背景
使用wrk模拟http压力打nginx时,发现压测过程中持续出现重传现象,而且在高压下和低压下都会出现不同程度的重传。
下面按照不同的客户端压力分析三种重传现象的根因,并给出解决方法。
场景一:压测并发1会话1——TimeWait满导致FIN包乱序重传
优化效果:重传0.3 --> 0
复现
wrk http://xxx/ -t1 -c1 -d 1 -H “Connection: Close” --latency
低压压测,运行时会产生3000个短连接GET。
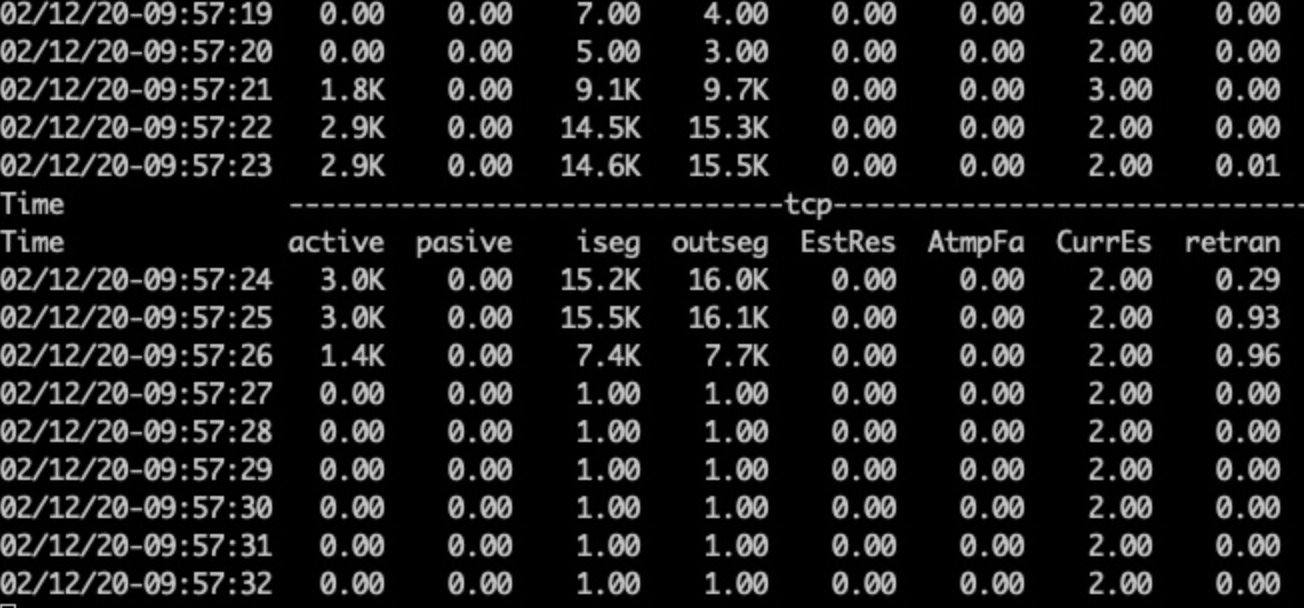
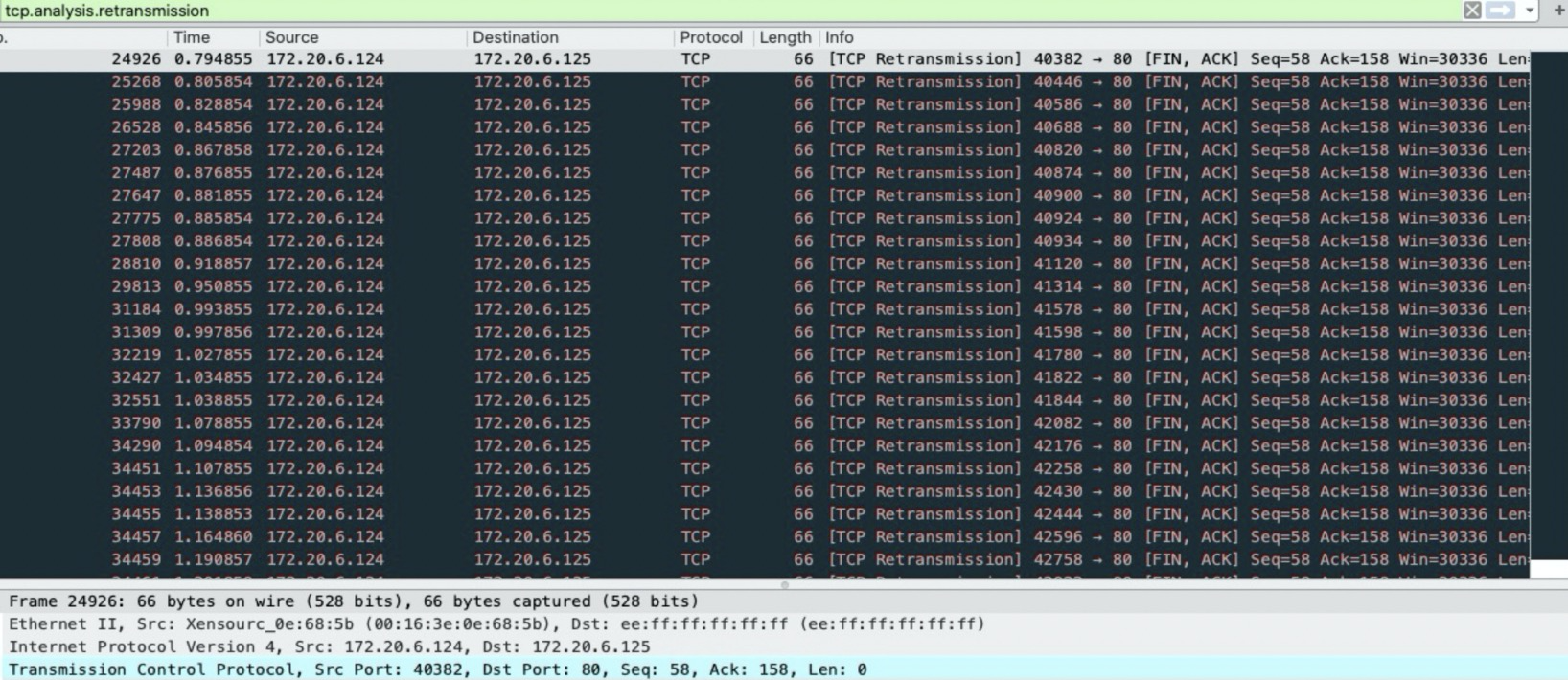
压测重传到0.2左右,wireshark发现大量重传FIN包。
分析
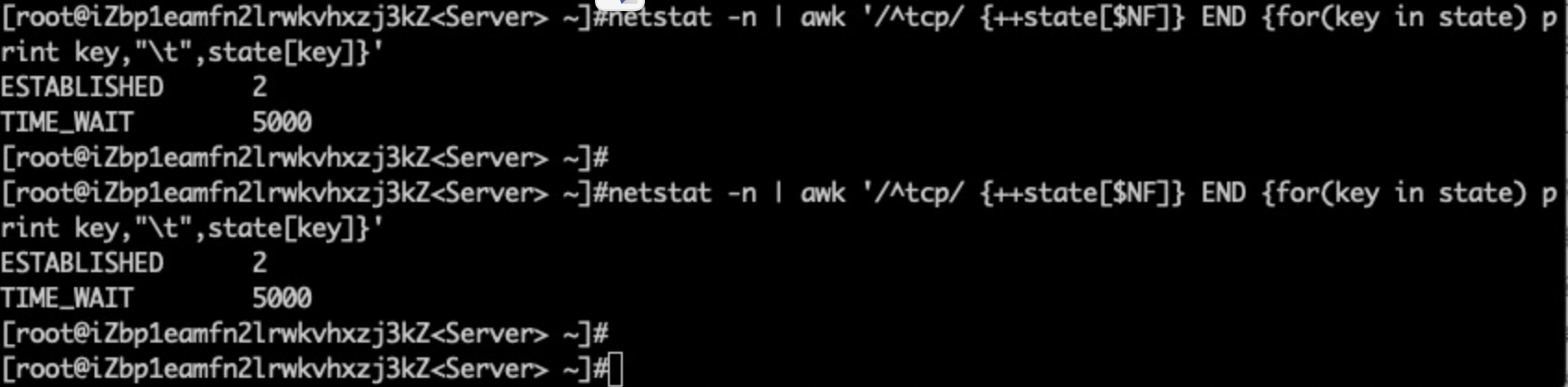
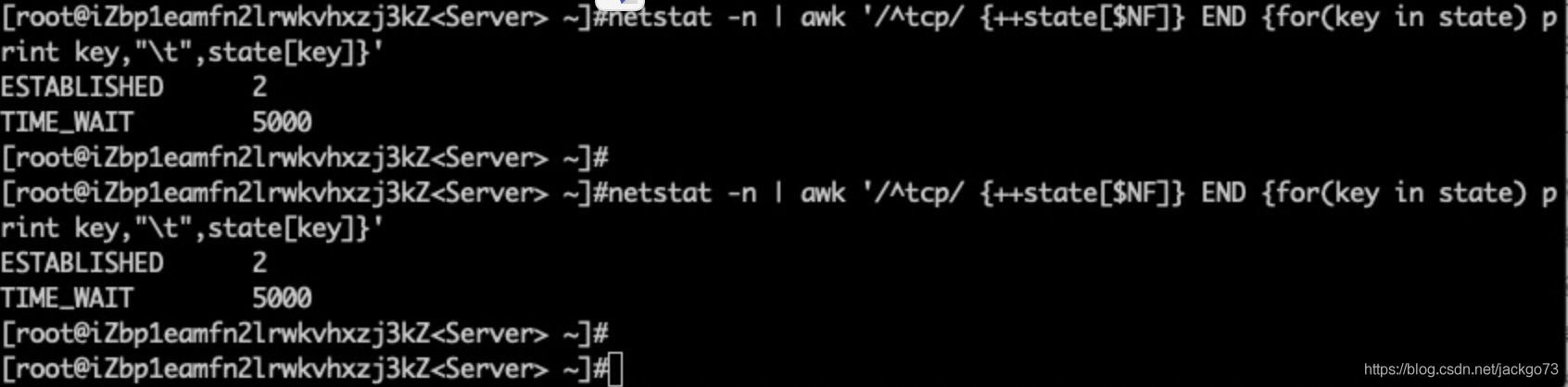
netstat连接状态
sysctl -a | grep -E "somaxconn|tcp_tw_reuse|tcp_tw_recycle|tcp_timestamps|tcp_max_tw_buckets|ip_local_port_range"
server异常分析
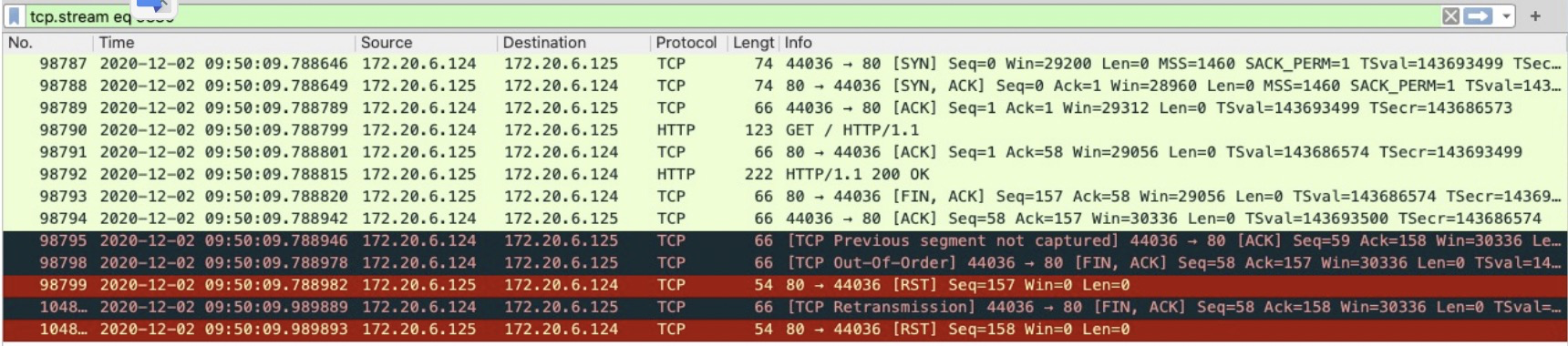
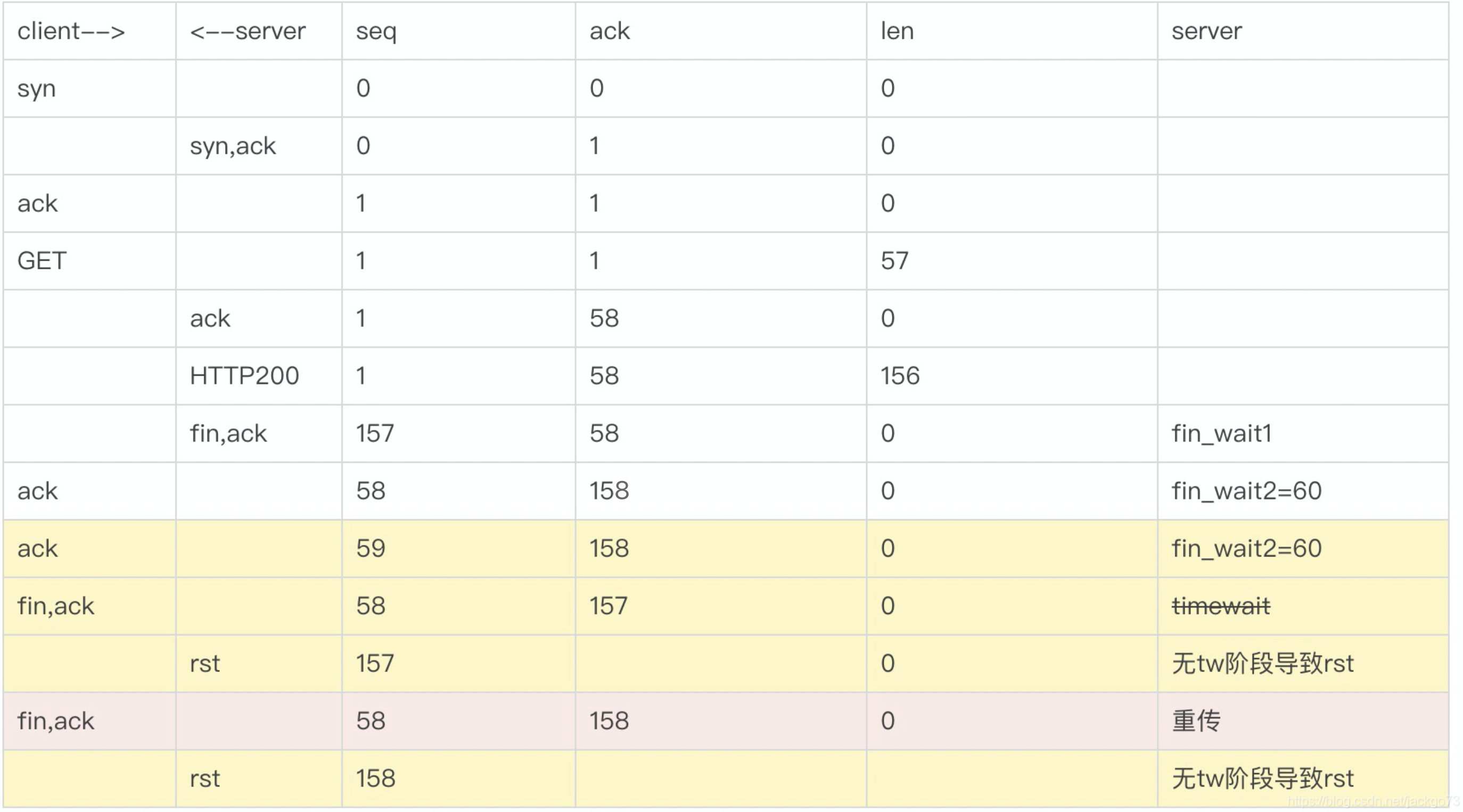
- 正常来说,第二组fin/ack的ack都要加一响应才是正常的。所以两边都认为自己先发的fin导致包序错乱。
- 包序错乱后,timewait等2MSL(最大包生命周期),保证所有包都进来避免下次连接时收到上一次的包。但是由于timewait队列满,这个阶段直接被砍掉。
- 服务端发出157,58;等待客户端成功ask;服务端等待58,158。
- 服务端没有等到58,158;反而收到58,157
- 服务端tw满,不在继续等待,直接返回rst重置
- 客户端重传发生,返回正确的fin包58,158
- 为什么客户端发了58,157?
- response to http200
ps. 正常流程
内核处理逻辑:队列满不进入timewait
/*
* Move a socket to time-wait or dead fin-wait-2 state.
*/
void tcp_time_wait(struct sock *sk, int state, int timeo)
{
struct inet_timewait_sock *tw = NULL;
const struct inet_connection_sock *icsk = inet_csk(sk);
const struct tcp_sock *tp = tcp_sk(sk);
bool recycle_ok = false;
if (tcp_death_row.sysctl_tw_recycle && tp->rx_opt.ts_recent_stamp)
recycle_ok = tcp_remember_stamp(sk);
if (tcp_death_row.tw_count < tcp_death_row.sysctl_max_tw_buckets)
tw = inet_twsk_alloc(sk, state);
// timewait如果已经满了,会返回null
if (tw != NULL) {
// ... 进行timewait流程
} else {
// ... 不进入timewait流程
/* Sorry, if we're out of memory, just CLOSE this
* socket up. We've got bigger problems than
* non-graceful socket closings.
*/
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_TCPTIMEWAITOVERFLOW);
}
tcp_update_metrics(sk);
tcp_done(sk);
}
accept与syn队列是否满了?
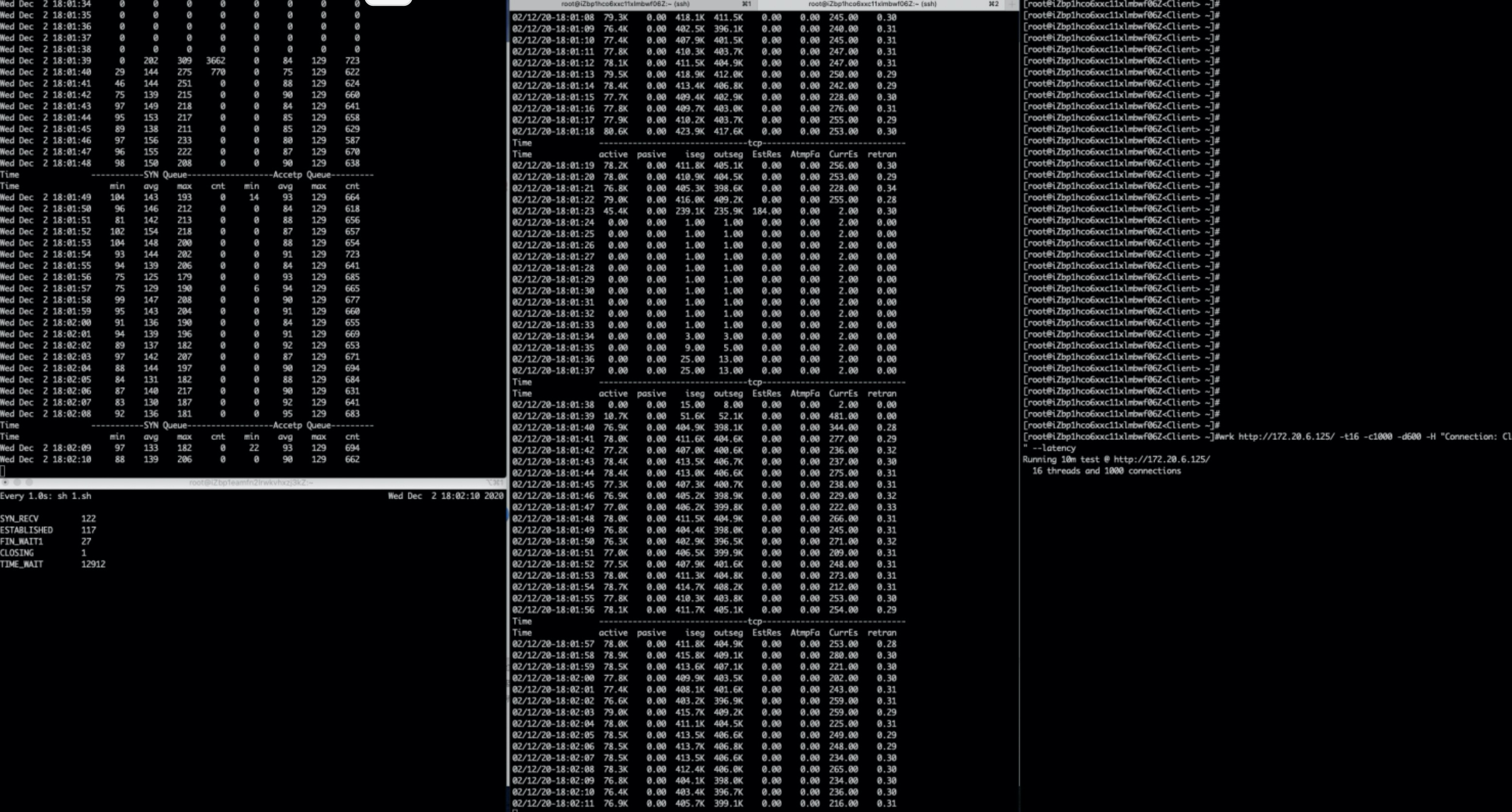
压测复现问题,stap双队列监控
(图中左侧工具stap,中间工具tsar,右侧压测工具)
双队列未满;
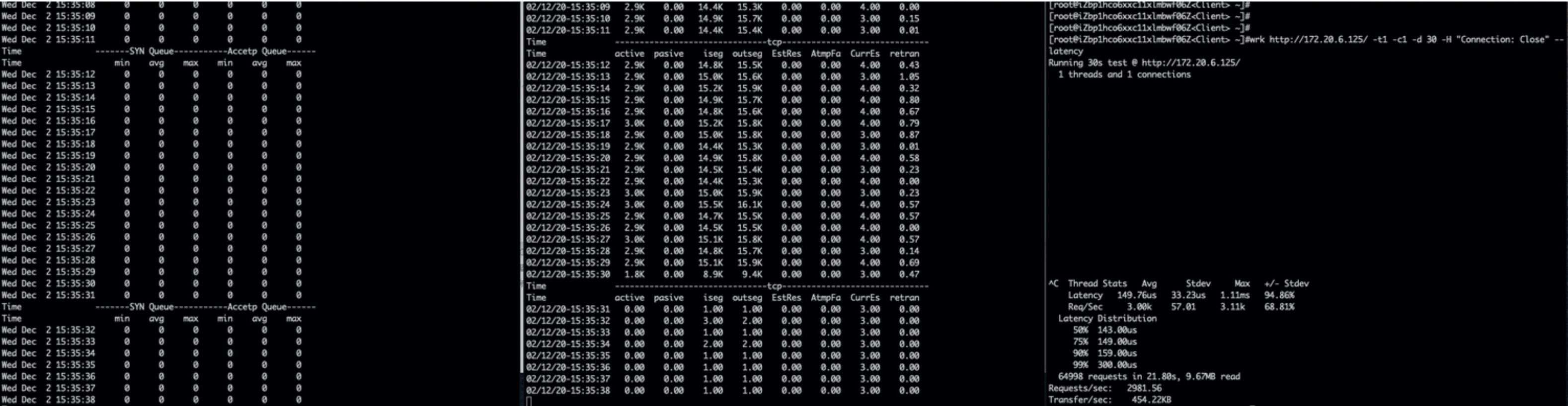
TW状态满了。
优化
server端开启快速tw回收
sysctl -w net.ipv4.tcp_timestamps=1
sysctl -w net.ipv4.tcp_tw_recycle=1
启用后tcp_tw_recycle快速回收timeout连接,保持timeout流程正常避免由于tcp_max_tw_buckets满导致立即关闭socket。
结果(重传0.3–>0)
修改前,重传0.29、0.93、0.96
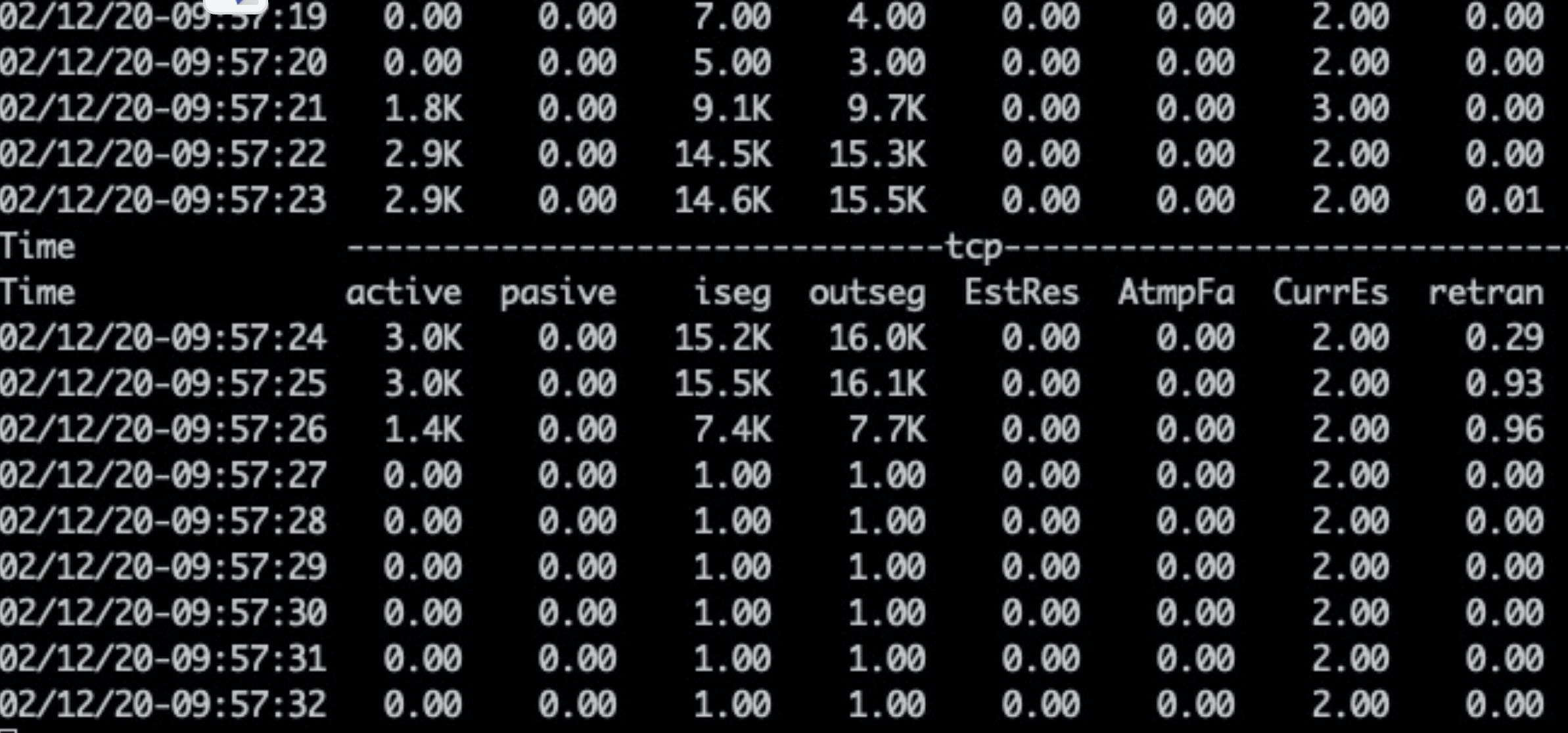
修改后,重传0
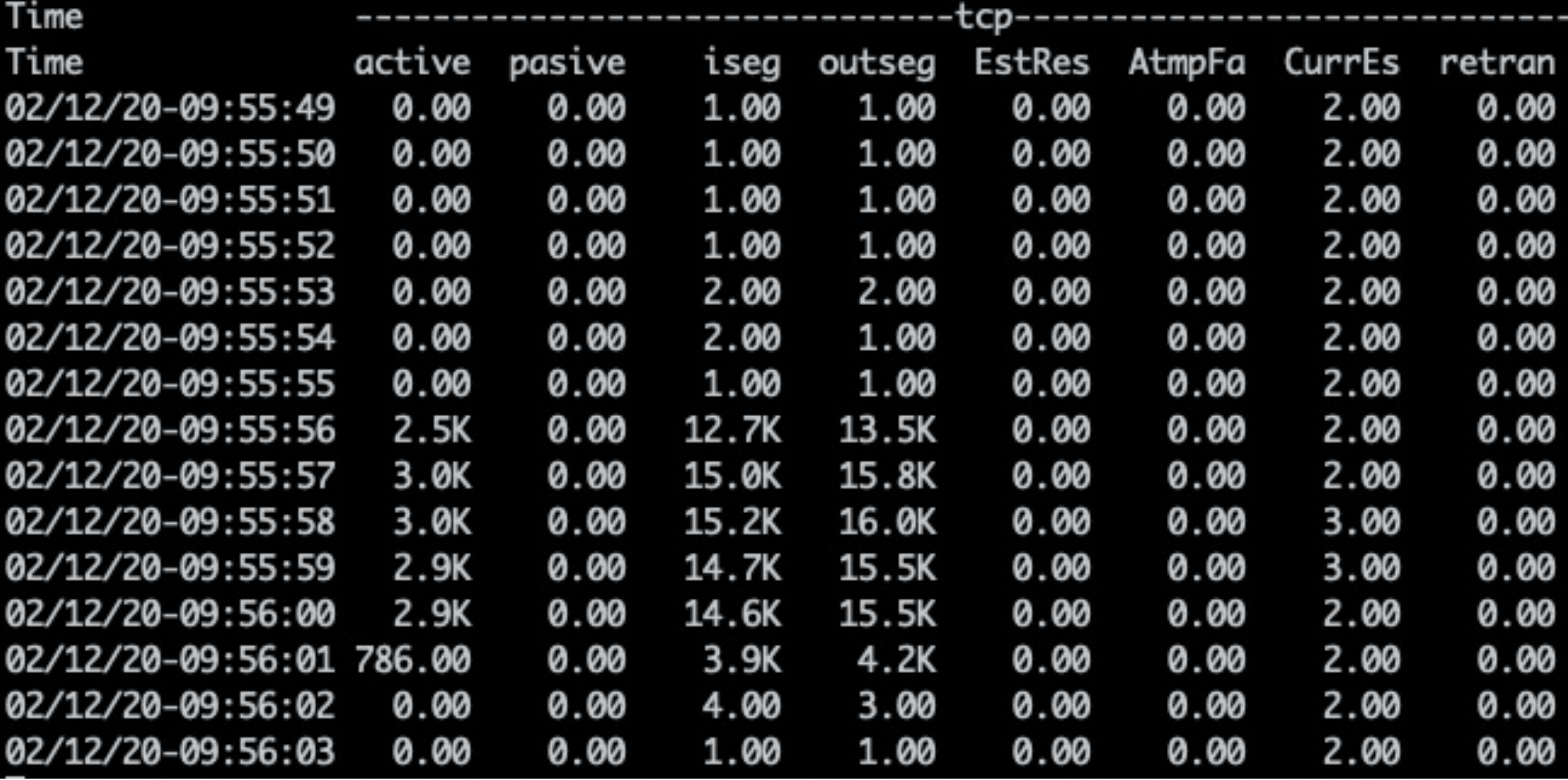
场景二:压测并发10会话1——TimeWait回收慢FIN乱序重传
优化效果:0.6 --> 0
复现
tsar看重传在0.4 - 0.7间
(图中左:netstat、中间tsar、右侧压测工具wrk)
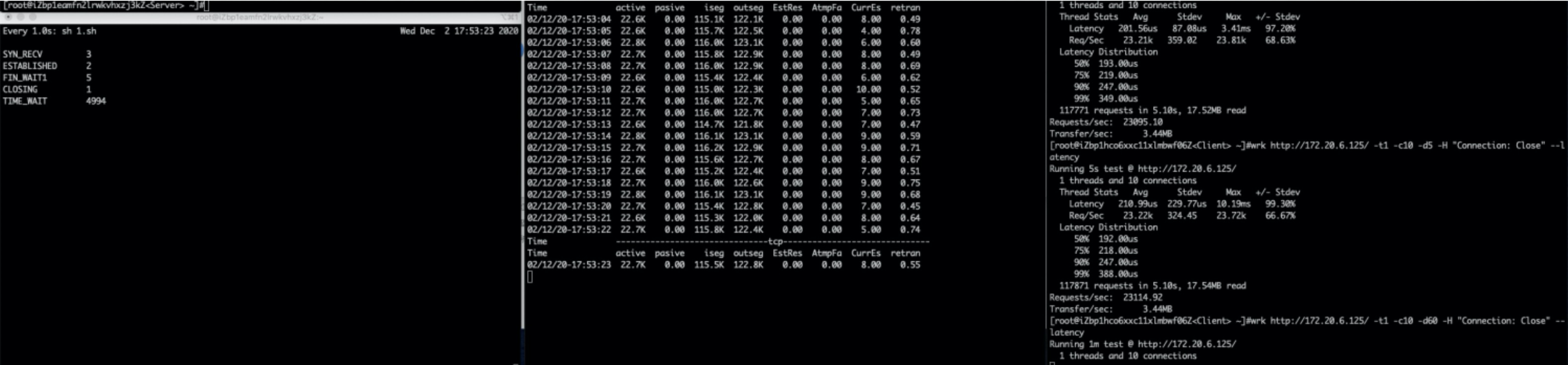
优化
上面启用了TW RECYCLE的功能,但是在压力稍微上来的情况下,TW队列又满了。
这次的优化是增加TW大小(TW占系统内存很低,可以多保留一些,但是不要超端口数)
sysctl -w net.ipv4.tcp_max_tw_buckets=20000
结果(重传0.6–>0)
不再出现重传,注意tw bucket不在打满。
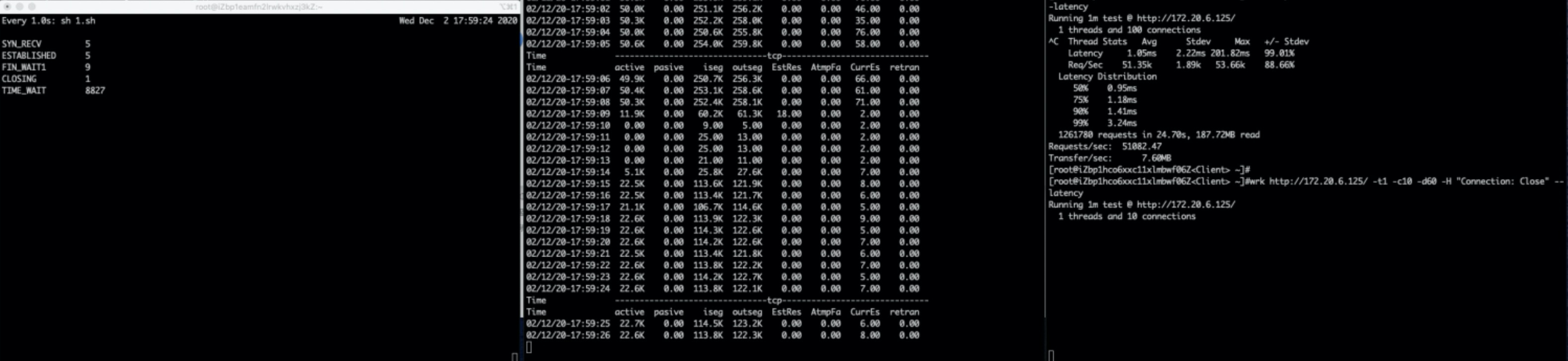
场景三:压测并发1000会话16——队列满重传
优化效果:0.3 --> 0.01
复现
wrk http://xxx/ -t16 -c 1000 -d 60 -H “Connection: Close” --latency
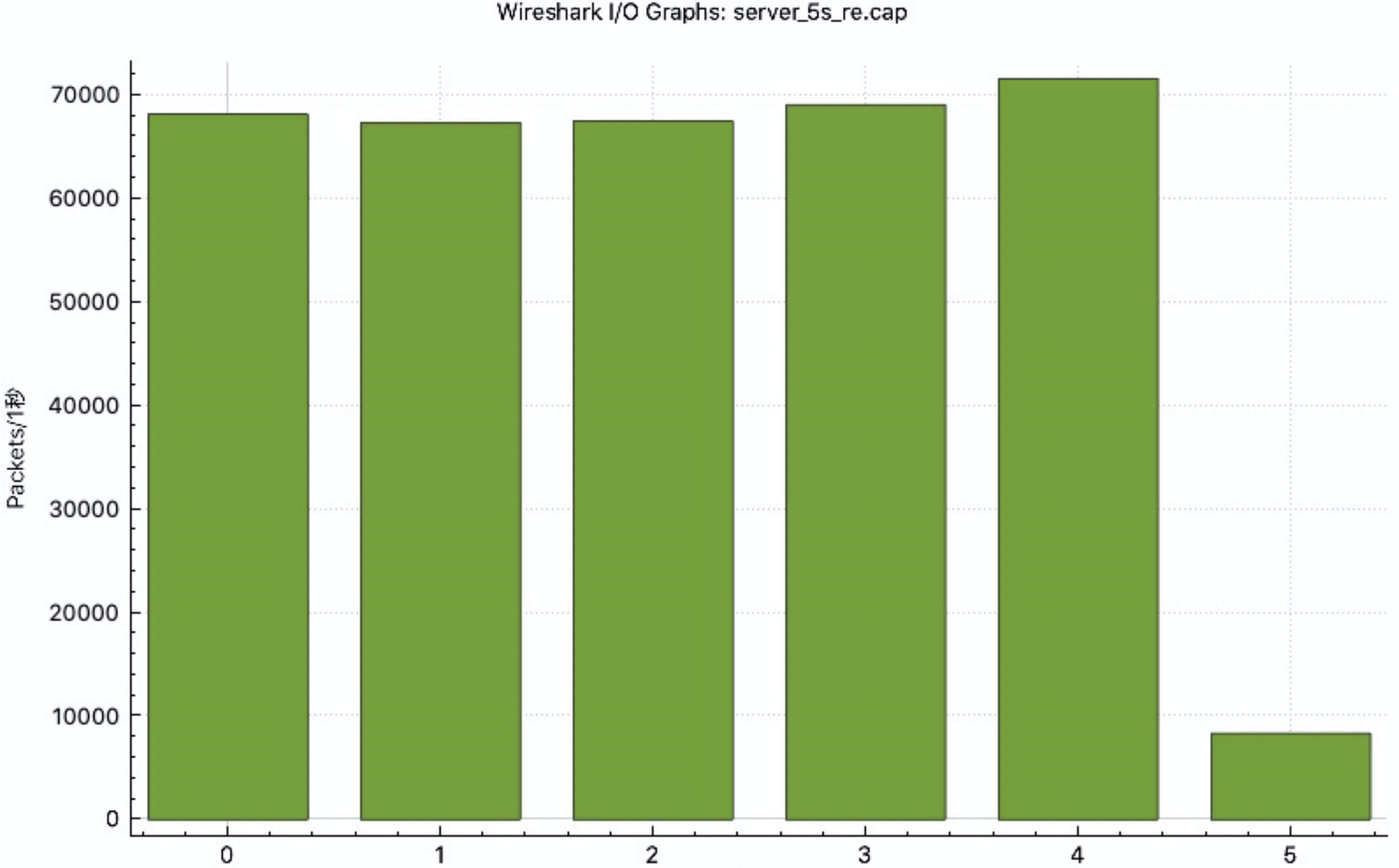
Timewait bucket未满、SYN队列未满,ACC队列每秒打满600次左右。重传0.3左右。
图中左侧stap监控说明:SYN QUEUE的avg表示一秒内平均队列长度,cnt表示一秒内队列打满次数(stap监控代码需要的话请联系我获取)
队列优化
1 系统参数优化
sysctl -w net.core.somaxconn=1024# ss -ltp | grep nginx
LISTEN 113128 *:http *:* users:(("nginx",pid=21965,fd=6),("nginx",pid=21964,fd=6),("nginx",pid=21963,fd=6),("nginx",pid=21962,fd=6),("nginx",pid=21961,fd=6))
2 nginx默认backlog=128,按1024启动。
nginx.conf
...
server {
listen 80 backlog=1024;
...
...
启动后acc队列1024
# ss -ltp|grep nginx
LISTEN 8921024 *:http *:* users:(("nginx",pid=11391,fd=6),("nginx",pid=11390,fd=6),("nginx",pid=11389,fd=6),("nginx",pid=11388,fd=6),("nginx",pid=11387,fd=6))
SYN queue length limit: 2048
Accept queue length limit: 1024
结果(重传0.3–>0.01)
TW、SYN未满,ACC未满。重传从0.3降低到0.01-0.02左右。

最后的0.01全部是syn重传,rto=1000ms,这是5秒内SYN发送情况。重传原因是大量集中短连接建立server处理不及时。
按syn过滤
背景知识
SYN队列
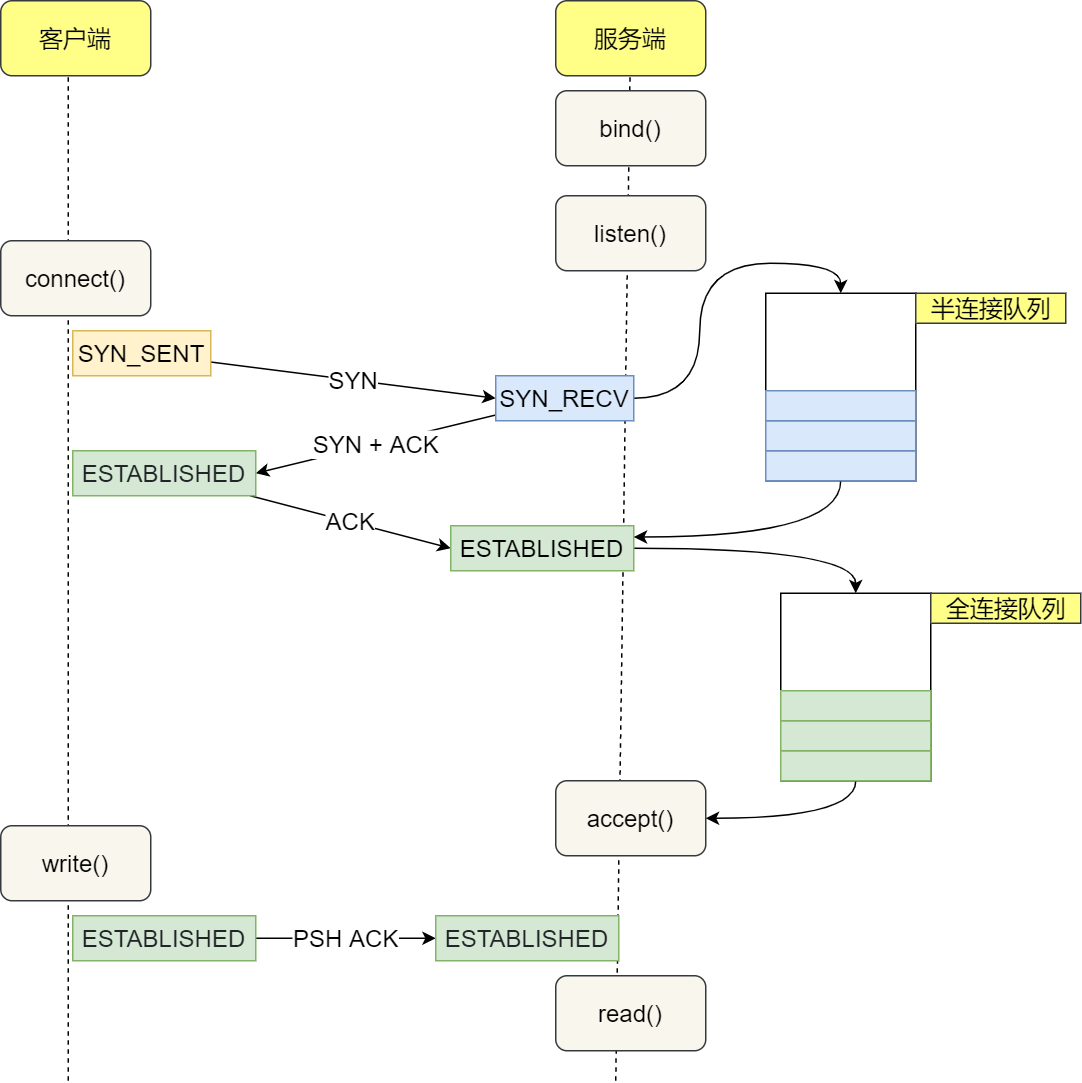
SYN队列存储了收到SYN包的连接(对应内核代码的结构体:struct inet_request_sock)。它的职责是回复SYN+ACK包,并且在没有收到ACK包时重传,直到超时。在Linux下,重传的次数为:
$ sysctl net.ipv4.tcp_synack_retries
net.ipv4.tcp_synack_retries = 5
文档中对tcp_synack_retries的描述如下:
tcp_synack_retries - int整型
对于一个被动TCP连接,重传SYNACKs的次数。该值不能超过255。
默认值为5,如果初始RTO是1秒,那么对应的最后一次重传是31秒。
对应的最后一次超时是63秒之后。
发送完SYN+ACK之后,SYN队列等待从客户端发出的ACK包(也即三次握手的最后一个包)。当收到ACK包时,首先找到对应的SYN队列,再在对应的SYN队列中检查相关的数据看是否匹配,如果匹配,内核将该连接相关的数据从SYN队列中移除,创建一个完整的连接(对应内核代码的结构体:struct inet_sock),并将这个连接加入Accept队列。
Accept队列
Accept队列中存放的是已建立好的连接,也即等待被上层应用程序取走的连接。当进程调用accept(),这个socket从队列中取出,传递给上层应用程序。
队列大小限制
应用程序通过调用系统调用listen(2),传入backlog参数,Accept队列的最大大小
listen(sfd, 1024)
SYN队列的最大大小用net.core.somaxconn来同时表示Accept队列的最大大小。在我们的服务器上,我们将它设置为16k:
$ sysctl net.core.somaxconn
net.core.somaxconn = 16384
TIME_WAIT 状态
一个常见的关闭连接过程如下1
- 当客户端没有待发送的数据时,它会向服务端发送 FIN 消息,发送消息后会进入 FIN_WAIT_1 状态;
- 服务端接收到客户端的 FIN 消息后,会进入 CLOSE_WAIT 状态并向客户端发送 ACK 消息,客户端接收到 ACK 消息时会进入 FIN_WAIT_2 状态;
- 当服务端没有待发送的数据时,服务端会向客户端发送 FIN 消息;
- 客户端接收到 FIN 消息后,会进入 TIME_WAIT 状态并向服务端发送 ACK 消息,服务端收到后会进入 CLOSED 状态;
- 客户端等待两个最大数据段生命周期(Maximum segment lifetime,MSL)2的时间后也会进入 CLOSED 状态;
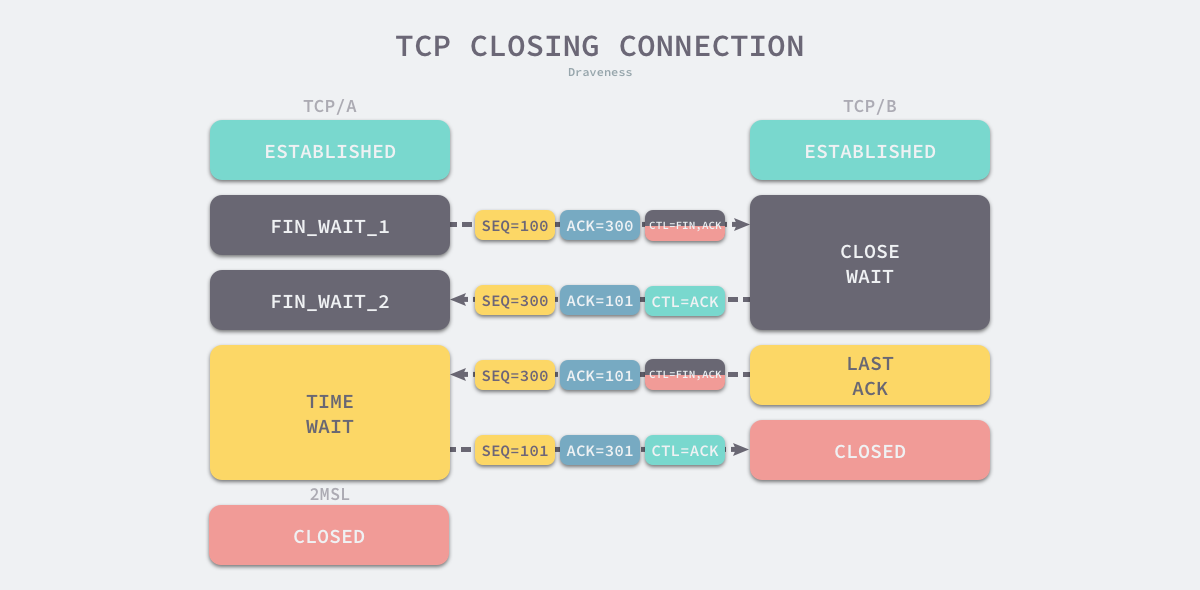
从上述过程中,我们会发现 TIME_WAIT 仅在主动断开连接的一方出现,被动断开连接的一方会直接进入 CLOSED 状态,进入 TIME_WAIT 的客户端需要等待 2 MSL 才可以真正关闭连接。TCP 协议需要 TIME_WAIT 状态的原因和客户端需要等待两个 MSL 不能直接进入 CLOSED 状态的原因是一样的3:
- 防止延迟的数据段被其他使用相同源地址、源端口、目的地址以及目的端口的 TCP 连接收到;
保证 TCP 连接的远程被正确关闭,即等待被动关闭连接的一方收到 FIN 对应的 ACK 消息;
最后
以上就是飘逸水壶最近收集整理的关于重传问题四阶段优化分享背景知识的全部内容,更多相关重传问题四阶段优化分享背景知识内容请搜索靠谱客的其他文章。





![Yocto系列讲解[实战篇] 10 - 在qemux86机器运行时安装程序](https://www.shuijiaxian.com/files_image/reation/bcimg16.png)


发表评论 取消回复