概念
引用Spark官网的定义:Apache Spark™ is a fast and general engine for large-scale data processing
Spark是用于大规模数据处理的快速和通用的集群计算平台
目前大数据处理的应用主要可以分为离线的海量数据处理(如用户画像、推荐系统),以及实时的数据流处理(天猫双十一实时大屏)。
前者可以使用Hadoop MapReduce,后者可以使用Storm。
而我们的Spark,既可以支持离线海量数据处理,又可以支持实时的数据流处理,并且还具有很多优势:快速、通用、兼容、强大的生态圈。
优势
(1)快速
与Hadoop的MapReduce(计算完之后会将中间结果存储在磁盘)相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。
(2)通用
Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法。
(3)兼容
Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase等。
Spark生态圈
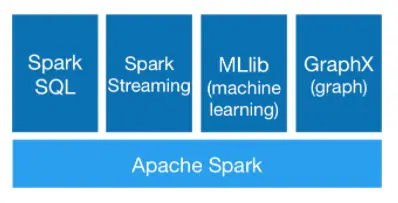
(1)Spark Core :实现Spark基本功能,如任务调度,内存管理,与存储系统交互,还包括对弹性分布式数据集RDD的API定义。
(2)Spark SQL :Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用。它将Spark SQL转换成RDD,然后提交到集群执行,执行效率非常快。
(3)Spark Streaming :是Spark提供的对实时数据进行流式计算的组件。如网页服务器日志等都是数据流,Spark Streaming提供了操作数据流的API。
(4)Mlib :提供了很多种机器学习算法,包括分类、回归、聚类、协同过滤等,还提供了模型评估,数据导入等额外支持的功能。
(5)GraphX: 是用于操作图(比如社交网络的朋友关系图)的程序库,可以进行并行的图计算。
作者:Seven_Ki
链接:https://www.jianshu.com/p/b3ce62f2f287
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
转载于:https://www.cnblogs.com/chendongjing/p/8461032.html
最后
以上就是包容老虎最近收集整理的关于Spark入门教程(一) 初始Spark:概述、特点及其生态圈概念优势Spark生态圈的全部内容,更多相关Spark入门教程(一)内容请搜索靠谱客的其他文章。








发表评论 取消回复