文章目录
- 1 引入
- 2 白盒攻击
- 2.1 Biggio
- 2.2 Szegedy's limited-memory BFGS (L-BFGS)
- 2.3 Fast gradient sign method (FGSM)
- 2.4 DeepFool
- 2.5 Jacobian-based saliency map attack (JSMA)
- 2.6 Basic iterative method (BIM) / Projected gradient descent (PGD) attack
- 2.7 Carlini & Wagner′s attack (C&W′s attack)
- 2.8 Ground truth attack
- 2.9 其他 l p l_p lp攻击
- 2.10 全局攻击 (universal attack)
- 2.11 空间转换攻击 (spatially transformed attack)
- 2.12 无约束对抗样本
- 3 物理世界攻击
- 3.1 物理世界的对抗样本探索
- 3.2 道路标志的Eykholt攻击
- 3.3 Athaly的3D对抗对象
- 4 黑盒攻击
- 4.1 替换模型
- 4.2 ZOO:基于零阶优化的黑盒攻击
- 4.3 高效查询黑盒攻击
- 5 灰盒攻击
- 6 中毒攻击
- 6.1 Biggio在SVM上的中毒攻击
- 6.2 Koh的模型解释
- 6.3 毒青蛙 (poison frogs)
- 参考文献
1 引入
相较于其他领域,图像领域的对抗样本生成有以下优势:
1)真实图像与虚假图像于观察者是直观的;
2)图像数据与图像分类器的结构相对简单。
主要内容:以全连接网络和卷积神经网络为例,以MNIST、CIFAR10,以及ImageNet为基础样本,研究基于逃避对抗,包括白盒、黑盒、灰盒,以及物理攻击的图像对抗样本生成。
2 白盒攻击
攻击者接收到分类器
C
C
C与受害样本 (victim sample)
(
x
,
y
)
(x,y)
(x,y) 后,其目标是合成一张在感知上与原始图像相似,但可能误导分类器给出错误预测结果的虚假图像:
找到
x
′
满足
∥
x
′
−
x
∥
≤
ϵ
,
例
如
C
(
x
′
)
=
t
≠
y
,
(1)
tag{1} text{找到}x'text{满足}|x'-x|leqepsilon, 例如C(x')=tneq y,
找到x′满足∥x′−x∥≤ϵ, 例如C(x′)=t=y,(1)其中
∥
⋅
∥
|cdot|
∥⋅∥用于度量
x
′
x'
x′与
x
x
x的不相似性,通常为
l
p
l_p
lp范数。接下来介绍该攻击手段下的主要方法。
2.1 Biggio
在MNIST数据集上生成对抗样本,攻击目标是传统的机器学习分类器,如SVM和3层全连接神经网络,且通过优化判别函数来误导分类器。
例如图1中,对于线性SVM,其判别函数
g
(
x
)
=
<
w
,
x
>
+
b
g(x)=<w,x>+b
g(x)=<w,x>+b。假设有一个样本
x
x
x被正确分类到3。则对于该模型,biggio首先生成一个新样本
x
′
x'
x′,其在最小化
g
(
x
′
)
g(x')
g(x′)的同时保持
∥
x
′
−
x
∥
1
|x'-x|_1
∥x′−x∥1最小。如果
g
(
x
′
)
<
0
g(x')<0
g(x′)<0,
x
′
x'
x′将被误分类。

2.2 Szegedy’s limited-memory BFGS (L-BFGS)
首次应用在用于图像分类的神经网络上,其通过优化以下目标来寻找对抗样本:
min
∥
x
−
x
′
∥
2
2
s.t.
C
(
x
′
)
=
t
and
x
′
∈
[
0
,
1
]
m
.
(2)
tag{2} begin{array}{l} & min &|x-x'|_2^2qquad text{s.t.} C(x') = t text{and }x'in[0,1]^m. end{array}
min∥x−x′∥22s.t.C(x′)=t and x′∈[0,1]m.(2) 通过引入损失函数来近似求解该问题:
min
λ
∥
x
−
x
′
∥
2
2
+
L
(
θ
.
x
′
,
t
)
,
s.t.
x
′
∈
[
0
,
1
]
m
,
(3)
tag{3} min lambda|x-x'|_2^2+mathcal{L}(theta.x',t), qquadtext{s.t. }x'in[0,1]^m,
min λ∥x−x′∥22+L(θ.x′,t),s.t. x′∈[0,1]m,(3)其中
λ
lambda
λ是一个规模参数。通过调整
λ
lambda
λ,可以找到一个与
x
x
x足够相似的
x
′
x'
x′,且同时误导分类器
C
C
C。
2.3 Fast gradient sign method (FGSM)
Goodfellow等人设计了一个一步到位的快速对抗样本生成方法:
x
′
=
x
+
ϵ
sign
(
∇
x
L
(
θ
,
x
,
y
)
)
,
非目标
x
′
=
x
−
ϵ
sign
(
∇
x
L
(
θ
,
x
,
t
)
)
,
目标
t
(4)
tag{4} begin{aligned} &x'=x+epsilontext{ sign}(nabla_xmathcal{L}(theta,x,y)),qquadtext{非目标}\ &x'=x-epsilontext{ sign}(nabla_xmathcal{L}(theta,x,t)),qquadtext{目标}t end{aligned}
x′=x+ϵ sign(∇xL(θ,x,y)),非目标x′=x−ϵ sign(∇xL(θ,x,t)),目标t(4) 在目标攻击设计下,该问题可以通过一步梯度下降求解:
min
L
(
θ
,
x
′
,
t
)
s.t.
∥
x
′
−
x
∥
∞
and
x
′
∈
[
0
,
1
]
m
.
(5)
tag{5} minmathcal{L}(theta,x',t)qquadtext{s.t. }|x'-x|_inftytext{ and }x'in[0,1]^m.
minL(θ,x′,t)s.t. ∥x′−x∥∞ and x′∈[0,1]m.(5) FGSM快速的一个原因是其仅需一次反向传播,因此适应于生成大量对抗样本的情况,其在ImageNet上的应用如图2。

2.4 DeepFool
研究分类器
F
F
F围绕数据点的决策边界,试图找到一条可以超越决策边界的路径,如图3,从而误分类样本点
x
x
x。例如,为误判类别为4的样本
x
0
x_0
x0到类别3,决策边界可以被描述为
F
3
=
{
z
:
F
(
x
)
4
−
F
(
x
)
3
=
0
}
mathcal{F}_3={ z:F(x)_4 - F(x)_3 = 0 }
F3={z:F(x)4−F(x)3=0}。令
f
(
x
)
=
F
(
x
)
4
−
F
(
x
)
3
f(x)=F(x)_4 - F(x)_3
f(x)=F(x)4−F(x)3,在每次攻击中,它将使用泰勒展开
F
3
′
=
{
x
:
f
(
x
)
≈
f
(
x
0
)
+
<
∇
x
f
(
x
0
)
−
(
x
−
x
0
)
>
=
0
}
mathcal{F}_3'={ x:f(x)approx f(x_0) + < nabla_xf(x_0)-(x-x_0)>=0 }
F3′={x:f(x)≈f(x0)+<∇xf(x0)−(x−x0)>=0}来线性化决策超平面,并计算
ω
0
omega_0
ω0到超平面
F
3
′
mathcal{F}_3'
F3′的正交向量
ω
omega
ω。向量
ω
omega
ω可以作为扰动使得
x
0
x_0
x0游离于超平面。通过移动
ω
omega
ω,算法将找到可以被分类为3的对抗样本
x
0
′
x_0'
x0′。
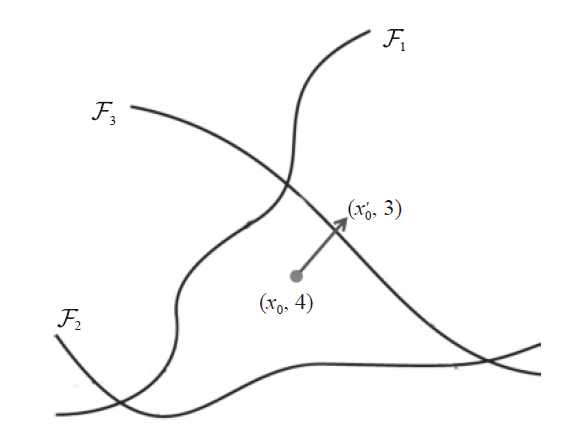
DeepFool的实验结果展示,对于一般性的DNN图像分类器,所有的测试样本都非常接近决策边界。例如LeNet在MNIST数据集上训练好后,只需些许扰动,超过90%的样本都将被误分类,这表面DNN分类器对扰动是不健壮的。
2.5 Jacobian-based saliency map attack (JSMA)
JSMA介绍了一种基于计算评分函数
F
F
F雅可比矩阵的方法,其迭代地操作对模型输出影响最大的像素,可被视为一种贪心攻击算法。
具体地,作者使用雅可比矩阵
J
F
(
x
)
=
∂
F
(
x
)
∂
x
=
{
∂
F
j
(
x
)
∂
x
i
}
i
×
j
mathcal{J}_F(x)=frac{partial F(x)}{partial x}=left{ frac{partial F_j(x)}{partial x_i} right}_{itimes j}
JF(x)=∂x∂F(x)={∂xi∂Fj(x)}i×j来对
F
(
x
)
F(x)
F(x)响应
x
x
x变化时的改变建模。在目标攻击设置下,攻击者试图将样本误分类为
t
t
t。因此,JSMA反复地搜索和操作这样的像素,其增加/减少将导致
F
t
(
x
)
F_t(x)
Ft(x)增加/减少
∑
j
≠
t
F
j
(
x
)
sum_{jneq t} F_j(x)
∑j=tFj(x)。最终分类器将在类别
t
t
t上给
x
x
x更大的分数。
2.6 Basic iterative method (BIM) / Projected gradient descent (PGD) attack
该方法是FGSM的迭代版本,在非目标攻击下,将迭代性地生成
x
′
x'
x′:
x
0
=
x
;
x
t
+
1
=
C
l
i
p
x
,
ϵ
(
x
t
+
α
sign
(
∇
x
L
(
θ
,
x
t
,
y
)
)
)
(6)
tag{6} x_0=x; x^{t+1}=Clip_{x,epsilon}(x^t+alphatext{ sign}(nabla_xmathcal{L}(theta,x^t,y)))
x0=x;xt+1=Clipx,ϵ(xt+α sign(∇xL(θ,xt,y)))(6) 这里的
C
l
i
p
Clip
Clip表示将接收内容投影到
x
x
x的
ϵ
epsilon
ϵ邻域超球
B
ϵ
(
x
)
:
{
x
′
:
∥
x
′
−
x
∥
∞
≤
ϵ
}
B_epsilon(x):{ x':|x'-x|_inftyleq epsilon }
Bϵ(x):{x′:∥x′−x∥∞≤ϵ}的函数。步长
α
alpha
α通常被设置为一个相当小的值,例如使得每个像素每次只改变一个单位,步数用于保证扰动可以到达边界,例如
s
t
e
p
=
ϵ
a
l
p
h
a
+
10
step=frac{epsilon}{alpha}+10
step=alphaϵ+10。如果
x
x
x是随机初始化的,该算法也可被叫做PGD。
BIM启发性地于样本
x
x
x邻域
l
∞
l_infty
l∞内搜寻具有最大损失的样本
x
′
x'
x′,这样的样本也被称为“最具对抗性”样本:当扰动强度被限定后,这样的样本有最强的攻击性,其最可能愚弄分类器。找到这样的对抗样本将有助于探测深度学习模型的缺陷。
2.7 Carlini & Wagner′s attack (C&W′s attack)
C&W′s attack用于对抗在FGSM和L-BFGS上的防御策略,其目标是解决L-BFGS中定义的最小失真扰动。使用以下策略来近似公式2:
min
∥
x
−
x
′
∥
2
2
+
c
⋅
f
(
x
′
,
t
)
,
s.t.
x
′
∈
[
0
,
1
]
m
,
(7)
tag{7} min |x-x'|_2^2+ccdot f(x',t),qquadtext{s.t. }x'in[0,1]^m,
min∥x−x′∥22+c⋅f(x′,t),s.t. x′∈[0,1]m,(7)其中
f
(
x
′
,
t
)
=
(
max
i
=
t
Z
(
x
′
)
i
−
Z
(
x
′
)
t
)
+
f(x',t)=(max_{i=t}Z(x')_i-Z(x')_t)^+
f(x′,t)=(maxi=tZ(x′)i−Z(x′)t)+,
Z
(
⋅
)
Z(cdot)
Z(⋅)用于获取softmax前的网络层输入。通过最小化
f
(
x
′
,
t
)
f(x',t)
f(x′,t)可以找到一个在类别
t
t
t上得分远大于其他类的
x
′
x'
x′。接下来运用线性搜索,将找到一个离
x
x
x最近的
x
′
x'
x′。
函数
f
(
x
,
y
)
f(x,y)
f(x,y)可以看作是关于数据
(
x
,
y
)
(x,y)
(x,y)的损失函数:可以惩罚一些标签
i
i
i的得分
Z
(
x
)
i
>
Z
(
x
)
y
Z(x)_i>Z(x)_y
Z(x)i>Z(x)y的情况。C&W’s attack与L-BFGS的唯一区别是前者使用
f
(
x
,
t
)
f(x,t)
f(x,t)来代替后者的交叉熵
L
(
x
,
t
)
mathcal{L}(x,t)
L(x,t)。这样的好处在于,当分类器输出
C
(
x
′
)
=
t
C(x')=t
C(x′)=t时,损失
f
(
x
′
,
t
)
=
0
f(x',t)=0
f(x′,t)=0,算法将直接最小化
x
′
x'
x′到
x
x
x的距离。
作者宣称他们的方法是最强的攻击策略之一,其击败了很多被反击手段。因此,该方法可以作为DNN安全检测的基准点,或者用于评估对抗样本的质量。
2.8 Ground truth attack
攻击与防御针锋相对,为了打破这种僵局,Carlini等人试图找到一种最强攻击,其用于寻找理论上的最小失真对抗样本。该攻击方法基于一种用于验证神经网络特性的算法,其将模型参数
F
F
F和数据
(
x
,
y
)
(x,y)
(x,y)编码为类线性编程系统的主题,并通过检查样本
x
x
x的邻域
B
ϵ
(
x
)
B_epsilon(x)
Bϵ(x)是否存在一个能够误导分类器的样本
x
′
x'
x′来处理该系统。通过缩小邻域直至不存在
x
′
x'
x′,那么由于最后一次搜寻到的
x
′
x'
x′与
x
x
x之间具有最小不相似性,此时的
x
′
x'
x′便被叫做基本事实对抗样本 (ground truth adversarial example)。
Ground truth attack是首次严肃精确分类器健壮性的方法。然而,这种方法使用了可满足性模理论 (satisfiability modulo theories, SMT) 求解器 (一种检查一系列理论可满足性的复杂算法),这将使其速度缓慢且无法扩展到大型网络。后续则有工作着手提升其效率效率。
2.9 其他 l p l_p lp攻击
2.1–2.8的攻击方式主要关注
l
2
l_2
l2或
l
∞
l_infty
l∞约束下的扰动,这里则介绍一些其他的:
1)One-pixel attack:与L-BFGS区别在于约束种使用
l
0
l_0
l0,好处是可以限制允许改变的像素的数量。该工作展示,在CIFAR10数据集上,仅需改变一个像素就可以令训练良好的CNN分类器预判一半以上的样本;
2)Elastic-net attack (ENA):与L-BFGS的区别在于同时使用
l
1
l_1
l1和
l
2
l_2
l2范数来约束。
2.10 全局攻击 (universal attack)
2.1–2.9的方法仅对一个特定的样本
x
x
x进行攻击。而该攻击旨在误导分类器在所有测试集上的结果,其试图找到满足以下条件的扰动
δ
delta
δ:
1)
∥
δ
∥
p
≤
ϵ
|delta|_pleqepsilon
∥δ∥p≤ϵ;
2)
R
x
∼
D
(
x
)
(
C
(
x
+
δ
)
≠
C
(
x
)
)
≤
1
−
σ
mathbb{R}_{xsim D(x)}(C(x+delta)neq C(x))leq1-sigma
Rx∼D(x)(C(x+δ)=C(x))≤1−σ。
在相应实验中,成功找到了一个扰动
δ
delta
δ,使得ResNet152网络在ILSVRC 2012数据集上的
85.4
%
85.4%
85.4%的样本受到攻击。
2.11 空间转换攻击 (spatially transformed attack)
传统的对抗性攻击算法直接修改图像中的像素,这将改变图像的颜色强度。空间转换攻击通过在图像上添加一些空间扰动来进行攻击,包括局部图像特征的平移扭曲、旋转,以及扭曲。这样的扰动足以逃避人工检测,亦能欺骗分类器,如图4。
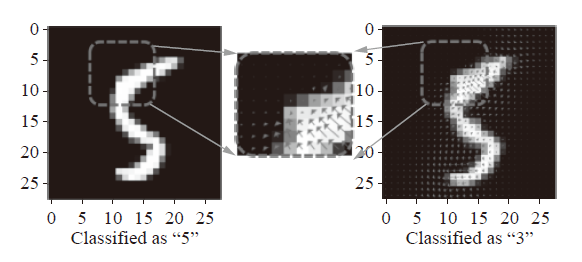
2.12 无约束对抗样本
2.1–11的工作均在图像上添加不引入注意的扰动,该工作则生成了一些无约束的对抗样本:这些样本无需看起来和受害图像类似,而是能够愚弄分类器且在观察者眼中合法的图像。
为了攻击分类器
C
C
C,增强类对抗生成网络 (AC-GAN)
G
mathcal{G}
G首先基于
c
c
c类噪声向量
z
0
z^0
z0生成一个合法样本
x
x
x。然后找到一个接近
z
0
z^0
z0的噪声向量
z
z
z,其使得
G
(
z
)
mathcal{G}(z)
G(z)可以误导
C
C
C。由于
z
z
z在潜在空间中与
z
0
z^0
z0相似,输出
G
(
z
)
mathcal{G}(z)
G(z)依然具备标签
y
y
y,从而达到攻击的目的。
3 物理世界攻击
章节2中的所有攻击方法都以数字形式应用,其被攻击方将输入图像直接提供给机器学习模型。然而,在某些情况下并非总是如此,例如使用摄像头、麦克风或其他传感器接收信号作为输入的情况。这种情况下依然通过生成物理世界对抗对象来攻击这些系统吗?这样的攻击方式是存在的,例如将贴纸贴在道路标志上,这会严重威胁自动驾驶汽车的标志识别器。这类对抗性对象对深度学习模型的破坏性更大,因为它们可以直接挑战DNN的许多实际应用,例如人脸识别、自动驾驶等。
3.1 物理世界的对抗样本探索
例如通过检查生成的对抗图像 (FGSM、BIM) 在自然变换 (如改变视点、光照等) 下是否“稳健”来探索制作物理对抗对象的可行性。在这里,“健壮”是指制作的图像在转换后仍然是对抗性的。为了应用这种转换,首先打印出精心制作的图像,并让测试对象使用手机为这些打印输出拍照。在这个过程中,拍摄角度或光照环境不受限制,因此获取的照片是从先前生成的对抗样本转换而来的样本。实验结果表明,在转换后,这些对抗样本中的很大一部分,尤其是FGSM生成的样本,仍然与分类器对抗。这些结果表明物理对抗对象的可能性可以在不同环境下欺骗传感器。
3.2 道路标志的Eykholt攻击
图5中,通过在信号标志的适当位置粘贴胶带以愚弄信号识别器。作者的攻击手段包括:
1)
基
于
l
1
基于l_1
基于l1范数的攻击用于粗略定位扰动区域,这些区域后面将粘贴胶带;
2)在粗略定位区域,使用基于
l
2
l_2
l2范数的攻击生成胶带的颜色;
3)指定区域粘贴指定颜色胶带。这样的攻击方式从不同角度不同距离混淆自动驾驶系统。

3.3 Athaly的3D对抗对象
一个成功制作物理3D对抗对象的工作如图 6 所示。作者使用3D打印来制造对抗性乌龟。为了实现目标,他们实施了3D渲染技术。给定一个带纹理的3D对象,首先优化对象的纹理,使渲染图像从任何角度来看都是对抗性的。在这个过程中,还确保扰动在不同环境下保持对抗性:相机距离、光照条件、旋转,以及背景。在找到3D渲染的扰动后,他们打印3D对象的一个实例。

4 黑盒攻击
4.1 替换模型
攻击者仅能通过输入样本
x
x
x后获取的标签信息
y
y
y来执行攻击。此外,攻击者可以有以下可用信息:
1)分类数据的领域;
2)分类器的框架,例如CNN还是RNN。
该工作探索了对抗样本的可迁移性:一个样本
x
′
x'
x′如果可以攻击分类器
F
1
F_1
F1,那么它同样可以攻击与
F
1
F_1
F1结构类似的分类器
F
2
F_2
F2。因此,作者训练了一个替换模型
F
′
F'
F′以对受害模型
F
F
F进行模拟,然后通过攻击
F
′
F'
F′来生成对抗样本,其主要步骤如下:
1)合成替换训练数据集:例如手写识别任务中,攻击者可以复刻测试样本或者其他手写数据;
2)训练替换模型:将合成数据集
X
X
X输入受害者模型以获取标签
Y
Y
Y,随后基于
(
X
,
Y
)
(X,Y)
(X,Y)训练DNN模型
F
′
F'
F′。攻击者将基于自身知识,从训练模型中选择一个与受害者模型结构最相似的
F
′
F'
F′;
3)数据增强:迭代增强
(
X
,
Y
)
(X,Y)
(X,Y)并重训练
F
′
F'
F′。这个过程将提升复刻数据的多样性并提升
F
′
F'
F′的精度;
4)攻击替换模型:利用已有方法如FGSM来攻击
F
′
F'
F′,生成的对抗样本将用于戏耍
F
F
F????
应该选择如何的攻击方法攻击
F
′
F'
F′?一个成功的替换模型黑盒攻击应当具备可迁移性,因此我们选择具有高迁移性的攻击方法如FGSM、PGD,以及动量迭代攻击。
4.2 ZOO:基于零阶优化的黑盒攻击
该方法假设可以从分类器获取预测置信度,这种情况下便无需建立替换数据集和替换模型。Chen等人通过调整
x
x
x的像素来观测
F
(
x
)
F(x)
F(x)的置信度变化,以获取
x
x
x相关的梯度信息。如公式8所示,通过引入足够小的扰动
h
h
h,我们能够通过输出信息来推着梯度信息:
∂
F
(
x
)
∂
x
i
≈
F
(
x
+
h
e
i
)
−
F
(
x
−
h
e
i
)
2
h
.
(8)
tag{8} frac{partial F(x)}{partial x_i}approxfrac{F(x+he_i)-F(x-he_i)}{2h}.
∂xi∂F(x)≈2hF(x+hei)−F(x−hei).(8) ZOO相较于替换模型更成功的地方在于可以利用更多的预测信息。
4.3 高效查询黑盒攻击
4.1-2中的方式需要多次查询模型的输出信息,这在某些应用中是禁止的。因此在有限次数内提高黑盒攻击对抗样本的生成效率是有必要的。例如引入自然进化策略来高效获取梯度信息,其基于 x x x的查询结果进行采样,然后评估 F F F的梯度在 x x x上的期望。此外,他们利用遗传算法来为对抗样本搜寻受害图像的邻域。
5 灰盒攻击
灰盒攻击的策略,例如,首先针对感兴趣模型训练一个GAN,然后直接基于对抗生成网络生成对抗样本。该作者认为基于GAN的攻击方式能够加速对抗样本的生成,且能获取更多自然且不易察觉的图像。随后这种策略也被用于人脸识别系统的入侵上。
6 中毒攻击
已有的讨论均是在分类器训练后进行,中毒攻击则在训练前生成对抗样本:生成一些对抗样本嵌入到训练集中,从而降低分类模型的总体精度或者影响特定类别的样本。通常,该设置下的攻击者拥有后续用于训练中毒数据的模型结构。中毒攻击通常用于图神经网络,这些因为它需要特定的图知识。
6.1 Biggio在SVM上的中毒攻击
找到这样的一个样本 x c x_c xc,其混入训练数据后,将导致习得的SVM模型 F x c F_{x_c} Fxc在验证集上有很大的损失。这样的攻击方法对SVM是奏效的,然而对于深度学习,找到这样的一个样本是困难的。
6.2 Koh的模型解释
Koh和Liang引入一种神经网络的解释方法:如果训练样本改变,模型的预测结果会有如何的变化?当只修改一个训练样本时,他们的模型可以明确量化最终损失的变化,而无需重新训练模型。 通过找到对模型预测有很大影响的训练样本,这项工作可以自然地用于中毒攻击。
6.3 毒青蛙 (poison frogs)
毒青蛙在训练集中混入一张带有真实标签的对抗图像,从而到达错误的预测测试集的目的。给定一个标签为
y
t
y_t
yt的目标测试样本
x
t
x_t
xt,攻击者首先使用标签为
y
b
y_b
yb的基准样本
x
b
x_b
xb,并通过以下优化找到
x
′
x'
x′:
x
′
=
arg min
x
∥
Z
(
x
)
−
Z
(
x
t
)
∥
2
2
+
β
∥
x
−
x
b
∥
2
2
(9)
tag{9} x'=argmin_x|Z(x)-Z(x_t)|_2^2+beta|x-x_b|_2^2
x′=xargmin∥Z(x)−Z(xt)∥22+β∥x−xb∥22(9) 由于
x
′
x'
x′与
x
b
x_b
xb最近,基于训练集
X
t
r
a
i
n
+
{
x
}
′
X_{train}+{x}'
Xtrain+{x}′训练的模型将会把
x
′
x'
x′预测为
y
b
y_b
yb。使用新模型去预测
x
t
x_t
xt,优化目标将会强制拉近
x
t
x_t
xt与
x
′
x'
x′的预测得分,即将
x
t
x_t
xt预测为
y
b
y_b
yb。
参考文献
【1】Adversarial Attacks and Defenses in Images, Graphs and Text: A Review
最后
以上就是欢喜老鼠最近收集整理的关于对抗攻击与防御 (1):图像领域的对抗样本生成1 引入2 白盒攻击3 物理世界攻击4 黑盒攻击5 灰盒攻击6 中毒攻击参考文献的全部内容,更多相关对抗攻击与防御内容请搜索靠谱客的其他文章。








发表评论 取消回复