[本专题会对常见的数据结构及相应算法进行分析与总结,并会在每个系列的博文中提供几道相关的一线互联网企业面试/笔试题来巩固所学及帮助我们查漏补缺。项目地址:https://github.com/absfree/Algo。由于个人水平有限,叙述中难免存在不清晰准确的地方,希望大家可以指正,谢谢大家:)]
一、什么是链表
提到链表,我们大家都不陌生,在平时的编码中我们也或多或少地使用过这个数据结构。算法(第4版) (豆瓣)一书中对链表的定义如下:
链表是一种递归的数据结构,它或者为空(null),或者是指向一个结点(node)的引用,该节点还有一个元素和一个指向另一条链表的引用。
把以上定义用Java语言来描述大概是这样的:
public class LinkedList<Item> { private Node first; private class Node { Item data; Node next; } ... }
一个LinkedList类实例便代表了一个链表,它的一个实例域保存了指向链表中第一个结点的引用。如下图所示:
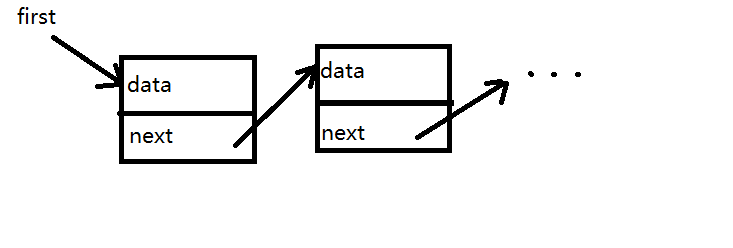
当然,以上我们所介绍的链表是single linked list(单向链表),有时候我们更喜欢double linked list(双向链表),double linked list就是每个node不仅包含指向下后一个结点的引用,还包含着指向前一个结点的引用。后文我们在介绍链表的具体实现是会对这两种链表进行更加详细地介绍。
通常来说,链表支持插入和删除这两种操作,并且删除/插入链表头部/尾部结点的时间复杂度通常都是常数级别的,链表的不足在于不支持高效的random access(随机访问)。
二、链表的实现
1. 单链表(Single-Linked List)
在上文中,我们已经简单用用Java刻画出了链表的部分结构,我们只需为以上的LinkedList类增加insert、delete等方法,便可以实现一个(单向)链表。下面我们来介绍如何向链表中插入及删除结点。
(1)插入结点
由于我们的LinkedList类中维护了一个指向first node的引用,所以在表头插入结点是很容易的,具体请看以下代码:
public void insert(Item item) { Node oldFirst = first; first = new Node(); first.item = item; first.next = oldFirst; itemCount++; }
(2)删除结点
在表头删除结点的代码也很简单,基本是自注释的:
public Item delete() { if (first != null) { Item item = first.item; first = first.next; return item; } else { throw new NullPointerException("There's no Node in the linked list."); }
2. 双向链表(Double-Linked List)
双向链表相比与单链表的优势在于它同时支持高效的正向及反向遍历,并且可以方便的在链表尾部删除结点(单链表可以方便的在尾部插入结点,但不支持高效的表尾删除操作)。双向链表的Java描述如下:
public class DoubleLinkedList<Item> { private Node first; private Node last; private int itemCount; private class Node { Node prev; Node next; Item item; } public void addFirst(Item item) { Node oldFirst = first; first = new Node(); first.item = item; first.next = oldFirst; if (oldFirst != null) { oldFirst.prev = first; } if (itemCount == 0) { last = first; } itemCount++; } public void addLast(Item item) { Node oldLast = last; last = new Node(); last.item = item; last.prev = oldLast; if (oldLast != null) { oldLast.next = last; } if (itemCount == 0) { first = last; } itemCount++; } public Item delFirst() { if (first == null) { throw new NullPointerException("No node in linked list."); } Item result = first.item; first = first.next; if (first != null) { first.prev = null; } if (itemCount == 1) { last = null; } itemCount--; return result; } public Item delLast() { if (last == null) { throw new NullPointerException("No node in linked list."); } Item result = last.item; last = last.prev; if (last != null) { last.next = null; } if (itemCount == 1) { first = null; } itemCount--; return result; } public void addBefore(Item targetItem, Item item) { //从头开始遍历寻找目标节点 Node target = first; if (target == null) { throw new NullPointerException("No node in linked list"); } while (target != null && target.item != targetItem) { //继续向后寻找目标节点 target = target.next; } if (target == null) { throw new NullPointerException("Can't find target node."); } //现在target为指向目标结点的引用 if (target.prev == null) { //此时相当于在表头插入结点 addFirst(item); } else { Node oldPrev = target.prev; Node newNode = new Node(); newNode.item = item; target.prev = newNode; newNode.next = target; newNode.prev = oldPrev; oldPrev.next = newNode; itemCount++; } } public void addAfter(Item targetItem, Item item) { Node target = first; if (target == null) { throw new NullPointerException("No node in linked list."); } while (target != null && target.item != targetItem) { target = target.next; } if (target == null) { throw new NullPointerException("Can't find target node."); } if (target.next == null) { addLast(item); } else { Node oldNext = target.next; Node newNode = new Node(); newNode.item = item; target.next = newNode; newNode.prev = target; newNode.next= oldNext; oldNext.prev = newNode; itemCount++; } } }
上面代码的逻辑都很直接,不过刚接触链表的小伙伴有时候可能容易感到有些迷糊,这时候一个好方法便是在拿出笔纸,画出链表操作相关结点的prev、next指针等的指向变化情况,这样链表相关的各类操作过程都能被非常直观的展现出来。
有一点需要我们注意的是,我们上面实现链表使用的是pointer wrapper方式,这种方式的特点是prev/next指针包含在结点中,而数据由结点中的另一个指针(即item)所引用。采取这种方式,在获取结点数据时,我们需要进行double-dereferencing,而且这种方式实现的链表不是一种[局部化结构],这意味着我们拿到链表的一个结点数据后,无法直接进行insert/delete操作。
另一种实现链表的方式是intrusive方式,这种方式实现的链表也就是intrusive linked list。这种链表的特点是data就是node,node就是data。使用这种链表,我们在获取data时,无需double-dereferencing,并且intrusive linked list是一种局部结构。
三、链表的特性
1. 优点
链表的主要优势有两点:一是插入及删除操作的时间复杂度为O(1);二是可以动态改变大小。
2. 缺点
由于其链式存储的特性,链表不具备良好的空间局部性,也就是说,链表是一种缓存不友好的数据结构。
四、小试牛刀之经典面试题
下面我们从《剑指Offer》中挑出几道关于链表的经典面试题来进一步巩固我们对链表相关技术点的掌握。
1. 输入一个链表,输出该链表中倒数第k个结点。
这道题给我们的框架如下,我们要做的是在这个框架中编程来实现从头到尾打印链表:
/* public class ListNode { int val; ListNode next = null; ListNode(int val) { this.val = val; } }*/ public class Solution { public ListNode FindKthToTail(ListNode head,int k) { } }
首先我们可以看到这里面表示链表的是ListNode类,这对应着我们上面的单链表实现中的Node类。实际上,这道题的难度要比我们上面实现的DoubleLinkedList中的addBefore/addAfter方法的难度要小。
我想到的一种直接解法如下:(如有问题希望大家可以指出)
public class Solution { public ListNode FindKthToTail(ListNode head,int k) { //先求得链表的尺寸,赋值给size int size = 0; ListNode current = head; while (current != null) { size++; current = current.next; } //获取next实例域size-k次,即可得到倒数第k个结点(从1开始计数) for (int i = 0; i < size - k; i++) { head = head.next; } return head; } }
2. 反转链表
本题的要求是输入一个链表,反转链表后,输出链表的所有元素。这道题的实现也比较直接,如以下代码所示:
public ListNode ReverseList(ListNode head) { if (head == null) { return null; } ListNode current = head; //原head的next node为null ListNode prevNode = null; ListNode newHead = null; while (current != null) { ListNode nextNode = current.next; current.next = prevNode; if (nextNode == null) { newHead = current; } prevNode = current; current = nextNode; } return newHead; }
这里只是从剑指Offer中找了两道关于链表的题来练手,以后会陆续在上面提到的项目地址跟大家分享更多的经常被用来作为一线互联网公司面试/笔试题的题目,这样在巩固自己算法基本功的同时,在面试/笔试时也能够更加得心应手。
转载于:https://www.cnblogs.com/absfree/p/5463372.html
最后
以上就是负责蜻蜓最近收集整理的关于深入理解数据结构之链表一、什么是链表二、链表的实现 三、链表的特性四、小试牛刀之经典面试题的全部内容,更多相关深入理解数据结构之链表一、什么是链表二、链表内容请搜索靠谱客的其他文章。








发表评论 取消回复