1.json.dumps()函数
def dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True,
allow_nan=True, cls=None, indent=None, separators=None,
default=None, sort_keys=False, **kw):
将obj转化为字符串。
列表——>字符串
import json
a=[1,1,2,3,4]
b=json.dumps(a)
print(b)
[1, 1, 2, 3, 4]
b
'[1, 1, 2, 3, 4]'
字典——>字符串
import json
a={'name':'MM',
'sex':'man',
'age':'18'}
b=json.dumps(a)
b
'{"name": "MM", "sex": "man", "age": "18"}'
2.assert函数的理解
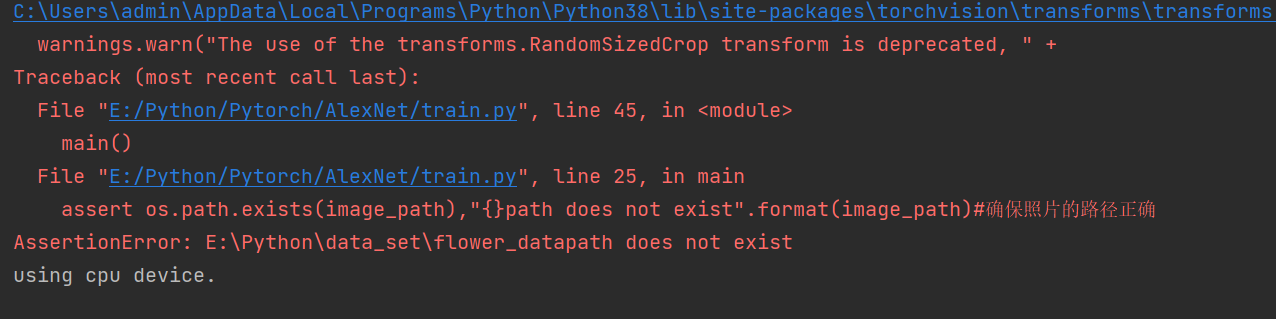
当assert后面的语句为假的时候,运行,不必等到程序运行崩溃。
assert os.path.exists(image_path),"{}path does not exist".format(image_path)#确保照片的路径正确
确保存在image_path的路径存在。
3.format函数
基本语法是通过 {} 和 : 来代替以前的 % 。
>>>"{} {}".format("hello", "world") # 不设置指定位置,按默认顺序
'hello world'
>>> "{0} {1}".format("hello", "world") # 设置指定位置
'hello world'
>>> "{1} {0} {1}".format("hello", "world") # 设置指定位置
'world hello world'
4.with torch.no_grad()的理解
是将with torch.no_grad()下面的语句tensor的计算不放在计算图中,不用跟踪反向梯度计算。
a=torch.tensor([3.4],requires_grad=True)
b=a*2
输出:
b
tensor([6.8000], grad_fn=<MulBackward0>)
从上面代码可以看出的梯度函数是MulBackward0
with torch.no_grad():
b.add_(2)
输出:
b
tensor([33.2000], grad_fn=<MulBackward0>)
继续将在with torch.no_grad()下面写b.add_2(),则可以看出,输出的tensor,并不是grad_fn=。
5.模型的加载以及存储
#第一种方法:只是存储模型中的参数,该方法速度快,占用空间少
model=AlexNet()
torch.save(model.state_dict(),Path) #存储Model的参数
new_model=AlexNet()
new_model.load_state_dict(torch.load(Path)) #将model中的参数加载到new_model中
#第二种方法:存储整个模型
model=AlexNet()
torch.save(model,Path) #存储整个模型
new_model=torch.load(Path) #将整个模型加载到new_model(需要像第一种那样新建立一个模型)
关于上面表达式中PATH参数的说明:
PATH参数是你保存文件的路径,并且需要指定保存文件的文件名,如:
torch.save(model, ‘/home/user/save_model/checkpoint.pth’)
即将该模型保存在/home/user/save_model路径下的checkpoint.pth文件中,保存的文件格式约定为.pth或.pt
new_model = torch.load(’/home/user/save_model/checkpoint.pth’)
参考原文:模型加载
6.torch.softmax()
torch.softmax(input,dim=a)
对n维输入张量运用Softmax函数,将张量的每个元素缩放到(0,1)区间且和为1。Softmax函数定义如下:
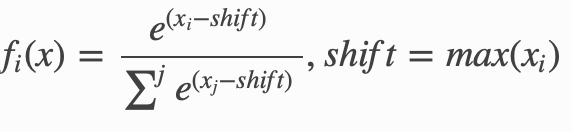
将input内部的值都转换为(0,1)内的值。
a=0的时候,按照列计算
a=1的时候,按照行计算
A=torch.tensor([[1.,10.,3.,4.],[1.,2.,4.,7.],[3.,5.,7.,8.]])
A
tensor([[ 1., 10., 3., 4.],
[ 1., 2., 4., 7.],
[ 3., 5., 7., 8.]])
B=torch.softmax(A,dim=0)
输出:
tensor([[1.0651e-01, 9.9298e-01, 1.7148e-02, 1.3213e-02],
[1.0651e-01, 3.3311e-04, 4.6613e-02, 2.6539e-01],
[7.8699e-01, 6.6906e-03, 9.3624e-01, 7.2140e-01]])
B=torch.softmax(A,dim=1)
输出:
tensor([[1.2298e-04, 9.9650e-01, 9.0869e-04, 2.4701e-03],
[2.3406e-03, 6.3625e-03, 4.7013e-02, 9.4428e-01],
[4.7304e-03, 3.4953e-02, 2.5827e-01, 7.0205e-01]])
7.torch.argmax()
torch.argmax(input,dim=a)
当a=0的时候,返回input列值最大的“行索引”
a=1的时候,返回Input行值最大的“列索引”
A=torch.tensor([[1,2,3,4],[1,2,4,7],[3,5,7,8]])
A
tensor([[1, 2, 3, 4],
[1, 2, 4, 7],
[3, 5, 7, 8]])
B=torch.argmax(A,dim=0)
#输出
B
tensor([2, 2, 2, 2])
B=torch.argmax(A,dim=1)
#输出
B
tensor([3, 3, 3])
最后
以上就是含蓄大碗最近收集整理的关于【Pytorch学习(AlexNet)——代码的理解】1.json.dumps()函数2.assert函数的理解3.format函数4.with torch.no_grad()的理解5.模型的加载以及存储6.torch.softmax()7.torch.argmax()的全部内容,更多相关【Pytorch学习(AlexNet)——代码的理解】1.json.dumps()函数2.assert函数的理解3.format函数4.with内容请搜索靠谱客的其他文章。








发表评论 取消回复