原文地址:https://segmentfault.com/a/1190000041823850?sort=newest
众所周知,cephfs的数据和元数据是分离的,处于不同的pool池里头,而无论是rgw、cephfs、rbd底层的数据池的存储都是基于RADOS(Reliable Autonomic Distributed Object Store),Ceph存储集群的基础,RADOS层的一切都是以对象的形式存储着的,无论上层是文件、对象还是块。
主要说说cephfs的文件在数据池中是如何分布的,下面以cephfs的内核客户端为例进行分析。
以下图文件为例,先找到这个文件的inode号1099511627776,转换为16进制为10000000000,从数据池中找到这个对象,对象的名称为文件的inode号.编号(数据位置/对象大小object_size(默认4M),从0开始编号)
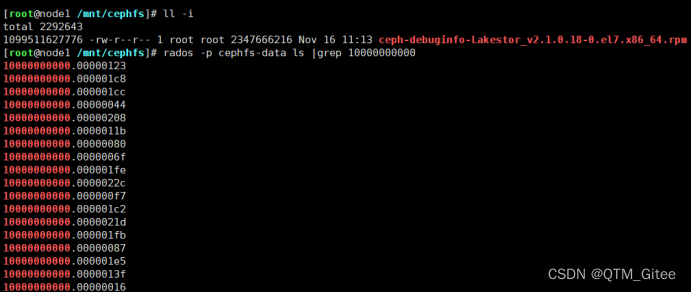
Cephfs读数据转换osd请求
struct ceph_file_layout {
/* file -> object mapping */
u32 stripe_unit; /* stripe unit, in bytes */
u32 stripe_count; /* over this many objects */
u32 object_size; /* until objects are this big */
s64 pool_id; /* rados pool id */
struct ceph_string __rcu *pool_ns; /* rados pool namespace */
};
文件的layout的属性,位于每个文件的inode属性中,是用来计算文件实际对象分布的条件。
客户端(linux内核客户端)位于文件的扩展属性xattr当中,通过set_xattr流程(客户端入口函数__ceph_setxattr和服务端mds入口函数为Server::handle_client_setxattr)进行修改。
可以使用getxattr命令查看默认值,命令和回显如下:
getfattr -n ceph.file.layout ceph-debuginfo-Lakestor_v2.1.0.18-0.el7.x86_64.rpm
ceph.file.layout="stripe_unit=4194304 stripe_count=1 object_size=4194304 pool=cephfs-data”
读流程从linux内核客户端向osd服务端发起请求:
入口函数为
|__ceph_read_iter
|____ceph_get_caps(获取文件的cap,如果cap不满足条件就发送getattr的req向mds服务端去获取最新的inode元数据,服务端处理完成回请求时客户端使用handle_reply最终fill_inode,将最新的元数据信息填写到客户端inode缓存里)
|______ceph_direct_read_write(如果客户端dcache没有对应位置缓存,就向osd发请求获取)
|__ceph_direct_read_write:
|____ceph_osdc_new_request(calc_layout-|______ceph_calc_file_object_mapping[ceph_oid_printf(&req->r_base_oid, “%llx.%08llx”, vino.ino, objnum);])
|________ceph_osdc_start_request
…
|__ceph_osdc_new_request:
|____calc_layout(layout, off, plen, &objnum, &objoff, &objlen):
|______ceph_calc_file_object_mapping
重要入参:1,inode中的layout结构,2,要写的偏移位置 off和3,要写的长度plen。
出参:1,要写的对象编号objnum,2,对象内的偏移objoff,。
|________ceph_oid_printf(&req->r_base_oid, “%llx.%08llx”, vino.ino, objnum);(将inode号.对象编号拼接起来形成要写的对象名)
最后
以上就是灵巧砖头最近收集整理的关于Cephfs数据池数据对象命名规则解析的全部内容,更多相关Cephfs数据池数据对象命名规则解析内容请搜索靠谱客的其他文章。








发表评论 取消回复