文章目录
- 结合多特征识别的恶意加密流量检测方法
- 摘要
- 论文解决的问题与贡献
- 1. 正常流量与恶意流量特征比较
- (1)会话的统计特征分析
- (2)TLS协议特征分析
- (3)服务器证书特征
- (4)服务器域名特征
- 2. RMETD-MF 方法
- (1)流量捕获
- (2)流量预处理
- (3)特征提取
- (4)模型训练与测试
- 结论
- 总结
- 1.学到的知识点
- 2.论文创新点
结合多特征识别的恶意加密流量检测方法
摘要
随着加密流量的广泛使用,越来越多恶意软件也利用加密流量来传输恶意信息,由于其传输内容不可见,传统的基于深度包分析的检测方法带来精度下降和实时性不足等问题。
本文通过分析恶意加密流量和正常流量的会话和协议,提出了一种结合多特征的恶意加密流量检测方法,该方法提取了加密流量会话的包长与时间马尔科夫链、包长与时间分布及包长与时间统计等方面的统计特征,结合握手阶段的 TLS 加密套件使用、证书及域名等协议特征,构建了 863 维的特征向量,利用机器学习方法对加密流量进行检测,从而发现恶意加密流量。
测试结果表明,结合多特征的恶意加密流量检测方法能达到 98%以上的分类准确性及 99.8%以上召回率,且在保持相当的分类准确性基础上,具有更好的鲁棒性, 适用性更广。
论文解决的问题与贡献
- 加密流量导致传统的基于深度包分析的检测方法带来精度下降和实时性不足等问题。
- 提出了一种结合多特征的恶意加密流量加测方法RMETD-MF,用以发现而已加密流量
- 通过监控网络流量,分析了恶意流量和正常流量的区别。提取了其中能明显区别正常流量和恶意流量的 69 个特征,包括会话元数据特征、包长序列统计特征、TLS 握手特征、证书特征和域名特征,用于恶意流量的识别和检测
- 分析了 RMETD-MF 方法在不同时间流量数据的检测效果以及不同数据集下分类的效果,验证了方法的稳定性和分类的准确度
1. 正常流量与恶意流量特征比较
(1)会话的统计特征分析
-
包数量的特征
恶意流量:大部分接受数据包数量为3-5个
正常流量:数据包数量变化范围大,从3个到几千个都有,大部分数据包数量为几十个 -
包长序列的特征
恶意流量:同一恶意家族的包长序列具有一定的相似性。
如trojan.win32.zbot 家族的加密会大部分都链接到网站infoplusplus.com 或 ax100.net 网站, 其中, 链接到infoplusplus.com 的会话包长序列为{403, 105, 51, 176, 508}, 而链接到 ax100.net 网站的包长序列为{396, 105, 51, 170, 509}
正常流量:正常加密会话的包长序列是变化的,并没有固定长度。
-
会话持续时间的特征
恶意流量:大多数恶意家族约在20s内完成加密会话。时间较短。
正常流量:正常的加密会话没有特定时间长度。 -
数据包顺序与大小特征
恶意流量:恶意家族的发送/接收数据包的顺序与大小较为相似。而且,同一恶意家族的会话的不同数据包序列可能具有相同的数据包子序列,会话的前几个数据包序列是相同的。
如恶意家族 Trojan.Win32.SelfDel 的 26836 个加密会话仅有 123 种不同的数据包序列, 恶意家族Trojan-Spy.Win32.Zbot 的 16758 个加密会话中仅有219 种不同的数据包序列。
正常流量:正常流量没有特定的数据包发送序列和大小。
(2)TLS协议特征分析
建立 TLS 连接的第一步是客户端向服务器端发送明文 Client Hello 消息,并将自己所支持的按优先级排列的加密套件信息和扩展列表发送给服务器端,这一消息的生成方式取决于构建客户端应用程序时所使用的软件包和方法。
服务端反馈 Server Hello 消息,包含选择使用的加密套件、扩展列表和随机数等,这一消息基于服务器端所用库和配置以及 Client Hello 消息中的详细信息创建。
由于大部分恶意软件会复用同一个恶意软件的代码,因此许多恶意软件的 Client Hello 消息在一些特征上十分相似, 如加密套件、扩展等。
-
加密套件使用的特征
恶意会话:95%的恶意加密会话使用相同的 7 个加密套件列表。
正常会话:加密套件列表分布较为分散。恶意会话中使用最高的加密套件列表在正常会话中所占的比例仅为 2.20%和 1.14%。可见恶意流量和正常流量在加密套件的使用上有明显区别。
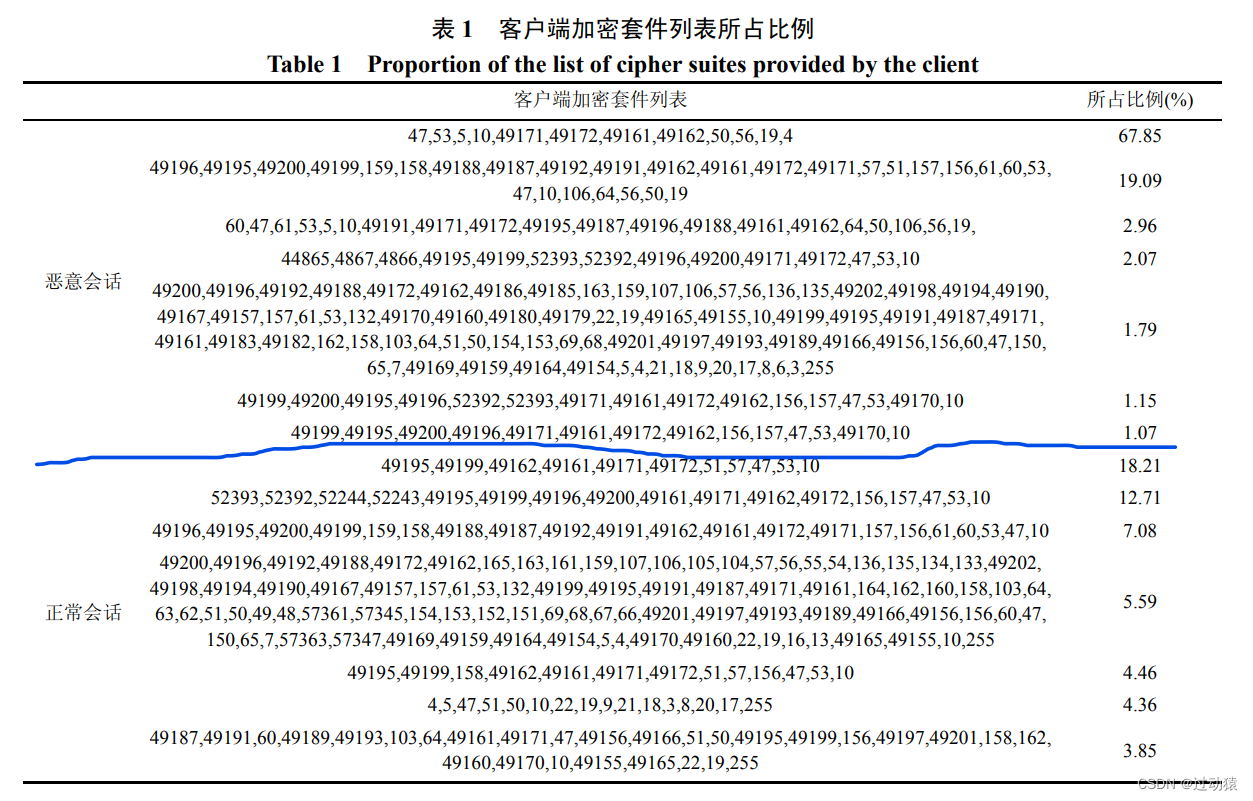
客户端所用单个加密套件数量:恶意会话中客户端集中使用 12 个和 28个加密套件。正常会话中客户端多使用17,14,11 个加密套件。加密套件 4、5、19、50、56 在恶意流量中的使用明显多于正常流量中的使用。而这些加密套件
被认为是比较弱的加密套件, 安全性不足, 在正常的软件中不被推荐使用。 -
扩展加密套件使用的特征
恶意会话:恶意会话客户端最多使用的扩展标识号为10、11、0、65281、5。恶意加密会话客户端所使用的扩展数目多为 5 个。
正常会话:正常加密会话客户端常用的扩展种类较多,而正常会话的客户端扩展数目较为多样。
(3)服务器证书特征
服务器证书是 TLS 协议中用来对服务器身份进行验证的文件。
恶意会话:
(1)由于会话复用的广泛使用,88%的恶意会话没有传输证书。
(2)在传输了证书的加密会话中,3.34%的恶意会话证书版本为 1。
(3)大部分(48%)恶意软件为了方便会选择使用自签名证书。这种证书支持超长有效期。
(4)恶意会话中只有 53%为域名,30%为.com 域名。
(5)恶意会话的证书的 Subject Alt Names数目最多的为 0~9 个
正常会话:
(1)由于会话复用的广泛使用,36%的正常会话没有传输证书
(2)在传输了证书的加密会话中,证书版本基本都为3。
(3)12%正常会话使用自签名证书。通常正常会话所用证书的有效时间多分布在 0~4 年间。
(4)85%的正常会话所用证书中的 Common Name 为域名,62%为.com 域名
(5)正常会话的证书的 Subject Alt Names数目有接近40%的比例是大于100个的。
(4)服务器域名特征
Client Hello 中的 Server Name Indication 扩展用于指示客户端请求的服务器域名, 防止一个 IP连接多个服务器而造成错误。当 Client Hello 中无域名指示时, 则取证书中的 Common Name 作为服务器域名。
恶意会话:恶意会话中域名较为分散, 大多数为比较不常见的域名。
正常会话:正常会话中域名多为常见域名。
这是因为正常会话多连向一些常见的正常网站,而恶意会话多连向一些由域名生成算法生成的不常见的网站,则其域名排名较为靠后。
2. RMETD-MF 方法
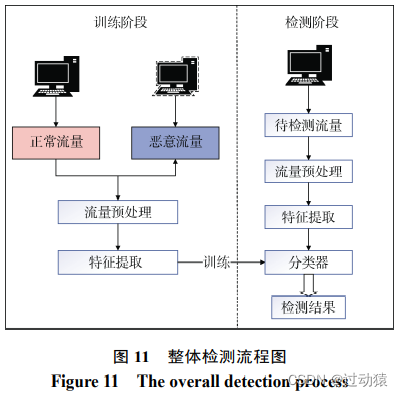
整体流程:
- 流量捕获:在沙箱中运行恶意软件和正常软件生成流量数据。
- 流量预处理:对流量进行清洗,过滤未加密流量和不完整的会话。
- 特征提取:根据需求, 提取相关会话的统计特征和系欸特征信息, 形成训练的 863 维特征向量
- 模型训练:构建恶意加密流量分析的模型。
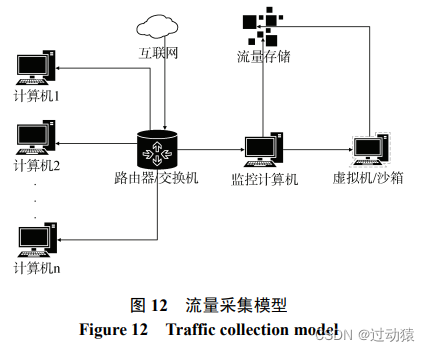
(1)流量捕获
- 正常流量:
(1)运行 wireshark 等工具捕获访问正常加密网站或运行正常软件产生的流量来获得
(2)通过监控较为干净的网络环境流量来获得, 并通过白名单过滤获得白名单中的会话作为正常流量
- 恶意流量:
在沙箱中运行恶意软件, 保存其运行期间产生的流量, 然后过滤掉沙箱间通信流量及系统白流量, 将剩余的流量作为恶意流量。
(2)流量预处理
- 过滤未加密的流量,保留使用SSL/TLS协议的流量。
- 过滤会话,过滤为完成完整握手过程和未传输加密数据的会话。
具体方法是:
通过观察会话中是否有 Client Hello 消息和 Change Cipher Spec 消息, 来判断握手是否完成;
通过观察会话中是否有 Application Data 消息, 来判断会话是否传输了加密数据。
- 过滤重传包、确认包和传输丢失的坏包。
(3)特征提取
- 会话的统计特征提取
(1)元数据特征:会话的一般信息,如client->server发送的包数、字节数,server->client发送的包数、字节数,会话持续时间等等
(2)包长与时间序列特征:包长:会话最大传输单位为1500字节,将该会话中传输长度分为10段,[0,150),[150,300)…,[1350,会话结束),构建每个数据包有效载荷的长度及相邻包之间的10*10转换关系矩阵。并按行拼接为100维特征。
时间:构建相邻数据包的时间间隔序列特征,将时间间隔分为十个分段 [0,50ms],[50ms,100ms],…, [450ms, +∞], 根据相邻包之间的时间间隔所在的区间及转换关系构建 10*10 的马尔可夫转换矩阵, 将其也按行拼接作为 100 维的特征向量。
(3)包长与时间分布特征
包长:将包长分为 150 个不同的范围(0,10), (10,20),…,(1490, +∞), 根据每个包的长度计算每个包长区间分布的包数, 作为 150 维的特征。
时间:将时间间隔分为 100 个不同的范围(0,0.005), (0.005,0.01),…,(0.45,+∞), 根据每个包与
前一个包的时间间隔计算每个时间间隔区间分布的包数, 作为 100 维的特征向量。(4)包长与时间统计特征
分别计算包长序列和时间序列的统计特征: 个数, 最小值, 最小元素位置, 25%分数, 中位数, 75%
分数, 均值, 最大值, 最大元素位置, 平均绝对方差, 方差, 标准差, 形成 24 维的特征向量。
- TLS 握手特征提取
(1)客户端TLS特征
– 观察发现客户端使用的加密套件共 260 种, 因此, 设置 260 维向量。
– 对客户端支持的扩展列表构建 43 维向量, 对应所使用的 43 个扩展加密套件。
– 计算扩展个数, 作为1维特征向量输入。(2)服务器端 tls 特征
– 将服务器端所选择的加密套件作为1维特征向量输入
– 同时服务器端支持的扩展列表构建成 43 维特征向量
– 扩展个数也是 1 维特征向量。
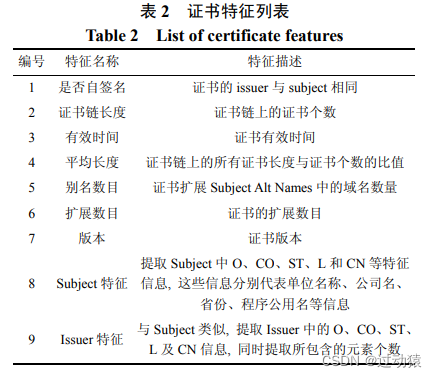
- 证书特征提取
- 域名特征
(1)域名特征
提取有关域名的特征,包括域名中字母符号数目占所有字符的比例、数字符号数目占所有字符的比例以及非字母数字符号数目占所有字符的比例。
(2)排名特征
根据域名在 Alexa 前 100 万列表中的排名, 构建一个长度为6的向量, 根据其是否在top100, top1000, top1w, top10w, top100w, not-in 列表中来进行向量设置, 在则将该位置为 1, 如果都不在就置为 0, 若不在前 100w 列表就置 not-in 位为 1。
(4)模型训练与测试
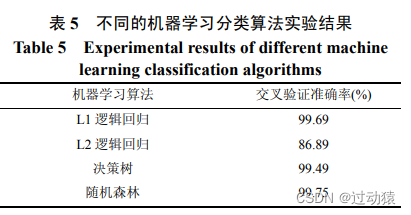
分别采用随机森林、逻辑回归、决策树等四种机器学习算法进行十折交叉验证。
结论
数据集:
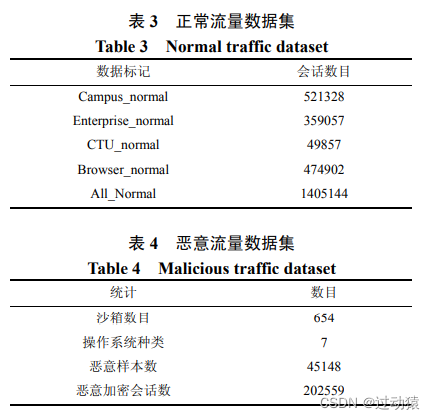
机器学习效果:
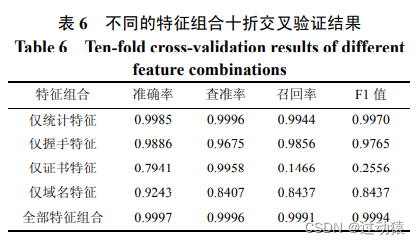
特征测试效果:
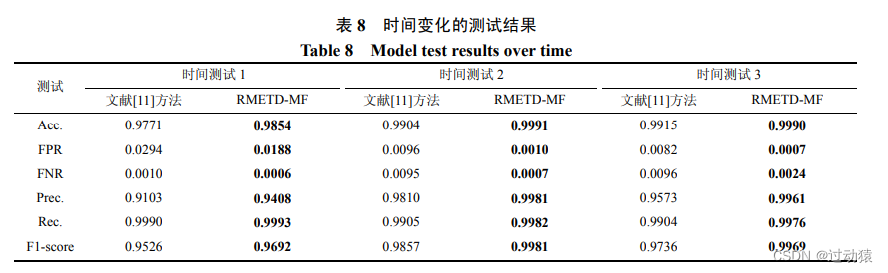
时间测试效果:
根据时间顺序将正常数据集和恶意数据集划为训练集和测试集。选取 2019 年 5 月~2019 年 7月中旬的恶意流量、2017 年 12 月~2018 年 2 月的校园网流量及 2019 年 8 月前两周的企业流量数据作为训练集; 选取 2019 年 7 月下旬~2019 年 8 月的恶意流量、2019 年 3 月和 2019 年 11 月的校园网流量、以及企业 2019 年 8 月第三周数据作为测试集。
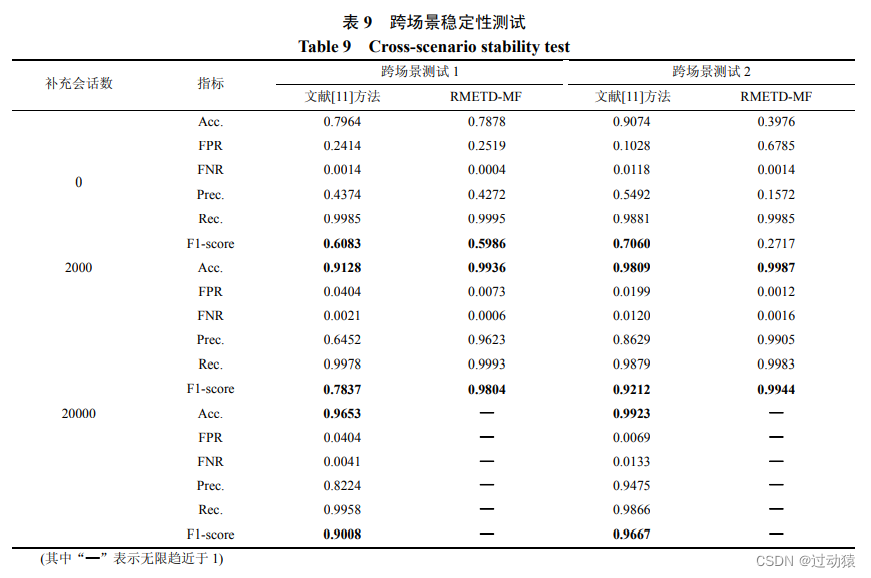
跨场景稳定性:
第一组实验测试选取 70%的校园网正常数据集与 70%的恶意数据集进行训练, 验证在企业正常数据集与 30%恶意数据集上的检测效果, 记为跨场景测试 1;
第二组实验选取70%的企业正常数据集和 70%的恶意数据集进行训练, 测试在校园网数据集与剩余的 30%的恶意数据集上的检测效果, 记为跨场景测试 2;
由于数据集不相交, 为了降低误报率, 从测试数据集中随机划分10%的正常数据集作为训练集的补充, 分别测试了随着补充的会话数增加对准确率等指标的影响
总结
1.学到的知识点
- TLS协议是较常用的加密协议
- 整体加密流量检测的流程,包括流量收集、流量预处理的方法。
2.论文创新点
- 从各个角度收集了恶意流量和正常流量的特征区别
- 提出的模型有很好的鲁棒性
最后
以上就是标致眼睛最近收集整理的关于【研究型论文】结合多特征识别的恶意加密流量检测方法(中文论文_信息安全学报)结合多特征识别的恶意加密流量检测方法的全部内容,更多相关【研究型论文】结合多特征识别内容请搜索靠谱客的其他文章。








发表评论 取消回复