理解论文 Residual Attention Network for Image Classification
Abstract
1.提出了 Residual Attention Network。
2.这是一种使用attention机制卷积神经网络,该卷积神经网络能够以端到端的训练方式与现有技术的前馈网络结构相结合。
3.Residual Attention Network通过堆叠产生attention感知特征的attention模块来构建的。
4.来自不同模块的attention感知features随着层的深入而自适应地改变。
5.在每个attention模块内部,采用自底向上、自顶向下的前馈结构,将前馈和反馈attention过程展开为单个前馈过程。
6.提出了attention residual learning来训练非常深的Residual Attention Network,它可以很容易地扩展到数百层。
一、Introduction
1.注意力机制带来了更有辨识度的特征表现力。
2.越来越多的注意力模块导致一致的性能改进,因为不同类型的注意力被广泛捕获。 如下图1所示,

3.能能整合进最现金的网络结构来形成端到端的训练模式。并且网络的深度容易扩展到数百层。
4.该文章的贡献:
(1)Stacked network structure:通过堆叠多个Attention Modules来构造Residual Attention Network。堆叠结构是混合注意力机制的基本应用。因此,不同类型的注意力能够被不同的注意力模块捕获。
(2)Attention Residual Learning:直接叠加注意力模块会导致明显的学习性能下降。 因此,提出了attention residual learning mechanism来优化几百层的非常深层的Residual Attention Network。
(3)Bottom-up top-down feedforward attention:自底向上、自顶向下的前馈结构已经成功地应用于人体姿态估计和图像分割。 该文章使用这样的结构作为注意力模块的一部分来增加特征的soft weights。 这种结构可以在单个前馈过程中模仿自底向上的快速前馈过程和自顶向下的注意力反馈,从而使我们能够开发具有自顶向下注意力的端到端可训练网络。
三、Residual Attention Network
1.Residual Attention Network是通过堆叠多个Attention Modules模块来构造的。
2.每个注意力模块被分成两个分支:mask branch和trunk branch。
3.trunk branch执行特征处理,并且可以适应任何最先进的网络结构。 本文以预激活剩余单元[11]、ResNext[36]和Inception[32]作为Residual Attention Networks的基本单元来构造Attention Module。
4.给定具有输入x的trunk branch输出T(x),mask branch使用自下而上自顶向下结构[22,25,1,24]来学习相同size的mask M(X)并且soft weight output features T(x)。
5.自下而上、自上而下的结构模仿快速前馈和反馈attention过程。
6.输出的mask用作类似于Highway Network [29]的trunk branch的神经元的control gates。 Attention Module H的输出为:
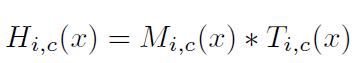
其中,i代表所有的空间位置,c代表channel的索引。整个机构能够内端到端训练。
7.在attention module中,attention mask不仅可以作为前向推理过程中的特征选择器,还可以作为反向传播过程中的梯度更新滤波器。 在soft mask branch中,input feature的mask的梯度为:
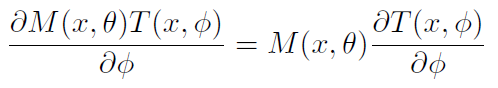
其中, θ是mask branch的参数,φ是trunk branch的参数。这个属性使得attention modules对噪音标签是鲁棒的。mask branch可以防止错误的梯度(来自噪音的标签)来更新trunk的参数。
8.Attention Residual Learning
(1)纯粹(naive)的堆积Attention Modules导致明显的性能下降。原因是:
①首先,mask范围从0到1的重复dot production会降低深层特征的价值。
②其次,soft mask可能会破坏trunk branch的良好特性,如Residual Unit的identical mapping。
(2)本文提出了attention residual learning来消除上述问题。和residual learning类似,如果mask 能够被构造为identical mapping,性能应该不会比没有attention更坏。因此修改Attention Module的输出H为:
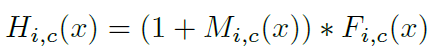
其中,M(x)的范围是[0,1],M(x)接近0时,H(x)将会接近原始特征F(x),称这种方法为 attention residual learning。
(3)本文的stacked attention residual learning不同于residual learning。在原始的ResNet中,residual learning的形式是:![]() ,其中
,其中![]() 近似为residual function。在本文中,
近似为residual function。在本文中,![]() 表示通过深层卷积网络产生的特征。关键点在于本文的mask branchs M(x)。他们作为特征选择器来加强来自于trunk branchs上的良好的特征并且抑制噪音。
表示通过深层卷积网络产生的特征。关键点在于本文的mask branchs M(x)。他们作为特征选择器来加强来自于trunk branchs上的良好的特征并且抑制噪音。
(4)除此之外,stacking Attention Modules以其递增的性质支持attention residual learning。 attention residual learning能够保持原始特征良好的属性,又给与他们绕过soft mask branch,向顶层传播,削弱mask branch的特征选择能力。 Stacked Attention Modules能够慢慢地精炼feature maps。就像图1所示,随着深度变得更深,特征变得越来越清晰。
(5)通过使用attention residual learning,增加所提出的Residual Attention Network的深度可以持续地提高性能。
9.Soft Mask Branch
(1)根据DBN[21]中的注意机制思想,本文中的的mask branch包含快速feed-forward扫描和自顶向下的feedback步骤。 前面的操作快速手机整幅图像的全局特征,后面的操作整合全局信息和原始feature maps。在卷积神经网络中,这两个步骤展开为bottom-up、top-down的全卷积的结构。
(2)从输入开始,少量的Residual Units之后使用了几次max pooling来快速增加感知野。在达到最低分辨率之后,全局信息通过对称的top-down架构展开,以指导每个位置的输入特征。 使用线性插值上采样 Residual Units的之后的输出。双线性插值的数目与max pooling相同,以保持输出大小与输入feature map相同。
(3)紧接着,一个sigmoid层将两个连续的1*1卷积层之后的输出normalizes到[0,1]之间。
(4)在bottom-up和 top-down之间也添加了skip connection来捕获来自不同尺度的信息。完整的模块如图2所示,

(5) bottom-up、top-down结构已经被应用于图像分割和human pose estimation。然后该文章的和前面的区别在于它的目的。该文章的mask branch在于提高trunk branch features而不是直接解决一个复杂的问题。
10.Spatial Attention and Channel Attention
(1)本文提出的网络中,mask branch提供的attention随着trunk branch的特征自适应的改变。然而,通过在soft mask output之前改变激活函数中的归一化步骤,仍然可以将attention约束添加到mask branch。 我们使用与mixed attention、channel attention和spatial attention相对应的三种激活函数。
①Mixed attention f1未使用附加的约束,只是用简单的sigmoid针对每个通道和空间位置。
②Channel attention f2 在所有channels内对每个空间位置执行L2归一化以移除空间信息。
③Spatial f3在来自每个通道的feature map内执行normalization,然后执行Sigmoid以获得仅与空间信息相关的soft mask。
上述三种方式的公式如下所示:

上述公式中,i的范围是所有的空间位置,c的范围是所有的通道。meanc和stdc表示来自第c个通道的feature map的特征值和方差。xi表示di一个空间位置的feature vector。
④上述三种方式的实验结果对比如下表1所示,其中mixed attention拥有最好的性能。

(2)以前的网络通常只关注一种类型的attention,例如:scale attention [3] or spatial attention [17],通过weight sharing or normalization来在soft mask上施加约束。
(3)然而,正如本文的实验表明,在不附加额外约束的情况下,通过特征自适应地改变注意力可以获得最佳的性能。
四、Experiments
1.在CIFAR-10, CIFAR-100 , and ImageNet上做实验。
2.实验包含两部分,
(1)第一部分,分析Residual Attention Network网络中每一个组成部分的有效性,包括attention residual learning mechanism和Attention Module中soft mask branch的不同结构。之后探索抗噪声特性。
(2)在第二部分中,用Inception模块和ResNeXt替换了Residual Unit,并在此基础上证明了本文提出的Residual Attention Network在参数效率和最终性能上都优于原始网络结构。 本文还将图像分类性能与ImageNet数据集上最新的ResNet和Inception进行了比较。
3.Implementation.
(1)整个的网络结构和参数设置如图2所示。训练数据,首先将32*32的数据0填充到40*40,然后随机裁剪32*32的大小来训练。
(2)和ResNet类似,本文的网络包含3个阶段。在每个阶段,对接了相等数量的Attention Modules。除此之外,每个阶段增加两个Residual Units。在trunk branch中weighted layers的数量是36m+20,其中m是在一个阶段中Attention Module的数量。
(3)测试时,使用原始大小32*32的图像进行测试。
最后
以上就是狂野冬瓜最近收集整理的关于Residual Attention Network for Image Classification的全部内容,更多相关Residual内容请搜索靠谱客的其他文章。





![[机器学习入门笔记] 3. 监督学习集成模型部分前言第 11 章 AdaBoost第 12 章 GBDT第 13 章 XGBoost](https://www.shuijiaxian.com/files_image/reation/bcimg20.png)


发表评论 取消回复