现在AI安全早已成为安全行业的热门词汇了,AI安全包括两个层面,一个用AI解决安全安全行业问题,一个是AI自身的安全问题,平时我们谈AI解决安全安全行业问题比较多,对AI自身安全确少有提及,今天要分享的就是AI自身安全问题,总结了一些前沿的论文,方便大家一目了然。
机器学习(深度学习)的分层实现:
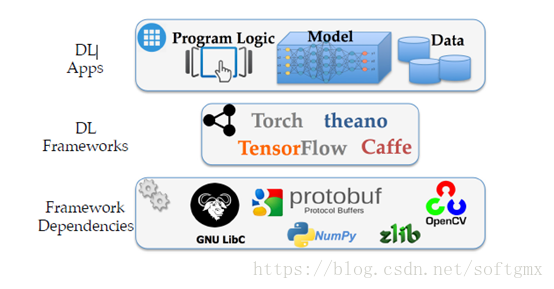
主流的深度机器学习平台的复杂度:
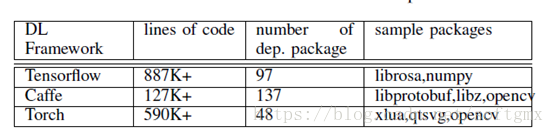
存在的攻击面:
- 输入畸形数据
- 输入被毒化的训练数据
- 输入带有攻击恶意模型
报过的漏洞:
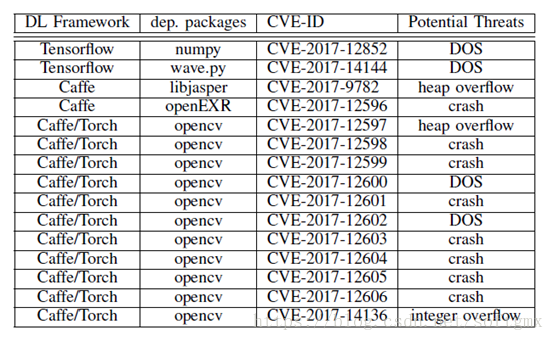
威胁类型:
(1) DoS 攻击
对训练机器的资源进行消耗,只到耗尽,形成DOS攻击,这种攻击将来对分布式训练平台也有很大的杀伤力
(2)规避攻击
1)通过漏洞复写训练结果模型
2) 劫持程序的执行改变训练模型的执行
(3)威胁训练系统( 通过构造一个恶意图片,使训练程序触发漏洞,导致训练机器被控制)
问题思考:
- 怎样保障机器学习环境(公用的分布式平台或封闭式环境)的不被入侵?
- 怎样检测深度学习模型的有没有被毒化?
- 怎样检出深度学习程序自身的逻辑错误或有没有被数据构造攻击
最后
以上就是呆萌小鸽子最近收集整理的关于深度学习自身的安全的全部内容,更多相关深度学习自身内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复