隐式马尔可夫模型的基础假设是,一个连续的时间序列时间,它的状态由且仅由前面的N个事件决定,对应的时间序列可以成为N阶马尔可夫链。
1.使用隐式马尔可夫算法识别XSS攻击
在URL的参数中,有字母大小写、数字和字符,经过范化为不同的标志后,这里研究的隐藏序列便是状态见的循环转化了,HMM就是通过学习样本生成转移概率矩阵和发射概率矩阵。
首先我们采用以白找黑的思路,通过学习正常来识别异常:
#-*- coding:utf-8 –*-
from apriori import apriori
from apriori import generateRules
import re
if __name__ == '__main__':
myDat=[]
#L, suppData = apriori(myDat, 0.5)
#rules = generateRules(L, suppData, minConf=0.7)
#print 'rules:n', rules
with open("/Users/zhanglipeng/Data/web-attack/xss-2000.txt") as f:
for line in f:
#/discuz?q1=0&q3=0&q2=0%3Ciframe%20src=http://xxooxxoo.js%3E
index=line.find("?")
if index>0:
line=line[index+1:len(line)]
#print line
tokens=re.split('=|&|?|%3e|%3c|%3E|%3C|%20|%22|<|>|\n|(|)|'|"|;|:|,|%28|%29',line)
#print "token:"
#print tokens
myDat.append(tokens)
f.close()
L, suppData = apriori(myDat, 0.15)
rules = generateRules(L, suppData, minConf=0.6)
#print 'rules:n', rules# -*- coding:utf-8 -*-
import sys
import urllib
import urlparse
import re
from hmmlearn import hmm
import numpy as np
from sklearn.externals import joblib
import HTMLParser
import nltk
#处理参数值的最小长度
MIN_LEN=6
#状态个数
N=10
#最大似然概率阈值
T=-200
#字母
#数字 1
#<>,:"'
#其他字符2
SEN=['<','>',',',':',''','/',';','"','{','}','(',')']
def ischeck(str):
if re.match(r'^(http)',str):
return False
for i, c in enumerate(str):
if ord(c) > 127 or ord(c) < 31:
return False
if c in SEN:
return True
#排除中文干扰 只处理127以内的字符
return False
#数据处理与特征提取
def etl(str):
vers=[]
for i, c in enumerate(str):
c=c.lower()
if ord(c) >= ord('a') and ord(c) <= ord('z'):
vers.append([ord(c)])
elif ord(c) >= ord('0') and ord(c) <= ord('9'):
vers.append([1])
elif c in SEN:
vers.append([ord(c)])
else:
vers.append([2])
#print vers
return np.array(vers)
def do_str(line):
words=nltk.word_tokenize(line)
print words
#从Weblog中提取url参数需要解决编码、参数提取等问题,问题得以解决是因为Python的接口。
def main(filename):
X = [[0]]
X_lens = [1]
with open(filename) as f:
for line in f:
line=line.strip('n')
#url解码
line=urllib.unquote(line)
#处理html转义字符
h = HTMLParser.HTMLParser()
line=h.unescape(line)
if len(line) >= MIN_LEN:
print "Learning xss query param:(%s)" % line
do_str(line)
def test(remodel,filename):
with open(filename) as f:
for line in f:
# 切割参数
result = urlparse.urlparse(line)
# url解码。parse_qsl切割参数遇到中文分号会截断,一定注意!!!
query = urllib.unquote(result.query)
params = urlparse.parse_qsl(query, True)
for k, v in params:
if ischeck(v) and len(v) >=N :
vers = etl(v)
pro = remodel.score(vers)
#print "CHK SCORE:(%d) QUREY_PARAM:(%s) XSS_URL:(%s) " % (pro, v, line)
if pro >= T:
print "SCORE:(%d) QUREY_PARAM:(%s) XSS_URL:(%s) " % (pro,v,line)
#print line
if __name__ == '__main__':
nltk.download()
main(sys.argv[1])
以黑查黑:
# -*- coding:utf-8 -*-
import sys
import urllib
import urlparse
import re
from hmmlearn import hmm
import numpy as np
from sklearn.externals import joblib
import HTMLParser
import nltk
#处理参数值的最小长度
MIN_LEN=10
#状态个数
N=5
#最大似然概率阈值
T=-200
#字母
#数字 1
#<>,:"'
#其他字符2
SEN=['<','>',',',':',''','/',';','"','{','}','(',')']
index_wordbag=1 #词袋索引
wordbag={} #词袋
tokens_pattern = r'''(?x)
"[^"]+"
|http://S+
|</w+>
|<w+>
|<w+
|w+=
|>
|w+([^<]+) #函数 比如alert(String.fromCharCode(88,83,83))
|w+
'''
def ischeck(str):
if re.match(r'^(http)',str):
return False
for i, c in enumerate(str):
if ord(c) > 127 or ord(c) < 31:
return False
if c in SEN:
return True
#排除中文干扰 只处理127以内的字符
return False
def do_str(line):
words=nltk.regexp_tokenize(line, tokens_pattern)
#print words
return words
def load_wordbag(filename,max=100):
X = [[0]]
X_lens = [1]
tokens_list=[]
global wordbag
global index_wordbag
with open(filename) as f:
for line in f:
line=line.strip('n')
#url解码
line=urllib.unquote(line)
#处理html转义字符
h = HTMLParser.HTMLParser()
line=h.unescape(line)
if len(line) >= MIN_LEN:
#print "Learning xss query param:(%s)" % line
#数字常量替换成8
line, number = re.subn(r'd+', "8", line)
#ulr日换成http://u
line, number = re.subn(r'(http|https)://[a-zA-Z0-9.@&/#!#?:=]+', "http://u", line)
#干掉注释
line, number = re.subn(r'/*.?*/', "", line)
#print "Learning xss query etl param:(%s) " % line
tokens_list+=do_str(line)
#X=np.concatenate( [X,vers])
#X_lens.append(len(vers))
fredist = nltk.FreqDist(tokens_list) # 单文件词频
keys=fredist.keys()
keys=keys[:max]
for localkey in keys: # 获取统计后的不重复词集
if localkey in wordbag.keys(): # 判断该词是否已在词袋中
continue
else:
wordbag[localkey] = index_wordbag
index_wordbag += 1
print "GET wordbag size(%d)" % index_wordbag
def main(filename):
X = [[-1]]
X_lens = [1]
global wordbag
global index_wordbag
with open(filename) as f:
for line in f:
line=line.strip('n')
#url解码
line=urllib.unquote(line)
#处理html转义字符
h = HTMLParser.HTMLParser()
line=h.unescape(line)
if len(line) >= MIN_LEN:
#print "Learning xss query param:(%s)" % line
#数字常量替换成8
line, number = re.subn(r'd+', "8", line)
#ulr日换成http://u
line, number = re.subn(r'(http|https)://[a-zA-Z0-9.@&/#!#?:]+', "http://u", line)
#干掉注释
line, number = re.subn(r'/*.?*/', "", line)
#print "Learning xss query etl param:(%s) " % line
words=do_str(line)
vers=[]
for word in words:
#print "ADD %s" % word
if word in wordbag.keys():
vers.append([wordbag[word]])
else:
vers.append([-1])
np_vers = np.array(vers)
#print np_vers
X=np.concatenate([X,np_vers])
X_lens.append(len(np_vers))
#print X_lens
remodel = hmm.GaussianHMM(n_components=N, covariance_type="full", n_iter=100)
remodel.fit(X,X_lens)
joblib.dump(remodel, "xss-train.pkl")
return remodel
def test(remodel,filename):
with open(filename) as f:
for line in f:
line = line.strip('n')
# url解码
line = urllib.unquote(line)
# 处理html转义字符
h = HTMLParser.HTMLParser()
line = h.unescape(line)
if len(line) >= MIN_LEN:
#print "CHK XSS_URL:(%s) " % (line)
# 数字常量替换成8
line, number = re.subn(r'd+', "8", line)
# ulr日换成http://u
line, number = re.subn(r'(http|https)://[a-zA-Z0-9.@&/#!#?:]+', "http://u", line)
# 干掉注释
line, number = re.subn(r'/*.?*/', "", line)
# print "Learning xss query etl param:(%s) " % line
words = do_str(line)
#print "GET Tokens (%s)" % words
vers = []
for word in words:
# print "ADD %s" % word
if word in wordbag.keys():
vers.append([wordbag[word]])
else:
vers.append([-1])
np_vers = np.array(vers)
#print np_vers
#print "CHK SCORE:(%d) QUREY_PARAM:(%s) XSS_URL:(%s) " % (pro, v, line)
pro = remodel.score(np_vers)
if pro >= T:
print "SCORE:(%d) XSS_URL:(%s) " % (pro,line)
#print line
def test_normal(remodel,filename):
with open(filename) as f:
for line in f:
# 切割参数
result = urlparse.urlparse(line)
# url解码
query = urllib.unquote(result.query)
params = urlparse.parse_qsl(query, True)
for k, v in params:
v=v.strip('n')
#print "CHECK v:%s LINE:%s " % (v, line)
if len(v) >= MIN_LEN:
# print "CHK XSS_URL:(%s) " % (line)
# 数字常量替换成8
v, number = re.subn(r'd+', "8", v)
# ulr日换成http://u
v, number = re.subn(r'(http|https)://[a-zA-Z0-9.@&/#!#?:]+', "http://u", v)
# 干掉注释
v, number = re.subn(r'/*.?*/', "", v)
# print "Learning xss query etl param:(%s) " % line
words = do_str(v)
# print "GET Tokens (%s)" % words
vers = []
for word in words:
# print "ADD %s" % word
if word in wordbag.keys():
vers.append([wordbag[word]])
else:
vers.append([-1])
np_vers = np.array(vers)
# print np_vers
# print "CHK SCORE:(%d) QUREY_PARAM:(%s) XSS_URL:(%s) " % (pro, v, line)
pro = remodel.score(np_vers)
print "CHK SCORE:(%d) QUREY_PARAM:(%s)" % (pro, v)
#if pro >= T:
#print "SCORE:(%d) XSS_URL:(%s) " % (pro, v)
#print line
if __name__ == '__main__':
#test(remodel,sys.argv[2])
load_wordbag(sys.argv[1],2000)
#print wordbag.keys()
remodel = main(sys.argv[1])
#test_normal(remodel, sys.argv[2])
test(remodel, sys.argv[2])
2.用隐式马尔可夫模型识别DGA域名
需要对域名特征进行提取,转为ASCII码后进行训练即可。
# -*- coding:utf-8 -*-
import sys
import urllib
import urlparse
import re
from hmmlearn import hmm
import numpy as np
from sklearn.externals import joblib
import HTMLParser
import nltk
import csv
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
#处理域名的最小长度
MIN_LEN=10
#状态个数
N=8
#最大似然概率阈值
T=-50
#模型文件名
FILE_MODEL="12-4.m"
#加载域名数据代码
def load_alexa(filename):
domain_list=[]
csv_reader = csv.reader(open(filename))
for row in csv_reader:
domain=row[1]
if domain >= MIN_LEN:
domain_list.append(domain)
return domain_list
#特征化逻辑就是直接转化为对应的ASCII码
def domain2ver(domain):
ver=[]
for i in range(0,len(domain)):
ver.append([ord(domain[i])])
return ver
#使用默认参数的HMM来训练
def train_hmm(domain_list):
X = [[0]]
X_lens = [1]
for domain in domain_list:
ver=domain2ver(domain)
np_ver = np.array(ver)
X=np.concatenate([X,np_ver])
X_lens.append(len(np_ver))
remodel = hmm.GaussianHMM(n_components=N, covariance_type="full", n_iter=100)
remodel.fit(X,X_lens)
joblib.dump(remodel, FILE_MODEL)
return remodel
#加载DGA数据代码
def load_dga(filename):
domain_list=[]
#xsxqeadsbgvpdke.co.uk,Domain used by Cryptolocker - Flashback DGA for 13 Apr 2017,2017-04-13,
# http://osint.bambenekconsulting.com/manual/cl.txt
with open(filename) as f:
for line in f:
domain=line.split(",")[0]
if domain >= MIN_LEN:
domain_list.append(domain)
return domain_list
def test_dga(remodel,filename):
x=[]
y=[]
dga_cryptolocke_list = load_dga(filename)
for domain in dga_cryptolocke_list:
domain_ver=domain2ver(domain)
np_ver = np.array(domain_ver)
pro = remodel.score(np_ver)
#print "SCORE:(%d) DOMAIN:(%s) " % (pro, domain)
x.append(len(domain))
y.append(pro)
return x,y
def test_alexa(remodel,filename):
x=[]
y=[]
alexa_list = load_alexa(filename)
for domain in alexa_list:
domain_ver=domain2ver(domain)
np_ver = np.array(domain_ver)
pro = remodel.score(np_ver)
#print "SCORE:(%d) DOMAIN:(%s) " % (pro, domain)
x.append(len(domain))
y.append(pro)
return x, y
if __name__ == '__main__':
#domain_list=load_alexa("../data/top-1m.csv")
domain_list = load_alexa("/Users/zhanglipeng/Data/top-1000.csv")
#remodel=train_hmm(domain_list)
remodel=joblib.load(FILE_MODEL)
x_3,y_3=test_dga(remodel, "/Users/zhanglipeng/Data/dga-post-tovar-goz-1000.txt")
x_2,y_2=test_dga(remodel,"/Users/zhanglipeng/Data/dga-cryptolocke-1000.txt")
x_1,y_1=test_alexa(remodel, "/Users/zhanglipeng/Data/test-top-1000.csv")
#test_alexa(remodel, "../data/top-1000.csv")
#%matplotlib inline
fig,ax=plt.subplots()
ax.set_xlabel('Domain Length')
ax.set_ylabel('HMM Score')
ax.scatter(x_3,y_3,color='b',label="dga_post-tovar-goz")
ax.scatter(x_2, y_2, color='g', label="dga_cryptolock")
#ax.scatter(x_1, y_1, color='r', label="alexa")
ax.legend(loc='right')
plt.show()
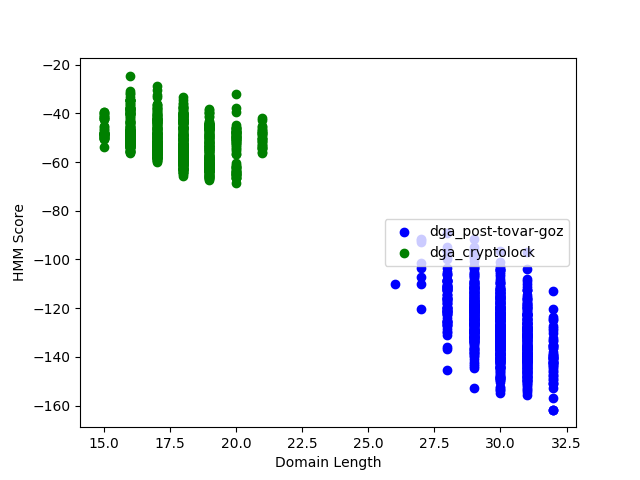
最后
以上就是听话小刺猬最近收集整理的关于隐式马尔可夫算法挖掘时序数据的全部内容,更多相关隐式马尔可夫算法挖掘时序数据内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复