【导读】ViT在大规模图像识别方面取得了显著的成功。但随着数据集规模以及自注意力中的tokens数量的增长,会导致计算成本呈平方级急剧增加!最近,清华自动化系的助理教授黄高的研究团队和华为的研究人员,提出了一种Dynamic Vision Transformer (DVT),可以自动为每个输入图像配置适当数量的tokens,并设计了特征重用和关系重用机制,从而大大减少了冗余计算。大量实验结果表明,该方法在理论计算效率和实际推理速度方面都明显优于当前的基准。

链接: https://arxiv.org/abs/2105.15075
代码:https://github.com/blackfeather-wang/Dynamic-Vision-Transformer.
摘要:Vision Transformers (ViT) 在大规模图像识别方面取得了显著的成功。他们将每个输入的2D图像分成固定数量大小的patch,每个patch都被视为一个token。通常,用更多的token来表示图像会得到更高的预测精度,同时这也会导致计算成本急剧增加。为了在准确性和速度之间取得适当的平衡,根据经验,通常将token数量设置为16x16。在本文中,我们认为每个图像都有自己的特征表示,理想情况下,token数量应当建立在每个单独的输入图上。事实上,我们观察到现实生活中存在相当多的“简单”图像,仅用 4x4 标记就可以进行准确预测,而只有一小部分“困难”的图像才需要更精细的标记。受这种现象的启发,我们提出了一种动态Transformer来为每个输入图像自动配置适当数量的token。我们可以通过级联的方式将拥有不同token数量的Transformer连接起来,在测试时,我们将较少的token依次开始进行顺序性激活,即:一旦产生充分置信度的预测,推理就会终止。随后,我们还针对Dynamic Transformer,设计了针对不同组件的高效特征重用和关系重用机制,该机制可以大大减少冗余计算。最后,在ImageNet、CIFAR-10 和 CIFAR-100 上的大量实验结果表明,我们的方法在理论计算效率和实际推理速度方面都明显优于当前的基准。
简介:现有的模型主要采用14x14/16x16 tokens. 在本文中,我们认为用相同数量的token处理所有样本可能不是最佳选择。事实上,不同图像(例如,内容、物体的比例、背景等)之间存在相当大的差异。因此,理想情况下,应该为每个输入专门配置特定的token的数量。这个问题对于模型的计算效率至关重要。例如,我们用不同的token数量训练 T2T-ViT-12,如下面所示: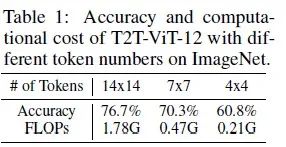 可以观察到,采用官方推荐的 14x14 token 只能正确识别 ~ 15.9%(76.7% vs 60.8%) 与使用 4x4 token的测试样本相比,增加了 8.5 倍的计算成本(1.78G 与 0.21G)。换句话说,将14x14 令牌应用于许多 4x4 令牌就可以处理的“简单”图像,极大程度上浪费了计算资源。受此观察的启发,我们提出了一种新颖的动态视觉变换器 (DVT) 框架,旨在以每个图像为前提,自动配置合适的token数量,以提高计算效率。具体来说,首先,在训练时,我们使用逐渐增加的token数量来训练一系列 Transformer模型。在测试时,这些模型从较少的token开始依次激活。一旦产生了具有足够置信度的预测,推理过程将立即终止。因此,通过动态调整token数量,计算效率在“简单”和 “困难”样本中的分配并不均匀,这里有很大的空间可以提高效率。对“简单”“困难”样本进行动态分配的方法,其现实效果可以参考下图的实例:
可以观察到,采用官方推荐的 14x14 token 只能正确识别 ~ 15.9%(76.7% vs 60.8%) 与使用 4x4 token的测试样本相比,增加了 8.5 倍的计算成本(1.78G 与 0.21G)。换句话说,将14x14 令牌应用于许多 4x4 令牌就可以处理的“简单”图像,极大程度上浪费了计算资源。受此观察的启发,我们提出了一种新颖的动态视觉变换器 (DVT) 框架,旨在以每个图像为前提,自动配置合适的token数量,以提高计算效率。具体来说,首先,在训练时,我们使用逐渐增加的token数量来训练一系列 Transformer模型。在测试时,这些模型从较少的token开始依次激活。一旦产生了具有足够置信度的预测,推理过程将立即终止。因此,通过动态调整token数量,计算效率在“简单”和 “困难”样本中的分配并不均匀,这里有很大的空间可以提高效率。对“简单”“困难”样本进行动态分配的方法,其现实效果可以参考下图的实例: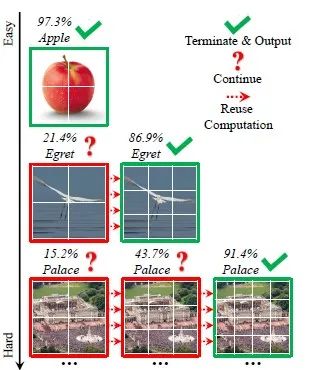 所以,进一步提出了特征重用机制和关系重用机制,它们都能够通过最小化计算成本来显著提高测试精度,以减少冗余计算。前者允许在先前提取的深度特征的基础上训练下游数据,而后者可以利用现有的上游的自注意力模型来学习更准确的注意力。值得注意的是,DVT可以作为一个通用的框架。大多数最先进的视觉 Transformer,例如 ViT、DeiT和 T2T-ViT,都可以直接将其作为backbone直接部署使用从而提高效率。我们的方法在灵活性方面也很有吸引力。DVT 的计算成本可以通过简单地对提前终止标准来进行调整,这一特性使得DVT适合可用计算资源动态变化,或通过最小功耗来实现给定性能的情况。DVT 的性能在 ImageNet和 CIFAR上使用 T2T-ViT 和 DeiT来进行评估。实验结果表明,DVT 显着提高了骨干网的效率。例如,DVT 在不牺牲准确性的情况下将 T2T-ViT 的计算成本降低了 1.6-3.6 倍。在一个NVIDIA 2080Ti GPU 上的真实推理速度与我们的理论结果一致。
所以,进一步提出了特征重用机制和关系重用机制,它们都能够通过最小化计算成本来显著提高测试精度,以减少冗余计算。前者允许在先前提取的深度特征的基础上训练下游数据,而后者可以利用现有的上游的自注意力模型来学习更准确的注意力。值得注意的是,DVT可以作为一个通用的框架。大多数最先进的视觉 Transformer,例如 ViT、DeiT和 T2T-ViT,都可以直接将其作为backbone直接部署使用从而提高效率。我们的方法在灵活性方面也很有吸引力。DVT 的计算成本可以通过简单地对提前终止标准来进行调整,这一特性使得DVT适合可用计算资源动态变化,或通过最小功耗来实现给定性能的情况。DVT 的性能在 ImageNet和 CIFAR上使用 T2T-ViT 和 DeiT来进行评估。实验结果表明,DVT 显着提高了骨干网的效率。例如,DVT 在不牺牲准确性的情况下将 T2T-ViT 的计算成本降低了 1.6-3.6 倍。在一个NVIDIA 2080Ti GPU 上的真实推理速度与我们的理论结果一致。
Method
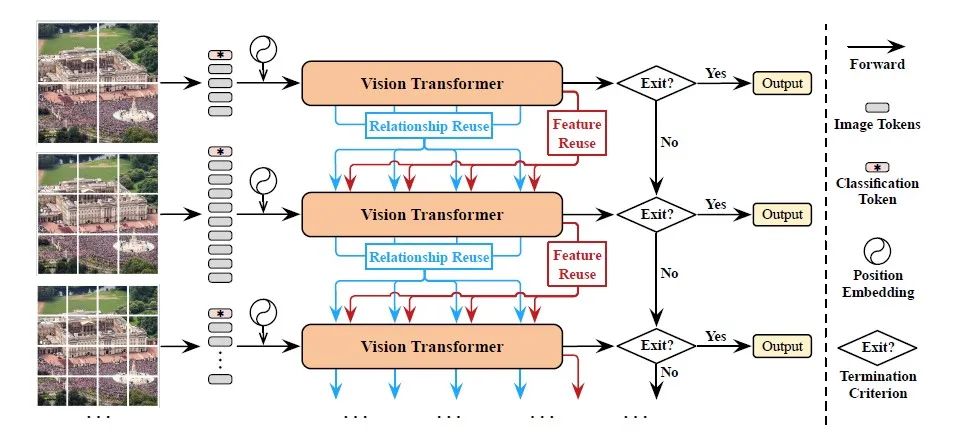 动态视觉转换器(DVT):针对输入特征图自动配置适当的token数量,并且通过逐渐增加token数量嵌入到Transformer进行训练。在测试时,它们会从较少的token开始被依次激活,直到获得一个充分置信度的预测,同时特性和关系重用机制允许不同token数量的Transformer对特征进行重用计算。
动态视觉转换器(DVT):针对输入特征图自动配置适当的token数量,并且通过逐渐增加token数量嵌入到Transformer进行训练。在测试时,它们会从较少的token开始被依次激活,直到获得一个充分置信度的预测,同时特性和关系重用机制允许不同token数量的Transformer对特征进行重用计算。
模型推理与训练
Inference: 我们首先描述DVT的推理过程,对于每个测试样本,我们首先使用少量的1D token嵌入来简单地表示它。这可以通过直接扁平化分割图像patch或利用token到token的模块技术来实现。我们首先用较少的token推断出一个视觉Transformer的性能,从而快速获得预测效果。而且,因为Transformer的计算成本随token数量的增加呈平方级增长,所以推理过程具有很高的效率。最后我们可以采用一定的标准对预测结果进行评价,当模型有足够的可信度时,立刻进行提前终止。一旦预测不能满足终止条件,原始输入图像将被分割成更多的token,通过这种方式,我们可以实现更准确但计算代价更高的推断过程。注意,这里每个token嵌入的维度保持不变,而知识token的数量会增加,这样可以支持更细粒度的特征表示。我们还将激活当前这个与前一个具有相同架构但不同参数的额外Transformer。通过这种方式,我们在一些“困难”的测试样本上在保证计算成本的同时实现了更高的精度。为了提高效率,新模型可以重用上一个模型学习过的特性和关系,类似地,在获得新的预测之后,将应用终止条件,并继续执行上述过程,直到样本退出或最终的Transformer已被推断出来。
Training: 对于训练,我们简单地训练DVT在所有出口产生正确的预测(即,每个出口都有相应数量的token)。形式上,优化目标是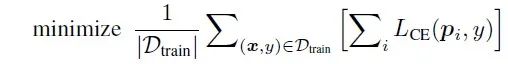
Transformer backbone : DVT是一种通用的、灵活的框架。它可以构建在大多数现有的视觉变形器如ViT, DeiT和T2T-ViT之上,以提高它们的效率。Transformer的体系结构仅仅遵循这些主干的实现。
Feature and Relationship Reuse
设计DVT方法的一个重要挑战是如何促进计算特征的重用。也就是说,一旦推断出具有更多token的下游Transformer,如果放弃在上一个模型中执行的计算,那么它显然是低效的。上游模型虽然基于更少的输入标记,但训练的却是相同的目标,并且也为当前的任务提取了有价值的信息。因此,我们提出了深度特征重用和自注意力关系重用两个机制。这两种方法都能显著提高测试精度并且带来最小的计算代价。
背景。为了便于介绍,我们首先回顾视觉Transformer的基本架构。Transformer编码器由交替堆叠的多头自注意(MSA)和多层感知器(MLP)块组成。在每个块之前和之后分别应用层归一化(LN)和残差连接。设 表示第 个Transformer输出层,其中N为每个样本的token数量, 为每个token的维数。注意, ,对应原始图像的 个patch和单个可学习分类token。形式上,我们有
其中 是Transformer中的总层数。将 中的分类令牌输入LN层,然后在进入一个全连接层最后输出预测结果。为了简单起见,这里我们省略了位置嵌入的细节,这与我们的主要思想无关。下面介绍特征重用机制的具体做法:
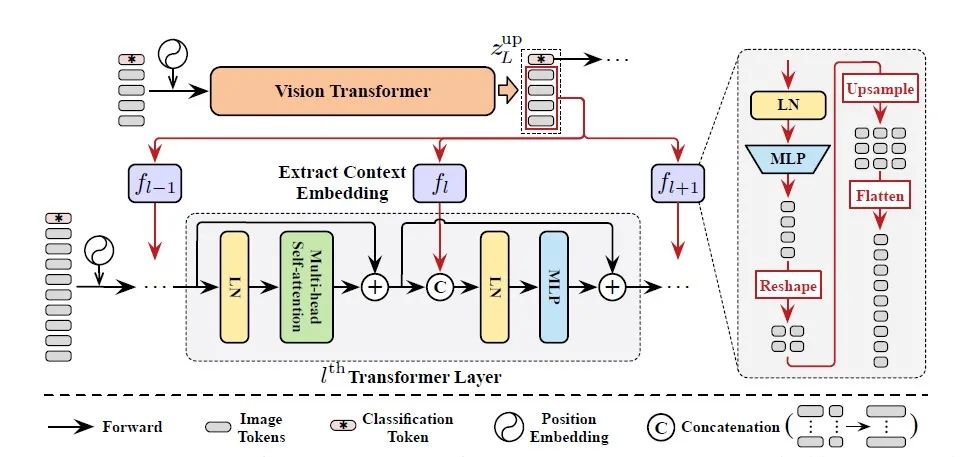
特征重用: DVT中所有的Transformer都有一个共同的目标,即提取可鉴别的特征表示从而实现准确的识别效果。因此,下游模型应该在上游模型已经获得深度特征的基础上进行学习,而不是从零开始提取特征。这样效率会更高,因为在上游模型中执行的计算对其本身和后续模型都有贡献。为了实现这个想法,我们提出了一个特性重用机制(见上图)。具体来说,我们利用上游Transformer最后一层输出的图像标记,即: 来学习下游模型嵌入层的 ,即:
这里, 代表一系列LN-MLP( )的计算操作,LN-MLP可以产生更多的非线性表达并且可以使Transformer之间的切换更加灵活. 然后将原始图像中相应的位置的token进行重塑,先后经过上采样、平化,以匹配下游模型的token数量。通常,我们使用小的 来表示 。然后,我们将 注入到下游模型中,提供关于识别输入图像的先验知识。数学公式表示为:
其中 与中间标记 进行拼接。我们简单地将LN和MLP第一层的维数从D增加到 。因为 是基于上游输出 的,它的token数量比 少,所以它实际上是总结了 中每个输入图像中token的上下文信息。因此,我们将 命名为上下文嵌入信息块。此外,我们不重复使用分类标记和填充零,根据经验,这对性能提升会有益。然后我们再利用特征重用公式,可以使得在训练下游模型时在保证最小化识别损失的基础上,逐层灵活利用 内的信息。这种特性重用形式也可以被理解为隐式地扩大了模型的深度。总结来说,我们利用特征重用机制,可以基于上游模型的最终表示输出,即 ,学习分层上下文信息并且嵌入到每个下游Transformer层的MLP块中。
自注意力关系重用:具体如下图所示: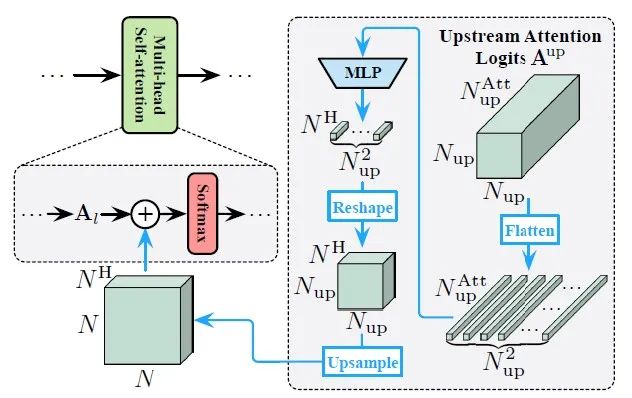 vision Transformer的一个突出优点是,它能够整合整个图像中的信息,从而有效地模型化了数据中的长期依赖关系。通常,模型需要学习每一层的一组注意力图来描述标记之间的关系。除了上面提到的深层特征外,下游模型还可以使用上游模型中产生的数据依赖关系。所以我们认为,上游模型中学习到的关系也能够被重用,以促进下游Transformer的学习。所以,这里我们的设计如下:给定输入
,自注意力表示如下。首先通过线性映射计算查询、键和值矩阵
、
和
:
vision Transformer的一个突出优点是,它能够整合整个图像中的信息,从而有效地模型化了数据中的长期依赖关系。通常,模型需要学习每一层的一组注意力图来描述标记之间的关系。除了上面提到的深层特征外,下游模型还可以使用上游模型中产生的数据依赖关系。所以我们认为,上游模型中学习到的关系也能够被重用,以促进下游Transformer的学习。所以,这里我们的设计如下:给定输入
,自注意力表示如下。首先通过线性映射计算查询、键和值矩阵
、
和
:
这里 表示权重矩阵,然后使用softmax进行缩放的点积运算来计算注意图,并且聚合所有token的值,即:
这里 代表 或者 的隐藏维数, 代表这个注意力图的logit值,为了简便起见,我们省略了关于多头注意机制的细节,其中 可能包括多个注意力图。这种简化并不影响对我们方法的描述。为了进行注意力特征图关系重用,我们首先将上游模型的所有层产生的注意力信息拼接起来( ),即:
这里, 和 代表上有模型的tokens数量和所有的注意力特征图.于是,我们可以得到 ,这里 代表的是多头注意力的head数量, 代表的是层数。因此这个下游的Transformer模型可以通过利用自身的token和 进行累加从而学习到注意力图。即最后的注意力图表示为:
这是一个简单但灵活的表述。一方面,下游模型中的每个自注意力块都可以访问所有上游浅层和深层的注意力头,因此可以训练得到更加多层次的关系信息。另一方面,由于新生成的注意力图和重用的关系以对数形式组合在一起,它们的相对重要性可以通过调整对数的大小来进行自动学习。
实验部分
在ImageNet和CIFAR-10/100上,我们分别验证了DVT的有效性,在这里,主要使用T2T-ViT和DeiT作为backbone. 我们列出来ImageNet上的 Top-1准确率v.s.吞吐量和CIFAR的 Top-1 准确率 v.s. GFLOP的具体效果图表,如下所示:
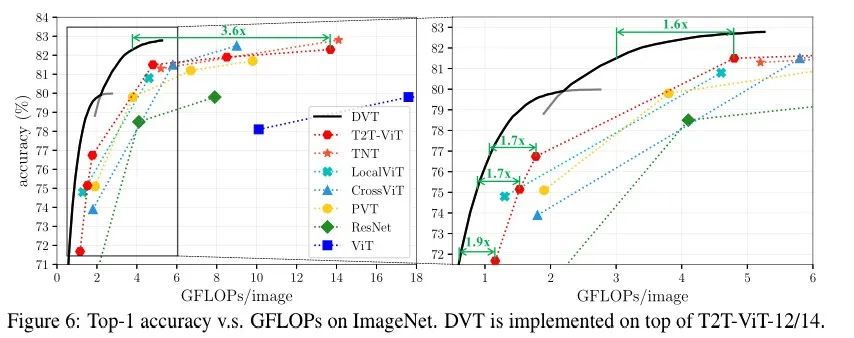
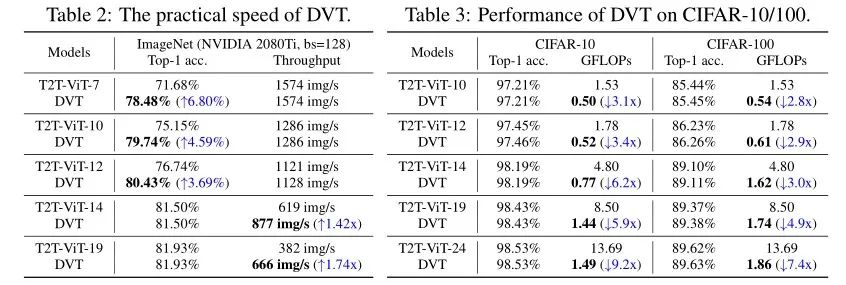
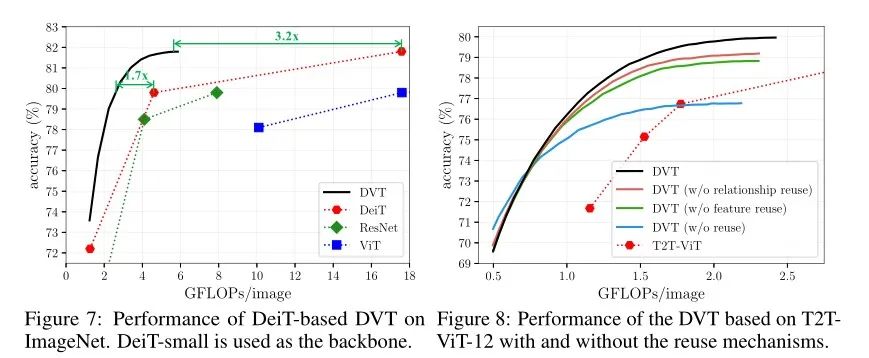
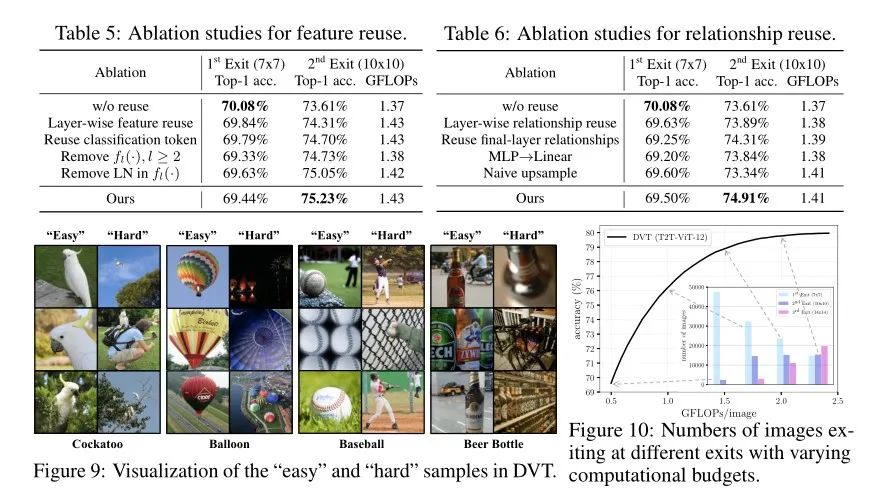
我们对两个特征重用机制分别进行了一系列消融实验,而且还进一步针对DVT中“简单”和“困难”样本进行了可视化。最后还根据不同计算预算从而来动态调整不同出口的图像数,具体结果如下所示:
总结
在本文中,我们试图为视觉Transformer中的每个输入图像优化配置适当数量的tokens,因此提出了动态视觉Transformer(DVT)框架。DVT通过递增token的数量来依次激活多个transformer处理并作为每个测试输入,直到达到合适的令牌数(即实现了一定的预测置信度)就直接提前终止退出。同时,我们还进一步引入了特征重用机制和注意力关系重用机制,以促进高效的计算特征重用。广泛的实验表明,无论是理论上还是实际场景中,DVT在最先进的视觉Transformer上显著提高了预测精度和计算效率。
更多实验细节,请阅读原文!
重磅!DLer-CVPR2021论文分享交流群已成立!
大家好,这是CVPR2021论文分享群里,群里会第一时间发布CVPR2021的论文解读和交流分享会,主要设计方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如图像分类+上交+小明)

???? 长按识别,邀请您进群!
最后
以上就是潇洒绿茶最近收集整理的关于并非所有图像都值16x16个词--- 清华&华为提出一种自适应序列长度的动态ViT的全部内容,更多相关并非所有图像都值16x16个词---内容请搜索靠谱客的其他文章。








发表评论 取消回复