Hive数据分析... 4
一、数据处理.... 4
1.1处理不符合规范的数据。... 4
1.2访问时间分段。... 5
二、基本统计信息.... 6
三、数据属性基础分析.... 6
3.1用户ID分析... 6
3.1.1UID的查询次数。... 6
3.1.2UID频度排名分析。... 7
3.2搜索关键词分析... 8
3.2.1热词分析... 8
3.2.2使用几个单词还是一个句子作为关键词。... 9
3.2.3使用文字描述还是域名一部分作为关键词。... 10
3.3URL分析... 10
3.3.1热门搜索分析。... 10
3.3.2URL流量分析。... 11
3.4 Rank分析... 12
3.5 Order分析... 13
3.6访问时间分析... 14
四、数据深入特色分析.... 15
4.1.某一用户分析... 15
4.1.1该UID背后是否是爬虫程序?. 15
4.1.2该UID背后是浏览器代理程序吗?... 16
4.2.某一网站分析... 18
4.2.1关键字分析... 18
4.2.2访问量与时间... 19
KMeans算法的MapReduce实现... 20
一、制定距离衡量标准.... 20
1.1曼哈顿距离衡量时间、Order、Rank之间的距离。... 20
1.2莱文斯坦距离衡量关键字之间的距离。... 21
1.3三种距离的计算。... 22
1.3.1两个记录之间的距离。... 22
1.3.2一条记录与类簇中心点集合的距离。... 22
1.3.3新类簇中心点集合与旧类簇中心点之间的距离。... 22
二、设计定制的Writeable集合与实现功能函数.... 23
2.1定制的Writable集合:dataCell类... 23
2.1.1构造函数:dataCell()、dataCell(String time, String uid, String keyword, int rank, int order, String url)。... 23
2.1.2序列化与反序列化:write(DataOutput out)、readFields(DataInput in)。... 23
2.1.3比较大小:compareTo(dataCell o) 23
2.2功能函数。... 24
2.2.1从一组元素中计算一个类簇中心:caculateCenter(List<List<Object>> A) 24
2.2.2从文件中获取所有类簇中心集合:getCenters(String inputpath) 24
2.2.3从Hdfs获取程序迭代类簇中心结果及分类结果到本地:getCenterResult( String localPath)、getClassfiyResult( String localPath) 24
2.2.4使用新类簇中心集合替换旧类簇中心集合:replaceOldCenter(String oldpath, String newpath) 25
2.2.5判断新旧两组类簇中心的距离是否已经达到迭代停止条件:isFinished(String oldpath, String newpath, int max) 25
三、生成初始类簇中心点.... 26
四、第一次MapReduce:迭代聚类中心点.... 27
4.1MapReduce设计。... 27
4.2 Mapper实现。... 27
4.3 Reducer实现。... 28
4.4 JobDriver实现。... 29
五、第二次MapReduce:数据分类.... 29
5.1 MapReduce设计。... 29
5.2 Mapper实现。... 30
5.3 Recuce实现。... 30
5.4 JobDriver实现。... 31
六、衡量分类效果.... 31
七、运行与分析.... 32
7.1 一次完整的程序运行... 32
7.1.1产生初始聚类中心。... 32
7.1.2迭代聚类中心。... 33
7.1.3数据分类。... 34
7.1.4衡量分类效果。... 34
7.2 寻找最佳类簇个数
Mapreduce附录.... 44
(1) dataCell类... 44
(2) Help类... 47
(3) HelpTest 55
(4) KMeansDriver 56
(5) KmeansMapperForCenter类... 59
(6) KMeansReducerForCenter类... 60
(7) KMeansMapperForClassify类... 61
(8) KMeansReducerForClassify类 62KMeans算法的MapReduce实现
在本文中我使用KMeans算法实现搜狗搜索数据集上的MapReduce程序。K-Means算法输入聚类个数k,以及源数据,并将源数据分为k类输出。在分类后的数据中,同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。众所周知,KMeans算法在初始中心点选取及聚类个数方面存在一定不足,在本文中我将在实现算法之余对于这两点尝试做出一些改进。此外,想要顺利的实现算法清晰的思路必不可少,在程序实现方面,我将按照制定距离衡量标准、生成初始聚类中心、迭代聚类中心、数据分类、衡量分类效果的步骤进行,最后还将对使用不同个数聚类中心,程序所展示出的效果进行分析。
一、制定距离衡量标准
搜狗数据集每行一条记录,每条记录由六个属性构成:时间、用户ID、搜索关键字、Order、Rank和URL。因为数据集没有分类标志,所以不能使用有监督算法对其进行分类,只能使用无监督算法。在六个属性中,用户ID是一串浏览器生成的字符,并不能衡量两个ID之间的距离,所以这里我们不将其考虑到算法中;URL的命名规则很随意,也很难衡量两个URL之间的距离,则算法中也不考虑URL属性。除此之外,我们将在算法中,依据时间、搜索关键字、Order、Rank对数据之间的距离进行衡量,并分类。
时间、搜索关键字、Order、Rank这四个属性拥有不同的特征,其中时间、Order、Rank是整数,可以执行数字运算;而搜索关键字是字符串无法执行数字运算,从而这两类属性需要使用不同的方法衡量距离。这里我们使用曼哈顿距离衡量时间、Order、Rank之间的距离,使用莱文斯坦距离衡量搜索关键字之间的距离:
1.1曼哈顿距离衡量时间、Order、Rank之间的距离。
在数据集中,时间是连续变化的其范围是:2011年12月30日至2011年12月31日,数据格式为“20111230000005”,其中第7,8位数字表示小时,为了不使计算过于麻烦,我们以小时(即时间属性字符串的7和8位数字)作为该条数据时间属性的值,每天有24个小时,这里我们对其进行归一化,设at为记录A的时间属性值,bt为记录B的时间属性值,则记录A与记录B之间时间属性的距离如公式(1)所示:
Dt=abs(at-bt)/24 公式(1)
Order是该条记录在网页展示时的排序,这是较为重要的一个属性。在数据集中Order值的范围在1~40之间,设ao为记录A的Order数值,bo为记录B的Order数值,则记录A与记录B之间的Order属性的的距离如公式(2)所示:
Do=abs(ao-bo) 公式(2)
Rank记录用户点击的次序,也是一个很重要的属性。这里设ar为记录A的Rank值,br为记录B的Rank至,则记录A与记录B之间的Order属性的距离如公式(3)所示:
Dr=abs(ar-br) 公式(3)
1.2莱文斯坦距离衡量关键字之间的距离。
本数据集中的记录中的搜索关键字属性是用户在使用搜狗浏览器输入的搜索内容,因其是文本,不能使用简单的算术运算衡量其距离,所以这里选择编辑距离——莱文斯坦距离衡量两个关键字之间的距离。在信息论和计算机科学中,莱文斯坦距离是一种两个字符串序列的距离度量。形式化地说,两个单词的莱文斯坦距离是一个单词变成另一个单词要求的最少单个字符编辑数量(如:删除、插入和替换)。莱文斯坦距离也被称做编辑距离,尽管它只是编辑距离的一种,与成对字符串比对紧密相关。其定义为,两个字符串a,b的莱文斯坦距离记为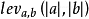 ,其计算公式为公式(11):
,其计算公式为公式(11):
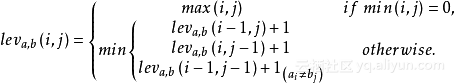 公式(11)
公式(11)
这里, ![]()  åÂ
 å ![]()  åå«è¡¨ç¤ºå符串aåbçé¿åº¦ï¼Â
 åå«è¡¨ç¤ºå符串aåbçé¿åº¦ï¼Â ![]()  æ¯å½Â
 æ¯å½Â ![]()  æ¶å¼ä¸º1ï¼å¦åå¼ä¸º0ç示æ§å½æ°ãè¿æ ·ï¼
 æ¶å¼ä¸º1ï¼å¦åå¼ä¸º0ç示æ§å½æ°ãè¿æ ·ï¼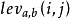 是 a的前 i个字符和b的前 j 个字符之间的距离。
是 a的前 i个字符和b的前 j 个字符之间的距离。
这里我们采用向量存储的方式实现莱文斯坦距离的计算,使用函levenshteinTwoRows(String string1, int s_len, String string2, int t_len) 来实现,该函数的执行过程如流程图1所示,具体实现代码见代码(1)。设ak为记录A的关键字,设bk为记录B的关键字,则记录A与记录B之间的Keyword属性的距离如公式(4)所示:
Dk=levenshteinTwoRows(ak,len(ak),bk,len(bk)) 公式(4)
1.3三种距离的计算。
综上所述,数据集中任意两条记录:记录A与记录B之间的距离可以使用公式(5)来计算。结合程序需求,我们需要计算三种情况的距离:1两个记å½ä¹é´çè·ç¦»ï¼2ä¸æ¡è®°å½ä¸ç±»ç°ä¸å¿ç¹éåçè·ç¦»ï¼3新类簇中心点集合与旧类簇中心点之间的距离。
D=Dt+Do+Dr+Dk 公式(5)
1.3.1两个记录之间的距离。
该功能使用函数caculateDistance0(List<Object> A,List<Object> B)实现,其实现逻辑为:程序使用公式(5)计算两个参数的距离,并返回该距离。函数的实现代码见附录Help类,函数的测试函数为caculateDistance0Test(),代码内容见附录HelpTest类。
1.3.2一条记录与类簇中心点集合的距离。
该功能使用函数caculateDistance1(List<Object> A,List< List<Object>> B)实现,其实现逻辑为:程序依次读取B中的元素,并使用公式(5)计算该元素与A的距离,记录每次的距离,最终返回最小距离所对应的元素。函数的实现代码见附录Help类,函数的测试函数为caculateDistance1Test(),代码内容见附录HelpTest类。
1.3.3新类簇中心点集合与旧类簇中心点之间的距离。
该功能使用函数caculateDistance2(List< List<Object>> A,List< List<Object>> B),其实现逻辑为:程序依次读取A的第K个元素与B的第K个元素(其中K∈(0,len(A))),并使用公式(5)计算距离,将每次得到的距离累加得到D,返回D/len(A)。
二、设计定制的Writeable集合与实现功能函数
2.1定制的Writable集合:dataCell类
Hadoop有一套非常有用的Writable实现可以满足大部分需求,但是在本文的情况下,我们需要设计构造一个新的实现,从而完全控制二进制的表示和排序顺序,这将有助于后续的MapReduce算法实现。
我们使用类dataCell实现对于一条记录的存储与表示。每条记录有六个字段,则dataCell需为这六个字段创建对应的属性,分别是: String time;String uid;String keyword;int rank;int order;String url。此外,我们为其这些属性提供getter和setter方法。为了让dataCell类能够用于MapReduce过程的数据传输中,我们需要让dataCell类可序列化、可比较大小,这里我们通过让类dataCell实现接口WritableComparable<dataCell>实现这些功能。dataCell的代码实现见附录dataCell类。
2.1.1构造函数:dataCell()、dataCell(String time, String uid, String keyword, int rank, int order, String url)。
在dataCell类中我们提供两个构造函数,其中无参构造函数用于反序列化时的反射;拥有六个参数的构造函数用于实例化一个dataCell对象,函数体内六个形参依次对类的六个属性赋值。
2.1.2序列化与反序列化:write(DataOutput out)、readFields(DataInput in)。
本类中序列化与反序列化的功能通过实现函数write与readFields实现。write函数实现序列化,本函数将六个属性依次写入输出流out,这里要注意的是写出String类型的属性时需要使用写出UTF的形式。readFields函数实现反序列化,该函数对应于write写出属性的格式与顺序将属性从输入流in中读取出来。
2.1.3比较大小:compareTo(dataCell o)
MapReduce的suffer过程中需要将输出的键值对进行排序,所以dataCell有必要实现比较大小的功能。这里我们将参数列表传入的参数o与类属性通过上文所提到函数caculateDistance0进行比较(注:这里不取绝对值),若结果大于0,返回1;结果小于0,返回-1。
2.2功能函数。
为了让MapReduce程序结构更清晰,让程序的可用性更高,这里我们将一些复杂的逻辑函提取出来放到Help类中,具体实现代码见附录Help类,对应测试代码见附录HelpTest类。
2.2.1从一组元素中计算一个类簇中心:caculateCenter(List<List<Object>> A)
本函数适用于迭代类簇的Reduce程序中。函数接收一组记录,首先遍历记录计算出这组记录的平均值,然后再次遍历记录从记录中找到与平均值距离最近的那条记录,作为新的类簇中心返回。这里要注意的是:不能直接返回这组记录的平均值作为新的类簇中心,否则会造成类簇中心集合元素缺失的问题。
2.2.2从文件中获取所有类簇中心集合:getCenters(String inputpath)
该函数的主要逻辑为从参数列表中获的类簇中心集合的路径,然后通过HDFS的API接口逐行读取类簇中心文件,并将每行数据封装成为一个List<Object>,最后返回类簇中心列表List< List<Object>>。
2.2.3从Hdfs获取程序迭代类簇中心结果及分类结果到本地:getCenterResult( String localPath)、getClassfiyResult( String localPath)
MapReduce程序执行完毕后会在输出目录下产生运行结果,getCenterResult与getClassfiyResult分别将类簇中心结果与分类结果拷贝到本地。这两个函数逻辑大致相同,使用HDFS的API接口从集群上取得对应的文件,然后将该文件放入参数localPath路径中。
2.2.4使用新类簇中心集合替换旧类簇中心集合:replaceOldCenter(String oldpath, String newpath)
由于HDFS的API中并没有提供集群中移动文件的方法,在这里我们通过首先将新类簇中心文件下载到本地文件,然后再旧类簇中心文件删除,最后再将本地文件上传到旧类簇中心文件中的方法实现该功能。参数oldpath为旧类簇中心文件的路径,newpath的新类簇中心文件的路径,该函数由isFinished函数调用。
2.2.5判断新旧两组类簇中心的距离是否已经达到迭代停止条件:isFinished(String oldpath, String newpath, int max)
该函数首先使用函数getCenters()分别从参数oldpath和参数newpath所对应的路径中获取旧类簇中心集合与新类簇中心集合,然后使用函数caculateDistance2()计算两组类簇的距离,如果距离小于max,则满足停止迭代条件,返回false;若距离大于max,则不满足迭代条件,使用函数replaceOldCenter将旧类簇中心文件替换为新类簇中心文件,返回true。使用流程图表示如图1所示
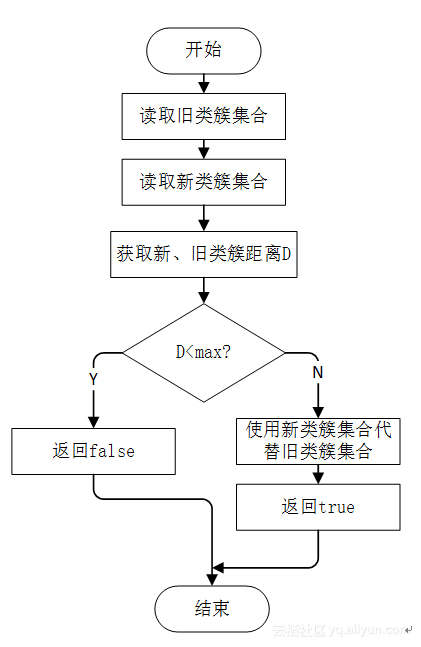
图1 isFinished函数流程图
三、生成初始类簇中心点
初始聚类中心的选择对于KMeans算法来说十分重要,初始类簇中心的好坏直接影响到聚类的效果。这里我使用“选择批次距离尽可能远的K个点”的方法,具体操作步骤为,首先随机选择一个点作为作为初始类簇中心点,然后选择距离该店最远的那个点作为第二个初始聚类中心点,然后再选择距离前两个点的最近距离最大的点作为第三个初始类簇的中心点,以此类推,直至选择出K个初始类簇中心点。
基于以上思想,在程序中实现该算法时,可以按照图1中流程执行。该算法使用函数ProdeceCenter(String inputpath,int k,int initRank,int initOrder)实现,其中参数inputpath为源数据的路径,k为要生成的初始类簇集合元素的个数,initRank为随机生成的初始类簇中心。函数的实现代码见附录Help类。
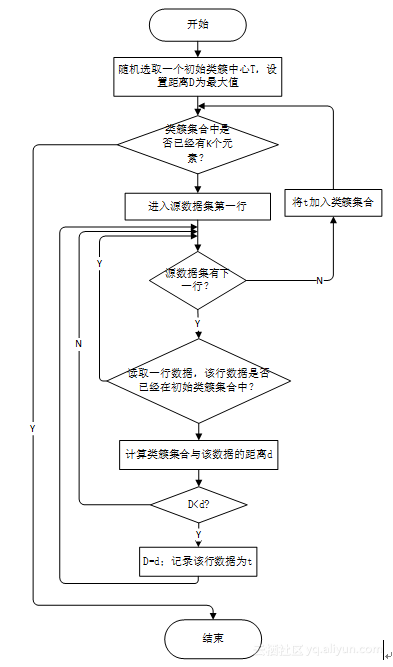
图1 生成初始类簇中心点
四、第一次MapReduce:迭代聚类中心点
在KMean算法中,迭代聚类中心是使用初始类簇作为集合做初始分类,然后再每个分类中寻找中心点作为新的类簇中心点,如此迭代,直到迭代次数足够多或者新旧两组类簇的类簇距离足够小。下面,将按照MapReduce设计、Mapper实现、Reducer实现、JobDriver实现三部分进行阐述。
4.1MapReduce设计。
该部分的MapReduce读取源数据,读取初始类簇集合,产生聚类中心集合。Map部分逐行读入搜狗搜索数据,并找到类簇集合中距离该行数据最近的类簇,然后将最近的类簇的序号作为这一行数据的标签,最终将标签作为Key,改行数据作为Value作为数据写出;Reduce部分负责接收Map产生的数据,并在标签相同的数据中找到中心点,将中心点作为新的类簇输出;JobDriver部分负责一些配置工作,并负责计算新旧两组类簇集合的距离、统计迭代的次数,其中类簇集合的距离与迭代的次数均可以控制整个MapReduce过程的停止。其中,Map部分与Reduce部分的输入输出格式如表1所示。
表1 Map与Reduce的输入输出格式
|
| 输入 | 输出 |
| Map | (字节偏移量,一行数据内容) | (类簇中心标志,一行数据内容) |
| Reduce | (类簇中心标志,多行数据内容) | (NULLWriteable,新的类簇中心) |
4.2 Mapper实现。
本文中我们使用类KmeansMapperForCenter实现迭代聚类中心的Mapper,该类的实现代码见附录KmeansMapperForCenter类。该类继承Mapper<LongWritable,Text,IntWritable,Text>类,并实现了Mapper类的抽象方法map。在map函数中实现了Mapper部分的主要逻辑,其流程如图1所示。
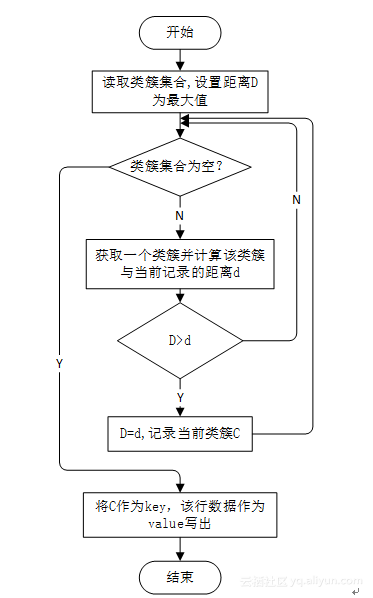
图1 map函数流程图
4.3 Reducer实现。
本文中我们使用类KMeansReducerForCenter实现迭代聚类中心的Reducer,该类的实现代码见附录KMeansReducerForCenter类。该类继承Reducer<IntWritable, Text, NullWritable, Text>类,并实现了Reducer类的抽象方法reduce。在reduce函数中实现了Reducer部分的主要逻辑,其流程如图2所示。
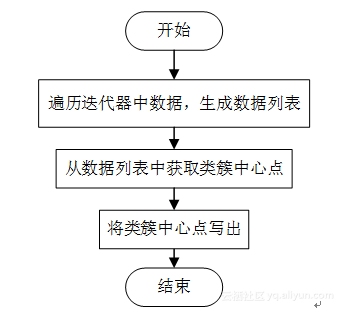
图2 reduce函数流程图
4.4 JobDriver实现。
JobDriver部分驱动MapReduce的执行,这里我们在类KMeansDriver中的getCenter()函数中实现该功能。getCenter()需要为MapReduce流程设置六个变量:输入路径、输出路径、旧类簇中心文件、新类簇中心内文件、类簇个数、聚类停止条件,并且该函数还设置了Map过程使用类,Reduce过程使用类等。我们在这个函数中控制迭代类簇中心的迭代次数,该函数的流程如图1所示,实现代码见附录KMeansDriver类。
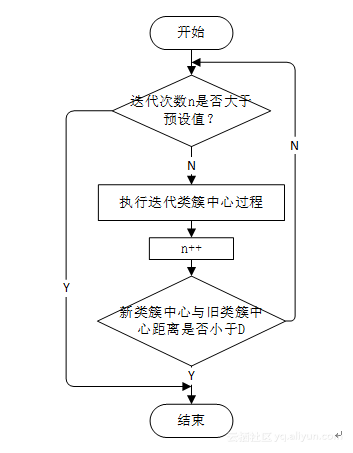
图2 getCenter()函数流程图
五、第二次MapReduce:数据分类
在KMeans算法中,数据分类一部分比较简单,该部分为每一个源数据中的元素在类簇中心集合中寻找一个距离最近的类簇中心,并将该元素标记为该类簇中心类即可。下面,将按照MapReduce设计、Mapper实现、Reducer实现、JobDriver实现三部分进行阐述。
5.1 MapReduce设计。
该部分的MapReduce读取源数据,读取初始类簇中心集合,给每个源数据中元素分类并输出。Map部分负责逐行读入搜狗搜索数据,并找到类簇中心集合中距离该行数据最近的类簇中心,然后将最近的类簇中心的序号作为这一行数据的标签,最终将标签作为Key,改行数据作为Value作为数据写出;Reduce部分负责将Map传输过来的数据逐行输出到结果集中;JobDriver部分负责程序的配置工作,以及提交任务。其中,Map部分与Reduce部分的输入输出格式如表2所示。
表2 Map与Reduce的输入输出格式
|
| 输入 | 输出 |
| Map | (字节偏移量,一行数据内容) | (类簇中心标志,一行数据内容) |
| Reduce | (类簇中心标志,多行数据内容) | n(类簇中心标志,一行数据内容) |
5.2 Mapper实现。
本文中我们使用类KMeansMapperForClassify实现迭代聚类中心的Mapper,该类的实现代码见附录KMeansMapperForClassify类。该类继承Mapper<LongWritable,Text,IntWritable,dataCell>类,并实现了Mapper类的抽象方法map。在map函数中实现了Mapper部分的主要逻辑,其流程如图1所示。
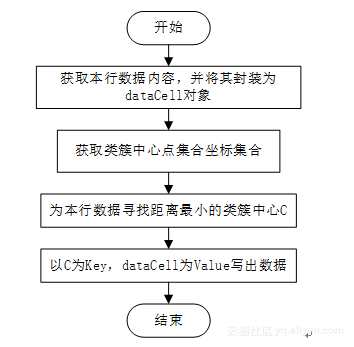
图1 map函数流程图
5.3 Recuce实现。
本文中我们使用类KMeansReducerForCenter实现迭代聚类中心的Reducer,该类的实现代码见附录KMeansReducerForCenter类。该类继承Reducer<IntWritable, Text, NullWritable, Text>类,并实现了Reducer类的抽象方法reduce。在reduce函数中实现了Reducer部分的主要逻辑,该部分比较简单,直接将迭代器中的dataCell对象写出到文件中即可。
5.4 JobDriver实现。
JobDriver部分驱动MapReduce的执行,这里我们在类KMeansDriver中的forClssify()函数中实现该功能。forClssify()需要为MapReduce流程设置四个变量:输入路径、输出路径、类簇中心文件、类簇个数,并且该函数还设置了Map过程使用类,Reduce过程使用类等。该函数过于简单,只是对Job做了一些简单的配置,在这里不予展示,实现代码见附录KMeansDriver类。
六、衡量分类效果
KMeans算法将数据分为几类,如何度量分类效果是值得考虑的问题。聚类的任务是将目标样本分为若干簇,并且保证每个簇之间样本尽可能接近,并且不同簇的样本距离尽可能远。基于此,聚类的效果好坏又分为两类指标衡量,一类是外部聚类效果,一类是内部聚类效果。这里我们仅使用内部聚类效果来衡量聚类的效果,且由于作业时间太紧,我们仅仅衡量聚类的紧凑度一项指标。
这里我们使用类簇中所有样本到类簇中心距离的累加和作为衡量紧凑度的标准,其中,数据集合相同的情况下,累加和越小,紧凑度越高;累加和越大,紧凑度越低。我们使用函数measureResult(String inputPath ,String centerPath,int k)衡量聚类效果,该函数有三个参数:inputPath为分类后结果数据集的路径,centerPath是迭代后类簇中心点的坐标,k是类簇的个数。程序调用getCenter()函数得到类簇中心点的集合,然后逐行读取inputPath中的数据并计算其与对应类簇中心的距离,并将距离累加,最终打印累加距离的值。该函数的实现代码见附录中Help类,其实现的流程如图1所示。
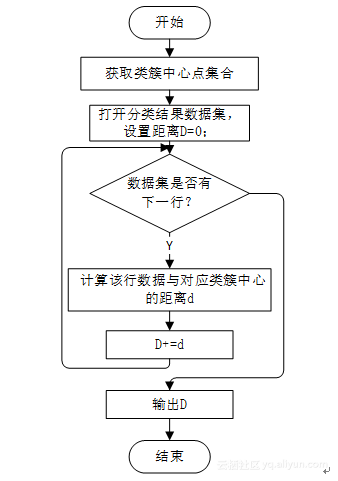
图1 measureResult函数流程图
七、运行与分析
由于电脑配置跟不上,而KMeans算法有需要较多的迭代次数,所以这里我仅使用了10000条数据运行程序。
7.1Â 一次完整的程序运行
在执行程序之前,首先要做一些配置:(1)创建迭代类簇中心点输出文件夹,创建分类结果输出文件夹;(2)将源数据提交到集群上;(3)将代码打包上传到Linux系统上。程序的运行步骤为:产生初始聚类中心、迭代聚类中心、数据分类、衡量分类效果。
7.1.1产生初始聚类中心。
我们首先产生20个不重复的类簇中心,以time=00,Rank=1,Order=1,key=“火影忍者”为随机初始类簇中心,运行函数Help.ProdeceCenter(),可以得到初始类簇中心,这里仅展示前10个,如表1所示。
表1 初始类簇中心
| 时间 | 搜索关键词 | Rank | Order |
| 20111230001328 | 火影忍者 | 2 | 2 |
| 20111230001600 | 蹲墙诱相公 | 10 | 10 |
| 20111230004356 | 家园守卫战罗德港防守攻略 | 1 | 1 |
| 20111230003246 | Gay 性骚扰 图 | 10 | 9 |
| 20111230002353 | 汕头市金平区八年级第一学期数学试卷 | 3 | 1 |
| 20111230000219 | 人体艺术 | 9 | 9 |
| 20111230004156 | 广州渥格服装辅料有限公司 | 1 | 2 |
| 20111230001037 | 快播 中文字幕 主妇42 | 10 | 8 |
| 20111230003830 | WWW、RRMMM、COM | 1 | 9 |
| 20111230001230 | 海南师范大学美术系校园照片 | 10 | 1 |
7.1.2迭代聚类中心。
根据上文产生的初始类簇中心,我们选取前六个初始类簇中心点迭代聚类中心。本此迭代共计六轮,最终迭代后的类簇中心如表2所示,程序运行截图如图1所示。
表2 迭代后的类簇中心
| 时间 | 搜索关键词 | Rank | Order |
| 20111230000249 | 天与地 | 2 | 1 |
| 20111230004246 | HTCG10手机系统自带软件怎么删除? | 1 | 2 |
| 20111230004356 | 家园守卫战罗德港防守攻略 | 1 | 1 |
| 20111230000158 | 北京市西城区2008英语抽样测试答案 | 4 | 1 |
| 20111230002353 | 汕头市金平区八年级第一学期数学试卷 | 3 | 1 |
| 20111230001418 | 环卫工人业务知识竞赛抢答题 | 4 | 2 |
图1 程序运行截图
7.1.3数据分类。
根据以上迭代产生的类簇中心点集合,我们执行数据分类操作,运行函数forClssify(),可以对数据集进行分类,部分分类结果如表1所示。从表1中我们可以看到分类效果还是不错的。
表1 数据分类结果
| 类簇 | 时间 | 用户ID | 关键词 | Rank | Order | URL |
| 0 | 20111230002225 | 5794763849288f418c58789492cd1f2e | 左耳 | 2 | 1 | http://www.tudou.com/programs/view/q96O7olHT-Q/ |
| 0 | 20111230000942 | b54b6c1e8039276b87c8002be3e8583f | 遵义宅 快递电话 | 2 | 2 | http://zhidao.baidu.com/question/235623645 |
| 0 | 20111230001418 | 1b4fc71d2a068a638e66db462a93f89f | 最终幻想 | 2 | 1 | http://www.163dyy.com/detail/1678.html |
| 0 | 20111230003938 | fa936e397a0994997f234681a65549b2 | 最新移动手机充值q币 | 2 | 1 | http://service.qq.com/info/25295.html |
| 1 | 20111230003905 | 3c21686be709b847009680976d6a2b4c | 百度一下 | 1 | 2 | http://www.baidu.com/ |
| 1 | 20111230004234 | 6056710d9eafa569ddc800fe24643051 | 百度一下 | 1 | 2 | http://www.baidu.com/ |
| 1 | 20111230000701 | c71267c05b21e2a8f6a3e6b812fabc1f | 百度ady | 1 | 2 | http://zhidao.baidu.com/question/188644177 |
7.1.4衡量分类效果。
经过以上三个步骤,我们已经基本完成了KMeans算法的基本过程,最后对算法的分类效果进行衡量。运行函数measureResult()可以得到类簇的累加距离,运行结果为10528。该数据需要有多组分类数据时进行比较才有意义,所以接下来我们寻找本数据集的最佳类簇个数。
7.2Â 寻找最佳类簇个数
我们使用产生聚类中心小节中产生的初始聚类中心,分别取前1个、前2个、前3个、前4个、前5个、前6个、前7个初始类簇中心对数据集进行聚类,并最终使用函数measureResult()计算累加距离,结果如表1所示。将表中数据用折线图表示如图1所示,从图中我们可以清楚看到,在类簇个数为3时,图中曲线出现了很大的转折:在类簇个数小于3时,每增加一个类簇,累加距离下降频度很大;在类簇个数大于3时,每增加一个类簇,累加距离下降频度较小。由此,当类簇个数为3时,既可以保证较好的分类效果,又可以避免分类过于细致的麻烦。
表1 1~7个类簇的分类效果
| 类簇个数 | 距离 |
| 1 | 25805 |
| 2 | 17503 |
| 3 | 12348 |
| 4 | 11798 |
| 5 | 11003 |
| 6 | 10528 |
| 7 | 10288 |
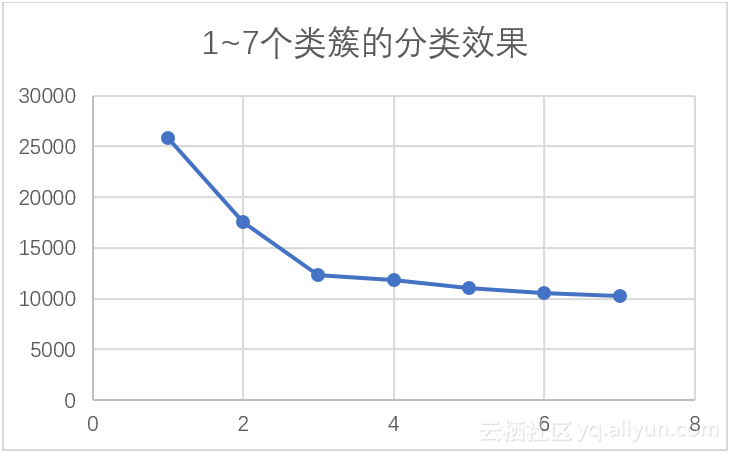
图1 1~7个类簇的分类效果
Mapreduce附录
(1)Â Â Â dataCell类
package myKMeans;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
/**
* 自定义的可以作为MR传输对象的类
* @author zheng
*
*/
public class dataCell implements WritableComparable<dataCell>{
private String time;
private String uid;
private String keyword;
private int rank;
private int order;
private String url;
/**************************get set 方法************************/
public String getTime() {
return time;
}
public void setTime(String time) {
this.time = time;
}
public String getUid() {
return uid;
}
public void setUid(String uid) {
this.uid = uid;
}
public String getKeyword() {
return keyword;
}
public void setKeyword(String keyword) {
this.keyword = keyword;
}
public int getRank() {
return rank;
}
public void setRank(int rank) {
this.rank = rank;
}
public int getOrder() {
return order;
}
public void setOrder(int order) {
this.order = order;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
/*************************构造函数*****************************/
/**
* 构造函数
* @param time
* @param uid
* @param keyword
* @param rank
* @param order
* @param url
*/
public dataCell(String time, String uid, String keyword, int rank, int order, String url) {
super();
this.time = time;
this.uid = uid;
this.keyword = keyword;
this.rank = rank;
this.order = order;
this.url = url;
}
/**
* 无参构造函数
* 空构造函数用于反射 反序列化
*/
public dataCell() {
super();
}
/**********************实现接口函数*****************************/
/**
*
* 反序列化的方法,反序列化是,从流中读取到各个字段的顺序应该与序列化时些出去的顺序保持一致
*/
public void readFields(DataInput in) throws IOException {
// TODO Auto-generated method stub
time=in.readUTF();
uid=in.readUTF();
keyword=in.readUTF();
rank=in.readInt();
order=in.readInt();
url=in.readUTF();
}
/**
* 序列化的方法
*/
public void write(DataOutput out) throws IOException {
// TODO Auto-generated method stub
out.writeUTF(time);
out.writeUTF(uid);
out.writeUTF(keyword);
out.writeInt(rank);
out.writeInt(order);
out.writeUTF(url);
}
/**
* 比较排序
*/
public int compareTo(dataCell o) {
// TODO Auto-generated method stub
//正序排列
if(this.rank>o.rank){
return 1;
}
else if (this.order>o.order){
return 1;
}
else{
return -1;
}
}
/**
* 字符串输出时的方法
*/
public String toString(){
return time+"t"+uid+"t"+keyword+"t"+rank+"t"+order+"t"+url;
}
}
(2)Â Â Â Help类
package myKMeans;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.util.LineReader;
import org.apache.xerces.util.URI;
public class Help {
/**
* 从hdfs文件中获取中心点,返回中心点列表的List
* @param inputpath
* @return
*/
public static ArrayList<ArrayList<Integer>> getCenters(String inputpath) {
// TODO Auto-generated method stub
ArrayList<ArrayList<Integer>> result = new ArrayList<ArrayList<Integer>>();
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.79.111:9000");
try {
FileSystem hdfs = FileSystem.get(conf);
Path in = new Path(inputpath);
FSDataInputStream fsIn = hdfs.open(in);
LineReader lineIn = new LineReader(fsIn, conf);
Text line = new Text();
while (lineIn.readLine(line) > 0){
String record = line.toString();
/**
* 因为Hadoop输出键值对时会在键跟值之间添加制表符, 所以用空格代替之。
*/
String[] fields = record.split("t");
List<Integer> tmplist = new ArrayList<Integer>();
for (int i = 0; i < fields.length; ++i){
tmplist.add(Integer.parseInt(fields[i]));
}
result.add((ArrayList<Integer>) tmplist);
}
fsIn.close();
} catch (IOException e){
e.printStackTrace();
}
return result;
}
/**
* 计算两个点之间的距离,返回两个点的距离
* @param data
* @param arrayList
* @return
*/
public static int caculateDistance0(ArrayList<Integer> data, ArrayList<Integer> arrayList) {
// TODO Auto-generated method stub
//曼哈顿距离
int x1=data.get(0);
int y1=data.get(1);
int x2=arrayList.get(0);
int y2=arrayList.get(1);
int distance=Math.abs(x1-x2)+Math.abs(y1-y2);
return distance;
}
/**
* 计算oldcenter队列与newcenter队列之间的距离,返回old队列中中心点与new队列中对应中心点的距离之和
* @param oldCenter
* @param newCenter
* @param k
* @return
*/
public static int caculateDistance2(List<ArrayList<Integer>> oldCenter,
List<ArrayList<Integer>> newCenter) {
// TODO Auto-generated method stub
//曼哈顿距离
int distance=0;
//System.out.println(oldCenter.size());
//System.out.println(newCenter.size());
for(int i=0;i<oldCenter.size()&&i<newCenter.size();i++){
distance+=Math.abs(oldCenter.get(i).get(0)-newCenter.get(i).get(0))
+Math.abs(oldCenter.get(i).get(1)-newCenter.get(i).get(1));
}
return distance;
}
/**
* 计算一个点与中心点队列的距离,返回该点与队列中所有中心的距离之和
* @param node
* @param centerList
* @return
*/
public static int caculateDistance1( List<Integer> data,
List<ArrayList<Integer>> centerList) {
// TODO Auto-generated method stub
//曼哈顿距离
int distance=0;
for(int i=0;i<centerList.size();i++){
int temp=Integer.MIN_VALUE;
temp=Math.abs(data.get(0)-centerList.get(i).get(0))
+Math.abs(data.get(1)-centerList.get(i).get(1));
if(temp!=0){
distance+=temp;
}
else{
distance=Integer.MIN_VALUE;
return distance;
}
}
return distance;
}
/**
* 计算中心点
* 在一堆node里面找中间的那一个
* @param helpList
* @return
*/
public static Text caculateCenter(List<ArrayList<Integer>> helpList) {
// TODO Auto-generated method stub
float rankTotal=0.0f;
float orderTotal=0.0f;
int totalDistance=Integer.MAX_VALUE;
int rankRusult=Integer.MAX_VALUE;
int orderResult=Integer.MAX_VALUE;
int i=0;
for(ArrayList<Integer> list:helpList){
rankTotal+=list.get(0);
orderTotal+=list.get(1);
i++;
}
System.out.println("$$$$$$$$$$"+i);
int rank=0;
int order=0;
if(i!=0){
rank =Math.round(rankTotal/i);
order=Math.round(orderTotal/i);
for(ArrayList<Integer> list:helpList){
int temp=list.get(0)-rank+list.get(1)-order;
if(temp<totalDistance){
rankRusult=list.get(0);
orderResult=list.get(1);
totalDistance=temp;
}
}
}
//System.out.println(rank);
//System.out.println(order);
Text result=new Text(rankRusult+"t"+orderResult);
System.out.println(rankRusult+"t"+orderResult);
return result;
}
/**
* 判断当前中心点是否已经到达停止条件
* @param oldpath
* @param newpath
* @param k
* @param max
* @return
* @throws IOException
*/
public static boolean isFinished(String oldpath, String newpath, int max) throws IOException {
// TODO Auto-generated method stub
//<oldcenters> <newcenters> <k> <threshold>
//构建oldcenters,newcenters数组
List<ArrayList<Integer>> oldcenters = Help.getCenters(oldpath);
List<ArrayList<Integer>> newcenters = Help.getCenters(newpath);
//计算距离
int distance=Help.caculateDistance2(oldcenters, newcenters);
System.out.println(distance);
if (distance<max){
//停止迭代
System.out.println("false");
return false;
}
else{
//继续迭代
//使用新中心替换旧中心
boolean flag=Help.replaceOldCenter(oldpath,newpath);
System.out.println(flag);
System.out.println("true");
return true;
}
}
/**
* 使用新中心点替代旧的中心点
* @param oldpath
* @param newpath
* @return
* @throws IOException
*/
public static boolean replaceOldCenter(String oldpath, String newpath) throws IOException {
// TODO Auto-generated method stub
ArrayList<ArrayList<Integer>> result = new ArrayList<ArrayList<Integer>>();
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.79.111:9000");
FileSystem fs = FileSystem.get(conf);
Path newFile = new Path(newpath);
Path oldFile=new Path(oldpath);
//Path temp=new Path("/root/testForHelp1.txt");
Path temp=new Path("C:\Users\zheng\Desktop\testForHelp1.txt");
//"/root/testForHelp1.txt"
fs.copyToLocalFile(newFile, temp);
fs.copyFromLocalFile(temp, oldFile);
return true;
}
public static boolean getClassfiyResult( String localPath) throws IOException {
// TODO Auto-generated method stub
ArrayList<ArrayList<Integer>> result = new ArrayList<ArrayList<Integer>>();
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.79.111:9000");
FileSystem fs = FileSystem.get(conf);
Path resultFile = new Path("/outForClassify/part-r-00000");
Path localFile=new Path(localPath);
fs.copyToLocalFile(resultFile, localFile);
System.out.println("successful copy");
return true;
}
public static boolean getCenterResult( String localPath) throws IOException {
// TODO Auto-generated method stub
ArrayList<ArrayList<Integer>> result = new ArrayList<ArrayList<Integer>>();
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.79.111:9000");
FileSystem fs = FileSystem.get(conf);
Path resultFile = new Path("/out/part-r-00000");
Path localFile=new Path(localPath);
fs.copyToLocalFile(resultFile, localFile);
System.out.println("successful copy");
return true;
}
/**
* 产生中心点
* @param inputpath 元数据集
* @param k 要产生几个聚类中心
* @param initRank 初始的rank
* @param initOrder 初始的order
*/
public static void ProdeceCenter(String inputpath,int k,int initRank,int initOrder){
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.79.111:9000");
//保存所有的center点的队列
List<ArrayList<Integer>> centerList=new ArrayList<ArrayList<Integer>>();
//保存最开始的中心点
ArrayList<Integer> firstCenter=new ArrayList<Integer>();
firstCenter.add(initRank);
firstCenter.add(initOrder);
//将最开始的中心点加入队列
centerList.add(firstCenter);
//保存临时最大距离
int maxDistance=0;
//保存待选中心点
ArrayList<Integer> tmpCenter=new ArrayList<Integer>();
for(int i=0;i<k-1;i++){
try {
//打开目标数据文件
FileSystem hdfs = FileSystem.get(conf);
Path in = new Path(inputpath);
FSDataInputStream fsIn = hdfs.open(in);
LineReader lineIn = new LineReader(fsIn, conf);
Text line = new Text();
//对数据文件中的每一行都进行处理
while (lineIn.readLine(line) > 0){
//从取出的记录中拿到Rank Order对,进行比较
String record = line.toString();
String[] fields = record.split("t");
ArrayList<Integer> data = new ArrayList<Integer>();
data.add(Integer.parseInt(fields[3]));
data.add(Integer.parseInt(fields[4]));
//比较list,将距离最远的放在tmpCenter里面
int tmpDistance=Help.caculateDistance1(data, centerList);
if(tmpDistance>maxDistance){
boolean flag=true;
for(ArrayList<Integer> c:centerList){
if(Integer.parseInt(fields[3])==c.get(0)&&Integer.parseInt(fields[4])==c.get(1)){
flag=false;
}
}
if(flag){
tmpCenter=data;
maxDistance=tmpDistance;
}
}
}
centerList.add(tmpCenter);
System.out.println(tmpCenter.get(0)+" "+tmpCenter.get(1));
fsIn.close();
} catch (IOException e){
e.printStackTrace();
}
}
for(ArrayList<Integer> c:centerList){
System.out.print(c.get(0)+" "+c.get(1)+";");
}
}
/**
* 衡量聚类的结果 返回质心距离的累加和,这里使用曼哈顿距离
* @param inputPath 聚类的结果及
* @param centerPth 聚类中心
* @param k 聚类中心的个数
* @return
*/
public static int measureResult(String inputPath ,String centerPth,int k){
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.79.111:9000");
int [] distanceList=new int[k];
try {
//打开目标数据文件
FileSystem hdfs = FileSystem.get(conf);
Path in = new Path(inputPath);
FSDataInputStream fsIn = hdfs.open(in);
LineReader lineIn = new LineReader(fsIn, conf);
Text line = new Text();
//对数据文件中的每一行都进行处理
ArrayList<ArrayList<Integer>> centers =Help.getCenters(centerPth);
while (lineIn.readLine(line) > 0){
String record = line.toString();
String[] fields = record.split("t");
int centerNum=Integer.parseInt(fields[0]);
int rank=Integer.parseInt(fields[4]);
int order=Integer.parseInt(fields[5]);
ArrayList<Integer> data = new ArrayList<Integer>();
data.add(rank);
data.add(order);
distanceList[centerNum]+=Help.caculateDistance0(centers.get(centerNum), data);
}
} catch (IOException e){
e.printStackTrace();
}
int distanceTotal=0;
for(int i=0;i<k;i++){
//System.out.println(distanceList[i]);
distanceTotal+=distanceList[i];
}
System.out.println(distanceTotal);
return distanceTotal;
}
}
(3)Â HelpTest
package myKMeans;
import static org.junit.Assert.*;
import java.io.IOException;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import org.apache.hadoop.io.Text;
import org.junit.Test;
public class Helptest {
@Test
public void getCentersTest() {
String path="/testForHelp.txt" ;
ArrayList<ArrayList<Integer>> result =Help.getCenters(path);
for(ArrayList<Integer> re :result){
System.out.println(re.get(0));
System.out.println(re.get(1));
}
}
@Test
public void caculateDistanceTest(){
ArrayList<Integer> data=new ArrayList<Integer>();
data.add(1);
data.add(2);
ArrayList<Integer> arrayList=new ArrayList<Integer>();
arrayList.add(7);
arrayList.add(2);
int distance=Help.caculateDistance0(data, arrayList);
System.out.println(distance);
}
@Test
public void caculateCenterTest(){
List<ArrayList<Integer>> list=new LinkedList<ArrayList<Integer>>();
ArrayList<Integer> a=new ArrayList<Integer>();
a.add(1);
a.add(2);
ArrayList<Integer> b=new ArrayList<Integer>();
b.add(2);
b.add(3);
ArrayList<Integer> c=new ArrayList<Integer>();
c.add(3);
c.add(4);
list.add(a);
list.add(b);
list.add(c);
Text t=Help.caculateCenter(list);
System.out.println(t.getLength());
}
@Test
public void replaceOldCenterTest() throws IOException{
String oldpath = "/testForHelp.txt";
String newpath = "/out/part-r-00000";
Help.replaceOldCenter(oldpath,newpath); }
@Test
public void caculateDistance1Test(){
List<Integer> data=new ArrayList<Integer>();
List<ArrayList<Integer>> centerList=new ArrayList<ArrayList<Integer>>();
data.add(10);
data.add(6);
ArrayList<Integer> data1=new ArrayList<Integer>();
data1.add(1);
data1.add(1);
ArrayList<Integer> data2=new ArrayList<Integer>();
data2.add(10);
data2.add(10);
centerList.add( data1);
centerList.add( data2);
int a=Help.caculateDistance1(data, centerList);
System.out.println(a);
}
}
(4)Â KMeansDriver
package myKMeans;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class KMeansDriver {
public final static int K=5;
public static void main(String[] args) throws ClassNotFoundException, IOException, InterruptedException{
//Help.ProdeceCenter("/in/ssaa", 20, 1, 1);
//getCenter();
forClssify();
//Help.getClassfiyResult("C:\Users\zheng\Desktop\mapreduce\5M\"+K+"\result\result.txt");
//Help.getCenterResult("C:\Users\zheng\Desktop\mapreduce\5M\"+K+"\result\center.txt");
//Help.measureResult("/outForClassify/part-r-00000", "/out/part-r-00000", K);
}
public static void getCenter() throws IOException, ClassNotFoundException, InterruptedException{
int repeated=0;
String[] otherArgs=new String[]{"/in","/out","/oldCenterSet","/out/part-r-00000",K+"","1"
};
do{
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.79.111:9000");
//String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 6){
System.err.println("Usage: <in> <out> <oldcenters> <newcenters> <k> <threshold>");
System.exit(2);
}
conf.set("centerpath", otherArgs[2]);
conf.set("kpath", otherArgs[4]);
Job job = new Job(conf, "KMeansCluster");
job.setJarByClass(KMeansDriver.class);
Path in = new Path(otherArgs[0]);
Path out = new Path(otherArgs[1]);
FileInputFormat.addInputPath(job, in);
FileSystem fs = FileSystem.get(conf);
if (fs.exists(out)){
fs.delete(out, true);
}
FileOutputFormat.setOutputPath(job, out);
job.setMapperClass(KmeansMapperForCenter.class);
job.setReducerClass(KMeansReducerForCenter.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
job.waitForCompletion(true);
++repeated;
System.out.println("We have repeated " + repeated + " times.");
} while (repeated < 9
&& (Help.isFinished(otherArgs[2], otherArgs[3], Integer.parseInt(otherArgs[5]))));
//&& (Help.isFinished(args[2], args[3], Integer.parseInt(args[4]), Float.parseFloat(args[5])) == false)
}
public static void forClssify() throws IOException, ClassNotFoundException, InterruptedException{
String[] otherArgs=new String[]{"/in","/outForClassify","/oldCenterSet","/out/part-r-00000",K+"","2"
};
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.79.111:9000");
//String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 6){
System.err.println("Usage: <in> <out> <oldcenters> <newcenters> <k> <threshold>");
System.exit(2);
}
conf.set("centerpath", otherArgs[2]);
conf.set("kpath", otherArgs[4]);
Job job = new Job(conf, "KMeansCluster");
job.setJarByClass(KMeansDriver.class);
Path in = new Path(otherArgs[0]);
Path out = new Path(otherArgs[1]);
FileInputFormat.addInputPath(job, in);
FileSystem fs = FileSystem.get(conf);
if (fs.exists(out)){
fs.delete(out, true);
}
FileOutputFormat.setOutputPath(job, out);
job.setMapperClass(KMeansMapperForClassify.class);/
job.setReducerClass(KMeansReducerForClassify.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(dataCell.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(dataCell.class);
job.waitForCompletion(true);
}
}
(5)Â KmeansMapperForCenter类
package myKMeans;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/***
* 未获得中心点的mapper
* @author zheng
*
*/
public class KmeansMapperForCenter extends Mapper<LongWritable,Text,IntWritable,Text>{
public void map(LongWritable key,Text value,Context context)
throws IOException,InterruptedException{
String line =value.toString();
String[] fields=line.split("t");
int rank=Integer.parseInt(fields[3]);
int order=Integer.parseInt(fields[4]);
ArrayList<Integer> data =new ArrayList<Integer>();
data.add(rank);
data.add(order);
//获取中心点列表
List<ArrayList<Integer>> centers = Help.getCenters(context.getConfiguration().get("centerpath"));
//有几个聚类中心
int k = Integer.parseInt(context.getConfiguration().get("kpath"));
//当前数据与中心点的最小距离
int minDist = Integer.MAX_VALUE;
//中心点索引
int centerIndex = k;
//计算样本点到各个中心的距离,并把样本聚类到距离最近的中心点所属的类
for(int i=0;i<k;i++){
int currentDist=0;
currentDist=Help.caculateDistance0(data,centers.get(i));
if(minDist>currentDist){
minDist=currentDist;
centerIndex=i;
}
}
Text centerdata=new Text(rank+"t"+order);
context.write(new IntWritable(centerIndex), centerdata);
}
}
(6) KMeansReducerForCenter类
package myKMeans;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
/**
* 为获得中心点的reducer
* @author zheng
*
*/
public class KMeansReducerForCenter extends Reducer<IntWritable, Text, NullWritable, Text> {
public void reduce(IntWritable key,Iterable<Text> value,Context context)
throws IOException,InterruptedException {
System.out.println("#######################");
List<ArrayList<Integer>> helpList=new LinkedList<ArrayList<Integer>> ();
String tempResult="";
for(Text val:value){
String line =val.toString();
String[] fields=line.split("t");
ArrayList<Integer> tempList=new ArrayList<Integer>();
for( String f:fields){
tempList.add(Integer.parseInt(f));
}
helpList.add(tempList);
}
//计算新的聚类中心
Text result= Help.caculateCenter(helpList);
context.write(NullWritable.get(), result);
}
}
(7) KMeansMapperForClassify类
package myKMeans;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Mapper.Context;
/**
* 为数据集分类的mapper
* @author zheng
*
*/
public class KMeansMapperForClassify extends
Mapper<LongWritable,Text,IntWritable,dataCell>{
public void map(LongWritable key,Text value,Context context)
throws IOException,InterruptedException{
String line =value.toString();
String[] fields=line.split("t");
dataCell cell=new dataCell(fields[0],fields[1],fields[2]
,Integer.parseInt(fields[3]),Integer.parseInt(fields[4]),fields[5]);
int rank=cell.getRank();
int order=cell.getOrder();
ArrayList<Integer> data =new ArrayList<Integer>();
data.add(rank);
data.add(order);
//获取中心点列表
List<ArrayList<Integer>> centers = Help.getCenters(context.getConfiguration().get("centerpath"));
//有几个聚类中心
int k = Integer.parseInt(context.getConfiguration().get("kpath"));
//当前数据与中心点的最小距离
int minDist = Integer.MAX_VALUE;
//中心点索引
int centerIndex = k;
//计算样本点到各个中心的距离,并把样本聚类到距离最近的中心点所属的类
for(int i=0;i<k;i++){
int currentDist=0;
currentDist=Help.caculateDistance0(data,centers.get(i));
if(minDist>currentDist){
minDist=currentDist;
centerIndex=i;
}
}
Text centerdata=new Text(rank+"t"+order);
context.write(new IntWritable(centerIndex), cell);
}
}
(8) KMeansReducerForClassify类
package myKMeans;
import java.io.IOException;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.Reducer;
/**
* 为数据集分类的Reducer
* @author zheng
*
*/
public class KMeansReducerForClassify extends Reducer<IntWritable, dataCell, IntWritable, dataCell>{
public void reduce(IntWritable key,Iterable<dataCell> value,Context context)
throws IOException,InterruptedException {
System.out.println("#######################");
for(dataCell val:value){
context.write(key, val);
}
}
}
最后
以上就是无语黑裤最近收集整理的关于KMeans算法的Mapreduce实现 KMeans算法的MapReduce实现的全部内容,更多相关KMeans算法的Mapreduce实现内容请搜索靠谱客的其他文章。








发表评论 取消回复