文章目录
- Robotic Assembling
- Deep Reinforcement Learning for High Precision Assembly Tasks (IROS 2017)
- Model-based
- Imagination-Augmented Agents for Deep Reinforcement Learning (NIPS 2017)
- Neural Network Dynamics for Model-Based Deep Reinforcement Learning with Model-Free Fine-Tuning (ICRA 2018)
- Uncertainty-driven Imagination for Continuous Deep Reinforcement Learning(CoRL 2017)
- Model-Based Value Expansion for Efficient Model-Free Reinforcement Learning (ICML 2018)
- MODEL-ENSEMBLE TRUST-REGION POLICY OPTIMIZATION (ICLR 2018)
- Sample-Efficient Reinforcement Learning with Stochastic Ensemble Value Expansion (NeurIPS 2018)
- Model-Based Reinforcement Learning via Meta-Policy Optimization(CoRL 2018)
- When to Trust Your Model: Model-Based Policy Optimization(2019)
- Meta Learning
- Model-Based Reinforcement Learning via Meta-Policy Optimization(CoRL 2018)
Robotic Assembling
Deep Reinforcement Learning for High Precision Assembly Tasks (IROS 2017)
[Blog][Paper][Video]
Abstract:
High precision assembly of mechanical parts requires accuracy exceeding the robot precision. Conventional part mating methods used in the current manufacturing requires tedious tuning of numerous parameters before deployment. We show how the robot can successfully perform a tight clearance peg-in-hole task through training a recurrent neural network with reinforcement learning. In addition to saving the manual effort, the proposed technique also shows robustness against position and angle errors for the peg-in-hole task. The neural network learns to take the optimal action by observing the robot sensors to estimate the system state. The advantages of our proposed method is validated experimentally on a 7-axis articulated robot arm.

Model-based
Imagination-Augmented Agents for Deep Reinforcement Learning (NIPS 2017)
[Blog][Paper]
Abstract:
We introduce Imagination-Augmented Agents (I2As), a novel architecture for deep reinforcement learning combining model-free and model-based aspects. In contrast to most existing model-based reinforcement learning and planning methods, which prescribe how a model should be used to arrive at a policy, I2As learn to interpret predictions from a trained environment model to construct implicit plans in arbitrary ways, by using the predictions as additional context in deep policy networks. I2As show improved data efficiency, performance, and robustness to model misspecification compared to several strong baselines.
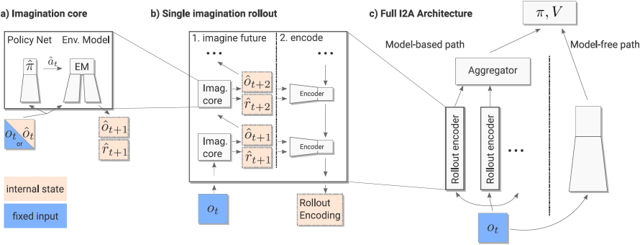
Neural Network Dynamics for Model-Based Deep Reinforcement Learning with Model-Free Fine-Tuning (ICRA 2018)
[Blog][Paper][Video][Code]
Abstract:
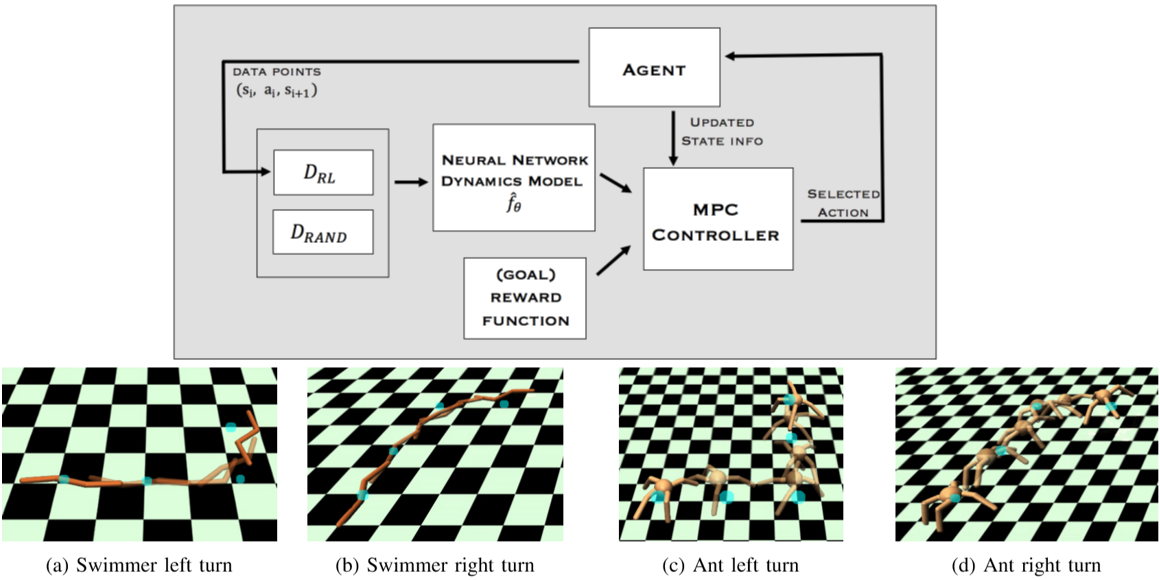
Model-free deep reinforcement learning algorithms have been shown to be capable of learning a wide range of robotic skills, but typically require a very large number of samples to achieve good performance. Model-based algorithms, in principle, can provide for much more efficient learning, but have proven difficult to extend to expressive, high-capacity models such as deep neural networks. In this work, we demonstrate that medium-sized neural network models can in fact be combined with model predictive control (MPC) to achieve excellent sample complexity in a model-based reinforcement learning algorithm, producing stable and plausible gaits to accomplish various complex locomotion tasks. We also propose using deep neural network dynamics models to initialize a model-free learner, in order to combine the sample efficiency of model-based approaches with the high task-specific performance of model-free methods. We empirically demonstrate on MuJoCo locomotion tasks that our pure model-based approach trained on just random action data can follow arbitrary trajectories with excellent sample efficiency, and that our hybrid algorithm can accelerate model-free learning on high-speed benchmark tasks, achieving sample efficiency gains of 3-5x on swimmer, cheetah, hopper, and ant agents.
Uncertainty-driven Imagination for Continuous Deep Reinforcement Learning(CoRL 2017)
[Blog][Paper][Video]
Abstract:
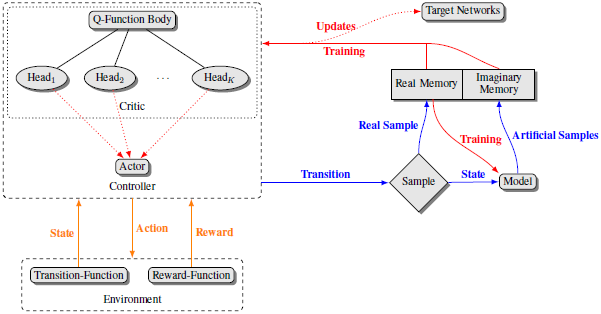
Continuous control of high-dimensional systems can be achieved by current state-of-the-art reinforcement learning methods such as the Deep Deterministic Policy Gradient algorithm, but needs a significant amount of data samples. For real-world systems, this can be an obstacle since excessive data collection can be expensive, tedious or lead to physical damage. The main incentive of this work is to keep the advantages of model-free Q-learning while minimizing real-world interaction by the employment of a dynamics model learned in parallel. To counteract adverse effects of imaginary rollouts with an inaccurate model, a notion of uncertainty is introduced, to make use of artificial data only in cases of high uncertainty. We evaluate our approach on three simulated robot tasks and achieve faster learning by at least 40 per cent in comparison to vanilla DDPG with multiple updates.
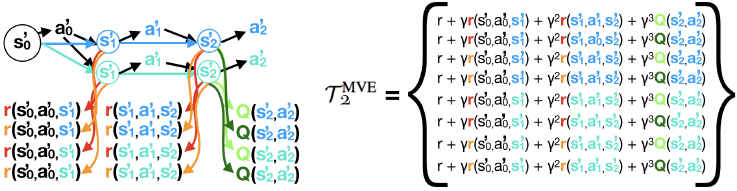
Model-Based Value Expansion for Efficient Model-Free Reinforcement Learning (ICML 2018)
[Blog][Paper]
Abstract:
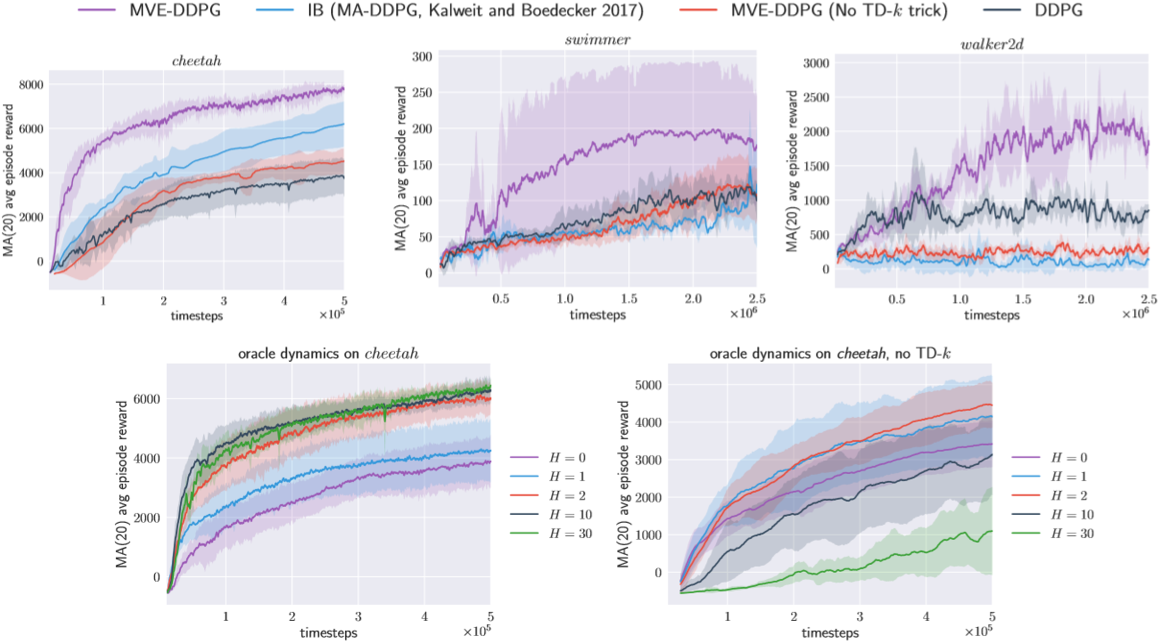
Recent model-free reinforcement learning algorithms have proposed incorporating learned dynamics models as a source of additional data with the intention of reducing sample complexity. Such methods hold the promise of incorporating imagined data coupled with a notion of model uncertainty to accelerate the learning of continuous control tasks. Unfortunately, they rely on heuristics that limit usage of the dynamics model. We present model-based value expansion, which controls for uncertainty in the model by only allowing imagination to fixed depth. By enabling wider use of learned dynamics models within a model-free reinforcement learning algorithm, we improve value estimation, which, in turn, reduces the sample complexity of learning.
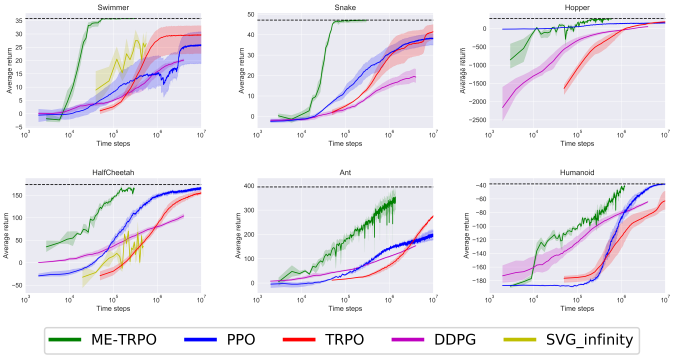
MODEL-ENSEMBLE TRUST-REGION POLICY OPTIMIZATION (ICLR 2018)
[Blog][Paper][Video][Code]
Abstract:
Model-free reinforcement learning (RL) methods are succeeding in a growing number of tasks, aided by recent advances in deep learning. However, they tend to suffer from high sample complexity, which hinders their use in real-world domains. Alternatively, model-based reinforcement learning promises to reduce sample complexity, but tends to require careful tuning and to date have succeeded mainly in restrictive domains where simple models are sufficient for learning. In this paper, we analyze the behavior of vanilla model-based reinforcement learning methods when deep neural networks are used to learn both the model and the policy, and show that the learned policy tends to exploit regions where insufficient data is available for the model to be learned, causing instability in training. To overcome this issue, we propose to use an ensemble of models to maintain the model uncertainty and regularize the learning process. We further show that the use of likelihood ratio derivatives yields much more stable learning than backpropagation through time. Altogether, our approach Model-Ensemble Trust-Region Policy Optimization (ME-TRPO) significantly reduces the sample complexity compared to model-free deep RL methods on challenging continuous control benchmark tasks.
Sample-Efficient Reinforcement Learning with Stochastic Ensemble Value Expansion (NeurIPS 2018)
[Blog][Paper][Code]
Abstract:
Integrating model-free and model-based approaches in reinforcement learning has the potential to achieve the high performance of model-free algorithms with low sample complexity. However, this is difficult because an imperfect dynamics model can degrade the performance of the learning algorithm, and in sufficiently complex environments, the dynamics model will almost always be imperfect. As a result, a key challenge is to combine model-based approaches with model-free learning in such a way that errors in the model do not degrade performance. We propose stochastic ensemble value expansion (STEVE), a novel model-based technique that addresses this issue. By dynamically interpolating between model rollouts of various horizon lengths for each individual example, STEVE ensures that the model is only utilized when doing so does not introduce significant errors. Our approach outperforms model-free baselines on challenging continuous control benchmarks with an order-of-magnitude increase in sample efficiency, and in contrast to previous model-based approaches, performance does not degrade in complex environments.
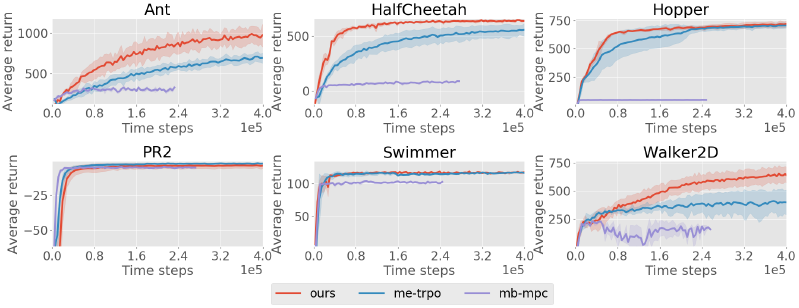
Model-Based Reinforcement Learning via Meta-Policy Optimization(CoRL 2018)
[Blog][Paper][Video][Code][Homepage]
Abstract:
Model-based reinforcement learning approaches carry the promise of being data efficient. However, due to challenges in learning dynamics models that sufficiently match the real-world dynamics, they struggle to achieve the same asymptotic performance as model-free methods. We propose Model-Based Meta- Policy-Optimization (MB-MPO), an approach that foregoes the strong reliance on accurate learned dynamics models. Using an ensemble of learned dynamic models, MB-MPO meta-learns a policy that can quickly adapt to any model in the ensemble with one policy gradient step. This steers the meta-policy towards internalizing consistent dynamics predictions among the ensemble while shifting the burden of behaving optimally w.r.t. the model discrepancies towards the adaptation step. Our experiments show that MB-MPO is more robust to model imperfections than previous model-based approaches. Finally, we demonstrate that our approach is able to match the asymptotic performance of model-free methods while requiring significantly less experience.
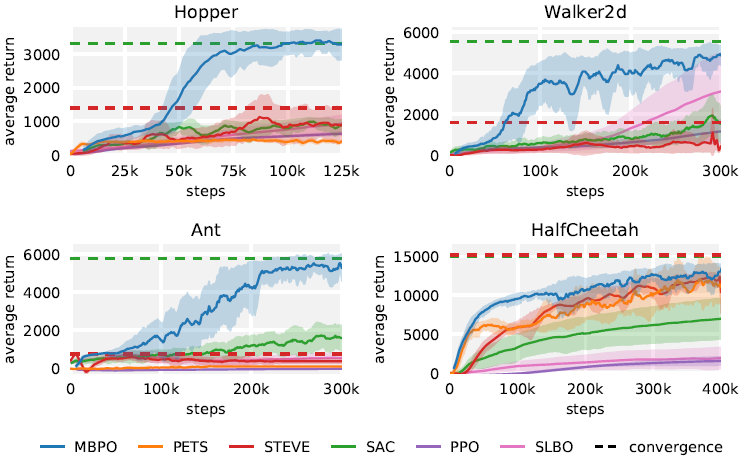
When to Trust Your Model: Model-Based Policy Optimization(2019)
[Blog][Paper][Code]
Abstract:
Designing effective model-based reinforcement learning algorithms is difficult because the ease of data generation must be weighed against the bias of model-generated data. In this paper, we study the role of model usage in policy optimization both theoretically and empirically. We first formulate and analyze a model-based reinforcement learning algorithm with a guarantee of monotonic improvement at each step. In practice, this analysis is overly pessimistic and suggests that real off-policy data is always preferable to model-generated on-policy data, but we show that an empirical estimate of model generalization can be incorporated into such analysis to justify model usage. Motivated by this analysis, we then demonstrate that a simple procedure of using short model-generated rollouts branched from real data has the benefits of more complicated model-based algorithms without the usual pitfalls. In particular, this approach surpasses the sample efficiency of prior model-based methods, matches the asymptotic performance of the best model-free algorithms, and scales to horizons that cause other model-based methods to fail entirely.
Meta Learning
Model-Based Reinforcement Learning via Meta-Policy Optimization(CoRL 2018)
[Blog][Paper][Video][Code][Homepage]
Abstract:
Model-based reinforcement learning approaches carry the promise of being data efficient. However, due to challenges in learning dynamics models that sufficiently match the real-world dynamics, they struggle to achieve the same asymptotic performance as model-free methods. We propose Model-Based Meta- Policy-Optimization (MB-MPO), an approach that foregoes the strong reliance on accurate learned dynamics models. Using an ensemble of learned dynamic models, MB-MPO meta-learns a policy that can quickly adapt to any model in the ensemble with one policy gradient step. This steers the meta-policy towards internalizing consistent dynamics predictions among the ensemble while shifting the burden of behaving optimally w.r.t. the model discrepancies towards the adaptation step. Our experiments show that MB-MPO is more robust to model imperfections than previous model-based approaches. Finally, we demonstrate that our approach is able to match the asymptotic performance of model-free methods while requiring significantly less experience.
最后
以上就是危机秋天最近收集整理的关于强化学习文献笔记:IndexRobotic AssemblingModel-basedMeta Learning的全部内容,更多相关强化学习文献笔记:IndexRobotic内容请搜索靠谱客的其他文章。








发表评论 取消回复