我是靠谱客的博主 大方耳机,这篇文章主要介绍【论文阅读】CVPR2017 Learning From Noisy Large-Scale Datasets With Minimal Supervision,现在分享给大家,希望可以做个参考。
论文地址:https://vision.cornell.edu/se3/wp-content/uploads/2017/04/DeepLabelCleaning_CVPR.pdf
利用大规模有噪数据训练模型的常用方法是在有噪数据上做预训练,在精标数据上做精调。
本文提出一种利用精标数据降低有噪数据中噪声的方法。
模型结构如下:
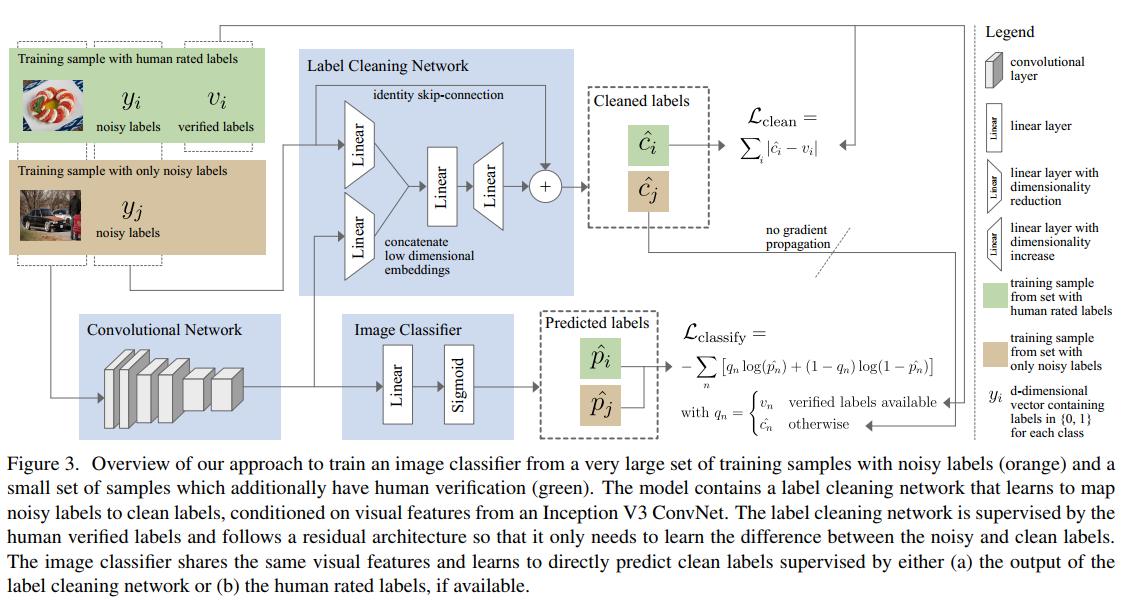
两个任务:
- Label Cleaning Network(模型结构图的上半部分):输入为有噪数据的图片及其有噪label,图片经过cnn抽取特征(模型结构图中Convolutional Network部分),有噪label隐射至低维向量空间,图片的低维向量表示与有噪label的低维向量表示拼接起来后经过两个Linear单元,并与有噪label相加后得到Label Cleaning Network的输出。公式表示如下:
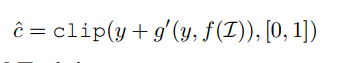
说明:作者认为引入有噪label残差后,Labeling Cleaning Network只需要学习精标label与有噪label的差,而不是去拟合精标label的全部,使得模型更容易学习;
- Image Classifier(模型结构图的下半部分):输入为图片,图片经过cnn抽取特征(与Label Cleaning Network共享)后,输入至Linear和Sigmoid,输出每个分类的概率;Image Classsifier的loss为交叉熵Lclassify,如果该样本含有精标label,则计算loss时使用该label,如果没有则使用Label Cleaning Network纠正过的label;
Loss及训练:
- 两个任务的Loss:
- Label Cleaning Network的Loss:
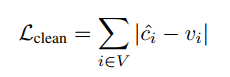
其中,V是带有有噪label和精标label的样本集合,Vi是样本i的精标label,Ci是Label Cleaning Network的输出; - Image Classifier的Loss:
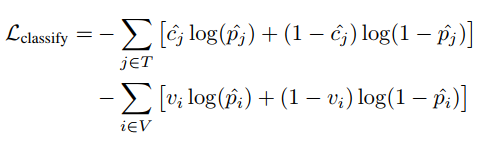
其中,V是带有有噪label和精标label的样本集合,T是仅带有有噪label的样本集合,Vi是样本i的精标label,Cj是Label Cleaning Network的输出,Pi/Pj是Image Classifier的输出 - 两个Loss的权重:论文中Lclean和Lclassify的权重分别为0.1和1.0;
- Label Cleaning Network的Loss:
- 训练:使用SGD训练模型,但是Lclassify的梯度不往Label Cleaning Network回传(如模型结构图中no gradient propagation所示)
结果:
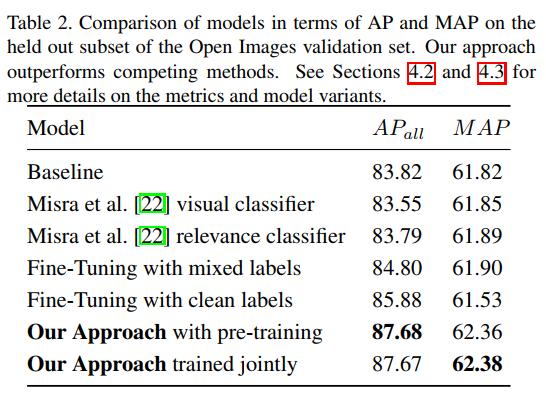
作者在Open Image Dataset提出Average Precision和Mean Average Precison来评价模型效果,具体公式见论文。模型AP值及MAP值如下:
最后
以上就是大方耳机最近收集整理的关于【论文阅读】CVPR2017 Learning From Noisy Large-Scale Datasets With Minimal Supervision的全部内容,更多相关【论文阅读】CVPR2017内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复