导入依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.11</artifactId>
<version>2.4.3</version>
</dependency>
import org.apache.spark.sql.SparkSession
object KafkaSource {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local[*]")
.appName("KafkaSource")
.getOrCreate()
import spark.implicits._
val df = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers","hadoop102:9092,hadoop103:9092,hadoop104:9092")
.option("subscribe","topic1")
.load
df.writeStream
.format("console")
.outputMode("update")
.option("truncate",false)
.start
.awaitTermination()
}
}

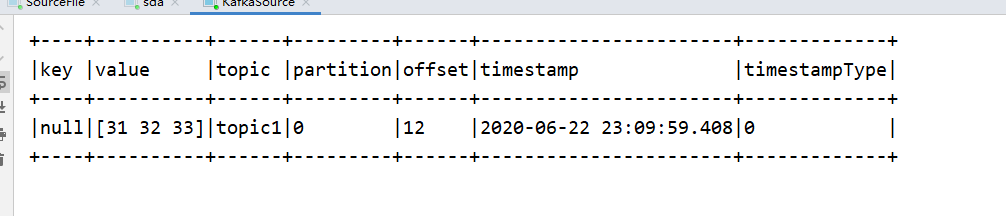
import org.apache.spark.sql.SparkSession
object KafkaSource {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local[*]")
.appName("KafkaSource")
.getOrCreate()
import spark.implicits._
val df = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers","hadoop102:9092,hadoop103:9092,hadoop104:9092")
.option("subscribe","topic1")
.load
// .select("value")
.selectExpr("cast(value as string)")
.as[String]
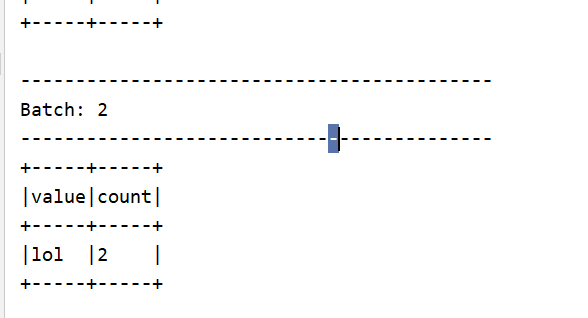
.flatMap(_.split(" "))
.groupBy("value")
.count()
df.writeStream
.format("console")
.outputMode("update")
.option("truncate",false)
.start
.awaitTermination()
}
}

最后
以上就是心灵美路灯最近收集整理的关于Structure Streaming-Kafka source的全部内容,更多相关Structure内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。







![Structured Streaming:从入门到精通(三)[整合Kafka,Mysql]整合Kafka整合MySQL](https://www.shuijiaxian.com/files_image/reation/bcimg24.png)
发表评论 取消回复