第13章 可扩展性设计之 MySQL Replication
前言:
MySQL Replication 是 MySQL 非常有特色的一个功能,他能够将一个 MySQL Server 的 Instance 中的数据完整的复制到另外一个 MySQL Server 的 Instance 中。虽然复制过程并不是实时而是异步进行的,但是由于其高效的性能设计,延时非常之少。MySQL 的Replication 功能在实际应用场景中被非常广泛的用于保证系统数据的安全性和系统可扩展设计中。本章将专门针对如何利用 MySQL 的 Replication 功能来提高系统的扩展性进行详细的介绍。
13.1 Replication 对可扩展性设计的意义
在互联网应用系统中,扩展最为方便的可能要数最基本的 Web 应用服务了。因为 Web应用服务大部分情况下都是无状态的,也很少需要保存太多的数据,当然 Session 这类信息比较例外。所以,对于基本的 Web 应用服务器很容易通过简单的添加服务器并复制应用程序来做到 Scale Out。
而数据库由于其特殊的性质,就不是那么容易做到方便的 Scale Out。当然,各个数据库厂商也一直在努力希望能够做到自己的数据库软件能够像常规的应用服务器一样做到方便的 Scale Out,也确实做出了一些功能,能够基本实现像 Web 应用服务器一样的Scalability,如很多数据库所支持的逻辑复制功能。
MySQL 数据库也为此做出了非常大的努力,MySQL Replication 功能主要就是基于这一目的所产生的。通过 MySQL 的 Replication 功能,我们可以非常方便的将一个数据库中的数据复制到很多台 MySQL 主机上面,组成一个 MySQL 集群,然后通过这个 MySQL 集群来对外提供服务。这样,每台 MySQL 主机所需要承担的负载就会大大降低,整个 MySQL 集群的处理能力也很容易得到提升。
为什么通过 MySQL 的 Replication 可以做到 Scale Out 呢?主要是因为通过 MySQL的 Replication,可以将一台 MySQL 中的数据完整的同时复制到多台主机上面的 MySQL 数据库中,并且正常情况下这种复制的延时并不是很长。当我们各台服务器上面都有同样的数据之后,应用访问就不再只能到一台数据库主机上面读取数据了,而是访问整个 MySQL 集群中的任何一台主机上面的数据库都可以得到相同的数据。此外还有一个非常重要的因素就是 MySQL 的复制非常容易实施,也非常容易维护。这一点对于实施一个简单的分布式数据库集群是非常重要的,毕竟一个系统实施之后的工作主要就是维护了,一个维护复杂的系统肯定不是一个受欢迎的系统。
13.2 Replication 机制的实现原理
要想用好一个系统,理解其实现原理是非常重要的事情,只有理解了其实现原理,我们才能够扬长避短,合理的利用,才能够搭建出最适合我们自己应用环境的系统,才能够在系统实施之后更好的维护他。
下面我们分析一下 MySQL Replication的实现原理。
13.2.1 Replication 线程
Mysql的 Replication 是一个异步的复制过程,从一个 Mysql instace(我们称之为Master)复制到另一个 Mysql instance(我们称之 Slave)。在 Master 与 Slave 之间的实现整个复制过程主要由三个线程来完成,其中两个线程(Sql线程和IO线程)在 Slave 端, 另外一个线程(IO线程)在 Master 端。
要实现 MySQL 的 Replication ,首先必须打开 Master 端的Binary Log(mysql-bin.xxxxxx)功能,否则无法实现。因为整个复制过程实际上就是Slave从Master端获取该日志然后再在自己身上完全顺序的执行日志中所记录的各种操作。打开 MySQL 的 Binary Log 可以通过在启动 MySQL Server 的过程中使用“—log-bin” 参数选项,或者在 my.cnf 配置文件中的 mysqld 参数组([mysqld]标识后的参数部分)增加 “log-bin” 参数项。
MySQL 复制的基本过程如下:
1. Slave 上面的IO线程连接上 Master,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容;
2. Master 接收到来自 Slave 的 IO 线程的请求后,通过负责复制的 IO 线程根据请求信息读取指定日志指定位置之后的日志信息,返回给 Slave 端的 IO 线程。返回信息中除了日志所包含的信息之外,还包括本次返回的信息在 Master 端的 Binary Log 文件的名称以及在 Binary Log 中的位置;
3. Slave 的 IO 线程接收到信息后,将接收到的日志内容依次写入到 Slave 端的 Relay Log文件(mysql-relay-bin.xxxxxx)的最末端,并将读取到的Master端的bin-log的文件名和位置记录到master-info文件中,以便在下一次读取的时候能够清楚的高速Master“我需要从某个bin-log的哪个位置开始往后的日志内容,请发给我”
4. Slave 的 SQL 线程检测到 Relay Log 中新增加了内容后,会马上解析该 Log 文件中的内容成为在 Master 端真实执行时候的那些可执行的 Query 语句,并在自身执行这些 Query。这样,实际上就是在 Master 端和 Slave 端执行了同样的 Query,所以两端的数据是完全一样的。
实际上,在老版本中,MySQL 的复制实现在 Slave 端并不是由 SQL 线程和 IO 线程这两个线程共同协作而完成的,而是由单独的一个线程来完成所有的工作。但是 MySQL 的工程师们很快发现,这样做存在很大的风险和性能问题,主要如下:
首先,如果通过一个单一的线程来独立实现这个工作的话,就使复制 Master 端的, Binary Log日志,以及解析这些日志,然后再在自身执行的这个过程成为一个串行的过程, 性能自然会受到较大的限制,这种架构下的 Replication 的延迟自然就比较长了。
其次,Slave 端的这个复制线程从 Master 端获取 Binary Log 过来之后,需要接着解析这些内容,还原成 Master 端所执行的原始 Query,然后在自身执行。在这个过程中, Master端很可能又已经产生了大量的变化并生成了大量的 Binary Log 信息。如果在这个阶段 Master 端的存储系统出现了无法修复的故障,那么在这个阶段所产生的所有变更都将永远的丢失,无法再找回来。这种潜在风险在Slave 端压力比较大的时候尤其突出,因为如果 Slave 压力比较大,解析日志以及应用这些日志所花费的时间自然就会更长一些,可能丢失的数据也就会更多。
所以,在后期的改造中,新版本的 MySQL 为了尽量减小这个风险,并提高复制的性能, 将 Slave 端的复制改为两个线程来完成,也就是前面所提到的 SQL 线程和 IO 线程。最早提出这个改进方案的是Yahoo!的一位工程师“Jeremy Zawodny”。通过这样的改造,这样既在很大程度上解决了性能问题,缩短了异步的延时时间,同时也减少了潜在的数据丢失量。
当然,即使是换成了现在这样两个线程来协作处理之后,同样也还是存在 Slave 数据延时以及数据丢失的可能性的,毕竟这个复制是异步的。只要数据的更改不是在一个事务中, 这些问题都是存在的。
如果要完全避免这些问题,就只能用 MySQL 的 Cluster 来解决了。不过 MySQL的Cluster 知道笔者写这部分内容的时候,仍然还是一个内存数据库的解决方案,也就是需要将所有数据包括索引全部都 Load 到内存中,这样就对内存的要求就非常大的大,对于一般的大众化应用来说可实施性并不是太大。当然,在之前与 MySQL 的 CTO David 交流的时候得知,MySQL 现在正在不断改进其 Cluster 的实现,其中非常大的一个改动就是允许数据不用全部 Load 到内存中,而仅仅只是索引全部 Load 到内存中,我想信在完成该项改造之后的 MySQL Cluster 将会更加受人欢迎,可实施性也会更大。
13.2.2 复制实现级别
MySQL 的复制可以是基于一条语句(Statement Level),也可以是基于一条记录(Row level),可以在 MySQL 的配置参数中设定这个复制级别,不同复制级别的设置会影响到Master 端的 Binary Log 记录成不同的形式。
1. Row Level:Binary Log 中会记录成每一行数据被修改的形式,然后在 Slave 端再对相同的数据进行修改。
优点:在 Row Level 模式下,Binary Log 中可以不记录执行的sql语句的上下文相关的信息,仅仅只需要记录那一条记录被修改了,修改成什么样了。所以 Row Level 的日志内容会非常清楚的记录下每一行数据修改的细节,非常容易理解。而且不会出现某些特定情况下的存储过程,或function,以及trigger的调用和触发无法被正确复制的问题。
缺点:Row Level下,所有的执行的语句当记录到 Binary Log 中的时候,都将以每行记录的修改来记录,这样可能会产生大量的日志内容,比如有这样一条update语句:UPDATE group_message SET group_id = 1 where group_id = 2,执行之后,日志中记录的不是这条update语句所对应的事件(MySQL以事件的形式来记录 Binary Log 日志),而是这条语句所更新的每一条记录的变化情况,这样就记录成很多条记录被更新的很多个事件。自然,
Binary Log 日志的量就会很大。尤其是当执行ALTER TABLE 之类的语句的时候,产生的日志量是惊人的。因为MySQL对于 ALTER TABLE 之类的 DDL 变更语句的处理方式是重建整个表的所有数据,也就是说表中的每一条记录都需要变动,那么该表的每一条记录都会被记录到日志中。
2. Statement Level:每一条会修改数据的 Query 都会记录到 Master的 Binary Log 中。Slave在复制的时候 SQL 线程会解析成和原来 Master 端执行过的相同的 Query 来再次执行。
优点:Statement Level下的优点首先就是解决了Row Level下的缺点,不需要记录每一行数据的变化,减少 Binary Log 日志量,节约了 IO 成本,提高了性能。因为他只需要记录在Master上所执行的语句的细节,以及执行语句时候的上下文的信息。
缺点:由于他是记录的执行语句,所以,为了让这些语句在slave端也能正确执行,那么他还必须记录每条语句在执行的时候的一些相关信息,也就是上下文信息,以保证所有语句在slave端杯执行的时候能够得到和在master端执行时候相同的结果。另外就是,由于Mysql现在发展比较快,很多的新功能不断的加入,使mysql得复制遇到了不小的挑战,自然复制的时候涉及到越复杂的内容,bug也就越容易出现。在statement level下,目前已经发现的就有不少情况会造成mysql的复制出现问题,主要是修改数据的时候使用了某些特定的函数或者功能的时候会出现,比如:sleep()函数在有些版本中就不能真确复制,在存储过程中使用了last_insert_id()函数,可能会使slave和master上得到不一致的id等等。由于row level是基于每一行来记录的变化,所以不会出现类似的问题。
从官方文档中看到,之前的 MySQL 一直都只有基于 Statement 的复制模式,直到5.1.5版本的 MySQL 才开始支持Row Level的复制。从5.0开始,MySQL 的复制已经解决了大量老版本中出现的无法正确复制的问题。但是由于存储过程的出现,给 MySQL 的复制又带来了更大的新挑战。另外,看到官方文档说,从5.1.8版本开始,MySQL 提供了除Statement Level和Row Level之外的第三种复制模式:Mixed Level,实际上就是前两种模式的结合。在Mixed模式下,MySQL会根据执行的每一条具体的 Query 语句来区分对待记录的日志形式,也就是在Statement和Row之间选择一种。新版本中的Statment level 还是和以前一样,仅仅记录执行的语句。而新版本的Mysql中队Row Level模式也被做了优化,并不是所有的修改都会以Row Level来记录,像遇到表结构变更的时候就会以statement 模式来记录,如果 Query 语句确实就是 UPDATE 或者 DELETE 等修改数据的语句,那么还是会记录所有行的变更。
13.3 Replication常用架构
MySQL Replicaion 本身是一个比较简单的架构,就是一台 MySQL 服务器(Slave)从另一台 MySQL 服务器(Master)进行日志的复制然后再解析日志并应用到自身。一个复制环境仅仅只需要两台运行有 MySQL Server 的主机即可,甚至更为简单的时候我们可以在同一台物理服务器主机上面启动两个 mysqld instance,一个作为 Master 而另一个作为Slave 来完成复制环境的搭建。但是在实际应用环境中,我们可以根据实际的业务需求利用MySQL Replication 的功能自己定制搭建出其他多种更利于 Scale Out 的复制架构。如Dual Master 架构,级联复制架构等。下面我们针对比较典型的三种复制架构进行一些相应的分析介绍。
13.3.1 常规复制架构(Master - Slaves)
在实际应用场景中,MySQL 复制90% 以上都是一个Master 复制到一个或者多个Slave的架构模式,主要用于读压力比较大的应用的数据库端廉价扩展解决方案。因为只要Master 和 Slave 的压力不是太大(尤其是 Slave 端压力)的话,异步复制的延时一般都很少很少。尤其是自从Slave端的复制方式改成两个线程处理之后,更是减小了 Slave 端的延时问题。而带来的效益是,对于数据实时性要求不是特别 Critical 的应用,只需要通过廉价的pc server来扩展 Slave 的数量,将读压力分散到多台 Slave 的机器上面,即可通过分散单台数据库服务器的读压力来解决数据库端的读性能瓶颈,毕竟在大多数数据库应用系统中的读压力还是要比写压力大很多。这在很大程度上解决了目前很多中小型网站的数据库压力瓶颈问题,甚至有些大型网站也在使用类似方案解决数据库瓶颈。
这个架构可以通过下图比较清晰的展示:

一个Master复制多个 Slave 的架构实施非常简单,多个 Slave 和单个 Slave的实施并没有实质性的区别。在 Master 端并不 Care 有多少个 Slave 连上了自己,只要有 Slave 的 IO 线程通过了连接认证,向他请求指定位置之后的 Binary Log 信息,他就会按照该IO线程的要求,读取自己的 Binary Log 信息,返回给 Slave 的 IO 线程。
大家应该都比较清楚,从一个 Master 节点可以复制出多个 Slave 节点,可能有人会想,那一个 Slave 节点是否可以从多个 Master 节点上面进行复制呢?至少在目前来看, MySQL 是做不到的,以后是否会支持就不清楚了。
MySQL 不支持一个 Slave 节点从多个 Master 节点来进行复制的架构,主要是为了避免冲突的问题,防止多个数据源之间的数据出现冲突,而造成最后数据的不一致性。不过听说已经有人开发了相关的 patch,让 MySQL 支持一个 Slave 节点从多个 Master 结点作为数据源来进行复制,这也正是 MySQL 开源的性质所带来的好处。
对于 Replication 的配置细节,在 MySQL 的官方文档上面已经说的非常清楚了,甚至介绍了多种实现 Slave 的配置方式,在下一节中我们也会通过一个具体的示例来演示搭建一个 Replication 环境的详细过程以及注意事项。
13.3.2 Dual Master 复制架构(Master - Master)
有些时候,简单的从一个 MySQL 复制到另外一个 MySQL 的基本 Replication 架构, 可能还会需要在一些特定的场景下进行 Master 的切换。如在 Master 端需要进行一些特别的维护操作的时候,可能需要停 MySQL 的服务。这时候,为了尽可能减少应用系统写服务的停机时间,最佳的做法就是将我们的 Slave 节点切换成 Master 来提供写入的服务。
但是这样一来,我们原来 Master 节点的数据就会和实际的数据不一致了。当原 Master 启动可以正常提供服务的时候,由于数据的不一致,我们就不得不通过反转原 Master - Slave 关系,重新搭建 Replication 环境,并以原 Master 作为 Slave 来对外提供读的服务。重新搭建 Replication 环境会给我们带来很多额外的工作量,如果没有合适的备份,可能还会让 Replication 的搭建过程非常麻烦。
为了解决这个问题,我们可以通过搭建 Dual Master 环境来避免很多的问题。何谓Dual Master 环境?实际上就是两个 MySQL Server 互相将对方作为自己的 Master,自己作为对方的 Slave 来进行复制。这样,任何一方所做的变更,都会通过复制应用到另外一方的数据库中。
可能有些读者朋友会有一个担心,这样搭建复制环境之后,难道不会造成两台 MySQL 之 间的循环复制么?实际上 MySQL 自己早就想到了这一点,所以在 MySQL 的 Binary Log 中 记录了当前 MySQL 的 server-id,而且这个参数也是我们搭建 MySQL Replication 的时候必须明确指定,而且 Master 和 Slave 的 server-id 参数值比需要不一致才能使 MySQL Replication 搭建成功。一旦有了 server-id 的值之后,MySQL 就很容易判断某个变更是从哪一个 MySQL Server 最初产生的,所以就很容易避免出现循环复制的情况。而且,如果我们不打开记录 Slave 的 Binary Log 的选项(--log-slave-update)的时候,MySQL 根本就不会记录复制过程中的变更到 Binary Log 中,就更不用担心可能会出现循环复制的情形了。
下如将更清晰的展示 Dual Master 复制架构组成:
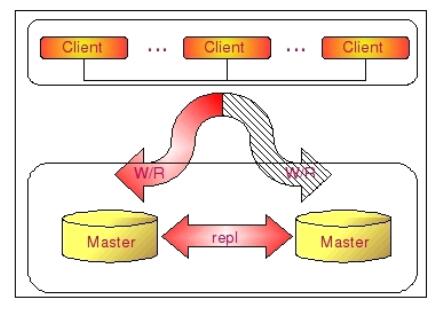
通过 Dual Master 复制架构,我们不仅能够避免因为正常的常规维护操作需要的停机所带来的重新搭建 Replication 环境的操作,因为我们任何一端都记录了自己当前复制到对方的什么位置了,当系统起来之后,就会自动开始从之前的位置重新开始复制,而不需要人为去进行任何干预,大大节省了维护成本。
不仅仅如此,Dual Master 复制架构和一些第三方的 HA 管理软件结合,还可以在我们当前正在使用的 Master 出现异常无法提供服务之后,非常迅速的自动切换另外一端来提供相应的服务,减少异常情况下带来的停机时间,并且完全不需要人工干预。
当然,我们搭建成一个 Dual Master 环境,并不是为了让两端都提供写的服务。在正常情况下,我们都只会将其中一端开启写服务,另外一端仅仅只是提供读服务,或者完全不提供任何服务,仅仅只是作为一个备用的机器存在。为什么我们一般都只开启其中的一端来提供写服务呢?主要还是为了避免数据的冲突,防止造成数据的不一致性。因为即使在两边执行的修改有先后顺序,但由于 Replication 是异步的实现机制,同样会导致即使晚做的修改也可能会被早做的修改所覆盖,就像如下情形:
| 时间点 | MySQL A | MySQL B |
| 1 | 更新x表y记录为10 | |
| 2 | 更新x表y记录为20 | |
| 3 | 获取到A日志并应用,更新x表的y记录为10(不符合期望) | |
| 4 | 获取B日志更新x表y记录为20(符合期望) |
这中情形下,不仅在B库上面的数据不是用户所期望的结果,A和B两边的数据也出现了不一致。
当然,我们也可以通过特殊的约定,让某些表的写操作全部在一端,而另外一些表的写操作全部在另外一端,保证两端不会操作相同的表,这样就能避免上面问题的发生了。
13.3.3 级联复制架构(Master - Slaves - Slaves ...)
在有些应用场景中,可能读写压力差别比较大,读压力特别的大,一个 Master 可能需要上10台甚至更多的 Slave 才能够支撑注读的压力。这时候,Master 就会比较吃力了, 因为仅仅连上来的 Slave IO 线程就比较多了,这样写的压力稍微大一点的时候,Master 端因为复制就会消耗较多的资源,很容易造成复制的延时。
遇到这种情况如何解决呢?这时候我们就可以利用 MySQL 可以在 Slave 端记录复制所产生变更的 Binary Log 信息的功能,也就是打开 —log-slave-update 选项。然后,通过二级(或者是更多级别)复制来减少 Master 端因为复制所带来的压力。也就是说,我们首先通过少数几台 MySQL 从 Master 来进行复制,这几台机器我们姑且称之为第一级Slave 集群,然后其他的 Slave 再从第一级 Slave 集群来进行复制。从第一级 Slave 进行复制的 Slave,我称之为第二级 Slave 集群。如果有需要,我们可以继续往下增加更多层次的复制。这样,我们很容易就控制了每一台 MySQL 上面所附属 Slave 的数量。这种架构我称之为 Master - Slaves - Slaves 架构这种多层级联复制的架构,很容易就解决了 Master 端因为附属 Slave 太多而成为瓶颈的风险。下图展示了多层级联复制的 Replication 架构。
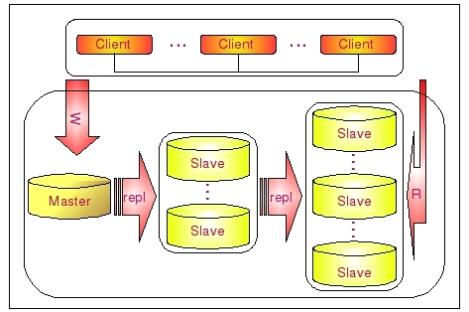
当然,如果条件允许,我更倾向于建议大家通过拆分成多个 Replication 集群来解决上述瓶颈问题。毕竟 Slave 并没有减少写的量,所有 Slave 实际上仍然还是应用了所有的数据变更操作,没有减少任何写 IO。相反,Slave 越多,整个集群的写 IO 总量也就会越多,我们没有非常明显的感觉,仅仅只是因为分散到了多台机器上面,所以不是很容易表现出来。
此外,增加复制的级联层次,同一个变更传到最底层的 Slave 所需要经过的 MySQL 也会更多,同样可能造成延时较长的风险。
而如果我们通过分拆集群的方式来解决的话,可能就会要好很多了,当然,分拆集群也需要更复杂的技术和更复杂的应用系统架构。
13.3.4 Dual Master 与级联复制结合架构(Master - Master - Slaves)
级联复制在一定程度上面确实解决了 Master 因为所附属的 Slave 过多而成为瓶颈的问题,但是他并不能解决人工维护和出现异常需要切换后可能存在重新搭建 Replication 的问题。这样就很自然的引申出了 Dual Master 与级联复制结合的 Replication 架构,我称之为 Master - Master - Slaves 架构和 Master - Slaves - Slaves 架构相比,区别仅仅只是将第一级 Slave 集群换成了一台单独的 Master,作为备用 Master,然后再从这个备用的 Master 进行复制到一个Slave 集群。下面的图片更清晰的展示了这个架构的组成:

这种 Dual Master 与级联复制结合的架构,最大的好处就是既可以避免主 Master 的写入操作不会受到 Slave 集群的复制所带来的影响,同时主 Master 需要切换的时候也基本上不会出现重搭 Replication 的情况。但是,这个架构也有一个弊端,那就是备用的Master 有可能成为瓶颈,因为如果后面的 Slave 集群比较大的话,备用 Master 可能会因为过多的 Slave IO 线程请求而成为瓶颈。当然,该备用 Master 不提供任何的读服务的时候,瓶颈出现的可能性并不是特别高,如果出现瓶颈,也可以在备用 Master 后面再次进行级联复制,架设多层 Slave 集群。当然,级联复制的级别越多,Slave 集群可能出现的数据延时也会更为明显,所以考虑使用多层级联复制之前,也需要评估数据延时对应用系统的影响。
13.4 Replication 搭建实现
MySQL Replication环境的搭建实现比较简单,总的来说其实就是四步,第一步是做好Master 端的准备工作。第二步是取得 Master 端数据的“快照”备份。第三步则是在 Slave端恢复 Master 的备份“快照”。第四步就是在 Slave 端设置 Master 相关配置,然后启动复制。在这一节中,并不是列举一个搭建 Replication 环境的详细过程,因为这在 MySQL 官方操作手册中已经有较为详细的描述了,我主要是针对搭建环境中几个主要的操作步骤中可以使用的各种实现方法的介绍,下面我们针对这四步操作及需要注意的地方进行一个简单的分析。
1. Master 端准备工作
在搭建 Replication 环境之前,首先要保证 Master 端 MySQL 记录 Binary Log 的选项打开,因为 MySQL Replication 就是通过 Binary Log 来实现的。让 Master 端 MySQL 记录 Binary Log 可以在启动 MySQL Server 的时候使用 —log-bin 选项或者在 MySQL 的配置文件 my.cnf 中配置 log-bin[=path for binary log]参数选项。
在开启了记录 Binary Log 功能之后,我们还需要准备一个用于复制的 MySQL 用户。
可以通过给一个现有帐户授予复制相关的权限,也可以创建一个全新的专用于复制的帐户。
当然,我还是建议用一个专用于复制的帐户来进行复制。在之前“MySQL 安全管理”部分也 已经介绍过了,通过特定的帐户处理特定一类的工作,不论是在安全策略方面更有利,对于维护来说也有更大的便利性。实现 MySQL Replication 仅仅只需要“REPLICATION SLAVE” 权限即可。可以通过如下方式来创建这个用户:
root@localhost : mysql 04:16:18> CREATE USER 'repl'@'192.168.0.2'
-> IDENTIFIED BY 'password';
Query OK, 0 rows affected (0.00 sec)
root@localhost : mysql 04:16:34> GRANT REPLICATION SLAVE ON *.*
-> TO 'repl'@'192.168.0.2';
Query OK, 0 rows affected (0.00 sec)
这里首先通过 CREATE USER 命令创建了一个仅仅具有最基本权限的用户 repl,然后再通过 GRANT 命令授予该用户 REPLICATION SLAVE 的权限。当然,我们也可以仅仅执行上面的第二条命令,即可创建出我们所需的用户,这已经在“MySQL 安全管理”部分介绍过了。
2. 获取 Master 端的备份“快照”
这里所说的 Master 端的备份“快照”,并不是特指通过类似 LVM 之类的软件所做的 snapshot,而是所有数据均是基于某一特定时刻的,数据完整性和一致性都可以得到保证的备份集。同时还需要取得该备份集时刻所对应的 Master 端 Binary Log 的准确 Log Position,因为在后面配置 Slave 的时候会用到。 一般来说,我们可以通过如下集中办法获得一个具有一致性和完整性的备份集以及所对应的 Log Position:
◆ 通过数据库全库冷备份
对于可以停机的数据库,我们可以通过关闭 Master 端 MySQL,然后通过 copy 所有数据文件和日志文件到需要搭建 Slave 的主机中合适的位置,这样所得到的备份集是最完整的。在做完备份之后,然后再启动 Master 端的MySQL。
当然,这样我们还仅仅只是得到了一个满足要求的备份集,我们还需要这个备份集所对应的日志位置才能可以。对于这样的备份集,我们有多种方法可以获取到对应的日志位置。如在 Master 刚刚启动之后,还没有应用程序连接上 Master 之前,通过执行SHOW Master STATUS 命令从 Master端获取到我们可以使用的 Log Position。如果我们无法在 Master 启动之后控制应用程序的连接,那么可能在我们还没有来得及执行SHOW Master STATUS 命令之前就已经有数据写进来了,这时候我们可以通过mysqlbinlog 客户端程序分析 Master 最新的一个 Binary Log来获取其第一个有效的 Log Position。当然,如果你非常清楚你所使用的 MySQL 版本每一个新的 Binary Log 第一个有效的日志位置,自然就不需要进行任何操作就可以。
◆ 通过 LVM 或者 ZFS 等具有 snapshot 功能的软件进行“热备份”
如果我们的 Master 是一个需要满足 365 * 24 * 7 服务的数据库,那么我们就无法通过进行冷备份来获取所需要的备份集。这时候,如果我们的 MySQL 运行在支持
Snapshot 功能的文件系统上面(如 ZFS),或者我们的文件系统虽然不支持 Snapshot, 但是我们的文件系统运行在 LVM 上面,那么我们都可以通过相关的命令对 MySQL 的数据文件和日志文件所在的目录就做一个 Snapshot,这样就可以得到了一个基本和全库冷备差不多的备份集。
当然,为了保证我们的备份集数据能够完整且一致,我们需要在进行Snapshot过 程中通过相关命令(FLUSH TABLES WITH READ LOCK)来锁住所有表的写操作,也包括支持事务的存储引擎中commit动作,这样才能真正保证该 Snapshot的所有数据都完整一致。在做完 Snapshot 之后,我们就可以 UNLOCK TABLES 了。可能有些人会担心, 如果锁住了所有的写操作,那我们的应用不是就无法提供写服务了么?确实,这是无法避免的,不过,一般来说 Snapshot 操作所需要的时间大都比较短,所以不会影响太长时间。
那 Log Position 怎么办呢?是的,通过 Snapshot 所做的备份,同样需要一个该备份所对应的 Log Position 才能满足搭建 Replication 环境的要求。不过,这种方式下,我们可以比进行冷备份更容易获取到对应的 Log Position。因为从我们锁定了所有表的写入操作开始到解锁之前,数据库不能进行任何写入操作,这个时间段之内任何时候通过执行 SHOW MASTER STATUS 明令都可以得到准确的 Log Position。
由于这种方式在实施过程中并不需要完全停掉 Master 来进行,仅仅只需要停止写入才做,所以我们也可以称之为“热备份”。
◆ 通过 mysqldump 客户端程序
如果我们的数据库不能停机进行冷备份,而且 MySQL 也没有运行在可以进行Snapshot 的文件系统或者管理软件之上,那么我们就需要通过 mysqldump 工具来将Master 端需要复制的数据库(或者表)的数据 dump 出来。为了让我们的备份集具有一致性和完整性,我们必须让 dump 数据的这个过程处于同一个事务中,或者锁住所有需要复制的表的写操作。要做到这一点,如果我们使用的是支持事务的存储引擎(如Innodb),我们可以在执行 mysqldump 程序的时候通过添加 —single-transaction 选项来做到,但是如果我们的存储引擎并不支持事务,或者是需要 dump 表仅仅只有部分支持事务的时候,我们就只能先通过 FLUSH TABLES WITH READ LOCK 命令来暂停所有写入服务,然后再 dump 数据。当然,如果我们仅仅只需要 dump 一个表的数据,就不需要这么麻烦了,因为 mysqldump 程序在 dump 数据的时候实际上就是每个表通过一条 SQL 来得到数据的,所以单个表的时候总是可以保证所取数据的一致性的。
上面的操作我们还只是获得了合适的备份集,还没有该备份集所对应的 Log Position,所以还不能完全满足搭建 Slave 的要求。幸好 mysqldump 程序的开发者早就考虑到这个问题了,所以给 mysqldump 程序增加了另外一个参数选项来帮助我们获取到对应的 Log Position,这个参数选项就是 —master-data 。当我们添加这个参数选项之后,mysqldump会在 dump 文件中产生一条 CHANGE MASTER TO 命令,命令中记录了 dump时刻所对应的详细的 Log Position 信息。如下:
测试 dump example 数据库下的 group_message 表:
sky@sky:~$ mysqldump --master-data -usky -p example group_message >
group_message.sql
Enter password:
然后通过 grep 命令来查找一下看看:
sky@sky:~$ grep "CHANGE MASTER" group_message.sql
CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000035', MASTER_LOG_POS=399;
连 CHANGE MASTER TO 的命令都已经给我们准备好了,还真够体贴的,呵呵。
如果我们是要一次性 dump 多个支持事务的表的时候,可能很多人会选择通过添加—single-transaction 选项来保证数据的一致性和完整性。这确实是一个不错的选择。
但是,如果我们需要 dump 的数据量比较大的时候,可能会产生一个很大的事务,而且会持续较长的时间。
◆ 通过现有某一个 Slave 端进行“热备份”
如果现在已经有 Slave 从我们需要搭建 Replication 环境的 Master 上进行复制的话,那我们这个备份集就非常容易取得了。我们可以暂时性的停掉现有 Slave(如果有多台则仅仅只需要停止其中的一台),同时执行一次 FLUSH TABLES 命令来刷新所有表和索引的数据。这时候在该 Slave 上面就不会再有任何的写入操作了,我们既可以通过 copy 所有的数据文件和日志文件来做一个全备份,同时也可以通过 Snapshot(如果支持)来进行备份。当然,如果支持 Snapshot功能,还是建议大家通过 Snapshot 来做,因为这样可以使 Slave 停止复制的时间大大缩短,减少该 Slave 的数据延时。
通过现有 Slave 来获取备份集的方式,不仅仅得到数据库备份的方式很简单,连所需要 Log Position,甚至是新 Slave 后期的配置等相关动作都可以省略掉,只需要新的 Slave 完全基于这个备份集来启动,就可以正常从 Master 进行复制了。
整个过程中我们仅仅只是在短暂时间内停止了某台现有 Slave 的复制线程,对系统的正常服务影响很小,所以这种方式也基本可以称之为“热备份”。
3. 通过 Slave 端恢复备份“快照”
上面第二步我们已经获取到了所需要的备份集了,这一步所需要做的就是将上一步所得到的备份集恢复到我们的 Slave 端的 MySQL 中。
针对上面四种方法所获取的备份集的不同,在 Slave 端的恢复操作也有区别。下面就针对四种备份集的恢复做一个简单的说明:
◆ 恢复全库冷备份集
由于这个备份集是一个完整的数据库物理备份,我们仅仅只需要将这个备份集通过FTP 或者是 SCP 之类的网络传输软件复制到 Slave 所在的主机,根据 Slave 上my.cnf 配置文件的设置,将文件存放在相应的目录,覆盖现有所有的数据和日志等相关文件,然后再启动 Slave 端的 MySQL,就完成了整个恢复过程。
◆ 恢复对 Master 进行 Snapshot 得到的备份集
对于通过对 Master 进行 Snapshot 所得到的备份集,实际上和全库冷备的恢复方法基本一样,唯一的差别只是首先需要将该 Snapshot 通过相应的文件系统 mount 到某个目录下,然后才能进行后续的文件拷贝操作。之后的相关操作和恢复全库冷备份集基本一致,就不再累述。
◆ 恢复 mysqldump 得到的备份集
通过 mysqldump 客户端程序所得到的备份集,和前面两种备份集的恢复方式有较大的差别。因为前面两种备份集的都属于物理备份,而通过 mysqldump 客户端程序所做的备份属于逻辑备份。恢复 mysqldump 备份集的方式是通过 mysql 客户端程序来执行备份文件中的所有 SQL 语句。
使用 mysql 客户端程序在 Slave 端恢复之前,建议复制出通过 —master-data 所得到的 CHANGE MASTER TO 命令部分,然后在备份文件中注销掉该部分,再进行恢复。
因为该命令并不是一个完整的 CHANGE MASTER TO 命令,如果在配置文件(my.cnf)中没有配置MASTER_HOST,MASTER_USER,MASTER_PASSWORD 这三个参数的时候,该语句是无法有效完成的。
通过 mysql 客户端程序来恢复备份的方式如下:
sky@sky:~$ mysql -u sky -p -Dexample < group_message.sql
这样即可将之前通过 mysqldump 客户端程序所做的逻辑备份集恢复到数据库中了。
◆ 恢复通过现有 Slave 所得到的热备份
通过现有 Slave 所得到的备份集和上面第一种或者第二种备份集也差不多。如果是通过直接拷贝数据和日志文件所得到的备份集,那么就和全库冷备一样的备份方式,如果是通过 Snapshot 得到的备份集,就和第二种备份恢复方式完全一致。
4. 配置并启动 Slave
在完成了前面三个步骤之后, Replication 环境的搭建就只需要最后的一个步骤了,那就是通过 CHANGE MASTER TO 命令来配置 然后再启动 Slave 了。
CHANGE MASTER TO 命令总共需要设置5项内容,分别为:
MASTER_HOST:Master 的主机名(或者 IP 地址);
MASTER_USER:Slave 连接 Master 的用户名,实际上就是之前所创建的 repl 用户;
MASTER_PASSWORD:Slave 连接 Master 的用户的密码;
MASTER_LOG_FILE:开始复制的日志文件名称;
MASTER_LOG_POS:开始复制的日志文件的位置,也就是在之前介绍备份集过程中一致提到的 Log Position。
下面是一个完整的 CHANGE MASTER TO 命令示例:
CHANGE MASTER TO
root@localhost : mysql 08:32:38> CHANGE MASTER TO
-> MASTER_HOST='192.168.0.1',
-> MASTER_USER='repl',
-> MASTER_PASSWORD='password',
-> MASTER_LOG_FILE='mysql-bin.000035',
-> MASTER_LOG_POS=399;
执行完 CHANGE MASTER TO 命令之后,就可以通过如下命令启动 SLAVE 了:
root@localhost : mysql 08:33:49> START SLAVE;
至此,我们的 Replication 环境就搭建完成了。读者朋友可以自己进行相应的测试来尝试搭建,如果需要了解 MySQL Replication搭建过程中更为详细的步骤,可以通过查阅MySQL 官方手册。
13.5 小结
在实际应用场景中,MySQL Replication 是使用最为广泛的一种提高系统扩展性的设计手段。众多的 MySQL 使用者通过 Replication 功能提升系统的扩展性之后,通过简单的增加价格低廉的硬件设备成倍甚至成数量级的提高了原有系统的性能,是广大 MySQL 中低端使用者最为喜爱的功能之一,也是大量 MySQL 使用者选择 MySQL 最为重要的理由之一。
摘自:《MySQL性能调优与架构设计》简朝阳
转载请注明出处:
作者:JesseLZJ
出处:http://jesselzj.cnblogs.com
转载于:https://www.cnblogs.com/jesselzj/p/5584245.html
最后
以上就是无限衬衫最近收集整理的关于MySQL性能调优与架构设计——第13章 可扩展性设计之 MySQL Replication的全部内容,更多相关MySQL性能调优与架构设计——第13章内容请搜索靠谱客的其他文章。








发表评论 取消回复