读取机制
Tensorflow中数据读取机制可见下图
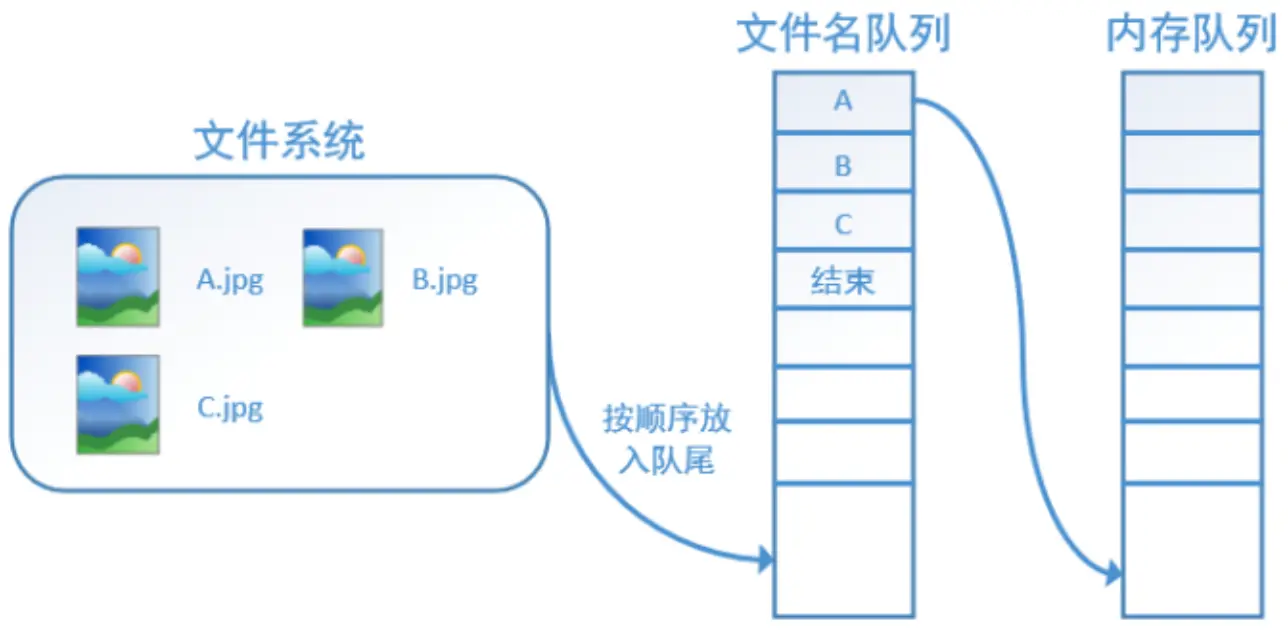
关于这张图,这篇文章已经介绍的非常详细,简而言之,Tensorflow为了不让数据读取成为代码的事件瓶颈,用了两个队列来进行文件的读取:
- 文件队列,通过tf.train.string_input_producer()函数来创建,文件名队列不包含文件的具体内容,只是在队列中记录所有的文件名,所以可以在这个函数中对文件设置多个epoch,并对其进行shuffle。这个函数只是创建一个文件队列,并指定入队的操作由几个线程同时完成。真正的读取文件名内容是从执行了tf.train.start_queue_runners()开始的,start_queue_runners返回一个op,一旦执行这个op,文件名队列就开始被填充了。
- 内存队列,这个队列不需要用户手动创建,有了文件名队列后,start_queue_runners之后,Tensorflow会自己维护内存队列并保证用户时时有数据可读。
典型的代码如下:
import tensorflow as tf
# 新建一个Session
with tf.Session() as sess:
# 我们要读三幅图片A.jpg, B.jpg, C.jpg
filename = ['A.jpg', 'B.jpg', 'C.jpg']
# string_input_producer会产生一个文件名队列
filename_queue = tf.train.string_input_producer(filename, shuffle=False, num_epochs=5)
# reader从文件名队列中读数据。对应的方法是reader.read
reader = tf.WholeFileReader()
key, value = reader.read(filename_queue)
# tf.train.string_input_producer定义了一个epoch变量,要对它进行初始化
tf.local_variables_initializer().run()
# 使用start_queue_runners之后,才会开始填充队列
threads = tf.train.start_queue_runners(sess=sess)
i = 0
while True:
i += 1
# 获取图片数据并保存
image_data = sess.run(value)
with open('read/test_%d.jpg' % i, 'wb') as f:
f.write(image_data)
注意string_input_producer()中的shuffle是文件级别的,如果要读取的文件是TFRecord文件,一个文件中就包含几千甚至更多条数据,那么这里的shuffle和我们平时训练数据时说的shuffle还是不一样的。
TODO: 把读取出的数据组成batch的代码
读取文件格式举例
tensorflow支持读取的文件格式包括:CSV文件,二进制文件,TFRecords文件,图像文件,文本文件等等。具体使用时,需要根据文件的不同格式,选择对应的文件格式阅读器,再将文件名队列传为参数,传入阅读器的read方法中。方法会返回key与对应的record value。将value交给解析器进行解析,转换成网络能进行处理的tensor。
CSV文件读取:
阅读器:tf.TextLineReader
解析器:tf.decode_csv
filename_queue = tf.train.string_input_producer(["file0.csv", "file1.csv"])
"""阅读器"""
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
"""解析器"""
record_defaults = [[1], [1], [1], [1]]
col1, col2, col3, col4 = tf.decode_csv(value, record_defaults=record_defaults)
features = tf.concat([col1, col2, col3, col4], axis=0)
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(100):
example = sess.run(features)
coord.request_stop()
coord.join(threads)二进制文件读取:
阅读器:tf.FixedLengthRecordReader
解析器:tf.decode_raw
图像文件读取:
阅读器:tf.WholeFileReader
解析器:tf.image.decode_image, tf.image.decode_gif, tf.image.decode_jpeg, tf.image.decode_png
TFRecords文件读取
TFRecords文件是tensorflow的标准格式。要使用TFRecords文件读取,事先需要将数据转换成TFRecords文件,具体可察看:convert_to_records.py 在这个脚本中,先将数据填充到tf.train.Example协议内存块(protocol buffer),将协议内存块序列化为字符串,再通过tf.python_io.TFRecordWriter写入到TFRecords文件中去。
阅读器:tf.TFRecordReader
解析器:tf.parse_single_example
又或者使用slim提供的简便方法:slim.dataset.Data以及slim.dataset_data_provider.DatasetDataProvider方法
用slim读取数据分为以下几步:
- 给出数据来源的文件名并据此建立slim.Dataset,逻辑上Dataset中是含有所有数据的,当然物理上并非如此。
- 根据slim.Dataset建立一个DatasetDataProvider,这个class提供接口可以让你从Dataset中一条一条的去取数据
- 通过DatasetDataProvider的get接口拿到获取数据的op,并对数据进行必要的预处理(如有)
- 利用从provider中get到的数据建立batch,此处可以对数据进行shuffle,确定batch_size等等
- 利用分好的batch建立一个prefetch_queue
- prefetch_queue中有一个dequeue的op,没执行一次dequeue则返回一个batch的数据。
def get_split(record_file_name, num_sampels, size):
reader = tf.TFRecordReader
keys_to_features = {
"image/encoded": tf.FixedLenFeature((), tf.string, ''),
"image/format": tf.FixedLenFeature((), tf.string, 'jpeg'),
"image/height": tf.FixedLenFeature([], tf.int64, tf.zeros([], tf.int64)),
"image/width": tf.FixedLenFeature([], tf.int64, tf.zeros([], tf.int64)),
}
items_to_handlers = {
"image": slim.tfexample_decoder.Image(shape=[size, size, 3]),
"height": slim.tfexample_decoder.Tensor("image/height"),
"width": slim.tfexample_decoder.Tensor("image/width"),
}
decoder = slim.tfexample_decoder.TFExampleDecoder(
keys_to_features, items_to_handlers
)
return slim.dataset.Dataset(
data_sources=record_file_name,
reader=reader,
decoder=decoder,
items_to_descriptions={},
num_samples=num_sampels
)
def get_image(num_samples, resize, record_file="image.tfrecord", shuffle=False):
provider = slim.dataset_data_provider.DatasetDataProvider(
get_split(record_file, num_samples, resize),
shuffle=shuffle
)
[data_image] = provider.get(["image"])
return data_image下面我们通过代码来一一介绍具体如何使用。
1.建立slim.Dataset
根据官方文档,slim.Dataset包含data_sources,reader,decoder,num_samples,descriptions五个部分,其中data_sources是一系列文件名,代表组成数据集全体的文件名;reader,针对文件的类型,选择合适的reader;decoder,一个解释器,用于将文件中存储的数据转换为Tensor类型;num_samples,指明数据集中一共含有多少条数据;descriptions可以添加一些对于数据的额外备注和说明,非必须。下面是一段典型的建立Dataset的代码,假设我们的数据由多个TFRecord文件组成,每个TFRecord存储若干数据,在TFRecord中,每条数据都是一个TFExample类型:
def get_split(split_name, dataset_dir, file_pattern, num_samples, reader=None):
dataset_dir = util.io.get_absolute_path(dataset_dir)
if util.str.contains(file_pattern, '%'):
# 处理有多个文件的情况,file_pattern是文件名list
file_pattern = util.io.join_path(dataset_dir, file_pattern % split_name)
else:
file_pattern = util.io.join_path(dataset_dir, file_pattern)
# Allowing None in the signature so that dataset_factory can use the default.
if reader is None:
reader = tf.TFRecordReader
keys_to_features = {
'image/encoded': tf.FixedLenFeature((), tf.string, default_value=''),
'image/format': tf.FixedLenFeature((), tf.string, default_value='jpeg'),
'image/filename': tf.FixedLenFeature((), tf.string, default_value=''),
'image/shape': tf.FixedLenFeature([3], tf.int64),
'image/object/bbox/label': int64_feature(labels),
}
items_to_handlers = {
'image': slim.tfexample_decoder.Image('image/encoded', 'image/format'),
'shape': slim.tfexample_decoder.Tensor('image/shape'),
'filename': slim.tfexample_decoder.Tensor('image/filename'),
'object/label': slim.tfexample_decoder.Tensor('image/object/bbox/label')
}
# slim.Decoder可以给两个参数,两个都是dict,第一个参数指定要如何解析每个Example,第二个参数可以把读取出的数据进一步简单处理或者组合成需要的数据
decoder = slim.tfexample_decoder.TFExampleDecoder(keys_to_features, items_to_handlers)
items_to_descriptions = {
'image': 'A color image of varying height and width.',
'shape': 'Shape of the image',
'object/label': 'A list of labels, one per each object.',
}
## 建立并返回一个Dataset
return slim.dataset.Dataset(
data_sources=file_pattern,
reader=reader,
decoder=decoder,
num_samples=num_samples,
items_to_descriptions=items_to_descriptions,
num_classes=2,
labels_to_names=labels_to_names)
2. 建立DatasetDataProvider
# 下面用到的dataset就是我们上面建立的slim.dataset.Dataset,num_readers是指定线程数目,即如果后续
# 要多线程读数据的话,最多可以有5个的get可以被同时调用来填充数据。capacity是provider自己维护的
# 队列的大小,get操作相当于dequeue操作,enqueue操作由provider自己完成
provider = slim.dataset_data_provider.DatasetDataProvider(dataset, num_readers=5,
common_queue_capacity=10, common_queue_min=1, shuffle=True)
# 每调用一次get,得到一条数据。同样,这里的get得到的依然是一个Tensor的op,不是一个实实在在的张量
[image, shape, label] = provider.get(['image', 'shape', 'object/label'])
3. 必要的预处理
# 此处可以做一些预处理,数据就一条,没有第一维的batch维度
[image, shape, label] = preprocess(image, shape, label)
4. 建立batch
根据官方文档,train.batch是维护有自己的队列的,所以它也可以开多个线程从provider中获取数据,num_threads就是这个意思,capacity自然就是队列大小。
# 官方还有tf.train.shuffle_batch等接口,提供shuffle数据等功能
b_image, b_label = tf.train.batch([image, label], batch_size=32, num_threads=4, capacity=200)
5. 建立prefetch_queue
batch_queue = slim.prefetch_queue.prefetch_queue([b_image, b_label], capacity = 20)
其实这个地方我有一个不解,既然第四步已经将数据都分好的batch放进了队列,理论上只要执行batch返回的的op就可以直接得到数据,为了还要再包一层队列,产生一个batch_queue呢?根据官方的解释,prefetch_queue的作用是把batch后的数据聚合到一起(assemble),保证用户在读取数据时不需要再花时间assemble。
看来Tensorflow早就想到了这个,并且外面再包一层也是有道理的,但是我本人理解batch后的数据就是assemble之后的,不知道它的batch操作是怎么样的等研究过代码再说吧。(TODO)
6. 运行dequeue的op获取数据
b_images, b_labels = batch_queue.dequeue()
with tf.Sesstion() as sess:
images, labels = sess.run(images, labels)
print(images)
print(labels)
tf.data.Dataset接口
slim提供的数据读取接口其实也不够简洁,看看生一部分的六个步骤就知道过程还有有些繁琐的,想要熟练运用,不了解一些Tensorflow的实现是有点难的。但是tf.data.Dataset则不然,他隐藏了所有Tensorflow处理数据流的细节,用户只需要几步简单的操作就可以轻松读到数据,这使得数据读取更加容易上手且写出的代码更加简洁、易懂。tf.data.Dataset的介绍将会在另外一篇文章中讲解。
参考文献
- 十图详解Tensorflow数据读取机制——知乎
- Tensorflow数据处理——CSDN
- Tensorflow中的README文档
- Tensorflow官网
- PixelLink源码
转自:
https://www.jianshu.com/p/63eb53cb5b73
最后
以上就是寒冷大神最近收集整理的关于TensorFlow笔记(五)——数据读取(二) 读取文件格式举例的全部内容,更多相关TensorFlow笔记(五)——数据读取(二) 读取文件格式举例内容请搜索靠谱客的其他文章。








发表评论 取消回复