最近放假比较闲,也来班门弄斧聊聊 AI 在 2021 年的发展与未来趋势。
Transformers 一统江湖
虽然不太关注感知类智能方向,但今年被 Transformer 刷屏的新闻也实在太多了。恰好最近看了@李沐 大佬的带你读论文系列,其中就介绍了从 BERT 到 ViT 到后面一系列的 MAE,MoCo 等,深切感受到了学术界对这个“大一统模型”的高涨热情。我们所需要做的就是把任何问题的输入,转化成一个离散 token 序列,然后套上 transformer,对着海量数据训练,就能刷新 SOTA。稍微搜了下发现还有更多的领域都有相关工作,比如:
语音音频方向的 AST[1],HuBERT[2],Jukebox[3]
Text-to-Image[4] 方向的 CogView[5],NÜWA[6]
视频方向的 VideoGPT[7]
表格类问题的 TabTransformer[8],NPT[9]
推荐系统方向的 Transformer4Rec[10]
甚至还有强化学习方向的 Decision Transformer[11]
将各种信息结合起来的 多模态方向[12]
当然 21 年也有 一些工作[13] 说把 transformer 里的注意力模块替换成更简单的组件,例如 pooling,MLP 也能取得很好的效果,所以我们对于 transformer 为何能在这么多任务上达到很好效果的原理还并不明朗,达到真正的大统一还为时尚早。
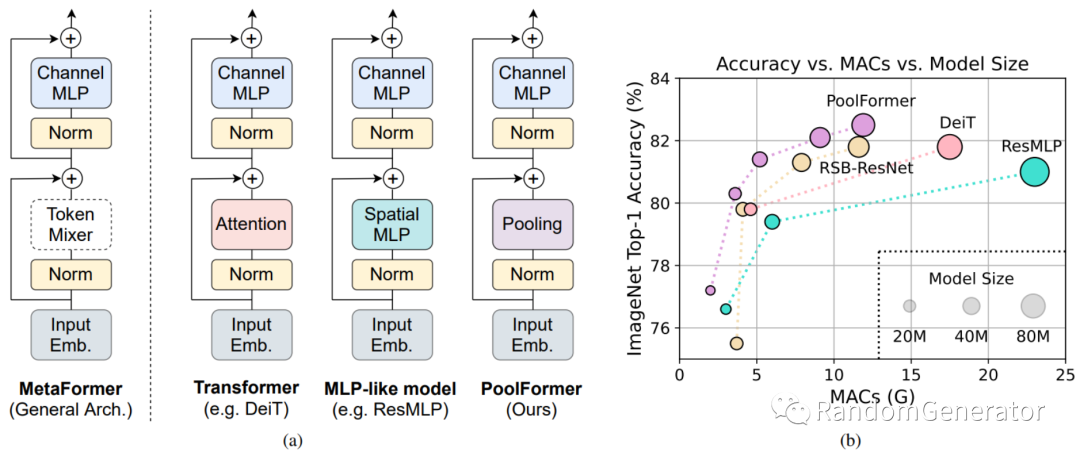
展望一下未来,我甚至有一些大胆的猜想,是不是能把知识表达,逻辑推理,因果推理等能力也融合进来,通过设计一些任务能让 transformer 做常识问题的推理,那样的话我们离通用人工智能的距离或许又近了一步 :)
大模型,更大的模型
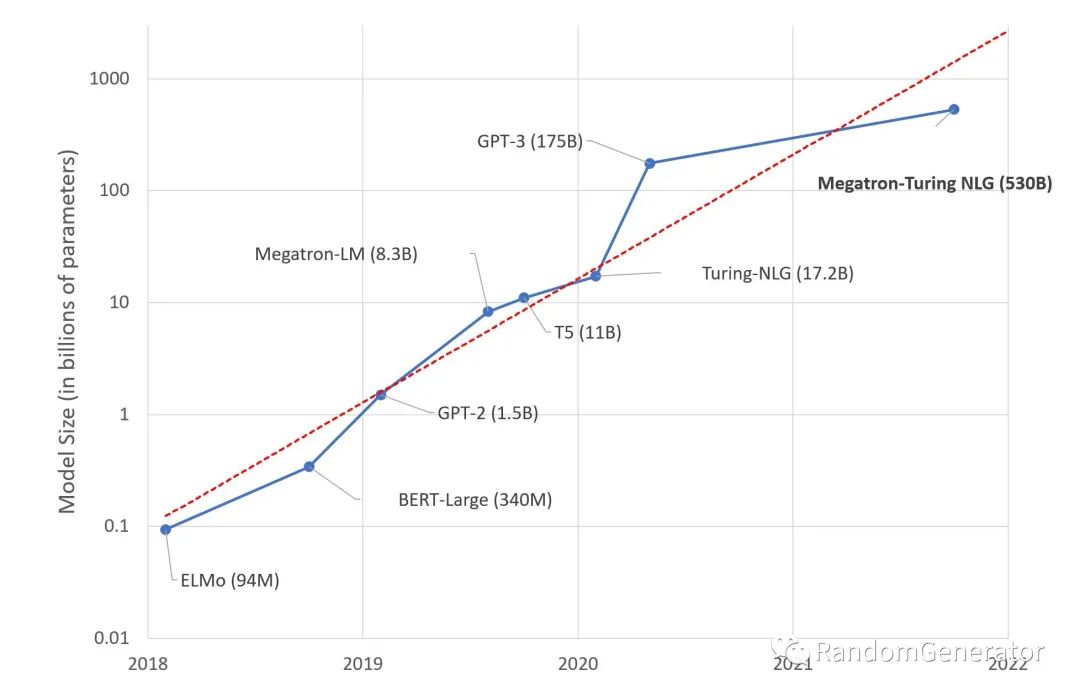
随着 transformer 的流行,大模型的“军备竞赛”被不断的推向高峰,大家发现在大数据集上不断增加模型的参数量,可以不断提升模型的精度,并没有呈现性能饱和的趋势。这里面的工作就不多列举了,可以参考斯坦福的这篇 Foundation Model[14]。对于后续工业界如何使用这些巨大的模型来更快的实现各类 AI 任务,感觉会是下一步的热门方向。
另外,大模型光依靠模型参数来“记忆”一些“长尾知识”可能效率并不高,近期也有一些研究 将大模型与 information retrieval 领域结合[15] 起来,一方面减少模型参数量的需求,另一方面也能更好的提升模型效果,并可以灵活通过迭代数据库的方式来“升级模型”。
自监督,预训练
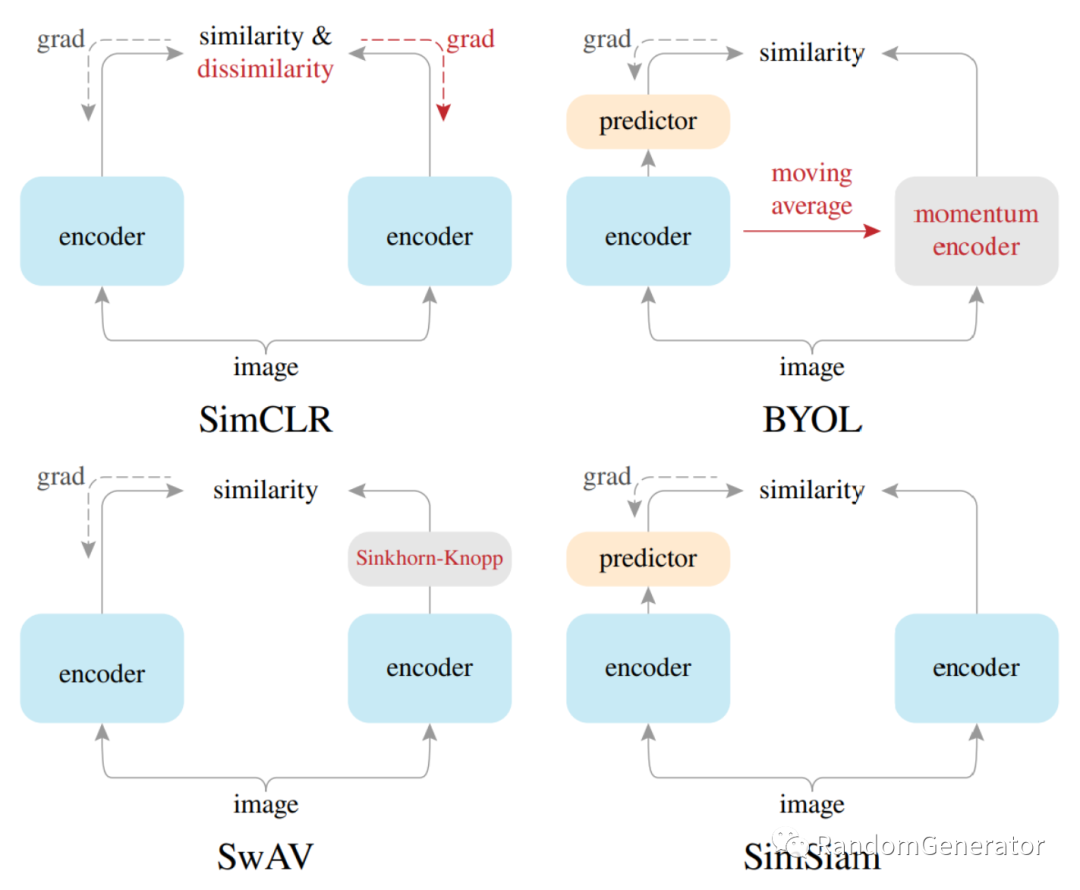
自监督学习的概念由来已久,像经典的 word2vec 就可以看作是一种自监督学习的方式,也备受 Lecun 等大佬的青睐。NLP 领域的自监督学习从 BERT 出现之后被推向了一个高峰,而 CV 领域这两年也开始借鉴这方面的思想,通过学习数据之间的相似和不相似关系来进行自监督学习,也就是时下非常火热的“对比学习”领域。具体可以参考 朱老师的这个视频讲解[16],对这个领域的各篇经典文章如 SimCLR,MoCo,BYOL,DINO,SimSiam 等都做了介绍。进一步来说,这个思想应该也可以应用到更广的领域,比如推荐,图模型等,让模型不需要标签就能从大量的数据中自动学习到一些“概念”。
Transformer,大模型,自监督,预训练加下游任务的 fine tune 整体成为了 21 年最具代表性的深度学习“设计模式”,这或许也会影响到后续工业界应用落地 AI 模型的方式。
Creative AI
以往 AI 主要被应用在各种偏“自动化”的任务中,例如搜索推荐,人脸识别,销量预测,文本情感判断等。很多关于 AI 的科普书中都会提到,很多创意类工作是很难由 AI 来完成的。但是进入到 21 年,出现了越来越多的“创意”类 AI 应用。例如使用 GPT 来生成特定需求的文本,通过 Github Copilot 帮助我们写代码,通过 DiffWave[17] 来生成语音,通过 VQGAN + CLIP[18] 来生成艺术!
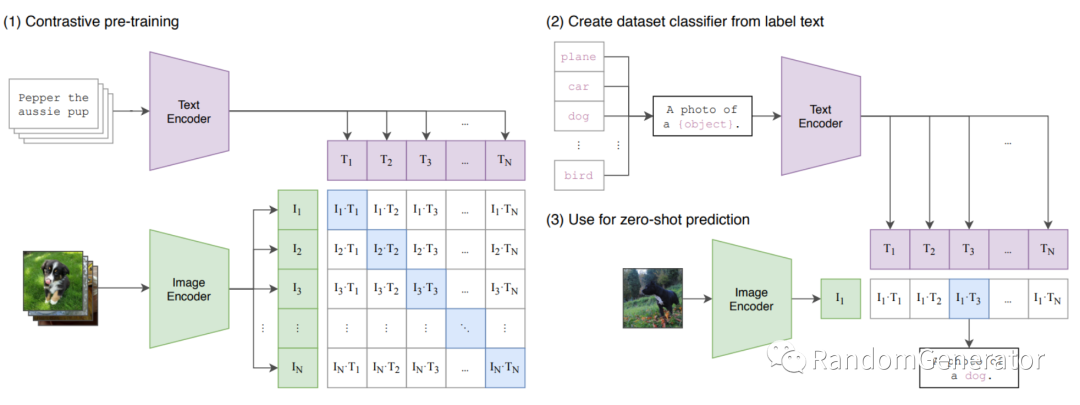
从技术层面来说,这里提到的 CLIP[19] 的出现让语言,图像,音频等不同的信息媒介之间的“打通”提供了很大的想象空间。另外 DiffWave 所用的 Diffusion Model 也是今年在生成模型领域风头力压 GAN 的热门方向。从应用角度来说,或许未来有更多内容生成的场景也会逐渐被 AI 侵占,比如一个看了全 Internet 文章视频的大模型默默就在知乎上写了个图文并茂的“2025 年人类智能有哪些关键性进展和突破?”的回答 :)

Data Centric AI
这两年业界在吴恩达大佬的强力宣导下,以数据为中心来开发 AI 也越来越成为一种主流认识,我之前也专门写了篇文章来记录最近的 Data Centric AI Workshop[20] 的内容。而且从前面的深度学习新趋势来看,的确在数据和训练框架,算力优化方面这两年的进展更加多一些,模型方面则变化不多甚至出现不少“复古”风潮。随着 AI 在越来越多场景得到应用,会遇到越来越多现实中的数据问题,解决这些问题带来的期望提升要远超过直接从学术界搬一个 fancy 模型过来。从长远来看,我们人类智能在做任何决策时,不也是需要依赖高质量的“历史数据”作为参考和推演依据么?
当然 Data Centric AI 的本质思想还是希望我们能像排查软件问题那样排查模型问题,并进行有明确反馈的改进动作,所以个人觉得针对模型的 debug 工具也会非常有用,两者并不是完全对立的两面。
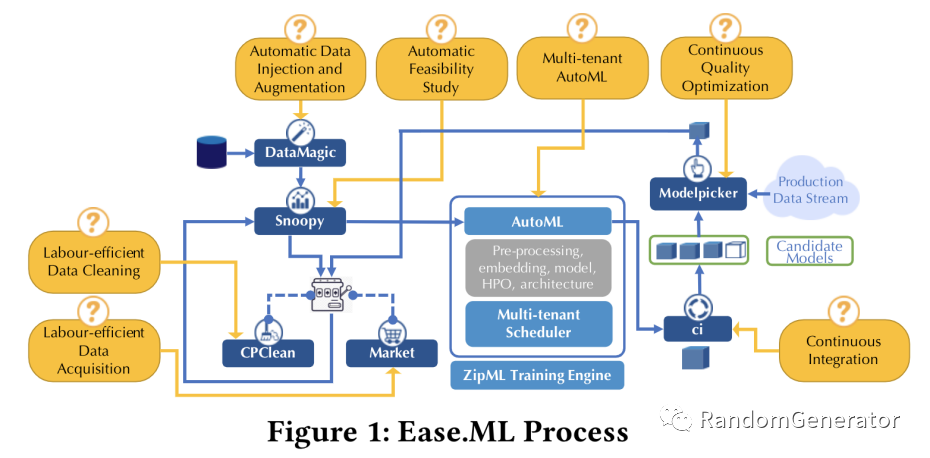
MLOps
随着 AI 在业界的落地范围扩大,如何让“普通公司”也能把 AI 用起来,把模型维护起来也成了一个新兴的大市场。毕竟不是每家公司都有像 Google,Facebook 那样的技术基础架构和算法专家储备。在这个方向上涌现出了 非常多的创业公司[21],各大云服务商也在各自的 AI 平台上不断增强算法运维方面的能力。我之前也调研总结了篇 MLOps 的科普文章[22]。目前来看大家主要把 MLOps 相关的框架集中在三个方向上,分别是 Feature Store, Model Store 和 Evaluation Store,这里也不做太多详细的展开了。
结合前面所说的深度学习范式,或许未来两年还会出现快速做 AI 模型 fine tune 并集成上线的 composite AI 类工具产品,让我们拭目以待 :)

Responsible AI
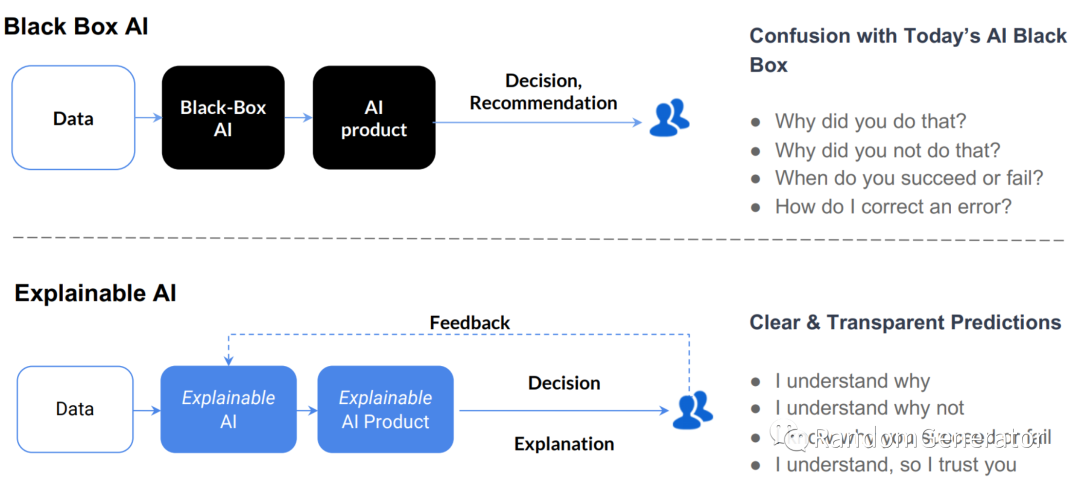
这个趋势也与 AI 在越来越多场景受到应用相关,尤其在企业决策,医疗,金融风控,政府等方向上,如何做可解释的人工智能,没有偏见和安全可靠的算法模型也越来越成为一个重要话题。Google 给出了他们对于 实现 Responsible AI 的行动建议[23]。我在去年也做了一个 可解释机器学习方面的分享[24]。
从未来看,可解释机器学习肯定不单单是面向开发人员的模型内部机理的解释,毕竟人脑如何工作也还是个黑盒,我们更需要的是类似于能够与模型“交流”的解释方式。而负责且安全可靠的模型方面,一方面需要在数据工程,隐私计算等技术方向上继续探索与开拓,另一方面也与 AI 的教育普及,相关政策法规的商讨制订息息相关。
AI 与决策智能
前面说到 AI 落地范围的扩大,不得不提一下在感知类智能之外的认知智能应用。事实上在很多商业公司的场景中,如何通过数据和 AI 来帮助企业提高决策质量是一个潜力非常巨大的市场。相信很多同学在日常生活中也开始潜移默化的使用一些这方面的模型来辅助你做决策,例如买基金会看一些数据或者模型推荐的结果,出门时用高德地图之类的预估一下交通路线和耗时,日常生活中通过各种可穿戴设备的提醒来保持良好的健康习惯,买东西时参考一下 App 给出的推荐等。在企业决策中,这类应用场景也为数众多,且每一个都能为公司的运营带来可见的效益提升。
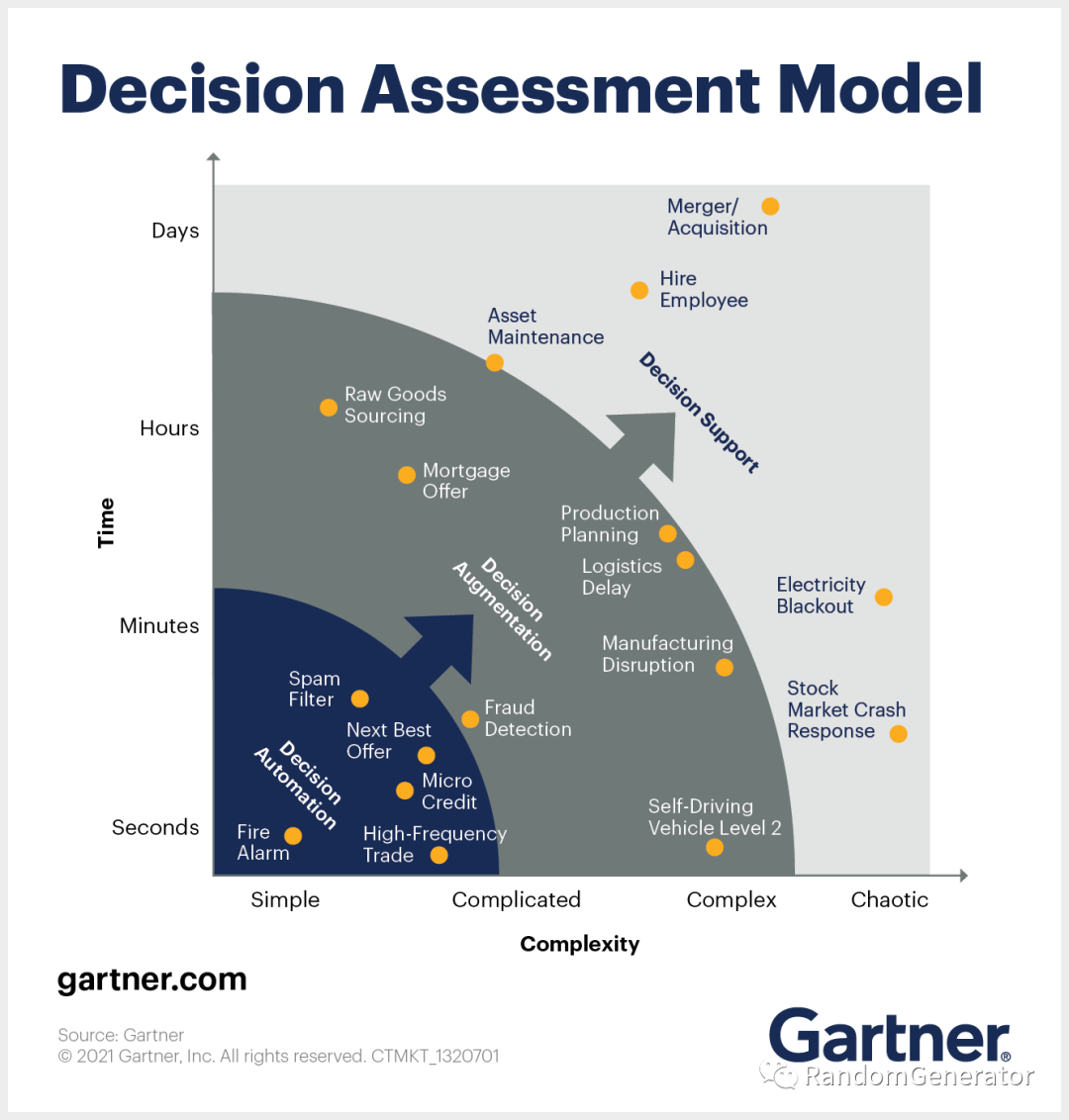
我们观远就持续在 Business Intelligence 和 Decision Intelligence 方向深耕,利用各种 AI 技术,深入业务场景来辅助决策者作出更高质量的判断和行动。这方面有很多有意思的技术和商业问题的挑战,非常欢迎有兴趣的同学加入我们,打造业界最好的 AI + BI 决策智能平台 :)
参考资料
[1]
AST: https://arxiv.org/abs/2104.01778
[2]HuBERT: https://arxiv.org/abs/2106.07447
[3]Jukebox: https://arxiv.org/abs/2005.00341
[4]Text-to-Image: https://arxiv.org/abs/2102.12092
[5]CogView: https://arxiv.org/abs/2105.13290
[6]NÜWA: https://arxiv.org/abs/2111.12417
[7]VideoGPT: https://arxiv.org/abs/2104.10157
[8]TabTransformer: https://arxiv.org/abs/2012.06678
[9]NPT: https://arxiv.org/abs/2106.02584
[10]Transformer4Rec: https://github.com/NVIDIA-Merlin/Transformers4Rec
[11]Decision Transformer: https://arxiv.org/abs/2106.01345
[12]多模态方向: https://arxiv.org/abs/2007.10639
[13]一些工作: https://arxiv.org/abs/2111.11418
[14]Foundation Model: https://arxiv.org/abs/2108.07258
[15]将大模型与 information retrieval 领域结合: https://arxiv.org/abs/2112.04426
[16]朱老师的这个视频讲解: https://www.bilibili.com/video/BV19S4y1M7hm
[17]DiffWave: https://arxiv.org/abs/2009.09761
[18]VQGAN + CLIP: https://github.com/nerdyrodent/VQGAN-CLIP
[19]CLIP: https://arxiv.org/abs/2103.00020
[20]Data Centric AI Workshop: https://zhuanlan.zhihu.com/p/435894738
[21]非常多的创业公司: https://huyenchip.com/2020/12/30/mlops-v2.html
[22]MLOps 的科普文章: https://zhuanlan.zhihu.com/p/357897337
[23]实现 Responsible AI 的行动建议: https://ai.google/responsibilities/responsible-ai-practices/
[24]可解释机器学习方面的分享: https://www.zhihu.com/zvideo/1358741331959980032
最后
以上就是敏感荔枝最近收集整理的关于2021年AI进展漫谈的全部内容,更多相关2021年AI进展漫谈内容请搜索靠谱客的其他文章。








发表评论 取消回复