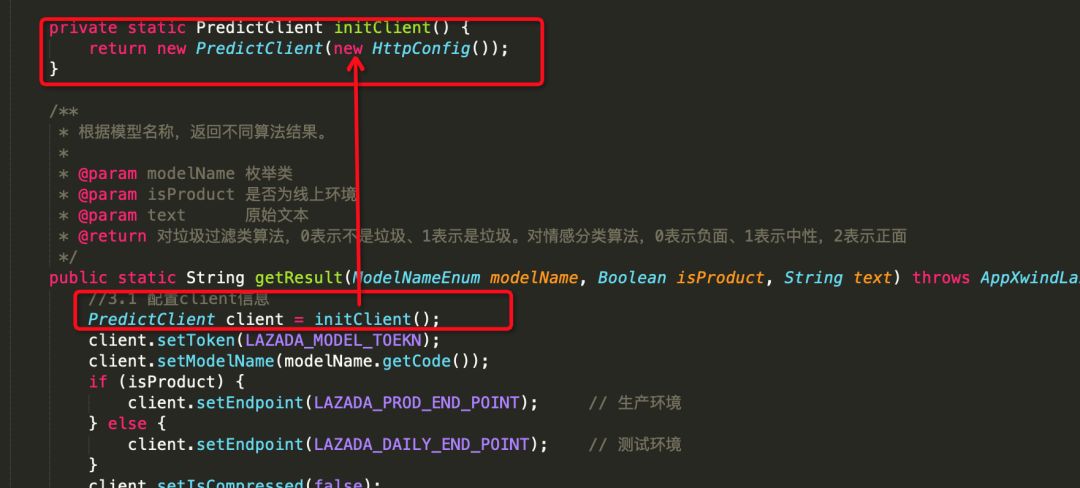
方法结束(方法结束都调用了shutdow)
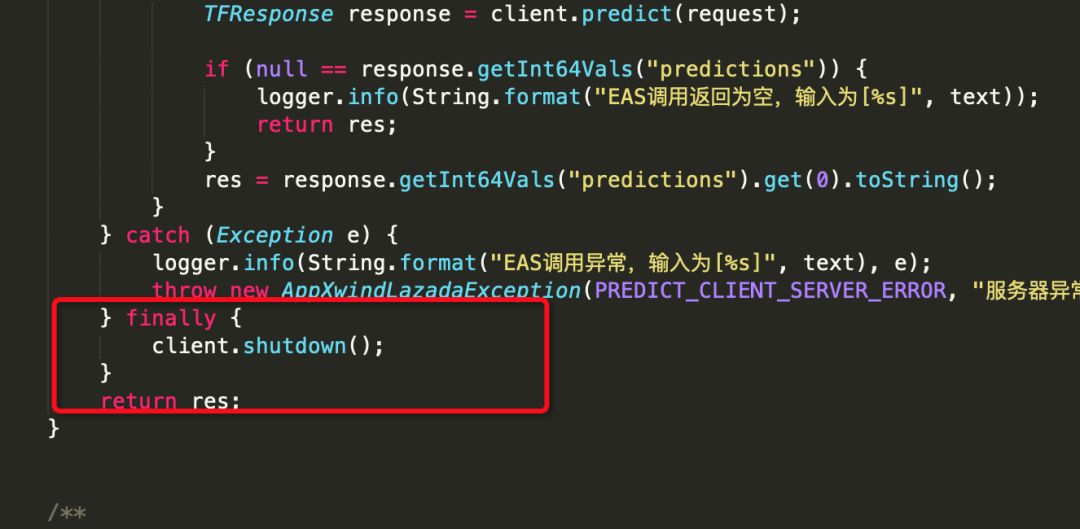
根据现象和对应线程堆栈信息,能确定线程就是在这边溢出,客户端的shutDown方法关闭线程池失效,导致由于初始的线程都是NIO模式,没有被结束,所以线程一直积压增加,可修改为单例模式,限制系统使用一个线程池,上线后解决问题
httpAsyncClient 部分源码解析
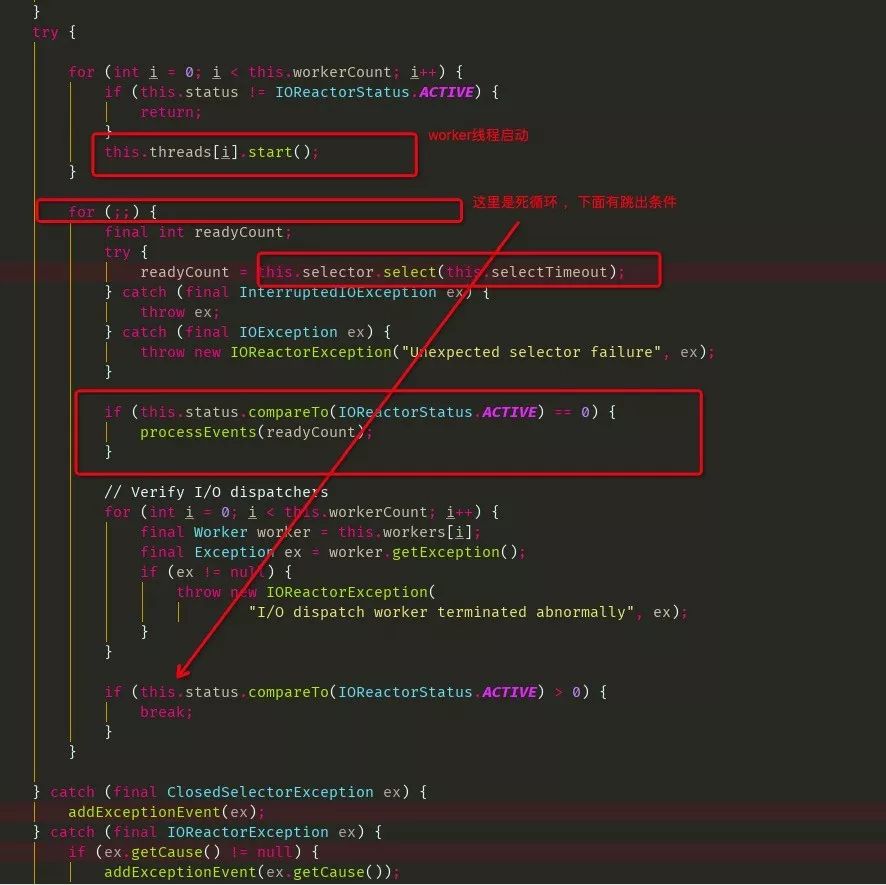
启动
a.Reactor Thread 负责 connect
Worker Thread 负责 read write
常驻线程
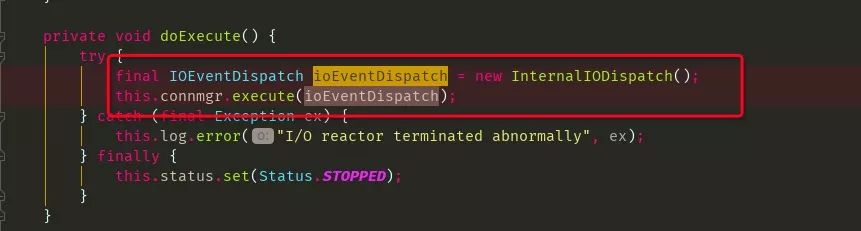
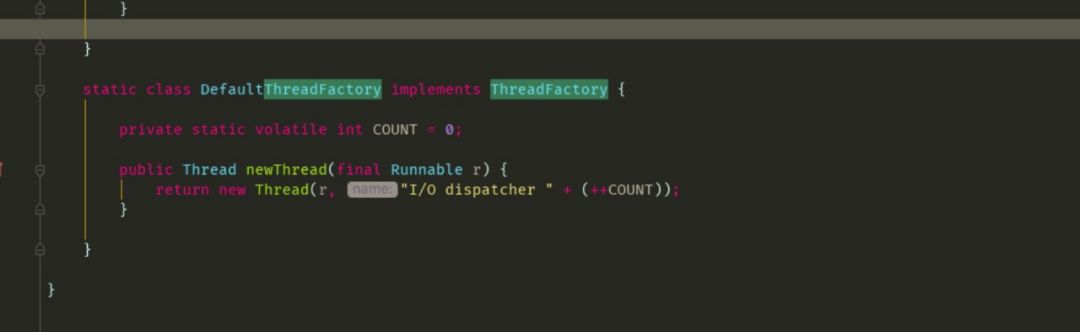
b.线程池命名,也就是上面出现pool--thread-的线程
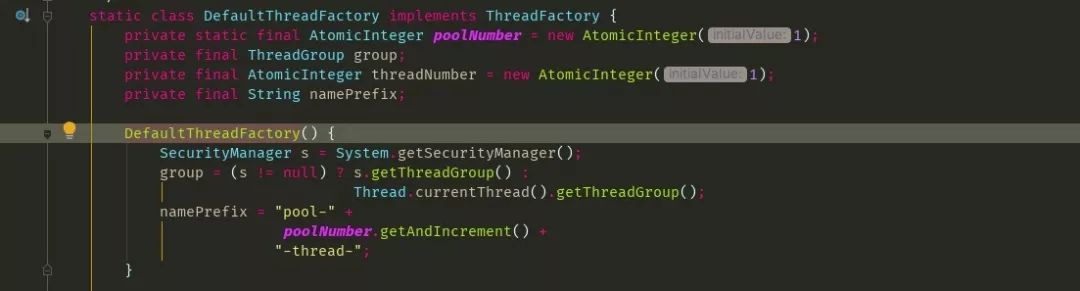
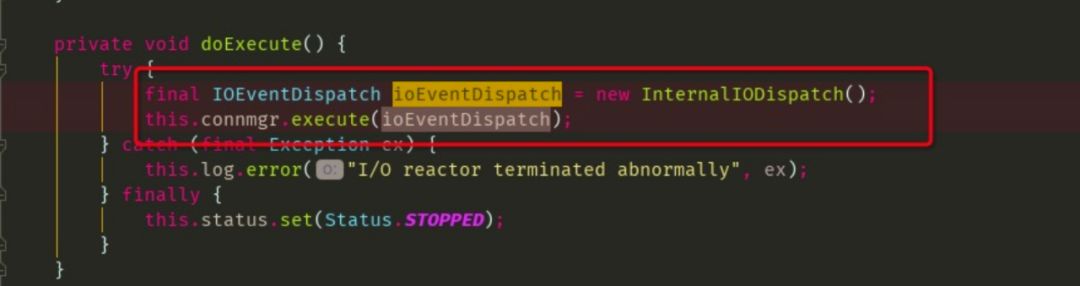
c.ioEventDispatch 线程
启动
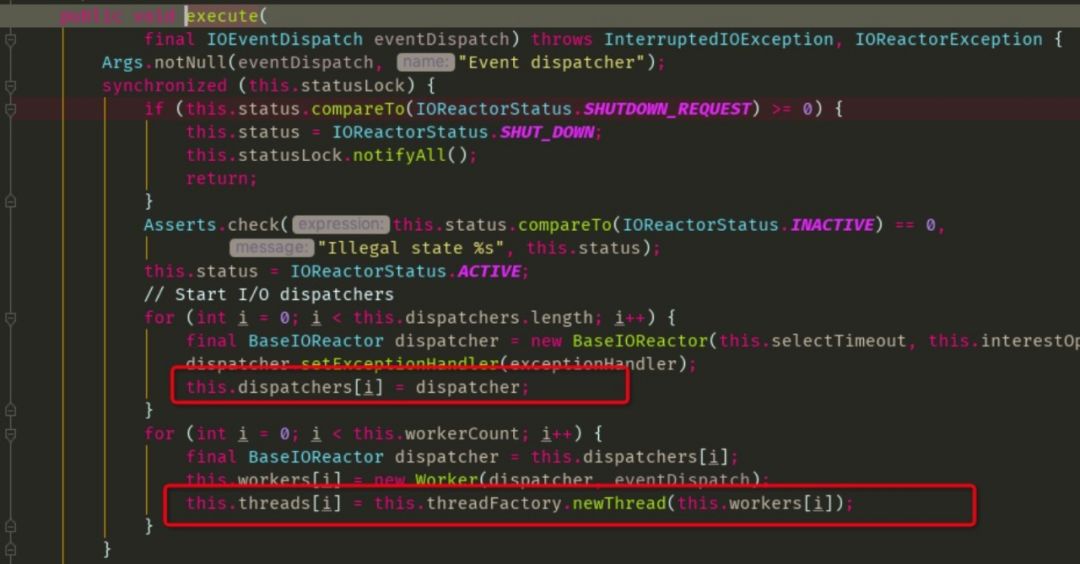
worker线程
worker线程名称
IO worker运行详细
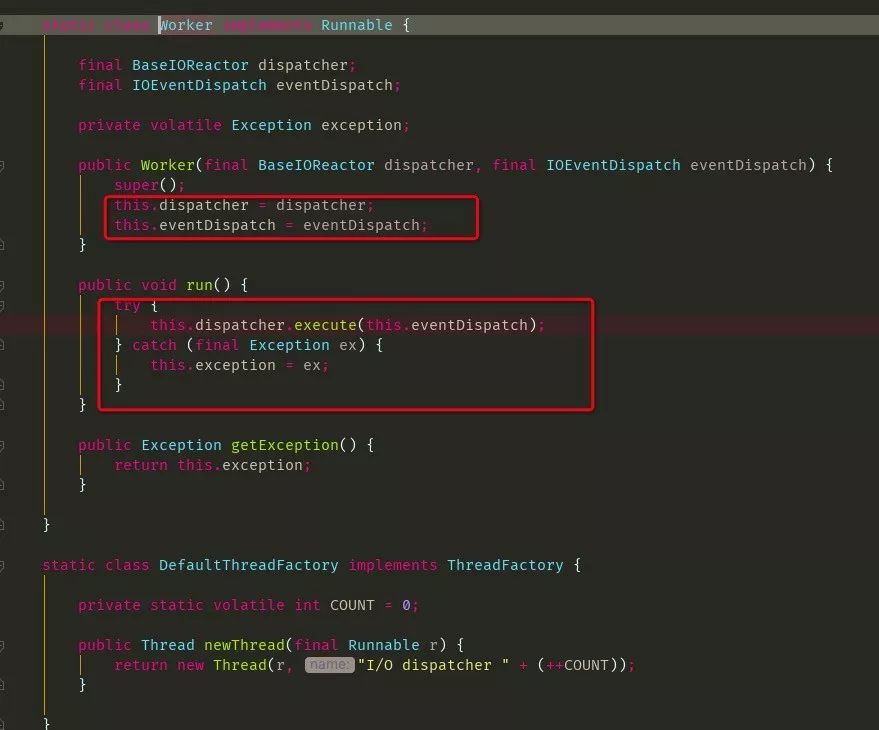
worker线程实现
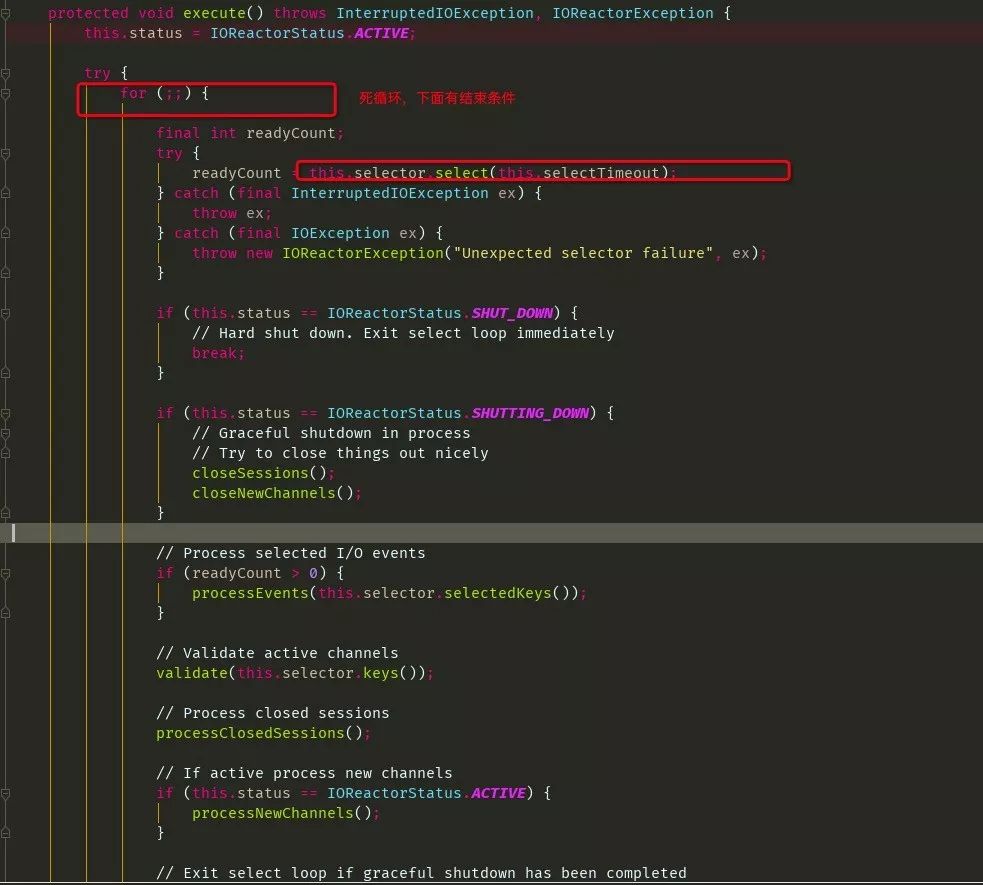
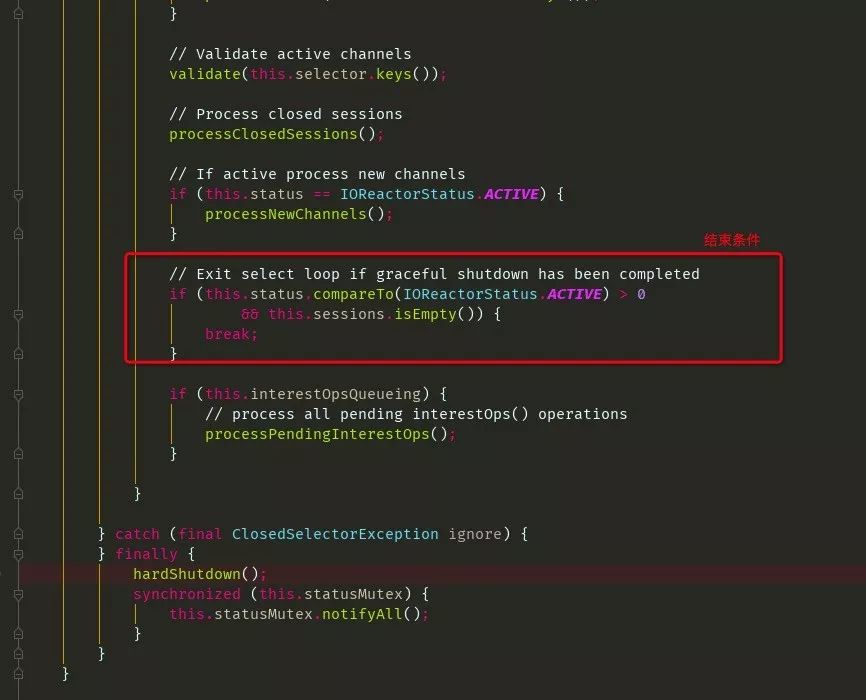
shutdown 这里就不做分析了,调用后,线程都会跳出死循环,结束线程,关闭链接等好多清理动作。
疑问
虽然每次方法调用都是new新的客户端,但是结束finally中都调用了shutDown,为何会关闭失败,上面使用单例模式,只是掩盖了为什么每次new客户端然后shutdown失效的原因
httpAsyncClient客户端在请求失败的情况下,httpclient.close()此处会导致主线程阻塞,经源码发现close方法内部,在线程连接池关闭以后, httpAsyncClient对应线程还处于运行之中,一直阻塞在epollWait,详见上面的线程状态,这里目前没有确定下为什么调用shutdown之后线程关闭失败,也没有任何异常日志,但是这是导致线程泄露的主要原因
在本地测试shutdown方法可正常关闭,很是奇怪。如果各位有知道具体的原因的,望指教。
长按订阅更多精彩▼

如有收获,点个在看,诚挚感谢
最后
以上就是矮小老鼠最近收集整理的关于内存泄露排查之线程泄露的全部内容,更多相关内存泄露排查之线程泄露内容请搜索靠谱客的其他文章。








发表评论 取消回复