卷友们好,我是rumor。
我已经好久没看多模态的paper了,记忆中多模态20年开始火起来,但那时还是模仿BERT的阶段,直接把图像编码放到Transformer里进行预训练,是直接针对一个个任务的。然后就是21年DALLE出来了,但只是文本->图像的生成,图像-文本只有CLIP这种纯编码器的模型。直到最近关注了一篇DeepMind的Flamingo模型,没想到多模态已经和文本一样,开始进入了大模型+少样本打败精调的时代(文本模型是PaLM,在推理数据上以8-shot超越了4个精调SOTA)。
不仅是打败精调,更重要的是它的通用性,弥补了纯文本大模型在多模态应用场景的不足,可以直接做端到端的多模态任务,比如问答、图片分类、甚至都能自带OCR批改小学生作业了:

这种兼备了文本和图像的理解能力的神秘黑盒,又往幻化成人走了一步。
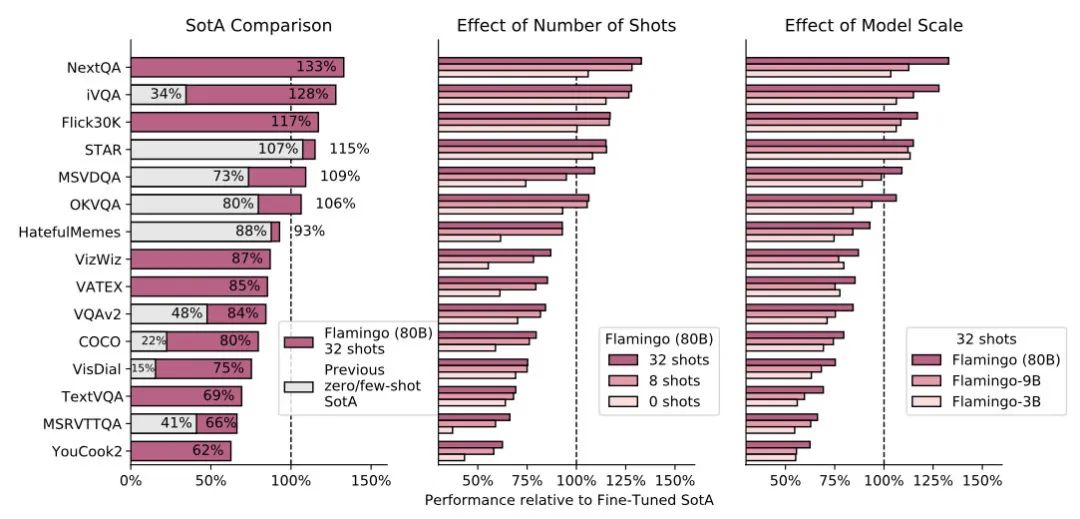
16个任务评估下来,Flamingo直接吊打之前的Zero/Few-shot SOTA,同时在6个任务上超越了现有的精调结果:
下面就让我们一起看看DeepMind是怎样调教Flamingo的。
模型
要把图像和文本合并到一起训练,第一个挑战就是怎样把2D的图像压缩到1D,好跟文本一起输入Transformer(不要问我为什么不把1D文本变成2D输入CNN,Transformer is all you need)。
作者首先用了一个预训练的ResNet对图像进行编码,之后为了节省后续Transformer的计算量,把图像编码压缩到R个token中,毕竟图像本来的信息密度就小一些,压一压也损失不了多少。
压缩的方法就是引入一个Perceiver Resampler模块,核心是做attention,如下图所示,用R个可学习的token作为Query,图像编码和R个token的拼接作为K和V(拼接后效果略好),这样attention下来输出也是R个token。
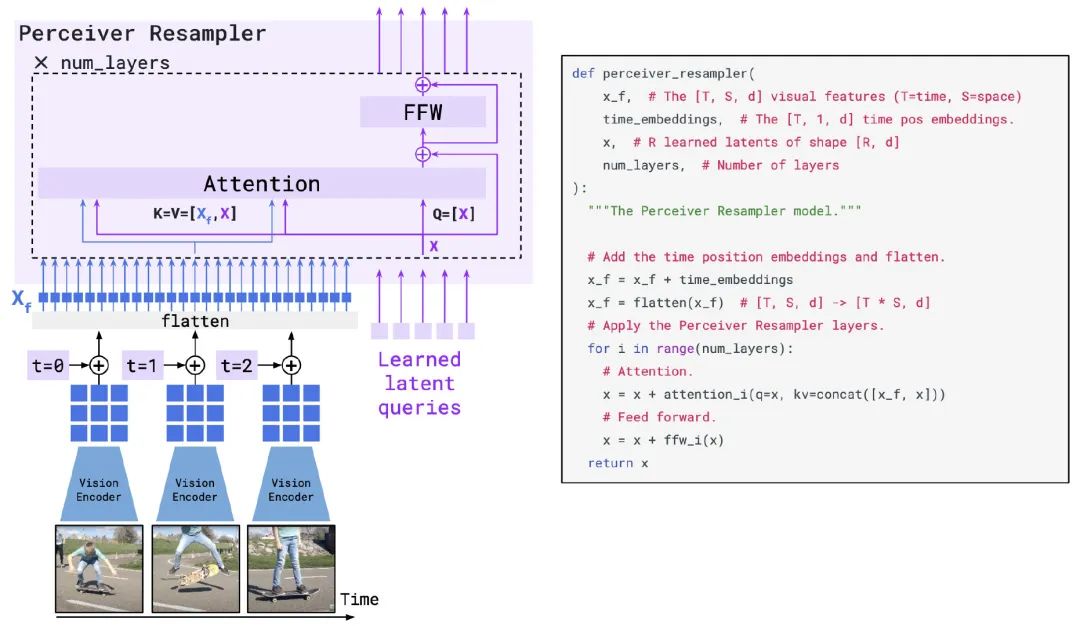
如果是视频的图像,作者会加上时间编码(位置编码也试了,没提升)。
把2D图像压缩到1D后,第二个挑战是如何让图像和文本做交互。
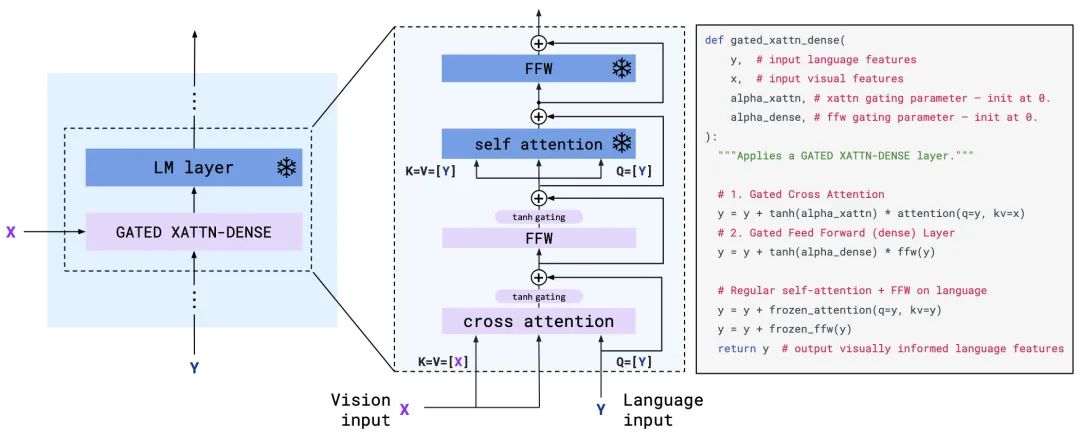
作者为了提升效率,直接从一个预训练好的70B语言模型Chinchilla[1]开始加入图像信息,考虑到保留之前LM学到的知识,训练时需要把LM的参数冻住,因此提出了Gated Cross attention机制来融合图像和文本。
具体来说,还是利用attention机制,如下图所示,把文本编码当作Q,图像编码当作K和V,这样输出的维度还是跟之前文本的一样。之后还是正常过FFW。同时为了提升稳定性和效果,在attention和FFW之后都增加了tanh门控,先开始是0,之后逐步增加。
但为了减少参数量,这个机制不一定每层都有,具体增加的策略如下:

同时为了减少不相关的图像噪声,也增加了一些mask策略。在Cross-attention时,每段文字只能关注到它之前的一个图像,如下图:
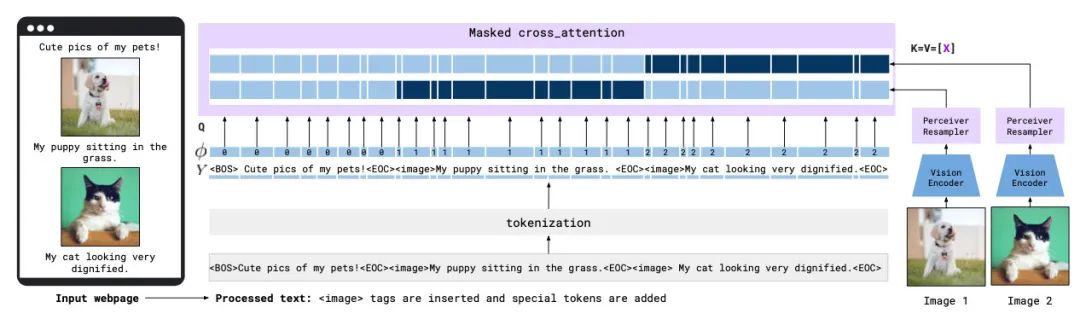
不过在最终预测的时候,还是保持LM的causal attention,也就是Cross-attention之后的正常attention可以保证在预测输出时会关注到以前所有的文字和图像。
有了上述两个机制后,图像和文本就成功融合到一起了,模型总结构如下(注意每个图像都是单独编码的):
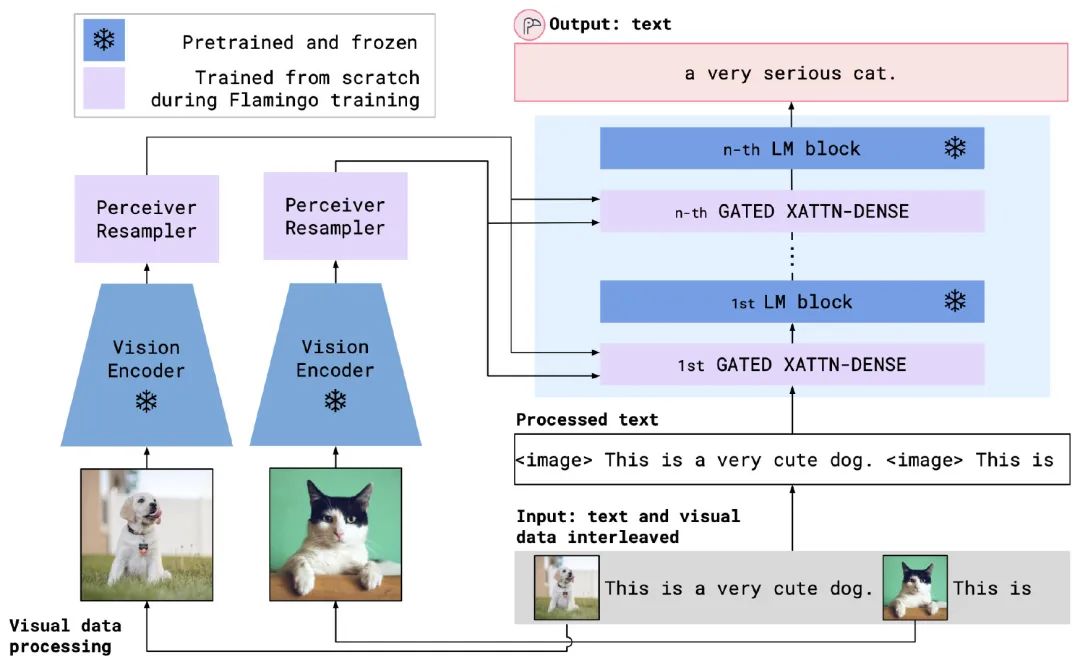
模型部分解决了,接下来第三个挑战是训练数据构造。
之前很多数据集要不是某个任务的,要不是处理好的文本和图像pair,而作者的目的是做一个泛化性更强的模型,因此不加任何的下游任务数据,直接从网页自己挖一些带有文本和图像的数据数据,构成M3W数据集。同时也用了别人的文本和图像pair的数据,如下所示:

效果
最终效果还是很惊艳的,Flamingo只用4-shot就可以碾压其他的Zero/Few-shot SOTA,并且32-shot在6个任务上超越了精调SOTA:
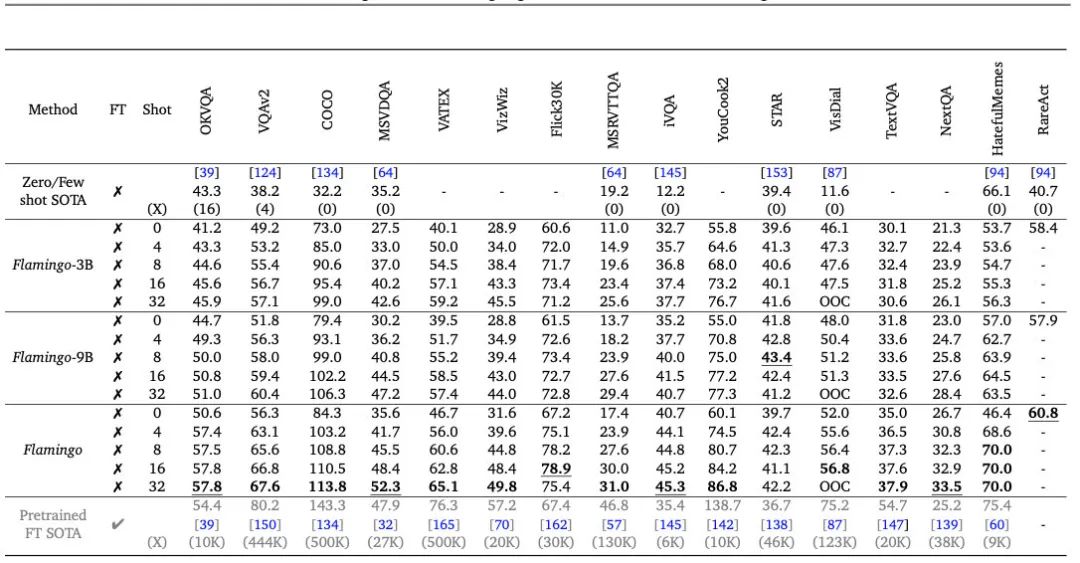
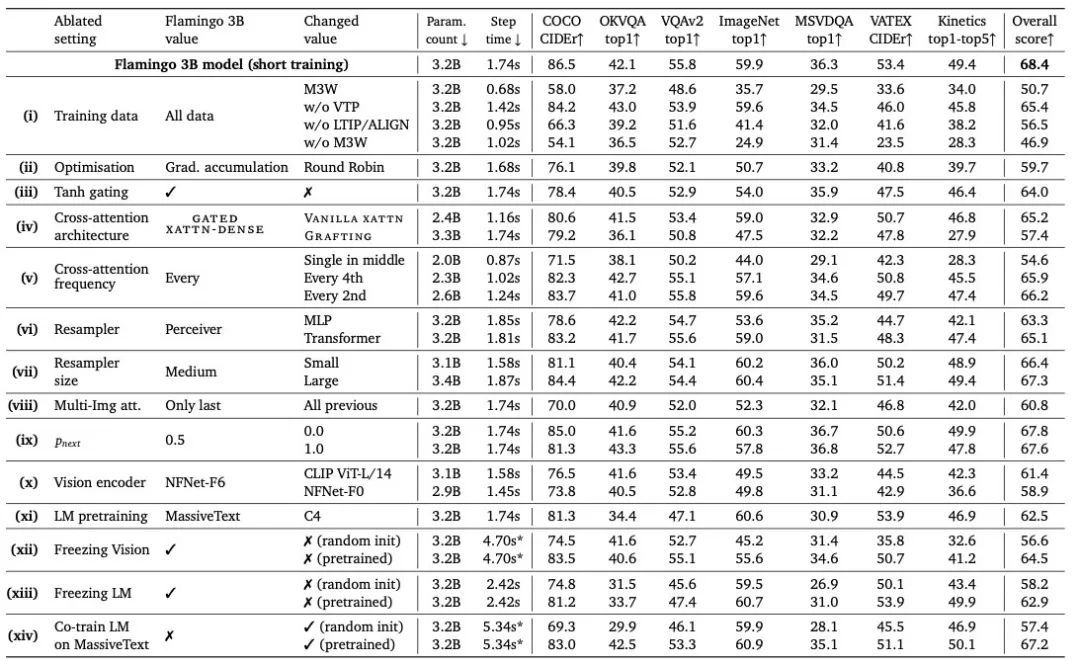
另外,作者提供了很详细的消融实验,可以给后续多模态模型参考,可以得到的一些关键结论是:
数据集真的很重要,其中M3W有作者们从网页收集的185M图像和182G的文本,LTIP包含312M的图像和文本,VTP包含27M的短视频和文本,M3W是其中占比很大的一个数据集
Cross-attention也起到了很大的作用,一方面是门控机制,另一方面是添加的频率(每层都加比偶尔加好)
总结
从很早起我就一直坚信,不管用深度学习还是其他方法,多模态肯定是一个必然的趋势,最近不光是这篇文章,我也看到了语音等其他模态的输入所赋予给模型的能力,那么,就让我们拭目以待吧。

参考资料
[1]
Training compute-optimal large language models: https://arxiv.org/pdf/2203.15556.pdf

我是朋克又极客的AI算法小姐姐rumor
北航本硕,NLP算法工程师,谷歌开发者专家
欢迎关注我,带你学习带你肝
一起在人工智能时代旋转跳跃眨巴眼
「要卷上CV了」
最后
以上就是有魅力飞鸟最近收集整理的关于DeepMind出手了!多模态少样本打败精调模型效果总结的全部内容,更多相关DeepMind出手了内容请搜索靠谱客的其他文章。








发表评论 取消回复