文章目录
- 背景
- Metrics
- pgstat
- 指标展示
- 指标统计相关的guc 参数
- pgstat 实现
- pg_stat_statements
- 基本用法及指标内容
- pg_stat_statements 实现
- Trace
- 总结
背景
PG 作为一个演进30多年历史的TP 数据库,其复杂度极高,如果想要提供 DBA 在线上分析复杂查询的性能问题或者构建PG集群提前发现问题的能力,这一些需求都事关 PG的易用性、可靠性、性能,所以PG也提供了一套自己的可观测性体系。
当然,可靠性以及性能 核心还是由那一些 commiter 保障的。
本篇涉及的PG代码版本是REL_12_STABLE
可观测性主要体现在 M (metrics), T(Trace), L(Log) 三个方面,LOG这块大家都比较熟知了,也算是Trace 能力的一种体现,在LOG 方面不会展开太多,主要关注前两个 M 和 T。
Metrics
我们执行sql的时候想要查看它的执行计划 以及 计划内每一步的耗时,可以通过 explain analyze 达成这个功能,它们本身属于 Metrics的一部分。
查看 启动的 postgres 进程时可以看到 PG 维护了一个 stats collector 子进程,用于做stat 统计
pgstat
pgstat 是PG 统计Metrics 的核心,主要是统计PG 各个组件累计的一些指标,其功能也被用于analyze 统计的实现;当然其提供的指标集选项中包括了静态指标 ,也有一些动态指标。
指标展示
pgstat 的指标集合 是由 前面 stats collector 进程收集统计 并且存放在共享内存中,对用户提供类似表形态的查询能力。
前面提到的动态指标,类似 pg_stat_activity 、pg_stat_progress_vacuum等能够动态得展示当前各个进程的行为 以及 vacuum当前运行到哪一步了;
比如查看 当前集群的每一个进程状态(除了 stats collector之外):

部分动态指标 以及其展示的内容 查看可以参考如下表:
| view name | 功能描述 |
|---|---|
| pg_stat_activity | 监控当前集群的每一个pg 子进程状态 |
| pg_stat_replication | 有主从的场景,监控每一个wal sender进程,展示客户端信息以及发送状态相关的指标 |
| pg_stat_wal_receiver | 展示主从场景 wal receiver 进程的状态信息 |
| pg_stat_subscription | 展示处理订阅信息相关的进程指标 |
| … | … |
更多的动态指标可以参考 monitoring-stats。
除了动态指标,还有一些静态指标,比如从创建表到现在该表内部的各种指标信息(insert tuple的个数、update tupe的个数,活跃tuple的个数最后一次 vacuum的时间等等);
通过 select * from pg_stat_all_tables; 就都能看到了:

还有很多其他静态指标,table, sys table, database,vacuum 等都能看到:
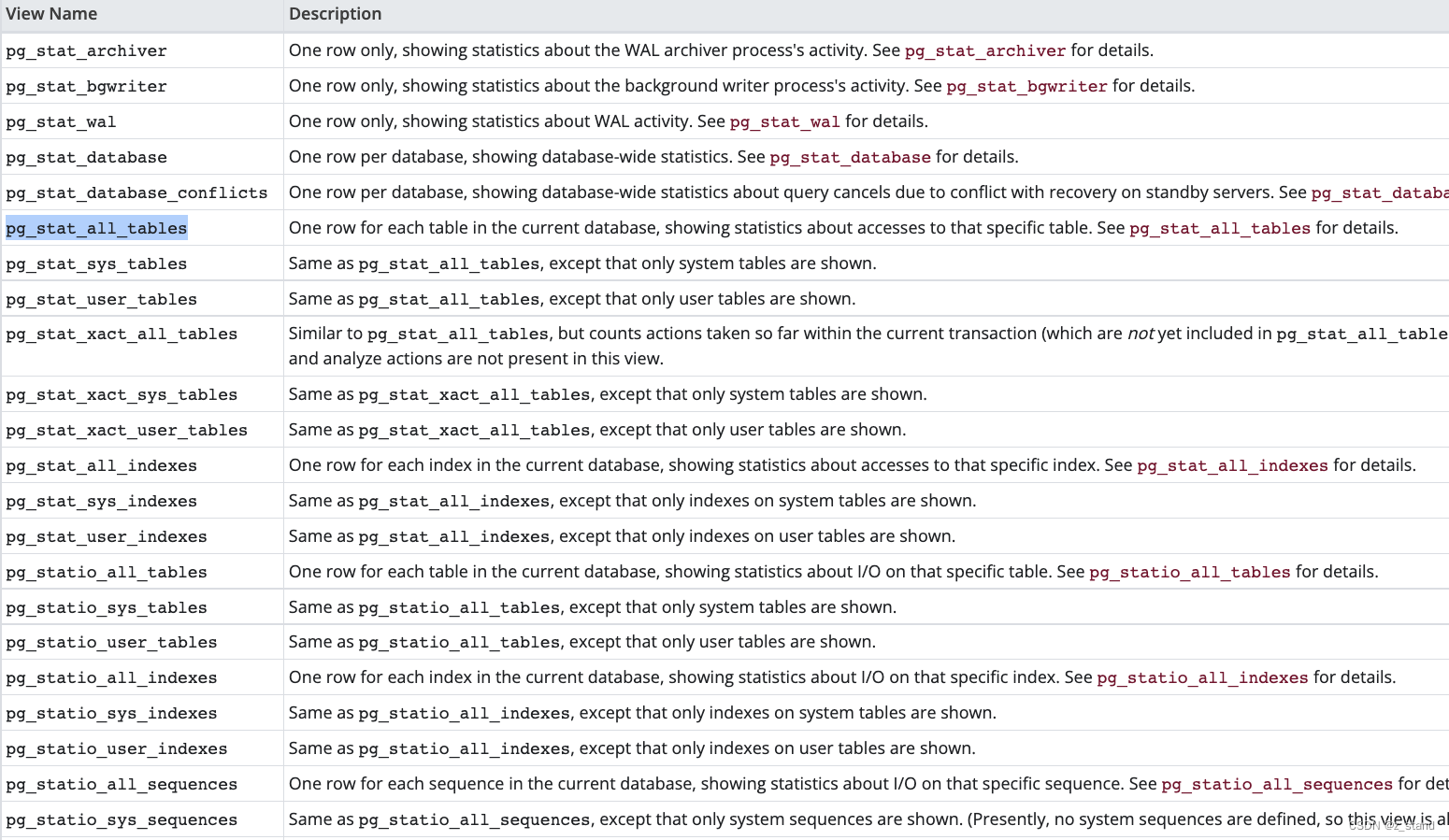
这一些指标能够极大得帮助我们展示当前整个 PG 集群各个组件的状态,从而能够进一步分析当前集群的健康状态(比如 tables 中 dead tuple数量过多,是不是就可以主动调度一次 vacuum做清理,否则影响读性能等)。
指标统计相关的guc 参数
对于上文提到的这一些指标的统计,PG 提供了一些控制参数:
track_activities = on;开启对各个子进程运行状态的监控。track_counts = on; 开启一些累计指标的计数功能。track_functions = on; 开启对 UDF(user defined functions)的一些调用统计,主要用于pg_stat_user_functions的查询。track_io_timing = on; 对阻塞式读写状态的监控;
这几个参数的权限都是 PGC_SUSET,即在进程运行过程中只有 超级用户才有权限通过 set命令设置(普通用户操作可能会影响整个集群的统计行为),其他的设置都只能写入 postgresql.conf中重启 server才能生效。
pgstat 实现
对于以上统计过程的实现整体比较简单的:
- 集群启动 postmaster 初始化 整个PG 所有的共享内存变量和信号量的时候会 对pgstat 存储统计信息的
BackendStatusArray变量进行初始化,其是一个共享内存变量。 - 集群正常运行调度各个dml 的过程中 内部已经在做统计了。每一个backend的统计信息会放在从
BackendStatusArray中取出来的对应当前backend的变量中。比如我们调用vacuum命令的时候会调用pgstat_progress_start_command以及pgstat_progress_start_command来做动态指标的统计;静态指标的统计则直接在 对应的执行链路插入统计count指标的函数方法,比如 heap_insert 完成tuple的插入之后就会执行pgstat_count_heap_insert(relation, 1);, - 集群启动的时候也会启动 stats collector进程,该进程主要用于自动处理集群内部的的一些组件指标统计需求。比如 因脏页过多或者周期 启动了
checkpointer进程来工作,则其main函数内部会调用pgstat_send_bgwriter发送指定的消息类型,请求PgstatCollectorMain中对应的指标统计函数进行指标收集存储。 - 用户在psql中想要读取这一些统计的指标,则会通过
pgstatfuncs.c实现的众多函数来去从 共享内存变量中提取对应需要的数据。
对于 analyze 这样的功能,完成对sql的追踪过程之后,也是将完成了的统计信息发送给 stats collector做存储,供用户通过 pgstatfuncts 中的函数做访问分析。
pg_stat_statements
以上通过 pgstat 统计的信息是整个数据库的状态视图,包括其中的各个组件。这一些metrics能帮助我们提前发现整体的一些问题,但是如果我们想要优化 sql 性能,那也就意味着需要query级别的统计信息,显然pgstat 是没法提供query级别的统计信息的。
这个能力会由 PG 的插件 pg_stat_statements 来提供。
基本用法及指标内容
因为 pg_stat_statements 是作为插件来使用的,开启的话则需要做如下配置:
创建这个插件需要
pg_stat_statements.control文件的存在,因为我是本地编译源码使用的,所以需要做一些额外的配置。
- 完成PG 本身编译的情况下,进入
contrib/pg_stat_statements/直接make && make install生成pg_stat_statements.so 动态库。 - 编辑
postgresql.conf文件,增加一行配置shared_preload_libraries='pg_stat_statements'标识启动时需要加载 前面编译好的动态库。 - PG 集群重启
./bin/pg_ctl -D /Users/zhanghuigui/Desktop/work/source/postgres/build/data -l logfile restart - psql 进入测试数据库,创建插件:
create extension pg_stat_statements; - 可以进行查询:
select * from pg_stat_statements;,能够看到一些执行过的sql 指标,指标类型包括如下信息:userid dbid queryid #唯一标识一个 query query # query的详细内容 calls # 调用的次数 total_time # 调用这么多次,执行的总时间 min_time # 其中最小时间 max_time mean_time stddev_time rows shared_blks_hit # buffer cache 命中的次数 shared_blks_read # buffer cache调度的读 shared_blks_dirtied # 写buffer cache 产生了多少脏页 shared_blks_written # 写了多个 page local_blks_hit # local buffer cache命中次数... local_blks_read local_blks_dirtied local_blks_written temp_blks_read temp_blks_written blk_read_time # 读io上消耗的时间 blk_write_time
通过这一些信息能够看到一些query粒度的基本统计信息,其中比较关键的是query 在内存/io 上的一些指标,这样我们能够分析出这个query的性能是否合理,如果cache命中都很少而大多数都在io上面,则能够进一步做一些os/pg 本身的配置调整或者问题分析。
pg_stat_statements 实现
因为它本身统计的是query级别的 metrics,很明显的是需要需要嵌入到执行器的逻辑中才能拿到这一些信息,PG 提供了 hook functions,这一些钩子函数就像UDF (user defined function) 一样能够嵌入到执行器的逻辑中进行执行统计;统计的指标也是和 pgstat 一样存储到共享内存中。
在加载插件的时候会初始化对应的 hook function:
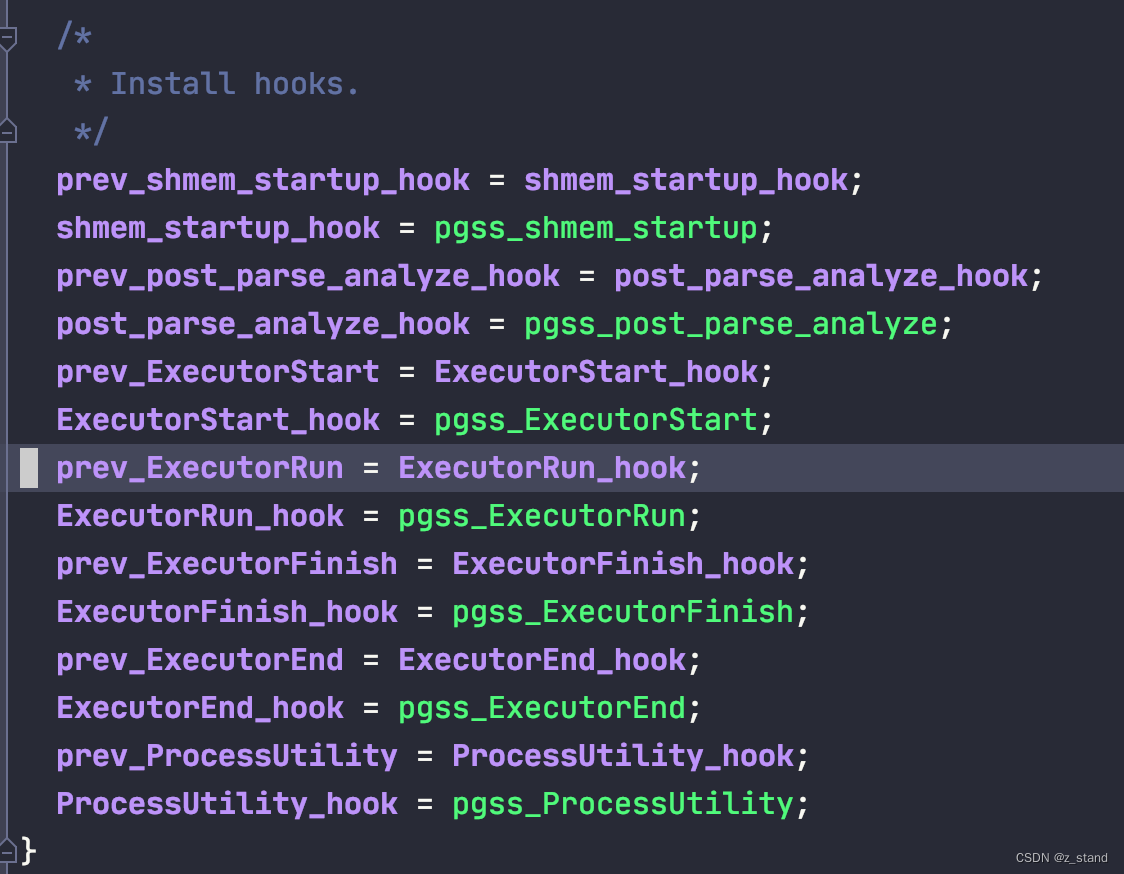
像是 ExecutorRun_hook 函数指针会被放在 执行器逻辑中调度,也就是pgss_ExecutorRun函数,其内还是会执行实际的standard_ExecutorRun函数,只是多了一些其他统计相关的逻辑:

指标的收集过程是在 执行器的 End部分,也就是 pgss_ExecutorEnd函数中,因为参数是 QueryDesc,其能够拿到整个链路执行时保存的结果,而实际执行的过程中保存的query级别的指标会放在 queryDesc->totaltime->bufusage 数据结构中。
BufferUsage的信息如下:
typedef struct BufferUsage
{
long shared_blks_hit; /* # of shared buffer hits */
long shared_blks_read; /* # of shared disk blocks read */
long shared_blks_dirtied; /* # of shared blocks dirtied */
long shared_blks_written; /* # of shared disk blocks written */
long local_blks_hit; /* # of local buffer hits */
long local_blks_read; /* # of local disk blocks read */
long local_blks_dirtied; /* # of shared blocks dirtied */
long local_blks_written; /* # of local disk blocks written */
long temp_blks_read; /* # of temp blocks read */
long temp_blks_written; /* # of temp blocks written */
instr_time blk_read_time; /* time spent reading */
instr_time blk_write_time; /* time spent writing */
} BufferUsage;
其中每一个指标都是在实际访问对应的组件时统计的
回到 pgss_ExecutorEnd函数,主要是将 queryDesc->totaltime->bufusage 统计好的数据通过 pgss_store 保存到 pgss_hash 共享内存的 HTAB hash表中,会将当前query的 userid , dbid, queryid 作为hash key。
在 pgss_hash 中的数据会在集群停止的时候通过 pgss_shmem_shutdown 写入到 data/pg_stat_tmp 中的 .stat文件中,方便重新启动的时候继续将之前记录的统计信息加载到内存中。
当然,也提供了 统计条数的guc 配置:
pg_stat_statements.max设置最大保存的统计条数,默认是5000pg_stat_statements.track设置 追踪那一些sql,默认是顶层查询,会忽略字查询的统计。如果想要追踪所有的查询,则需要配置为allpg_stat_statements.track_utility开启对utility 模式执行的sql 状态的追踪pg_stat_statements.save开启 集群退出时保存 追踪记录的 stats
其实 PG 这里做的可扩展性很强,如果用户觉得当前query级别的统计信息还不够,那用户完全可以自定义自己的统计函数,不过就是需要在内核链路中增加类似 BufferUsage 这样的自定义指标类型, 还是需要对内核代码 尤其是 执行器部分要熟悉一些。
目前query 级别的统计信息缺失的一大部分是事务相关的统计;包括 pgstats 给到的一些指标与事务部分相关的基本没有;这里是 PG 12版本的指标,看了一下15版本,增加了更多的指标,包括:生成plan的时间,wal相关操作的 数据量 以及 count,还有 jit的各个阶段的时间。可能事务部分的统计对于PG 来说有办法拿到锁相关的统计信息就够了(pg_locks 表),不需要更多其他的状态了,所以现有的指标对于PG的用户以及内核开发者来说是足够的。
Trace
Trace 能力本身和 LOG 能力是类似的,保存sql 数据库内部发生的各个事件,提供一种能够追踪query 详细步骤的能力。只是 Trace本身功能会更为专注,使用上更为便捷,能够快速详细得展示一个sql 的关键步骤的耗时,方便我们快速排查问题。
Trace 能力本身其实主要应用在微服务场景,在众多的调度模块中增加 trace能力,从而能够专注于一个context的生命周期,通过trace 快速定位线上问题的根因;数据库组件其实相对较少,trace能力在数据库领域可能更专注于性能分析。
PG 作为传统关系型数据库,其实Trace 能力比较弱的,仅提供了通过 DTrace 进行分析的能力。
主要应该是没有需求,其利用前面的metrics + commiter本身的能力 ???? ,作为发现以及解决问题的手段就已经足够了,其实并不需要再引入 trace 能力了。
关于PG 的 DTrace 的使用简单介绍一下:
-
编译时开启 dtrace 选项, configure 的时候增加
--enable-dtrace配置,编译完成之后就可以看到重新生成了一个probe.h,里面的trace 桩都用 dtrace的接口重新写了一遍。#define TRACE_POSTGRESQL_TRANSACTION_START(arg0) do { __asm__ volatile(".reference " TRACE_POSTGRESQL_TYPEDEFS); __dtrace_probe$postgresql$transaction__start$v1$756e7369676e656420696e74(arg0); __asm__ volatile(".reference " TRACE_POSTGRESQL_STABILITY); } while (0) -
从
probe.d中能够找到支持 dtrace 的探针函数,如果不在probe.d中的话就无法探测了。 -
运行 PG 集群,并编写dtrace 探测脚本进行探测。
#!/usr/sbin/dtrace -qs BEGIN { wal_insert = 0; printf ("%27s | %20s | %sn", "STAGE", "TIME-ns", "WAL-INS-COUNT"); } postgresql$1:::transaction-start { start_time = timestamp; } postgresql$1:::transaction-commit { printf("%10s | %20d | %dn", "transaction-commit-duration", timestamp - start_time, wal_insert); wal_insert = 0; } postgresql$1:::transaction-abort { printf("%10s | %20d | %dn", "transaction-abort-duration", timestamp - start_time, wal_insert); wal_insert = 0; } postgresql$1:::wal-insert { wal_insert ++; }这个脚本我探测的内容是 每一个事务从 start 到 commit/abort 的延时,并且统计在此期间写了多少次wal。
运行的话:./test-drace.d $pid,指定psql 启动的backend 进程id即可,然后在进程id中做一些操作就能看到实时打印的结果。我是在mac上跑的脚本,dtrace运行时需要root权限
最后的输出结果如下:
STAGE | TIME-ns | WAL-INS-COUNT transaction-commit-duration | 698250 | 3 transaction-abort-duration | 5139649500 | 3 transaction-commit-duration | 1212917 | 2
当然大家如果想要添加自己的探针,也比较简单,在 probe.d 中增加自己的探针类型,增加一个对应的宏定义类型到 probe.h中,将这个类型放在自己想要统计的 内核代码中,最后重新编译这个探针就能用了。
关于postgresql 的 dtrace 使用有一些注意的地方:
使用者想要在线上用这个功能,需要对内核的行为 以及 dtrace的行为有一定的理解,不能在频繁调用的地方增加探针,否则会极大得拖慢应用的性能。
dtrace能做的,systemtap也能做,目前来看其实比dtrace更方便,至少不用增加probe重新编译,而是任意编译到binary的函数符号都能被systemtap追踪;只不过dtrace 在跨平台上支持的更好一些,能够在unix系统跑(mac),而systemtap仅能在linux上跑。
所以PG 社区并不建议 DBA 或者 用户去线上使用这个功能,这个能力本身就是为内核开发者来做调试用的,大家也能看出来 PG 本身的 trace能力对于普通用户来说还是比较弱的,对于社区的开发者来说当前的dtrace非常灵活且可配置,已经使用习惯了,完全不需要外部用户考虑这方面。
总结
总的来说 PG 社区的可观测性能力是不错的,不过在Trace 这方面还是比较欠缺(菜鸟角度),对于想要基于PG做开发的数据库来说这方面的能力需要独立建设。
当然业界已经有比较成熟的trace 体系,像是 opentracing 以及 dapper 这种支持分布式trace的架构,能够极大得提升复杂系统排查问题的效率。
最后
以上就是无奈御姐最近收集整理的关于PostgreSQL 内核可观测性体系的全部内容,更多相关PostgreSQL内容请搜索靠谱客的其他文章。








发表评论 取消回复