阿里云的MaxCompute是大数据存储和分析平台。使用DataHub、SLS可以将海量数据轻松同步到MaxCompute,然后使用SQL查询、UDF和Map Reduce进行数据处理、分析和挖掘。这里我从一个初识平台的用户角度,讲解一下如何快速上手该平台以及如果使用最新的Java9可能遇到的问题。
1、开通MaxCompute服务
前两步(“实名认证“和”创建AccessKey“)搞定以后,接下来是MaxCompute相关配置。
1)选择region及服务
开始使用该服务时,建议选择“按量付费”,随着数据量增大,再将套餐换为包年包月。
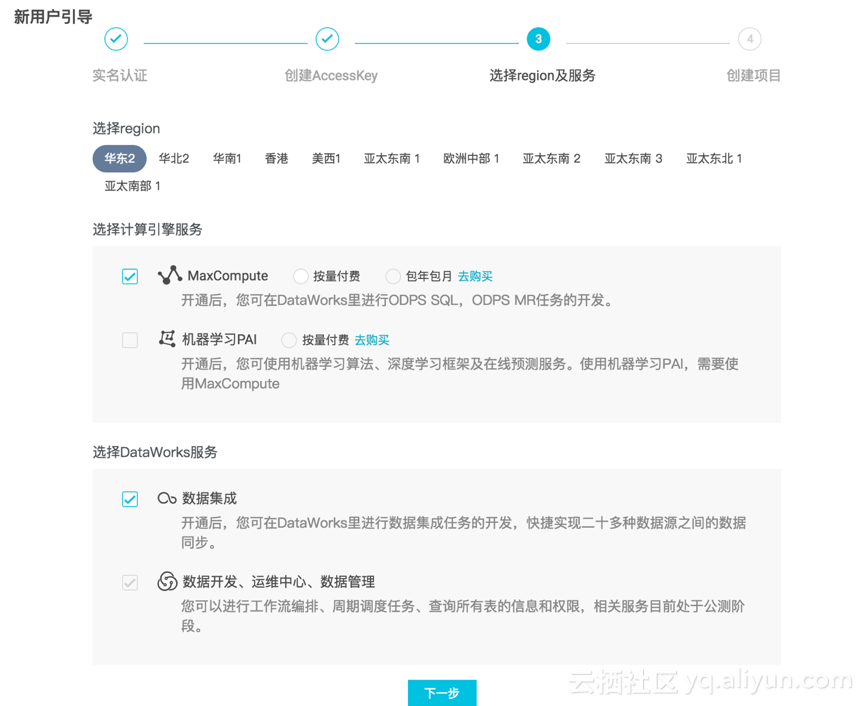
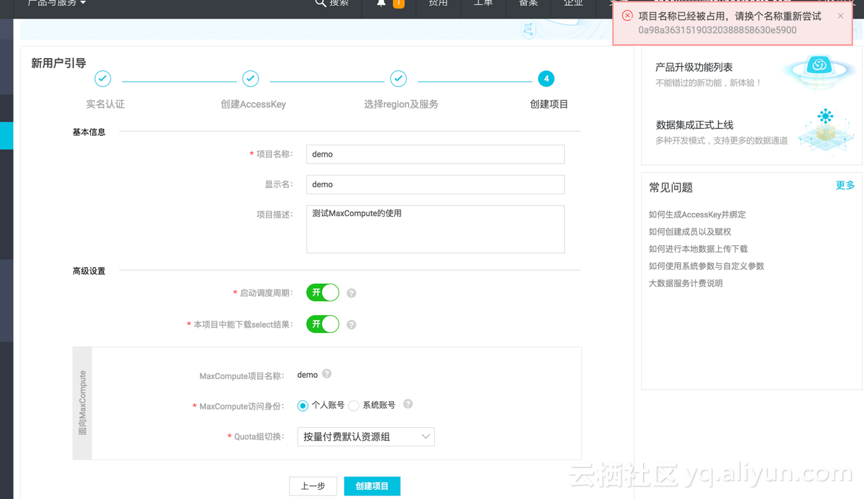
2)创建项目
注意“项目名称”在阿里云里面是全局唯一的,所以项目名称不能跟其他人的项目重复。
2、使用表查询功能
项目创建好了以后,我们首先试用一下SQL查询功能。
1)创建数据表
SQL查询是基于table的,首先创建一个company表。在“数据开发”->“表查询”面板中,点击“+”按钮即可打开一个SQL编辑页面。输入下面的语句创建一个空的ODPS表。
create table if not exists company (name string, industry string);2)插入数据
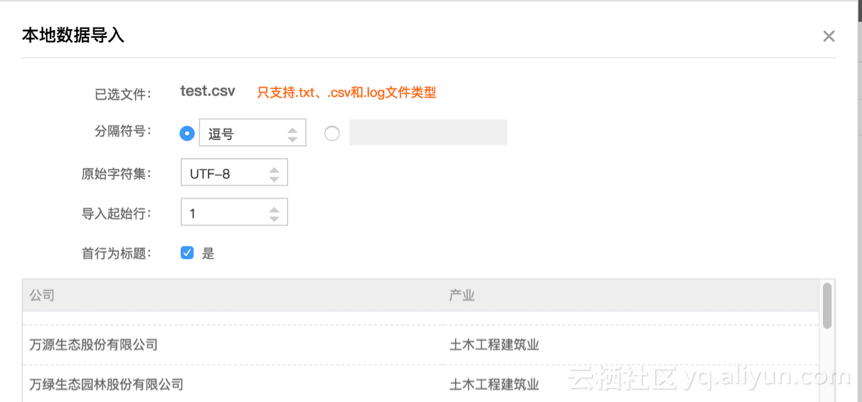
可以选择使用insert插入数据,这里我们选择更简洁的方法,即将本地的数据导入ODPS表中。点击“导入”按钮,选择“导入本地数据“。选择正确的“分隔符号”和“原始字符集”,就可以看到正确的数据预览结果(本文中使用的数据从互联网收集,仅作参考)。
几千条数据的导入速度很快,导入结束以后即可在company表的“数据预览”查看到相关记录了。
3)Dataworks中进行数据查询
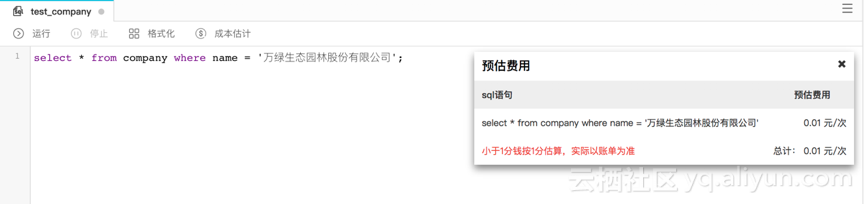
在SQL编辑面板中输入下面SQL语句,
SELECT * FROM company WHERE name = '万绿生态园林股份有限公司';
点击“成本预估”可以看到详细的成本预估结果。直接点击“运行”,弹出框中也可以看到预估的费用。
因为MaxCompute运行数据查询需要Job排队运行,所以数据量很小的查询仍然需要几秒钟才能看到结果。
在Job执行过程中,可以看到日志。点击下图中的“Log view”可以看到更详细的Job执行情况。
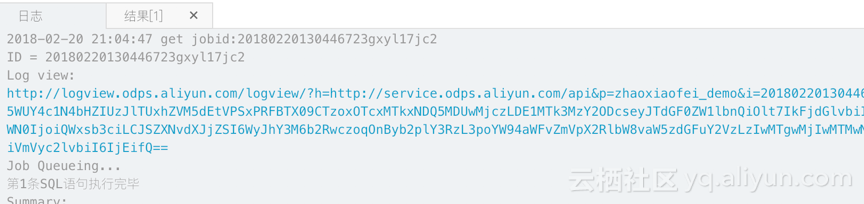
4)Studio中进行数据查询
Studio的配置详见官方介绍。
数据查询的执行结果如下图所示,点击“日志”中的“Click Here To See Detail”,即可看到详细的Job执行情况。由于在Studio中查看Job运行情况更为直观,而且Studio中的script文件还可以加入到git中进行版本管理,建议尽量使用Studio进行数据查询。
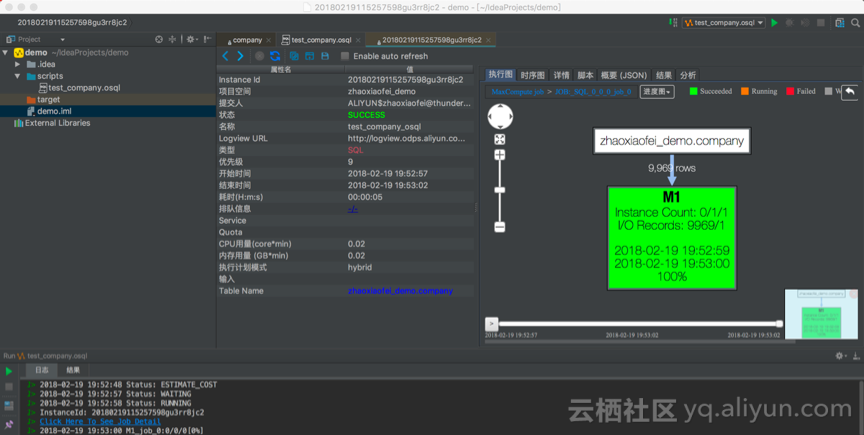
5)CLT中进行数据查询
CLT的配置请参照官方文档。在CLT中进行系统配置和基本的建表、赋权等操作非常方便。不过,如果使用Java9等更高的Java版本,在提交Job的时候经常会收到ODPSConsoleException的错误信息,不过此时Job已经提交成功,可以通过Job view来查看Job运行情况和运算结果。
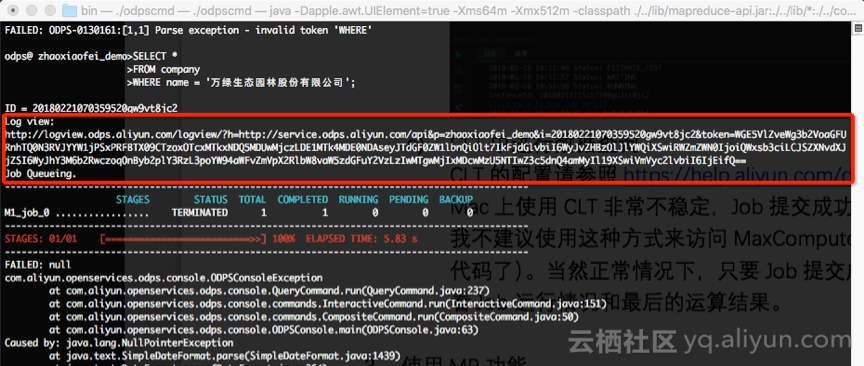
3、使用UDF功能
1)配置
在Studio中开发UDF是十分方便的。使用UDF开发请参照阿里云官方文档。如果使用Java9,那么除了官方文档中对于Maven的修改以外,还需要加入以下Maven依赖,整个工程才能运行:
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.5</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.5</version>
</dependency>
<dependency>
<groupId>javax.xml.bind</groupId>
<artifactId>jaxb-api</artifactId>
<version>2.2.11</version>
</dependency>
<dependency>
<groupId>com.sun.xml.bind</groupId>
<artifactId>jaxb-core</artifactId>
<version>2.2.11</version>
</dependency>
<dependency>
<groupId>com.sun.xml.bind</groupId>
<artifactId>jaxb-impl</artifactId>
<version>2.2.11</version>
</dependency>配置好了以后,就可以写一个简单的UDF函数了,demo是取公司名称的前两个中文字符粗略作为这个公司的归属地。程序写好以后,可以先在本地运行一下,测试通过后再部署到MaxCompute服务器。
2)本地运行
1、按照warehouse中的样本数据,创建company样本数据作为函数的输入。注意样本数据中,schema和data中的列和列之间的分隔符都必须是逗号“,”。
2、右键点击类文件,选择 run “CityExtractUDF.main()”,在弹出框中选择刚刚创建的MaxCompute table和Table columns,点击“OK”。运行结果如下图所示,
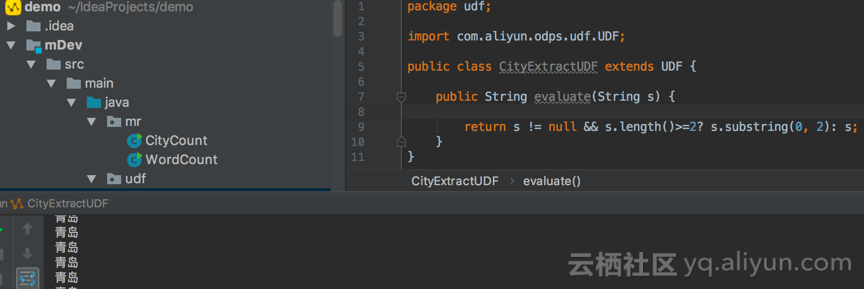
3)MaxCompute服务器运行
本地运行成功以后,就可以把UDF提交到maxCompute server在线运行了。提交方法非常简单,右键点击该class文件,选择“Deploy to server…”,然后给UDF起一个响当当的名字就可以了。顺利的话很快就可以上传成功,在Studio中刷新meta data可以看到该function。接下来提交一个简单的job试运行一下,
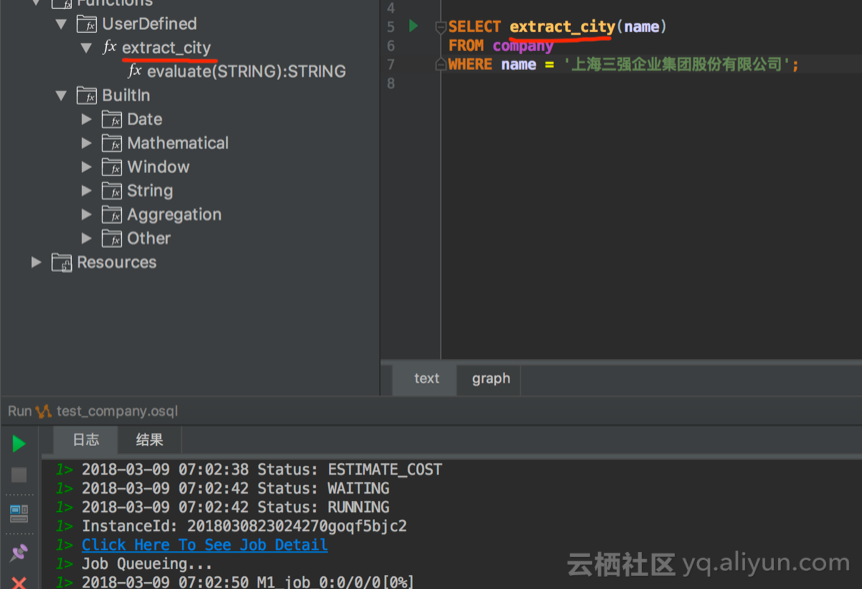
由于UDF函数已经在Server端,我们也可以在DataWorks和CLT中直接调用该函数。在CLT中使用list functions命令可以看到刚刚定义的函数,但是在DataWorks中的“函数管理”无法看见。
4、使用Map Reduce功能
使用MaxCompute的MR功能是非常容易的,首先可以参照examples中的word count例子,写一个自己的MR程序,我的MR程序要完成的任务是计算每个省企业的个数。
1)本地运行
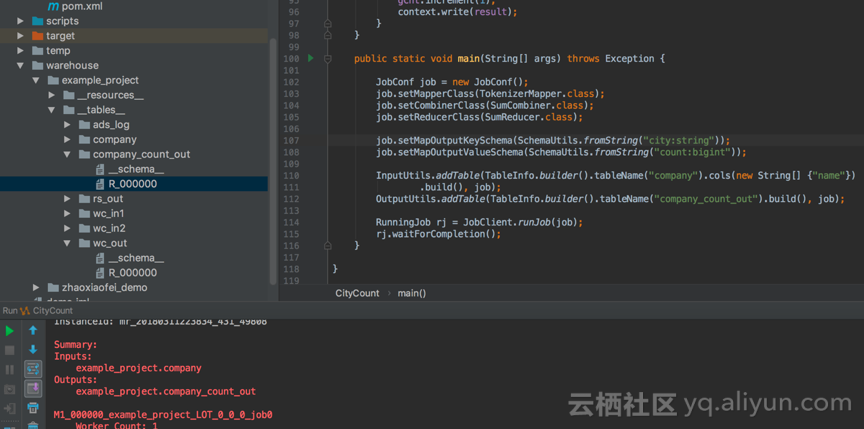
要本地执行该程序,同样需要在warehouse中创建MR程序的输入输出,比如下图中的company和company_count_out。程序执行结果如下:
2)MaxCompute服务器运行
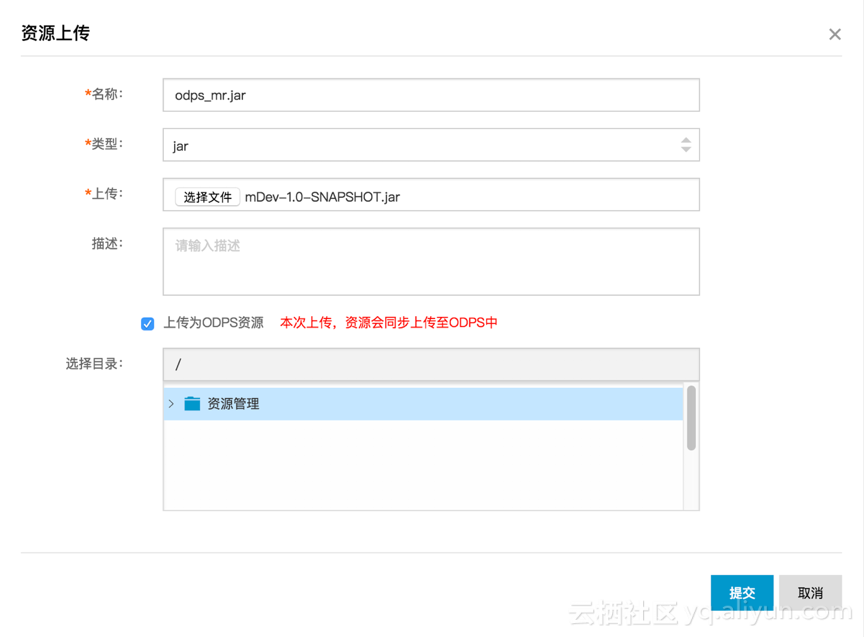
1、 部署Jar包到MaxCompute服务端。在DataWorks选择“资源管理”,点击“资源上传”,选择Jar包完成上传。
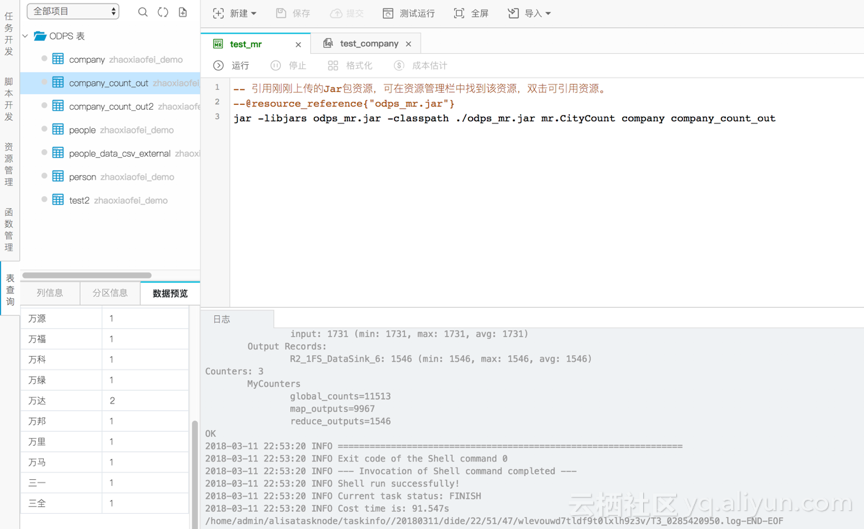
2、执行ODPS_MR任务。在DataWorks上面点击“新建任务”,在弹出框中选择任务类型为“ODPS_MR”。填写相关信息后提交并运行刚刚写的MR Job,等Job执行结束,通过“数据预览”功能,可以在company_count_out表看到输出。
最后
以上就是无限心情最近收集整理的关于MaxCompute 数据计算入门1、开通MaxCompute服务2、使用表查询功能3、使用UDF功能4、使用Map Reduce功能的全部内容,更多相关MaxCompute内容请搜索靠谱客的其他文章。








发表评论 取消回复