使用tensorflow框架进行物体识别训练,为了使其更快的达到训练目的,采用分布式训练。
PS-worker架构
将模型维护和训练计算解耦合,将模型训练分为两个作业(job):
- 模型相关作业,模型参数存储、分发、汇总、更新,有由PS执行
- 训练相关作业,包含推理计算、梯度计算(正向/反向传播),由worker执行
该架构下,所有的woker共享PS上的参数,并按照相同的数据流图传播不同batch的数据,计算出不同的梯度,交由PS汇总、更新新的模型参数,大体逻辑如下:
- pull:各个woker根据数据流图拓扑结构从PS获取最新的模型参数
- feed:各个worker根据定义的规则填充各自batch的数据
- compute:各个worker使用第一步的模型参数计算各自的batch数据,求出各自batch的梯度
- push:各个worker将各自的梯度推送到PS
- update:PS汇总来自n个worker的n份梯度,求出平均值后更新模型参数
分布式经典架构PS-worker会重复上面步骤,直到损失到达阈值或者轮数到达阈值。
根据参数更新分类
1、所谓的同步更新指的是:各个用于并行计算的电脑,计算完各自的batch 后,求取梯度值,把梯度值统一送到ps服务机器中,由ps服务机器求取梯度平均值,更新ps服务器上的参数。可以看成有三台电脑,第一台电脑用于存储参数、共享参数、共享计算,可以简单的理解成内存、计算共享专用的区域,也就是ps job;另外两台电脑用于并行计算的,也就是worker task。
这种计算方法存在的缺陷是:每一轮的梯度更新,都要等到A、B、C三台电脑都计算完毕后,才能更新参数,也就是迭代更新速度取决与A、B、C三台中,最慢的那一台电脑,所以采用同步更新的方法,建议A、B、C三台的计算能力都不想。
2、所谓的异步更新指的是:ps服务器收到只要收到一台机器的梯度值,就直接进行参数更新,无需等待其它机器。这种迭代方法比较不稳定,收敛曲线震动比较厉害,因为当A机器计算完更新了ps中的参数,可能B机器还是在用上一次迭代的旧版参数值。
分布式训练实践
首先,我们要准备三台电脑:一台为ps(参数提供)、一台master(主服务器处理参数)、一台worker(处理参数)。配置为8G内存 100M带宽 2vcpu。
代码改写
接下来进行代码train.py的改写
模型等一切前置条件准备好:
在train.py中添加如下内容:(ps机代码)
import functools
import json
import os
import tensorflow as tf
from object_detection.builders import dataset_builder
from object_detection.builders import graph_rewriter_builder
from object_detection.builders import model_builder
from object_detection.legacy import trainer
from object_detection.utils import config_util
tf.logging.set_verbosity(tf.logging.INFO)
flags = tf.app.flags
flags.DEFINE_string('master', '', 'Name of the TensorFlow master to use.')
flags.DEFINE_integer('task', 0, 'task id')
flags.DEFINE_integer('num_clones', 1, 'Number of clones to deploy per worker.')
flags.DEFINE_boolean('clone_on_cpu', False,
'Force clones to be deployed on CPU. Note that even if '
'set to False (allowing ops to run on gpu), some ops may '
'still be run on the CPU if they have no GPU kernel.')
flags.DEFINE_integer('worker_replicas', 1, 'Number of worker+trainer '
'replicas.')
flags.DEFINE_integer('ps_tasks', 0,
'Number of parameter server tasks. If None, does not use '
'a parameter server.')
flags.DEFINE_string('train_dir', '',
'Directory to save the checkpoints and training summaries.')
flags.DEFINE_string('type', '',
'Directory to save the checkpoints and training summaries.') //增加内容
flags.DEFINE_integer('index', 0,
'Number of parameter server tasks. If None, does not use '
'a parameter server.') //增加内容
flags.DEFINE_string('pipeline_config_path', '',
'Path to a pipeline_pb2.TrainEvalPipelineConfig config '
'file. If provided, other configs are ignored')
flags.DEFINE_string('train_config_path', '',
'Path to a train_pb2.TrainConfig config file.')
flags.DEFINE_string('input_config_path', '',
'Path to an input_reader_pb2.InputReader config file.')
flags.DEFINE_string('model_config_path', '',
'Path to a model_pb2.DetectionModel config file.')
flags.DEFINE_string('cluster_data', '',
'Path to a model_pb2.DetectionModel config file.')
FLAGS = flags.FLAGS
@tf.contrib.framework.deprecated(None, 'Use object_detection/model_main.py.')
def main(_):
assert FLAGS.train_dir, '`train_dir` is missing.'
if FLAGS.task == 0: tf.gfile.MakeDirs(FLAGS.train_dir)
if FLAGS.pipeline_config_path:
configs = config_util.get_configs_from_pipeline_file(
FLAGS.pipeline_config_path)
if FLAGS.task == 0:
tf.gfile.Copy(FLAGS.pipeline_config_path,
os.path.join(FLAGS.train_dir, 'pipeline.config'),
overwrite=True)
else:
configs = config_util.get_configs_from_multiple_files(
model_config_path=FLAGS.model_config_path,
train_config_path=FLAGS.train_config_path,
train_input_config_path=FLAGS.input_config_path)
if FLAGS.task == 0:
for name, config in [('model.config', FLAGS.model_config_path),
('train.config', FLAGS.train_config_path),
('input.config', FLAGS.input_config_path)]:
tf.gfile.Copy(config, os.path.join(FLAGS.train_dir, name),
overwrite=True)
model_config = configs['model']
train_config = configs['train_config']
input_config = configs['train_input_config']
model_fn = functools.partial(
model_builder.build,
model_config=model_config,
is_training=True)
def get_next(config):
return dataset_builder.make_initializable_iterator(
dataset_builder.build(config)).get_next()
create_input_dict_fn = functools.partial(get_next, input_config)
env = json.loads(os.environ.get('TF_CONFIG', '{}'))
cluster_data = { //改动内容
"worker":[
"192.168.1.109:2222"
],
"ps":[
"192.168.1.116:2224"
],
"master":[
"192.168.1.108:2223"
]
}
#cluster = tf.train.ClusterSpec(cluster_data) if cluster_data else None
cluster = tf.train.ClusterSpec(cluster_data) if cluster_data else None
task_data = env.get('task', None) or {'type': 'master', 'index': 0}
task_info = type('TaskSpec', (object,), task_data)
# Parameters for a single worker.
ps_tasks = 0
worker_replicas = 1
worker_job_name = 'lonely_worker'
task = 0
is_chief = True
master = ''
task_info.type=FLAGS.type //增加内容
task_info.index = FLAGS.index //增加内容
if cluster_data and 'worker' in cluster_data:
# Number of total worker replicas include "worker"s and the "master".
worker_replicas = len(cluster_data['worker']) + 1
if cluster_data and 'ps' in cluster_data:
ps_tasks = len(cluster_data['ps'])
print('ps_tasks%d',ps_tasks)
if worker_replicas > 1 and ps_tasks < 1:
raise ValueError('At least 1 ps task is needed for distributed training.')
if worker_replicas >= 1 and ps_tasks > 0:
# Set up distributed training. //注释掉
# server = tf.train.Server(tf.train.ClusterSpec(cluster), protocol='grpc',
# job_name=task_info.type,
# task_index=task_info.index)
#server = tf.train.Server(cluster, job_name="worker", task_index=0)
#print('进入worker%d',worker_replicas)
if task_info.type == 'ps' or True: //作为ps机
server = tf.train.Server(cluster, job_name=task_info.type, task_index=task_info.index)
print('进入ps')
server.join()
worker_job_name = '%s/task:%d' % (task_info.type, task_info.index)
task = task_info.index
is_chief = (task_info.type == 'master')
master = server.target
graph_rewriter_fn = None
if 'graph_rewriter_config' in configs:
graph_rewriter_fn = graph_rewriter_builder.build(
configs['graph_rewriter_config'], is_training=True)
trainer.train(
create_input_dict_fn,
model_fn,
train_config,
master,
task,
FLAGS.num_clones,
worker_replicas,
FLAGS.clone_on_cpu,
ps_tasks,
worker_job_name,
is_chief,
FLAGS.train_dir,
graph_hook_fn=graph_rewriter_fn)
if __name__ == '__main__':
tf.app.run()
worker机和master机代码
import functools
import json
import os
import tensorflow as tf
from object_detection.builders import dataset_builder
from object_detection.builders import graph_rewriter_builder
from object_detection.builders import model_builder
from object_detection.legacy import trainer
from object_detection.utils import config_util
tf.logging.set_verbosity(tf.logging.INFO)
flags = tf.app.flags
flags.DEFINE_string('master', '', 'Name of the TensorFlow master to use.')
flags.DEFINE_integer('task', 0, 'task id')
flags.DEFINE_integer('num_clones', 1, 'Number of clones to deploy per worker.')
flags.DEFINE_boolean('clone_on_cpu', False,
'Force clones to be deployed on CPU. Note that even if '
'set to False (allowing ops to run on gpu), some ops may '
'still be run on the CPU if they have no GPU kernel.')
flags.DEFINE_integer('worker_replicas', 1, 'Number of worker+trainer '
'replicas.')
flags.DEFINE_integer('ps_tasks', 0,
'Number of parameter server tasks. If None, does not use '
'a parameter server.')
flags.DEFINE_string('train_dir', '',
'Directory to save the checkpoints and training summaries.')
flags.DEFINE_string('type', '',
'Directory to save the checkpoints and training summaries.') //增加内容
flags.DEFINE_integer('index', 0,
'Number of parameter server tasks. If None, does not use '
'a parameter server.') //增加内容
flags.DEFINE_string('pipeline_config_path', '',
'Path to a pipeline_pb2.TrainEvalPipelineConfig config '
'file. If provided, other configs are ignored')
flags.DEFINE_string('train_config_path', '',
'Path to a train_pb2.TrainConfig config file.')
flags.DEFINE_string('input_config_path', '',
'Path to an input_reader_pb2.InputReader config file.')
flags.DEFINE_string('model_config_path', '',
'Path to a model_pb2.DetectionModel config file.')
flags.DEFINE_string('cluster_data', '',
'Path to a model_pb2.DetectionModel config file.')
FLAGS = flags.FLAGS
@tf.contrib.framework.deprecated(None, 'Use object_detection/model_main.py.')
def main(_):
assert FLAGS.train_dir, '`train_dir` is missing.'
if FLAGS.task == 0: tf.gfile.MakeDirs(FLAGS.train_dir)
if FLAGS.pipeline_config_path:
configs = config_util.get_configs_from_pipeline_file(
FLAGS.pipeline_config_path)
if FLAGS.task == 0:
tf.gfile.Copy(FLAGS.pipeline_config_path,
os.path.join(FLAGS.train_dir, 'pipeline.config'),
overwrite=True)
else:
configs = config_util.get_configs_from_multiple_files(
model_config_path=FLAGS.model_config_path,
train_config_path=FLAGS.train_config_path,
train_input_config_path=FLAGS.input_config_path)
if FLAGS.task == 0:
for name, config in [('model.config', FLAGS.model_config_path),
('train.config', FLAGS.train_config_path),
('input.config', FLAGS.input_config_path)]:
tf.gfile.Copy(config, os.path.join(FLAGS.train_dir, name),
overwrite=True)
model_config = configs['model']
train_config = configs['train_config']
input_config = configs['train_input_config']
model_fn = functools.partial(
model_builder.build,
model_config=model_config,
is_training=True)
def get_next(config):
return dataset_builder.make_initializable_iterator(
dataset_builder.build(config)).get_next()
create_input_dict_fn = functools.partial(get_next, input_config)
env = json.loads(os.environ.get('TF_CONFIG', '{}'))
cluster_data = { //改动内容
"worker":[
"192.168.1.109:2222"
],
"ps":[
"192.168.1.116:2224"
],
"master":[
"192.168.1.108:2223"
]
}
#cluster = tf.train.ClusterSpec(cluster_data) if cluster_data else None
cluster = tf.train.ClusterSpec(cluster_data) if cluster_data else None
task_data = env.get('task', None) or {'type': 'master', 'index': 0}
task_info = type('TaskSpec', (object,), task_data)
# Parameters for a single worker.
ps_tasks = 0
worker_replicas = 1
worker_job_name = 'lonely_worker'
task = 0
is_chief = True
master = ''
task_info.type=FLAGS.type //增加内容
task_info.index = FLAGS.index //增加内容
if cluster_data and 'worker' in cluster_data:
# Number of total worker replicas include "worker"s and the "master".
worker_replicas = len(cluster_data['worker']) + 1
if cluster_data and 'ps' in cluster_data:
ps_tasks = len(cluster_data['ps'])
print('ps_tasks%d',ps_tasks)
if worker_replicas > 1 and ps_tasks < 1:
raise ValueError('At least 1 ps task is needed for distributed training.')
if worker_replicas >= 1 and ps_tasks > 0:
# Set up distributed training. //注释掉
# server = tf.train.Server(tf.train.ClusterSpec(cluster), protocol='grpc',
# job_name=task_info.type,
# task_index=task_info.index)
server = tf.train.Server(cluster, job_name=task_info.type, task_index=task_info.index) //改动内容
print('进入worker%d',worker_replicas)
if task_info.type == 'ps' :
server = tf.train.Server(cluster, job_name=task_info.type, task_index=task_info.index)
print('进入ps')
server.join()
worker_job_name = '%s/task:%d' % (task_info.type, task_info.index)
task = task_info.index
is_chief = (task_info.type == 'master')
master = server.target
graph_rewriter_fn = None
if 'graph_rewriter_config' in configs:
graph_rewriter_fn = graph_rewriter_builder.build(
configs['graph_rewriter_config'], is_training=True)
trainer.train(
create_input_dict_fn,
model_fn,
train_config,
master,
task,
FLAGS.num_clones,
worker_replicas,
FLAGS.clone_on_cpu,
ps_tasks,
worker_job_name,
is_chief,
FLAGS.train_dir,
graph_hook_fn=graph_rewriter_fn)
if __name__ == '__main__':
tf.app.run()
执行命令
代码该写完以后执行相关命令:
ps机执行代码:进入虚拟环境并处在train文件同级。
c:TFWSVENVGPUScriptsactivate
cd C:TFWSmodelsresearchobject_detectionlegacy
python train.py --logtostderr --train_dir=C:TFWSmodelsresearchobject_detectiondo_datatraining --pipeline_config_path=C:TFWSmodelsresearchobject_detectiondo_datatrainingssd_mobilenet_v1_coco.config --type=ps --index=0master机执行代码:进入虚拟环境并处在train文件同级。
c:TFWSVENVGPUScriptsactivate
cd C:TFWSmodelsresearchobject_detectionlegacy
python train.py --logtostderr --train_dir=C:TFWSmodelsresearchobject_detectiondo_datatraining --pipeline_config_path=C:TFWSmodelsresearchobject_detectiondo_datatrainingssd_mobilenet_v1_coco.config --type=master --index=0worker机执行代码:进入虚拟环境并处在train文件同级。
c:TFWSVENVGPUScriptsactivate
cd C:TFWSmodelsresearchobject_detectionlegacy
python train.py --logtostderr --train_dir=C:TFWSmodelsresearchobject_detectiondo_datatraining --pipeline_config_path=C:TFWSmodelsresearchobject_detectiondo_datatrainingssd_mobilenet_v1_coco.config --type=worker --index=0执行顺序为:先执行ps机,再执行master机,接着执行worker机。
当ps机成功启动时显示:

当master机成功启动时显示:在等待worker机的接入。

当worker机成功启动后,master机的显示:

worker机和master机同时训练,达到分布式(异步)的效果。
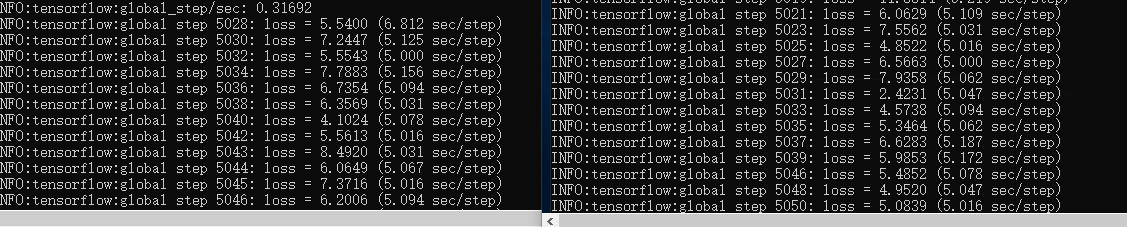
当有多个worker机时,顺序不能相反,比如是这样的:
"worker":[
"192.168.1.109:2222",
"192.168.1.111:2222",
"192.168.1.113:2222"
],
"ps":[
"192.168.1.116:2224"
],
"master":[
"192.168.1.108:2223"
]那么之后workerindex=0就必须是第一个,index=1就必须是第二个,以此类推。
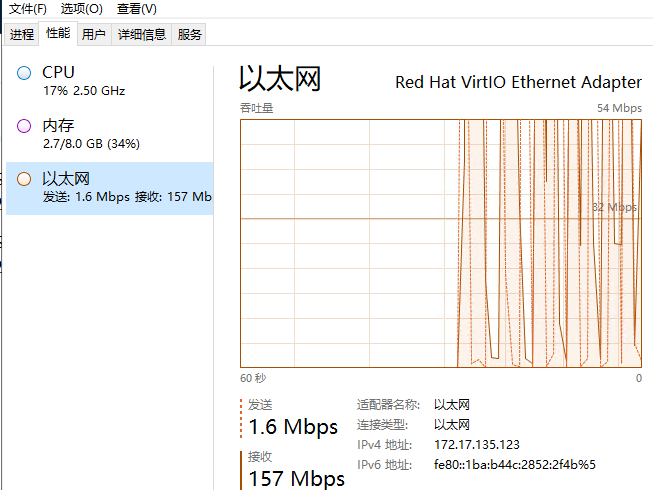
配置截图
下图为ps机
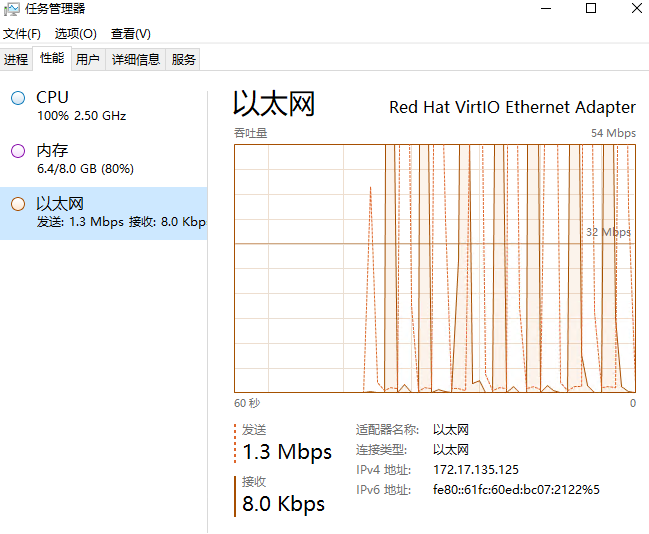
下图为worker机和master机
最后
以上就是留胡子小松鼠最近收集整理的关于tensorflow object_detection分布式训练 ObjectDetection系列(三)PS-worker架构的全部内容,更多相关tensorflow内容请搜索靠谱客的其他文章。








发表评论 取消回复