# All default
pd.merge(
left,
right,
how="inner",
on=None,
left_on=None,
right_on=None,
left_index=False,
right_index=False,
sort=True,
suffixes=("_x", "_y"),
copy=True,
indicator=False,
validate=None,
)import pandas as pd
#当只加两个dataframe参数,其余参数都为默认的时候,两个dataframe必须要有至少一个相同的两列,否则会报错
#一个相同的key
data1 = pd.DataFrame(
{
"key1": ["K0", "K1", "K2", "K3"],
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
}
)
data2 = pd.DataFrame(
{
"key1": ["K0", "K1", "K2", "K3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
}
)
mergeData = pd.merge(data1,data2)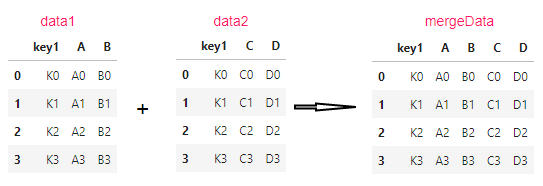
#两个相同的key
data3 = pd.DataFrame(
{
"key1": ["K0", "K1", "K2", "K3"],
"key2": ["K4", "K5", "K6", "K7"],
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
}
)
data4 = pd.DataFrame(
{
"key1": ["K0", "K1", "K2", "K3"],
"key2": ["K4", "K5", "K6", "K7"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
}
)
mergeData1 = pd.merge(data3,data4)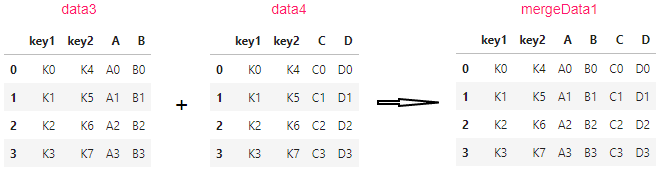
#没有相同的key
data5 = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
}
)
data6 = pd.DataFrame(
{
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
}
)
pd.merge(data5,data6)
#MergeError: No common columns to perform merge on. Merge options: left_on=None, right_on=None, left_index=False, right_index=Falseon 指定相同合并的列
pd.merge(data3,data4,on="key1")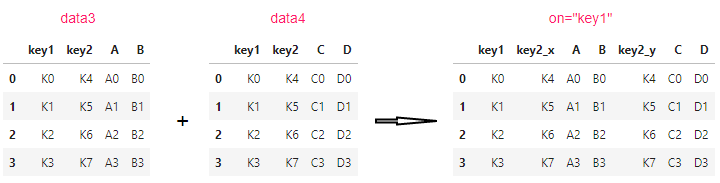
pd.merge(data3,data4,on=["key1","key2"])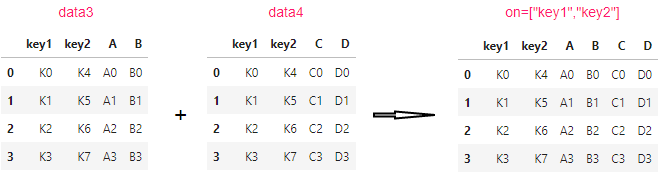
left_on, right_on 指定不同合并的列
data5 = pd.DataFrame(
{
"key1": ["K0", "K1", "K2"],
"A": ["A0", "A1", "A2"],
"B": ["B0", "B1", "B2"],
}
)
data6 = pd.DataFrame(
{
"key2": ["K1", "K2", "K3"],
"C": ["C0", "C1", "C2"],
"D": ["D0", "D1", "D2"],
}
)
pd.merge(data5,data6,left_on="key1",right_on="key2")
how - left、right、outer、inner(Default)、cross
#注意两个DaraFrame的key1和key2不一样
left = pd.DataFrame(
{
"key1": ["K0", "K0", "K1", "K2"],
"key2": ["K0", "K1", "K0", "K1"],
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
}
)
right = pd.DataFrame(
{
"key1": ["K0", "K1", "K1", "K2"],
"key2": ["K0", "K0", "K0", "K0"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
}
)left :只保留左侧dataframe的keys进行合并,右侧dataframe的keys如果左侧dataframe没有的话,则删除。
pd.merge(left, right, how="left", on=["key1", "key2"])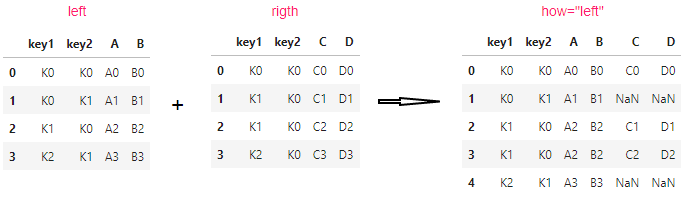
right :只保留右侧dataframe的keys进行合并,左侧dataframe的keys如果右侧dataframe没有的话,则删除。
pd.merge(left, right, how="right", on=["key1", "key2"])
outer :并集,即两个dataframe的keys都保留
pd.merge(left, right, how="outer", on=["key1", "key2"])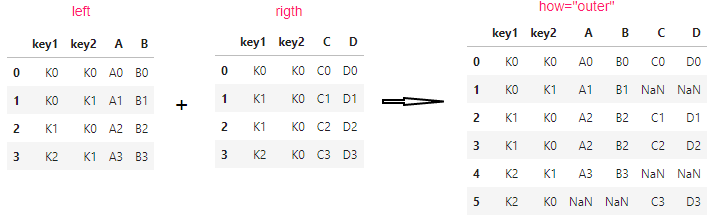
inner :交集,即两个dataframe的相同keys才保留
pd.merge(left, right, how="inner", on=["key1", "key2"])
cross :组合,4*4=16行,但不能再使用"on"参数
pd.merge(left, right, how="cross")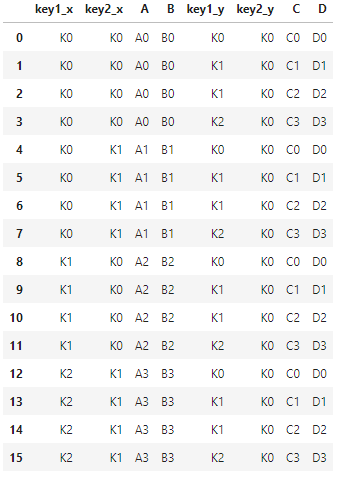
left_index , right_index 通过index进行合并
left = pd.DataFrame(
{"A": ["A0", "A1", "A2"], "B": ["B0", "B1", "B2"]}, index=["K0", "K1", "K2"]
)
right = pd.DataFrame(
{"C": ["C0", "C2", "C3"], "D": ["D0", "D2", "D3"]}, index=["K0", "K2", "K3"]
)
#两个index都必须设置为True,否则报错。
pd.merge(left, right, left_index=True, right_index=True, how="outer")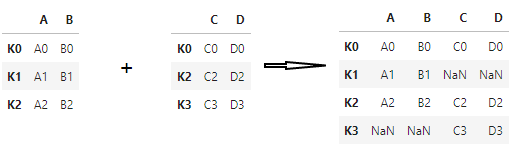
pd.merge(left, right, left_index=True, right_index=True, how="inner")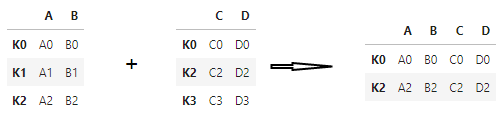
suffixes 两个dataframe有相同的列名,并且这列名不做keys时,使用不同的后缀来区别两个dataframe的列
pd.merge(data3, data4, on="key1", how="outer", suffixes=("_first","_second"))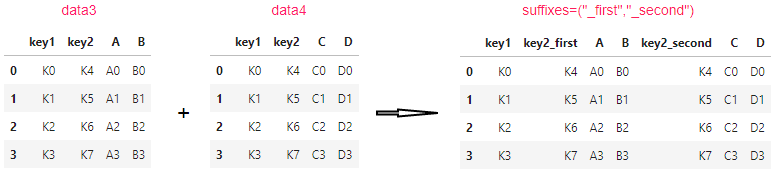
indicator 溯源,判断新dataframe的key分别来自哪个dataframe(both,left_only,right_only)
pd.merge(left, right, left_index=True, right_index=True, how="outer", indicator="indicator_column")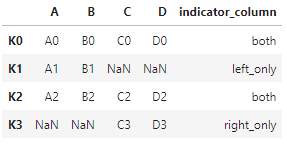
validate
"one_to_one" or "1:1": checks if merge keys are unique in both left and right datasets.
"one_to_many" or "1:m": checks if merge keys are unique in left dataset.
"many_to_one" or "m:1": checks if merge keys are unique in right dataset.
"many_to_many" or "m:m": allowed, but does not result in checks.
df1 = pd.DataFrame({"A": [1, 2], "B": [1, 2]})
df2 = pd.DataFrame({"A": [4, 5, 6], "B": [2, 2, 2]})#右侧的df2,"B"列里是有重复的
pd.merge(df1, df2, on="B", how="outer", validate="one_to_one")
#MergeError: Merge keys are not unique in right dataset; not a one-to-one merge
pd.merge(df1, df2, on="B", how="outer", validate="many_to_one")
#Merge keys are not unique in right dataset; not a many-to-one merge
pd.merge(df1, df2, on="B", how="outer", validate="one_to_many")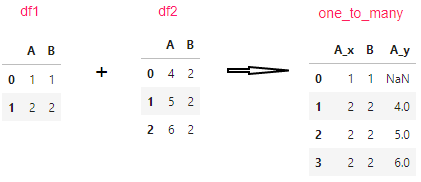
#换A作为key试试。
pd.merge(df1, df2, on="A", how="outer", validate="one_to_one")
pd.merge(df1, df2, on="A", how="outer", validate="many_to_one")
pd.merge(df1, df2, on="A", how="outer", validate="one_to_many")
#都是同一个结果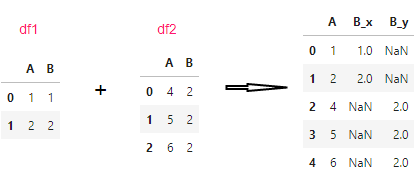
merge其他更加复杂的合并方式,请大家移步官网:https://pandas.pydata.org/docs/user_guide/merging.html
最后
以上就是愤怒墨镜最近收集整理的关于pandas - merge 函数的全部内容,更多相关pandas内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复