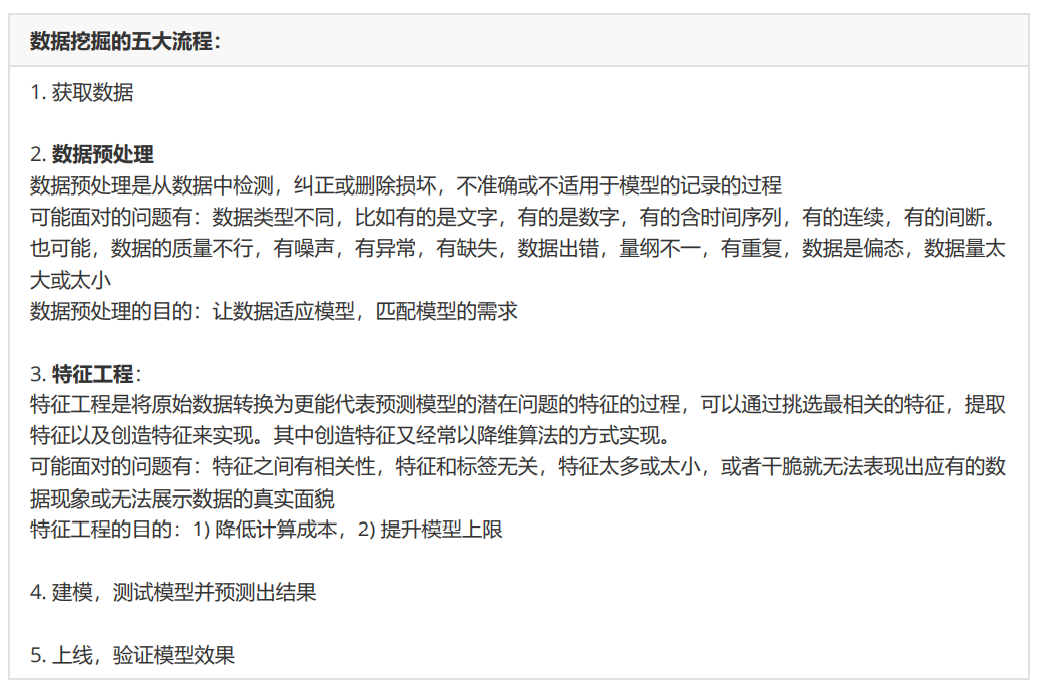
sklearn中的数据预处理和特征工程:


数据预处理
数据无量纲化


from sklearn.preprocessing import MinMaxScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
#不太熟悉numpy的小伙伴,能够判断data的结构吗?
#如果换成表是什么样子?
import pandas as pd
pd.DataFrame(data)
# 0 1
#0 -1.0 2
#1 -0.5 6
#2 0.0 10
#3 1.0 18
#实现归一化
scaler = MinMaxScaler() #实例化
scaler = scaler.fit(data) #fit,在这里本质是生成min(x)和max(x)
result = scaler.transform(data) #通过接口导出结果
result
#array([[0. , 0. ],
# [0.25, 0.25],
# [0.5 , 0.5 ],
# [1. , 1. ]])
result_ = scaler.fit_transform(data) #训练和导出结果一步达成
scaler.inverse_transform(result) #将归一化后的结果逆转
#使用MinMaxScaler的参数feature_range实现将数据归一化到[0,1]以外的范围中
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler = MinMaxScaler(feature_range=[5,10]) #依然实例化
标准化:

from sklearn.preprocessing import StandardScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler = StandardScaler() #实例化
scaler.fit(data) #fit,本质是生成均值和方差
scaler.mean_ #查看均值的属性mean_
#array([-0.125, 9. ])
scaler.var_ #查看方差的属性var_
#array([ 0.546875, 35. ])
x_std = scaler.transform(data) #通过接口导出结果
x_std.mean() #导出的结果是一个数组,用mean()查看均值
#0.0
x_std.std() #用std()查看方差
#1.0
scaler.fit_transform(data) #使用fit_transform(data)一步达成结果
scaler.inverse_transform(x_std) #使用inverse_transform逆转标准化


缺失值处理
class sklearn.impute.SimpleImputer (missing_values=nan, strategy=’mean’, fill_value=None, verbose=0,
copy=True)

import pandas as pd
from sklearn.impute import SimpleImputer
data = pd.read_csv("./Narrativedata.csv",index_col=0)
age = data.iloc[:,0]
Age = age.values.reshape(-1,1)#sklearn当中特征矩阵必须是二维
imp_mean = SimpleImputer() #实例化,默认均值填补
imp_median = SimpleImputer(strategy="median") #用中位数填补
imp_0 = SimpleImputer(strategy="constant",fill_value=0) #用0填补
imp_mean = imp_mean.fit_transform(Age) #fit_transform一步完成调取结果
imp_median = imp_median.fit_transform(Age)
imp_0 = imp_0.fit_transform(Age)
#在这里我们使用中位数填补Age
data.loc[:,"Age"] = imp_median
data.info()
#<class 'pandas.core.frame.DataFrame'>
#Int64Index: 891 entries, 0 to 890
#Data columns (total 4 columns):
# Column Non-Null Count Dtype
#--- ------ -------------- -----
# 0 Age 891 non-null float64
# 1 Sex 891 non-null object
# 2 Embarked 889 non-null object
# 3 Survived 891 non-null object
#dtypes: float64(1), object(3)
#memory usage: 74.8+ KB
#使用众数填补Embarked
Embarked = data.loc[:,"Embarked"].values.reshape(-1,1)
imp_mode = SimpleImputer(strategy = "most_frequent")
data.loc[:,"Embarked"] = imp_mode.fit_transform(Embarked)
#用pandas和numpy进行填补
import pandas as pd
data = pd.read_csv("./Narrativedata.csv",index_col=0)
data.loc[:,"Age"] = data.loc[:,"Age"].fillna(data.loc[:,"Age"].median())
#.fillna 在DataFrame里面直接进行填补'
data.dropna(axis=0,inplace=True)
#.dropna(axis=0)删除所有有缺失值的行,.dropna(axis=1)删除所有有缺失值的列
#参数inplace,为True表示在原数据集上进行修改,为False表示生成一个复制对象,不修改原数据,默认False
离散数据处理:将文字型数据转换为数值型
1.preprocessing.LabelEncoder:标签专用,能够将分类转换为分类数值
from sklearn.preprocessing import LabelEncoder
y = data.iloc[:,-1] #要输入的是标签,不是特征矩阵,所以允许一维
le = LabelEncoder() #实例化
le = le.fit(y) #导入数据
label = le.transform(y) #transform接口调取结果
le.classes_ #属性.classes_查看标签中究竟有多少类别
#array(['No', 'Unknown', 'Yes'], dtype=object)
data.iloc[:,-1] = label #让标签等于我们运行出来的结果
data.head()
# Age Sex Embarked Survived
#0 22.0 male S 0
#1 38.0 female C 2
#2 26.0 female S 2
#3 35.0 female S 2
#4 35.0 male S 0
2.preprocessing.OrdinalEncoder:特征专用,能够将分类特征转换为分类数值
from sklearn.preprocessing import OrdinalEncoder
#接口categories_对应LabelEncoder的接口classes_,一模一样的功能
data_ = data.copy()
OrdinalEncoder().fit(data_.iloc[:,1:-1]).categories_
#[array(['female', 'male'], dtype=object), array(['C', 'Q', 'S'], dtype=object)]
data_.iloc[:,1:-1] = OrdinalEncoder().fit_transform(data_.iloc[:,1:-1])
data_.head()
# Age Sex Embarked Survived
#0 22.0 1.0 2.0 0
#1 38.0 0.0 0.0 2
#2 26.0 0.0 2.0 2
#3 35.0 0.0 2.0 2
#4 35.0 1.0 2.0 0
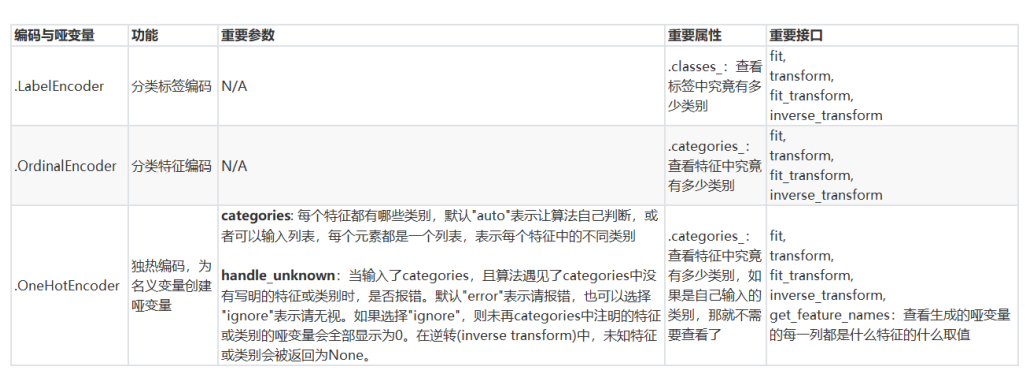
3.preprocessing.OneHotEncoder:独热编码,创建哑变量



from sklearn.preprocessing import OneHotEncoder
X = data.iloc[:,1:-1]
enc = OneHotEncoder(categories='auto').fit(X)
result = enc.transform(X).toarray()
#array([[0., 1., 0., 0., 1.],
# [1., 0., 1., 0., 0.],
# [1., 0., 0., 0., 1.],
#依然可以直接一步到位,但为了给大家展示模型属性,所以还是写成了三步
#OneHotEncoder(categories='auto').fit_transform(X).toarray()
enc.get_feature_names()
#array(['x0_female', 'x0_male', 'x1_C', 'x1_Q', 'x1_S'], dtype=object)
#axis=1,表示跨行进行合并,也就是将量表左右相连,如果是axis=0,就是将量表上下相连
newdata = pd.concat([data,pd.DataFrame(result)],axis=1)
# Age Sex Embarked Survived 0 1 2 3 4
#0 22.0 male S 0 0.0 1.0 0.0 0.0 1.0
#1 38.0 female C 2 1.0 0.0 1.0 0.0 0.0
#2 26.0 female S 2 1.0 0.0 0.0 0.0 1.0
#3 35.0 female S 2 1.0 0.0 0.0 0.0 1.0
#4 35.0 male S 0 0.0 1.0 0.0 0.0 1.0
newdata.drop(["Sex","Embarked"],axis=1,inplace=True)
newdata.columns = ["Age","Survived","Female","Male","Embarked_C","Embarked_Q","Embarked_S"]
# Age Survived Female Male Embarked_C Embarked_Q Embarked_S
#0 22.0 0 0.0 1.0 0.0 0.0 1.0
#1 38.0 2 1.0 0.0 1.0 0.0 0.0
#2 26.0 2 1.0 0.0 0.0 0.0 1.0
#3 35.0 2 1.0 0.0 0.0 0.0 1.0
#4 35.0 0 0.0 1.0 0.0 0.0 1.0
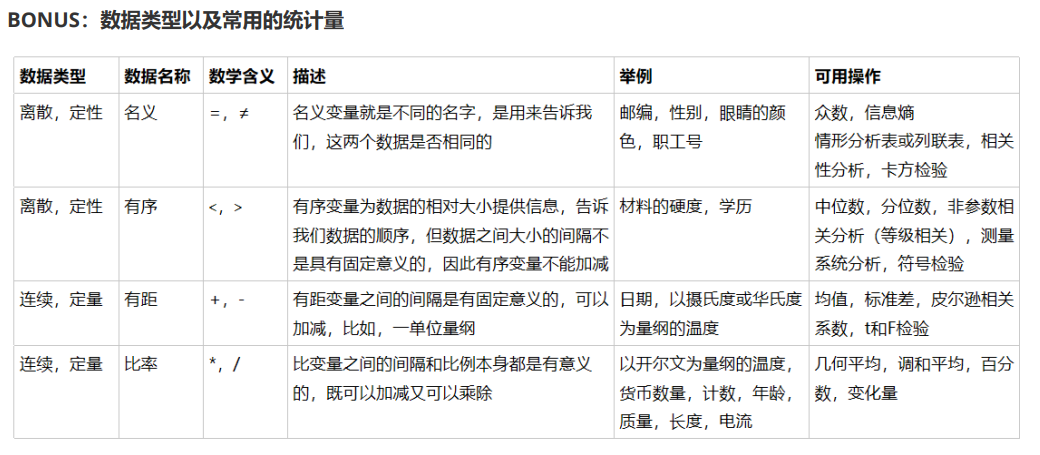
连续数据处理:二值化或分段
sklearn.preprocessing.Binarizer

from sklearn.preprocessing import Binarizer
data_2 = data.copy()
X = data_2.iloc[:,0].values.reshape(-1,1) #类为特征专用,所以不能使用一维数组
transformer = Binarizer(threshold=30).fit_transform(X) #将年龄中大于30的分类为1,小于等于30的分类为0
#array([0., 1., 0., 1., 1., 0., 1., 0., 0., 0., 0., 1., 0., 1., 0., 1., 0.,
# 0., 1., 0., 1., 1., 0., 0., 0., 1., 0., 0., 0., 0., 1., 0., 0., 1.,
# 0., 1., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0. ...]
preprocessing.KBinsDiscretizer
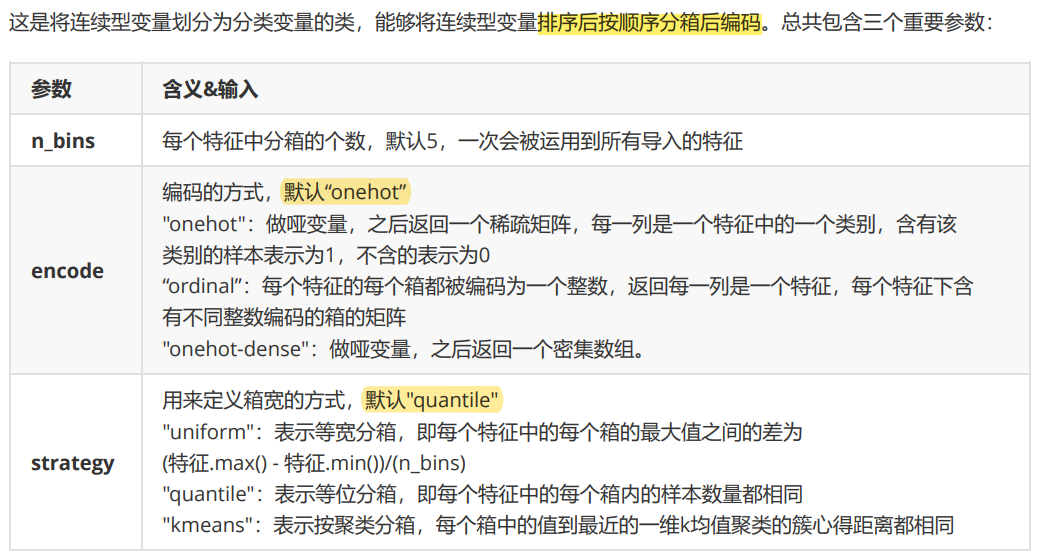
from sklearn.preprocessing import KBinsDiscretizer
X = data.iloc[:,0].values.reshape(-1,1)
est = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='uniform')
est.fit_transform(X)
#查看转换后分的箱:变成了一列中的三箱
set(est.fit_transform(X).ravel())
#{0.0, 1.0, 2.0}
#uniform:表示等宽分箱
est = KBinsDiscretizer(n_bins=3, encode='onehot', strategy='uniform')
#查看转换后分的箱:变成了哑变量
est.fit_transform(X).toarray()
#array([[1., 0., 0.],
# [0., 1., 0.],
# [1., 0., 0.],
特征选择

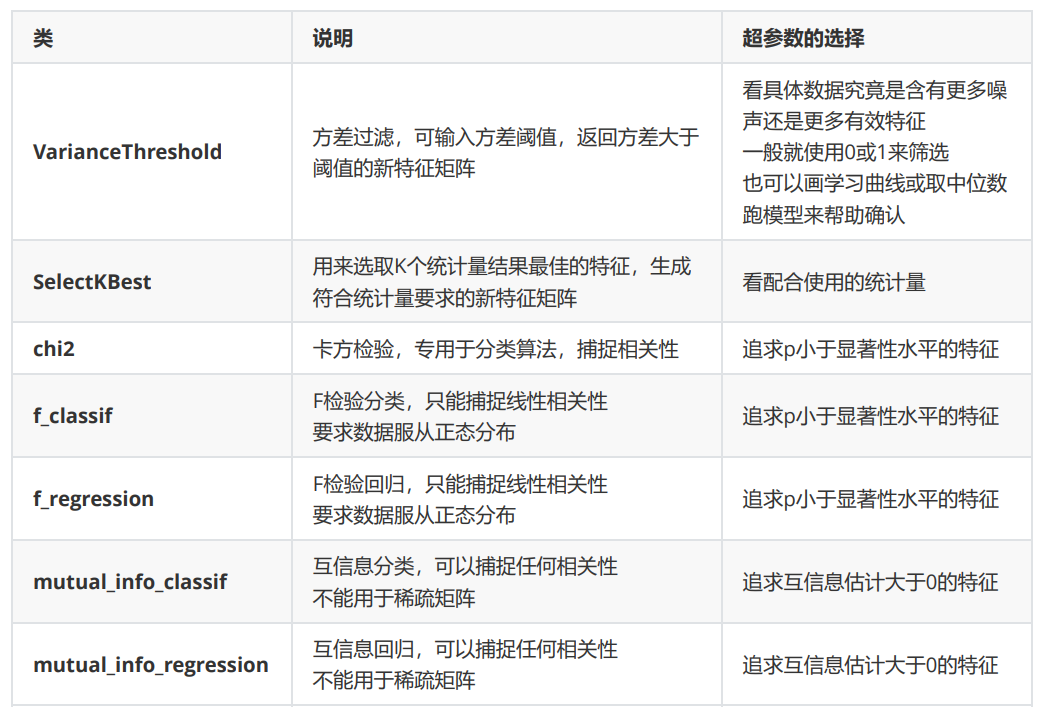
Filter过滤法

方差过滤:

import pandas as pd
from sklearn.feature_selection import VarianceThreshold
data = pd.read_csv("./digit recognizor.csv")
x = data.iloc[:,1:]
y = data.iloc[:,0]
#取除特征中方差为0的特征,即所有值都相等的特征
selector = VarianceThreshold() #实例化,不填参数默认方差为0
X_var0 = selector.fit_transform(x) #获取删除不合格特征之后的新特征矩阵
X_var0.shape
#(42000, 784)-》 (42000, 708)
设置阈值来削减特征:
import numpy as np
X.var().values
#pixel0 0.000000
#pixel1 0.000000
#pixel2 0.000000 ...
np.median(X.var().values)
#1352.2867031797243
#以方差的中位数为阈值,可以削减一半的特征
X_fsvar = VarianceThreshold(np.median(X.var().values)).fit_transform(X)
X_fsvar.shape
#(42000, 392)

#若特征是伯努利随机变量,假设p=0.8,即二分类特征中某种分类占到80%以上的时候删除特征
X_bvar = VarianceThreshold(.8 * (1 - .8)).fit_transform(x)
X_bvar.shape
#(42000, 685)


相关性过滤

卡方过滤

from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import cross_val_score
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
#假设在这里我一直我需要300个特征
X_fschi = SelectKBest(chi2, k=300).fit_transform(X_fsvar, y)
X_fschi.shape
#(42000, 300)
#验证模型效果
cross_val_score(RFC(n_estimators=10,random_state=0),X_fschi,y,cv=5).mean()
#0.9344761904761905
选取超参数K
#绘制学习曲线
%matplotlib inline
import matplotlib.pyplot as plt
score = []
#range(350,200,-10) [350, 340, 330, 320, 310, 300, 290, 280, 270, 260, 250, 240, 230, 220, 210]
for i in range(350,200,-10):
X_fschi = SelectKBest(chi2, k=i).fit_transform(X_fsvar, y)
once = cross_val_score(RFC(n_estimators=10,random_state=0),X_fschi,y,cv=5).mean()
score.append(once)
plt.plot(range(350,200,-10),score)
plt.show()
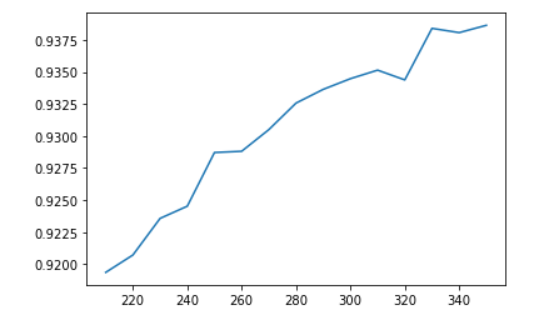


chivalue, pvalues_chi = chi2(X_fsvar,y)
chivalue #卡方值
#array([ 945664.84392643, 1244766.05139164, 1554872.30384525,
# 1834161.78305343, 1903618.94085294, 1845226.62427198,
# 1602117.23307537, 708535.17489837, 974050.20513718 ...]
pvalues_chi #P值
#array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
# 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
# 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0....]
#k取多少?我们想要消除所有p值大于设定值,比如0.05或0.01的特征:
k = chivalue.shape[0] - (pvalues_chi > 0.05).sum()
#392
#X_fschi = SelectKBest(chi2, k=填写具体的k).fit_transform(X_fsvar, y)
#cross_val_score(RFC(n_estimators=10,random_state=0),X_fschi,y,cv=5).mean()

F检验
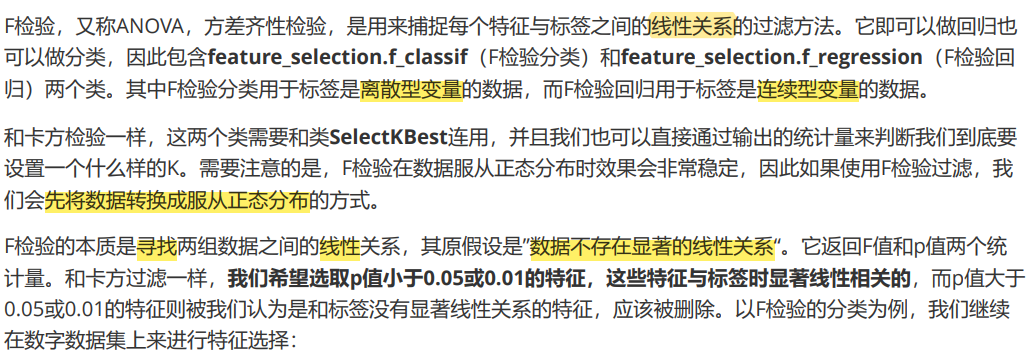
from sklearn.feature_selection import f_classif
F, pvalues_f = f_classif(X_fsvar,y)
F
#array([1.12236836, 1.69713477, 0.19542821, ..., 3.03522216, 3.73716286, 0.56568448])
pvalues_f
#array([0.28966539, 0.19296363, 0.65853243, ..., 0.08178345, 0.05349733,0.45215625])
k = F.shape[0] - (pvalues_f > 0.05).sum()
#392
互信息法

from sklearn.feature_selection import mutual_info_classif as MIC
result = MIC(X_fsvar,y)
k = result.shape[0] - sum(result <= 0)
#392
#X_fsmic = SelectKBest(MIC, k=填写具体的k).fit_transform(X_fsvar, y)
#cross_val_score(RFC(n_estimators=10,random_state=0),X_fsmic,y,cv=5).mean()

Embedded嵌入法
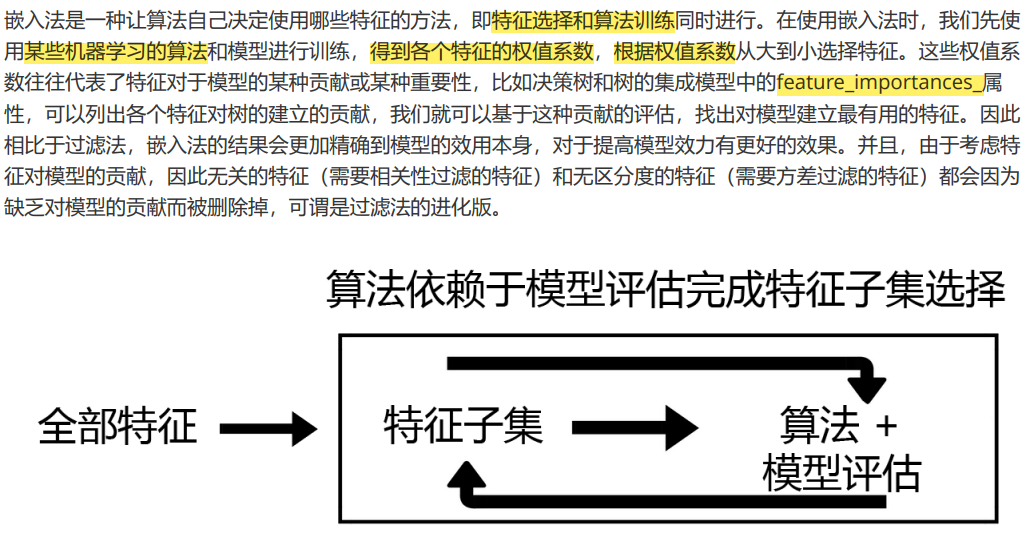
class sklearn.feature_selection.SelectFromModel (estimator, threshold=None, prefit=False, norm_order=1,
max_features=None)


from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier as RFC
RFC_ = RFC(n_estimators =10,random_state=0)
X_embedded = SelectFromModel(RFC_,threshold=0.005).fit_transform(X,y)
#在这里我只想取出来有限的特征。0.005这个阈值对于有780个特征的数据来说,是非常高的阈值,因为平均每个特征只能够分到大约0.001的feature_importances_
X_embedded.shape
#模型的维度明显被降低了
#(42000, 47)
#同样的,我们也可以画学习曲线来找最佳阈值
#======【TIME WARNING:10 mins】======#
import numpy as np
import matplotlib.pyplot as plt
RFC_.fit(X,y).feature_importances_
#array([0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
# 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
# 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00...]
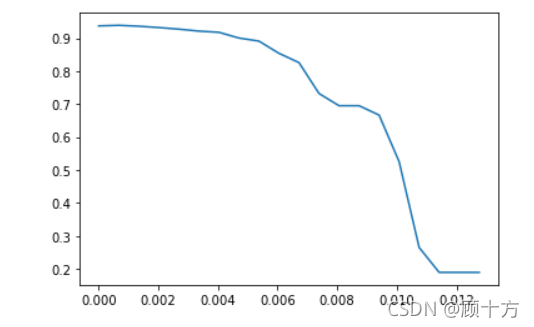
threshold = np.linspace(0,(RFC_.fit(X,y).feature_importances_).max(),20)
score = []
for i in threshold:
X_embedded = SelectFromModel(RFC_,threshold=i).fit_transform(X,y)
once = cross_val_score(RFC_,X_embedded,y,cv=5).mean()
score.append(once)
plt.plot(threshold,score)
plt.show()
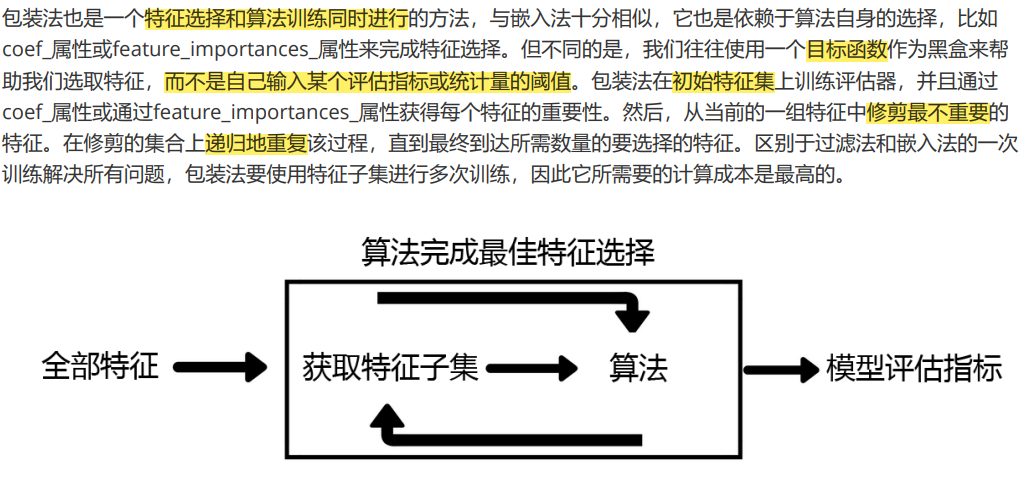
Wrapper包装法

class sklearn.feature_selection.RFE (estimator, n_features_to_select=None, step=1, verbose=0)

from sklearn.feature_selection import RFE
RFC_ = RFC(n_estimators =10,random_state=0)
selector = RFE(RFC_, n_features_to_select=340, step=50).fit(X, y)
selector.support_.sum()
#340
selector.ranking_
#array([10, 9, 8, 7, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6,
# 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 7, 7, 6, 6,
# 5, 6, 5, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 7, 6, 7, 7,
X_wrapper = selector.transform(X)
cross_val_score(RFC_,X_wrapper,y,cv=5).mean()
#0.9379761904761905
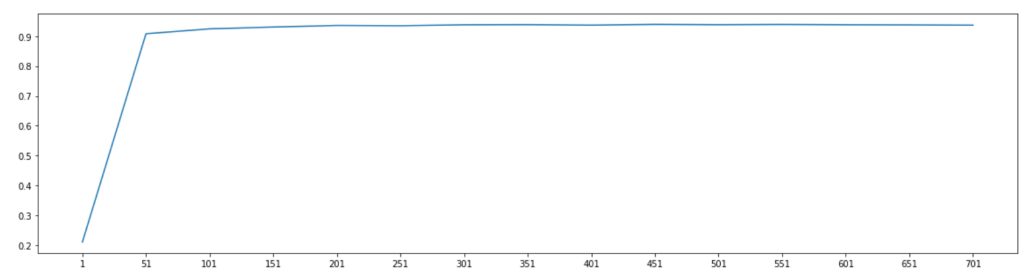
score = []
for i in range(1,751,50):
X_wrapper = RFE(RFC_,n_features_to_select=i, step=50).fit_transform(x,y)
once = cross_val_score(RFC_,X_wrapper,y,cv=5).mean()
score.append(once)
plt.figure(figsize=[20,5])
plt.plot(range(1,751,50),score)
plt.xticks(range(1,751,50))
plt.show()

最后
以上就是高兴煎蛋最近收集整理的关于使用Sklearn进行特征工程的全部内容,更多相关使用Sklearn进行特征工程内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。

![VUE 错误 [vuex] unknown action type: user/userLogin](https://www.shuijiaxian.com/files_image/reation/bcimg14.png)






发表评论 取消回复