进程
一个进程,包括了代码、数据和分配给进程的资源(内存),在计算机系统里直观地说一个进程就是一个PID。操作系统保护进程空间不受外部进程干扰,即一个进程不能访问到另一个进程的内存。有时候进程间需要进行通信,这时可以使用操作系统提供进程间通信机制。通常情况下,执行一个可执行文件操作系统会为其创建一个进程以供它运行。但如果该执行文件是基于多进程设计的话,操作系统会在最初的进程上创建出多个进程出来,这些进程间执行的代码是一样,但执行结果可能是一样的,也可能是不一样的。
为什么需要多进程?最直观的想法是,如果操作系统支持多核的话,那么一个执行文件可以在不同的核心上跑;即使是非多核的,在一个进程在等待I/O操作时另一个进程也可以在CPU上跑,提高CPU利用率、程序的效率。
在Linux系统上可以通过fork()来在父进程中创建出子进程。一个进程调用fork()后,系统会先给新进程分配资源,例如存储数据和代码空间。然后把原来进程的所有值、状态都复制到新的进程里,只有少数的值与原来的进程不同,以区分不同的进程。fork()函数会返回两次,一次给父进程(返回子进程的pid或者fork失败信息),一次给子进程(返回0)。至此,两个进程分道扬镳,各自运行在系统里。
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <stdlib.h>
void print_exit(){
printf("the exit pid:%dn",getpid() );
}
int main (){
pid_t pid;
atexit( print_exit );
//注册该进程退出时的回调函数
pid=fork();
// new process
int count = 0;
if (pid < 0){
printf("error in fork!");
}
else if (pid == 0){
printf("i am the child process, my process id is %dn",getpid());
count ++;
printf("child process add count.n");
}
else {
printf("i am the parent process, my process id is %dn",getpid());
count++;
printf("parent process add count.n");
sleep(2);
wait(NULL);
}
printf("At last, count equals to %dn", count);
return 0;
} 为了说明父进程与子进程有各自的资源空间,设置了对count的计数。Terminal输出如下:、
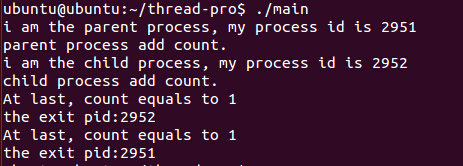
明显两个进程都执行了count++操作,但由于count是分别处在不同的进程里,所以实质上count在各自进程上只执行了一次。
线程
线程是可执行代码的可分派单元,CPU可单独执行单元。在基于线程的多任务的环境中,所有进程至少有一个线程(主线程),但是它们可以具有多个任务。这意味着单个程序可以并发执行两个或者多个任务。
也就是说,线程可以把一个进程分为很多片,每一片都可以是一个独立的流程,CPU可以选择其中的流程来执行。但线程不是进程,不具有PID,且分配的资源属于它的进程,共享着进程的全局变量,也可以有自己“私有”空间。但这明显不同于多进程,进程是一个拷贝的流程,而线程只是把一条河流截成很多条小溪。它没有拷贝这些额外的开销,但是仅仅是现存的一条河流,就被多线程技术几乎无开销地转成很多条小流程,它的伟大就在于它少之又少的系统开销。
Linux中可以使用pthread库来创建线程,但由于pthread不是Linux内核的默认库,所以编译时需要加入pthread库一同编译。
g++ -o main main.cpp -pthread
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
#include <pthread.h>
void* task1(void*);
void* task2(void*);
void usr();
int p1,p2;
int count = 0 ;
int main()
{
usr();
return 0;
}
void usr(){
pthread_t pid1, pid2;
pthread_attr_t attr;
void *p1, *p2;
int ret1=0, ret2=0;
pthread_attr_init(&attr);
//初始化线程属性结构
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_JOINABLE);
//设置attr结构
pthread_create(&pid1, &attr, task1, NULL);
//创建线程,返回线程号给pid1,线程属性设置为attr的属性
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_JOINABLE);
pthread_create(&pid2, &attr, task2, NULL);
ret1=pthread_join(pid1, &p1);
//等待pid1返回,返回值赋给p1
ret2=pthread_join(pid2, &p2);
//等待pid2返回,返回值赋给p2
printf("after pthread1:ret1=%d,p1=%dn", ret1,(int)p1);
printf("after pthread2:ret2=%d,p2=%dn", ret2,(int)p2);
printf("At last, count equals to %dn", count);
}
void* task1(void *arg1){
printf("task1 begin.n");
count++;
printf("task1 thread add count.n");
pthread_exit( (void *)1);
}
void* task2(void *arg2){
printf("thread2 begin.n");
count ++;
printf("task2 thread add count.n");
pthread_exit((void *)2);
}
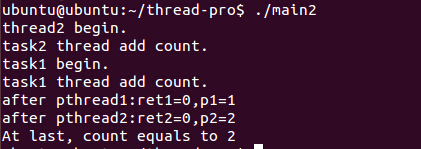
Terminal的输出显示thread2先于thread1执行,表明了这不是一个同步的程序,线程的运行是单独进行的,由内核线程调度来进行的。为了区别进程,在代码中也加入了count++操作。最后在主线程中输出count=2,即count被计数了2次,子线程被允许使用同一个进程内的共享变量,区别了进程的概念。
由于线程顺序、时间的不确定性,往往需要对进程内的一个共享变量进行读写限制,比如加锁等。
总结
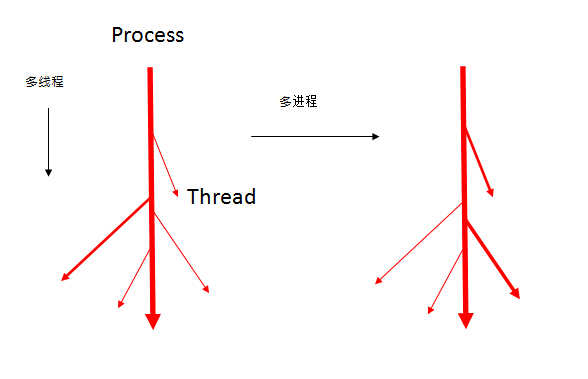
多进程和多线程的概念可以概括为一条河流。
1.纵向的是多线程,进程就像河流,线程就是分流,线程从一个进程中衍生出来。河流可以把水引向分流分担自身的流水量,且各个分流是同时流水的(并发),它们共享了一个源头(共享变量);
2.横向的是多进程,一条河流从源头上几乎完全与另一条河流一样,但由于一些环境的不同,造成了两者最后的流向、各个分流的流量可能会不一样,但是两条河流同时在流水(并发)。
最后
以上就是勤劳手套最近收集整理的关于学习整理——多进程和多线程概念理解的全部内容,更多相关学习整理——多进程和多线程概念理解内容请搜索靠谱客的其他文章。






![python多进程manager_python进程之间修改数据[Manager]与进程池[Pool]](https://www.shuijiaxian.com/files_image/reation/bcimg16.png)

发表评论 取消回复