目录
一、前言
二、软件漏洞数据分析
三、软件漏洞分类实验流程
四、软件漏洞文本预处理
五、软件漏洞文本表示方法
六、软件漏洞分类模型构建
七、软件漏洞分类实验结果与分析
八、总结
一、前言
本人基于网络空间安全研究方向做过入侵检测实验、软件缺陷分类实验、软件安全漏洞分类管理实验等,网络安全方向相关数据集可参看个人总结:网络安全相关数据集介绍与下载。
本文的主要目的是为了构造一个有效的软件漏洞分类模型,该模型能有效提高软件漏洞分类管理的效率和软件漏洞分类的准确率。本文主要使用深度学习相关方法构造漏洞分类模型进行实验调研。
二、软件漏洞数据分析
实验所用数据为美国国家计算机通用漏洞数据库(National Vulnerability Database,NVD)和中国国家信息安全漏洞库(China National Vulnerability Database of Information Security,CNNVD),主要以NVD漏洞数据库中的漏洞数据为基准数据,本次实验使用的是从2002年到2019年5月份的NVD漏洞数据。
NVD漏洞数据库收录的漏洞数据具有唯一性,规范性,兼容性和统一性,采用国际编码语法规范,因此,可以作为软件漏洞分类研究的基准数据集。NVD漏洞数据库提供了XML和JSON两种格式的漏洞文件,本文使用的是XML格式的漏洞文件,文件中包含了漏洞的CVE-ID,CVSS_score,CVSS_Accuracyess,CVSS_vector,vuln-source,CWE-ID和vuln-summary等漏洞信息。
在过去的十几年中,漏洞数量增长迅速,对NVD从2002年到2019年5月份的数据统计显示,漏洞总数高达121279条,其中包括未知漏洞类型就多达38868条。年度新增漏洞数量分布如下图所示:
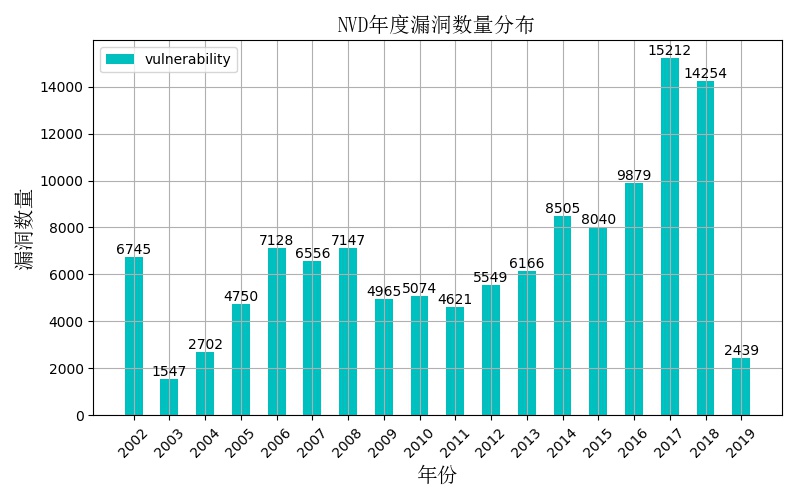
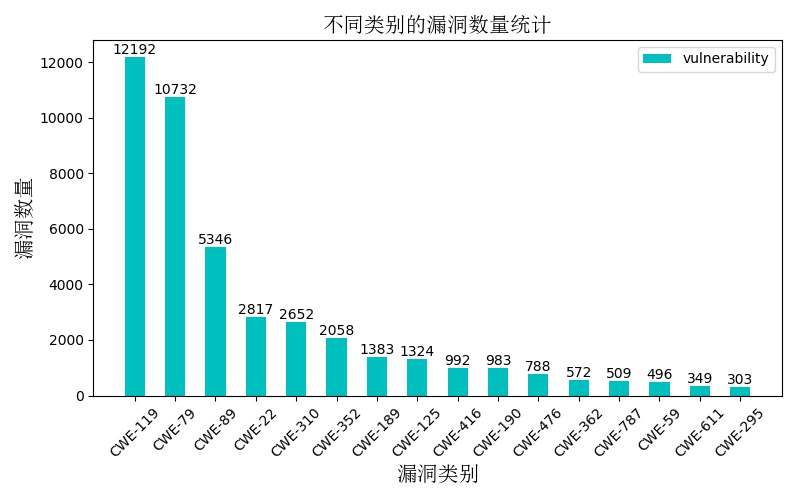
本实验选取从2002年到2019年5月份的43496条NVD漏洞数据进行实验研究,其中包含16个主要漏洞类型。不同漏洞类型统计数量分布如下图所示:
实验使用Python编程语言从XML漏洞文件中提取CVE-ID,CWE-ID和vuln-summary三部分数据信息,不相关的字段和不完整的数据将被删除,提取的部分漏洞信息如下表所示:
| CVE-ID | CWE-ID | vuln-summary |
| CVE-2019-9961 | CWE-79 | A cross-site scripting (XSS) vulnerability in ressource view in core/modules/resource/RESOURCEVIEW.php in Wikindx prior to version 5.7.0 allows remote attackers to inject arbitrary web script or HTML via the id parameter. |
| CVE-2019-9962 | CWE-119 | XnView MP 0.93.1 on Windows allows remote attackers to cause a denial of service (application crash) or possibly have unspecified other impact via a crafted file, related to VCRUNTIME140!memcpy. |
| … | … | … |
其中,CVE-ID表示每条漏洞的编号,CWE-ID表示漏洞类型,可以根据CWE标准得到漏洞具体类别,vuln-summary是对每条漏洞的详细描述信息 。
根据CWE标准可获得每个CWE-ID所对应的漏洞类型如下表所示(包括漏洞类别的中英文版本):
| CWE-ID | Vulnerability type |
| CWE-119 | Buffer Errors |
| CWE-79 | Cross-Site Scripting(XSS) |
| CWE-89 | SQL Injection |
| CWE-22 | Path Traversal |
| CWE-310 | Cryptographic Issues |
| CWE-352 | Cross-Site Request Forgery(CSRF) |
| CWE-189 | Numeric Errors |
| CWE-125 | Out-of-bounds Read |
| CWE-416 | Use After Free |
| CWE-190 | Integer Overflow or Wraparound |
| CWE-476 | Null Pointer Dereference |
| CWE-362 | Race Conditions |
| CWE-787 | Out-of-bounds Write |
| CWE-59 | Link Following |
| CWE-611 | XXE |
| CWE-295 | Improper Certificate Validation |
| CWE-ID | 漏洞类型 |
| CWE-119 | 缓冲区错误 |
| CWE-79 | 跨站点脚本(XSS) |
| CWE-89 | SQL 注入 |
| CWE-22 | 路径遍历 |
| CWE-310 | 加密问题 |
| CWE-352 | 跨站请求伪造(CSRF) |
| CWE-189 | 数字错误 |
| CWE-125 | 越界阅读 |
| CWE-416 | 免费使用 |
| CWE-190 | 整数溢出或环绕 |
| CWE-476 | Null指针解除引用 |
| CWE-362 | 比赛条件 |
| CWE-787 | 越界写作 |
| CWE-59 | 链接后 |
| CWE-611 | XXE |
| CWE-295 | 证书验证不正确 |
本实验将43496条NVD漏洞数据划分为训练集和测试集,其中训练集36971条,测试集6525条。
三、软件漏洞分类实验流程
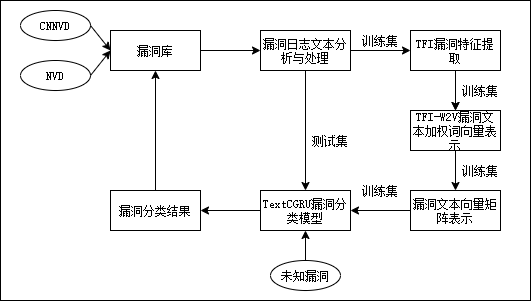
软件漏洞分类实验主要包括漏洞数据预处理、漏洞文本表示和漏洞分类模型三部分组成。详细实验流程图如下图所示:
四、软件漏洞文本预处理
数据预处理就是为了清洗数据,去除无用文本信息等,为漏洞文本表示做准备。实验过程中分别总结了中英文数据的常用预处理方法。
可参看:英文自然语言预处理,中文自然语言预处理方法总结。
本实验主要用了以下几种预处理方法:标点符号和特殊字符的去除、分词并将所有字符的大写转换为小写、词形还原、停用词过滤等。(并不局限于这几种预处理方法)
详细过程如下:
1、去除标点符号和特殊字符
原始漏洞文本中包含很多标点符号和特殊字符,而这些元素与上下文并不存在语义上的联系,因此首先需要对文本中的所有标点符号和特殊字符进行过滤,只保留含有较多语义信息的词汇。(可以使用正则表达式去除)
2、分词并将所有字符的大写转换为小写
对漏洞文本进行分词是指将连贯的漏洞文本信息切分成一个一个的单词,即将整个漏洞文本信息转换为可以通过统计学进行统计的最小语义单元。对于英文描述的漏洞文本,分词是非常简单的,只需要通过识别文本之间的空格或者标点符号即可将整条漏洞文本划分成一个一个的单词。然后将单词中所有字母的大写形式转换为字母的小写形式。
3、词形还原
词形还原是把一个任何形式的英文单词还原为一般形式,即将英文描述中的动词根据人称不同而变化的单词转换为动词原形;将名词的复数形式转换为名词的单数形式;将动名词形式转换为动词原形等,这些词都应该属于同一类的语义相近的词。比如“attack”,“attacking”,“attacked”则可划分为同属于一个词,用词根形式“attack”表示即可。
4、停用词过滤
停用词是指在漏洞文本中频繁出现且对文本信息的内容或分类类别贡献不大甚至无贡献的词语,如常见的介词、冠词、助词、情态动词、代词以及连词等对于漏洞分类来说毫无意义,因此这类词语应该被过滤掉。同时针对漏洞文本中有些词如“information”,“security”,“vulnerability”等词对于漏洞分类来说毫无意义,因此这类词语也应该被过滤掉。
本实验通过参考从网上下载的通用停用词表,并结合漏洞文本信息自身的特点构建针对漏洞分类专属的专用停用词表实现频繁无用词的过滤。(针对漏洞自身的频繁无用词的提取方法可以使用基于词频统计的方法,比如将每个单词按词频大小降序排列,然后设定一个阈值,将低于这个阈值的单词加入到专业停用词表中。)
停用词的过滤可以大大消除漏洞文本中的冗余信息,减少数据的冗余性。
五、软件漏洞文本表示方法
经过预处理后的漏洞数据并不能够直接输入模型进行分类,需要进行关键词提取并转化为词向量或句向量的形式输入模型进行训练和测试等,所以实验中探索了漏洞文本表示的可行性方法,总结如下。
方法一:关键词提取+词袋表示
使用TF-IDF和信息增益等方法进行漏洞数据的关键词提取,关键词提取的个数即为每条漏洞文本的向量维度(关键词提取多少个合适呢?这个可以根据实验效果进行调整,选择效果较优的关键词个数即可)。
然后把每一条漏洞文本表述成一个m维的向量(m就是所提取关键词的个数),这里可以使用词袋模型(one-hot编码,以关键词的权重值进行填充,每条漏洞文本中出现关键词则使用权重表示,不是关键词的用0表示即可),这样所有的漏洞文本通过这个m维的多维空间进行向量化后,漏洞文本的向量表示即建立完成。
关于实验过程中所用到的关键词提取方法本人做了总结,可参看:NLP关键词提取方法总结及实现
方法二:词的分布式表示方法
本人实验过程中使用了Word2Vec,Glove,Doc2vec,Fasttext等,并对其做了总结,可参看:NLP词向量和句向量方法总结及实现。
本实验使用了Word2Vec进行词向量的生成,使用了word2vec中基于Skip-gram语言模型的词分布式表示方法对漏洞文本进行词向量的训练和生成,同时使用了负采样的方法对Skip-gram模型进行优化。实验以43496条NVD漏洞数据作为词向量训练语料库(可以使用所有的漏洞数据),词向量维度设置为300,将语料中词频小于10的词去掉,使用负采样进行优化时的采样个数设置为5。
每条漏洞文本的表示方法有(1)将每条漏洞文本中所有词的向量相加求和然后取平均来表示句向量,即实验将每条漏洞文本使用300维的向量表示,作为模型的输入。(2)将每条漏洞文本中每个词的向量乘以该词的权重(加权词向量),然后相加求和取平均来表示句向量,作为模型的输入。其中,权重可以根据TF-IDF和信息增益等方法求得。(3)将每条漏洞文本表示成一个句子矩阵作为模型的输入。句子中每个词是由m维词向量组成的,也就是说输入矩阵大小为n*m,其中n为句子长度。
还可以尝试探索Elmo,Bert,Flair等方法。
六、软件漏洞分类模型构建
模型的构建可以使用传统机器学习方法、集成方法或使用DNN,LSTM,Bi-LSTM等深度学习方法。本实验构建了基于神经网络的TextCGRU分类模型。模型主要包括输入输层,卷积层,池化层,GRU层和输出层。如下图:
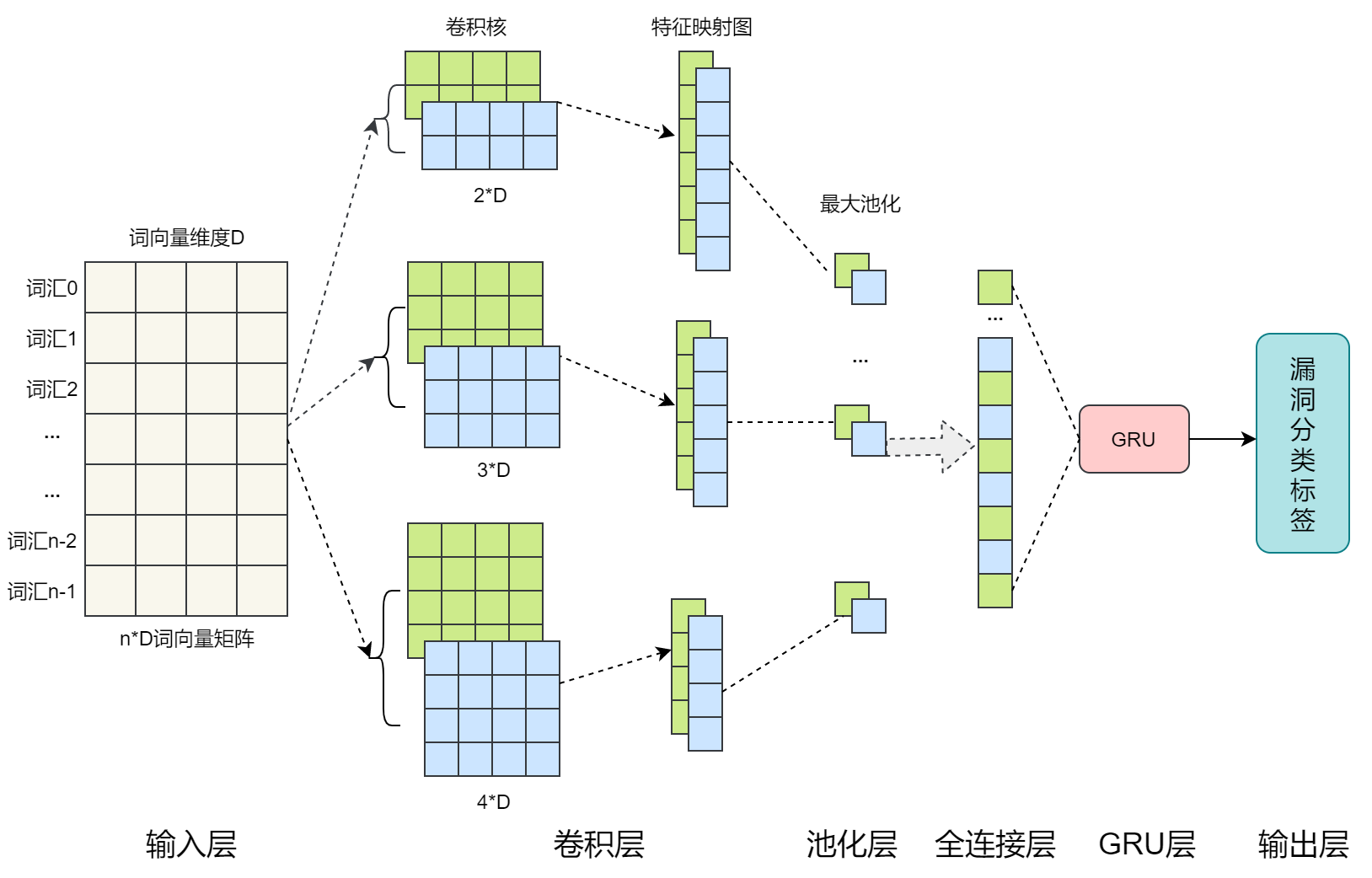
本实验的模型结构如图所示:
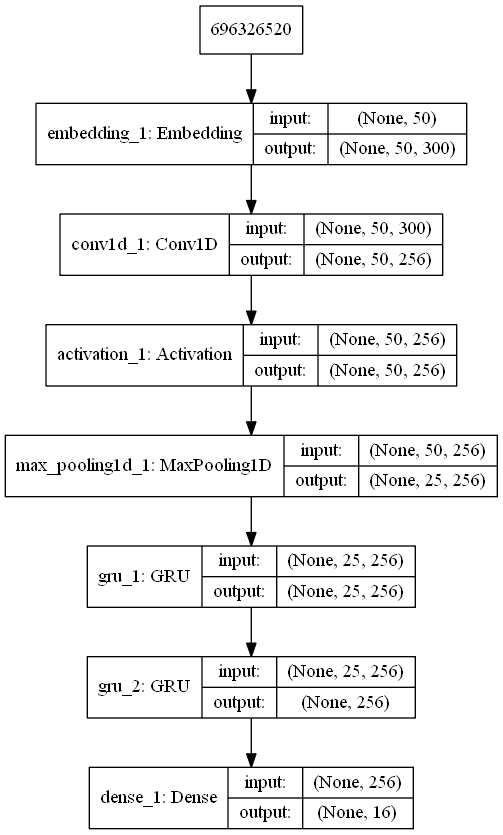
其中,嵌入层是50*300的二维矩阵,卷积层的滤波器为3*300的二维矩阵,向下移动的步长为1,卷积层之后使用Relu激活函数,最大池化层的池化窗口大小设置为2,GRU层的神经元个数设置为256,使用Dropout防止模型过拟合,其Dropout值设置为0.5,输出层的神经元个数设置为16,并且使用softmax作为输出层的激活函数。使用交叉熵损失函数计算该模型的损失,使用Adam优化器最小化损失函数,模型训练的批次大小设置为600,迭代次数设置为25。
其中,GRU(Gated Recurrent Unit)是LSTM的一个变体,在保留LSTM效果的同时,使结构更加简单,迭代速度也更快。GRU包括两个门控结构,分别为重置门和更新门。
GRU结构如图所示:
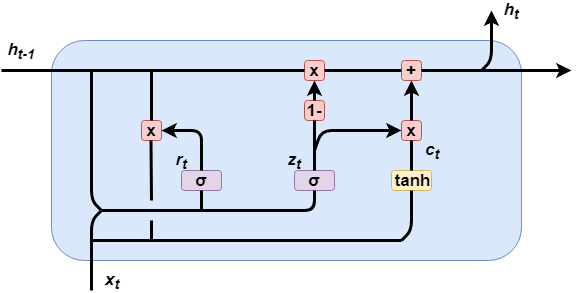
GRU内部结构的具体计算公式如下:

七、软件漏洞分类实验结果与分析
1、模型训练损失图
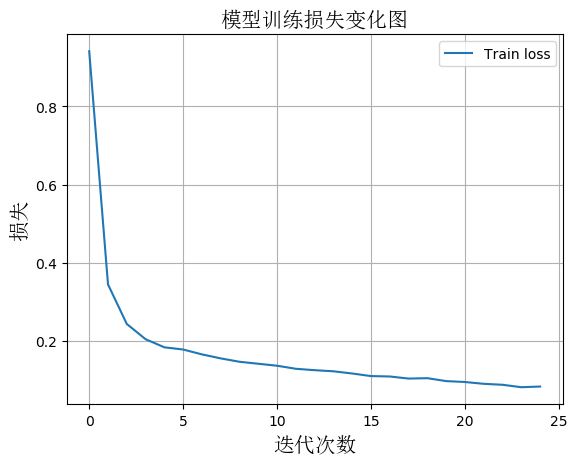
从图中可以看出,模型在迭代20次时,损失(loss)值下降到了一个相对较低的稳定值,模型取得较好收敛效果。
2、随着模型训练迭代次数的增加,模型在测试集上准确率变化图
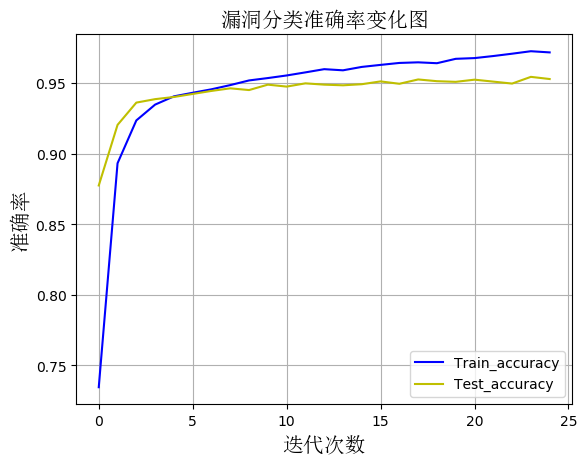
从图中可以看出随着迭代次数的增加,模型在测试集上的准确率逐渐提到,最终达到了95%。
3、随着模型训练迭代次数的增加,模型在测试集上的宏精确率、宏召回率和宏F1的变化图
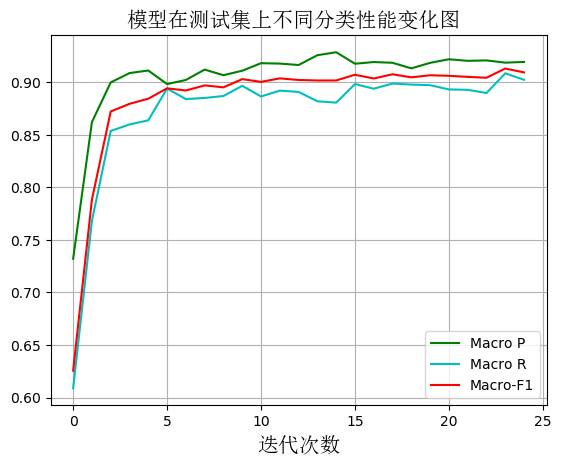
从图中可以看出随着迭代次数的增加,模型分类的Macro P、Macro R和Macro F1逐渐提高,当迭代达到15次时,模型的分类性能趋于稳定且处于一个相对较高的值,都超过了90%。
4、实验使用测试集对训练好模型进行分类测试,对所有漏洞类别详细分类结果混淆矩阵图
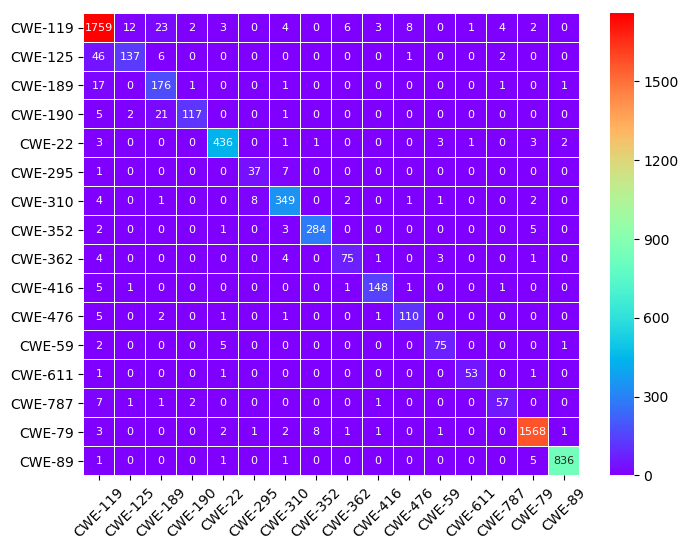
图中的行代表漏洞类别,每行的数字之和代表该漏洞类别的漏洞数目,对角线上的数字表示漏洞分类正确的个数,其余数字表示漏洞类别分类错误的个数。
5、模型对不同漏洞类型分类的精确率,召回率和F1-score值结果如下表
| Vulnerability type | Vulnerability number | P(Precision) | R(Recall) | F1(F1-score) |
| CWE-119 | 1827 | 0.94 | 0.96 | 0.95 |
| CWE-125 | 192 | 0.90 | 0.71 | 0.79 |
| CWE-189 | 197 | 0.77 | 0.89 | 0.82 |
| CWE-190 | 146 | 0.96 | 0.80 | 0.87 |
| CWE-22 | 450 | 0.97 | 0.97 | 0.97 |
| CWE-295 | 45 | 0.80 | 0.82 | 0.81 |
| CWE-310 | 368 | 0.93 | 0.95 | 0.94 |
| CWE-352 | 295 | 0.97 | 0.96 | 0.97 |
| CWE-362 | 88 | 0.88 | 0.85 | 0.87 |
| CWE-416 | 157 | 0.95 | 0.94 | 0.95 |
| CWE-476 | 120 | 0.91 | 0.92 | 0.91 |
| CWE-59 | 83 | 0.90 | 0.90 | 0.90 |
| CWE-611 | 56 | 0.96 | 0.95 | 0.95 |
| CWE-787 | 69 | 0.88 | 0.83 | 0.85 |
| CWE-79 | 1588 | 0.99 | 0.99 | 0.99 |
| CWE-89 | 844 | 0.99 | 0.99 | 0.99 |
从表中结果我们可以看出,模型对漏洞整体分类的性能达到了相对较高的水平。
6、模型在测试集上的分类性能如下表
| Model | Macro P | Macro R | Macro F1 |
| TextCGRU | 0.90 | 0.92 | 0.91 |
7、实验总结
实验主要使用了Word2Vec方法来表示漏洞文本,构造了基于神经网络的TextCGRU分类模型,很好的表征了词与词之间的语义和语法信息,同时也很好的处理了词向量空间的高维性和稀疏性问题。实验在测试集上的准确率达到了95%,在Macro P、Macro R和Macro F1这三个指标上分别达到了90%,92%和91%。
八、总结
随着深度学习的发展,越来越多的方法可以应用于软件漏洞分类领域,并能提高软件漏洞分类的效率和准确率。本文仅仅是记录了自己的实验历程,总结了自己实验中的想法和实现的过程,难免有不足之处,若有不足欢迎指正。本篇的大致思路、方法等总结的应该都比较清晰了,由于篇幅问题,一些细节问题在这里不再阐述,希望本篇博客总结能够帮助到做相关研究的人。还有本篇版权所有,仅供学习参考。记录学习,分享快乐!2020/7/16
NVD软件漏洞数据处理及分类方法源代码及数据集资源下载:
NVD软件漏洞数据处理及分类源代码及数据集资源.zip-网络安全文档类资源-CSDN下载
1、网络安全相关数据集介绍
2、KDD99 CUP数据集预处理
交流学习资料共享欢迎入群:955817470(群一),801295159(群二)
最后
以上就是大力大船最近收集整理的关于NVD软件漏洞数据处理及分类方法总结的全部内容,更多相关NVD软件漏洞数据处理及分类方法总结内容请搜索靠谱客的其他文章。








发表评论 取消回复