脑图
从LR到决策树
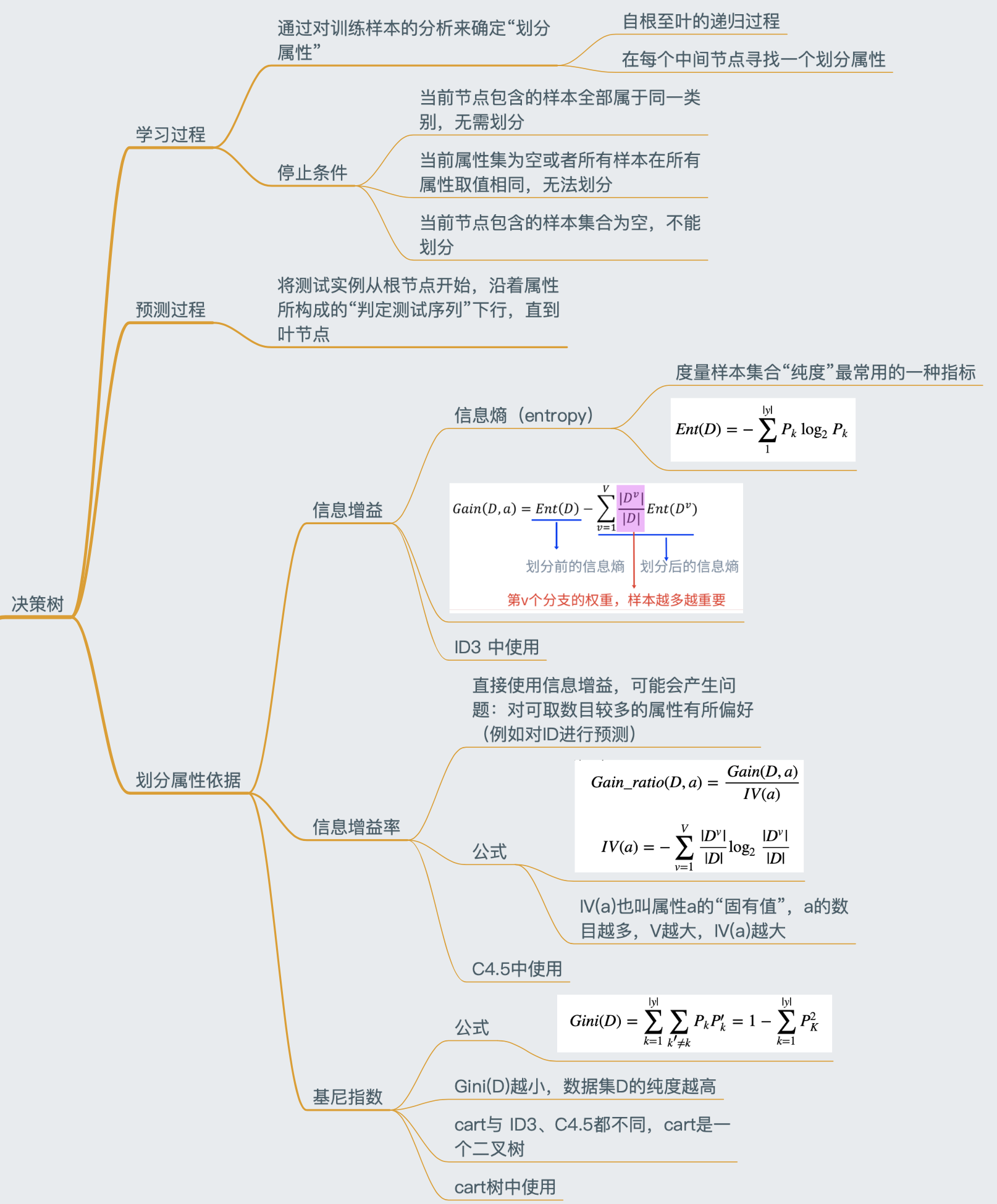
总体流程与核心问题
- 总体流程 : 分而治之 divide-and-conquer
- 自根至叶的递归过程
- 在每个中间节点寻找一个“划分”(split or test)属性
- 三种停止条件:
- 当前节点包含的样本全属于同一类别,无需划分(节点的一票否决权)
- 当前属性集为空,或者所有样本在所有属性上取值相同,无法划分(所有属性都一样,但是最后的结果又不同,无法区分了)
- 当前节点包含的样本集合为空,不能划分
下图摘自西瓜书,红底色文字就是决策树算法的核心:怎么选?

熵、信息增益、信息增益率
熵
信息熵(entropy)是度量样本集合“纯度”最常用的一种指标,假定当前样本集合D中第k类样本所占比例为
p
k
p_k
pk, 则D的信息熵定义为:
E
n
t
(
D
)
=
−
∑
1
∣
y
∣
P
k
log
2
P
k
Ent(D)=-sum_1^{|y|}P_klog_2P_k
Ent(D)=−1∑∣y∣Pklog2Pk
- 这里的 |y| 代表类别数量
- Ent(D)越小,则D的纯度越高
- Ent(D)的最小值时0,最大值是 log 2 ∣ y ∣ log_2|y| log2∣y∣
信息增益直接以信息熵为基础,计算当前划分对信息熵所造成的变化
最佳划分属性选择:信息增益(ID3)
信息增益 information gain:ID3中使用
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b9QZYqJR-1584930197120)(attachment:image.png)]](https://www.shuijiaxian.com/files_image/2023060522/20200323102351156.png)
【实例:西瓜书判断西瓜熟度】
最佳划分属性选择:信息增益率(C4.5)
使用信息增益有什么问题:对可取值数目较多的属性有所偏好(例如使用学号进行成绩区分,每一个学号下只有一个样本)
下面我们引入一个概念:信息增益率
G
a
i
n
_
r
a
t
i
o
(
D
,
a
)
=
G
a
i
n
(
D
,
a
)
I
V
(
a
)
Gain_ratio(D,a)=frac{Gain(D,a)}{IV(a)}
Gain_ratio(D,a)=IV(a)Gain(D,a)
其中,
I
V
(
a
)
=
−
∑
v
=
1
V
∣
D
v
∣
∣
D
∣
log
2
∣
D
v
∣
∣
D
∣
IV(a)=-sum_{v=1}^Vfrac{|D^v|}{|D|}log_2frac{|D^v|}{|D|}
IV(a)=−v=1∑V∣D∣∣Dv∣log2∣D∣∣Dv∣
IV(a)也叫属性a的“固有值”,a的数目越多,V越大,IV(a)越大,
1.2.4 最佳划分属性选择:基尼指数
分类与回归树 Cart - Classification and Rgression 中使用
定义基尼指数 Gini index :
G
i
n
i
(
D
)
=
∑
k
=
1
∣
y
∣
∑
k
′
≠
k
P
k
P
k
′
=
1
−
∑
k
=
1
∣
y
∣
P
K
2
Gini(D) = sum_{k=1}^{|y|}sum_{k'neq{k}}{P_k}{P_k'}=1-sum_{k=1}^{|y|}P_K^2
Gini(D)=k=1∑∣y∣k′=k∑PkPk′=1−k=1∑∣y∣PK2
Gini(D)越小,数据集D的纯度越高
属性a的基尼指数:
G
i
n
i
_
i
n
d
e
x
(
D
,
a
)
=
∑
v
=
1
V
∣
D
v
∣
∣
D
∣
G
i
n
i
(
D
v
)
Gini_index(D,a)=sum_{v=1}^{V}frac{|D^v|}{|D|}Gini(D^v)
Gini_index(D,a)=v=1∑V∣D∣∣Dv∣Gini(Dv)
在候选属性的集合中,选取使得划分后基尼指数最小的属性
cart与 ID3、C4.5都不同,cart是一个二叉树
基尼指数本质上与信息熵相同,推导:

写作不易,求电费

最后
以上就是深情戒指最近收集整理的关于【机器学习】决策树与树模型集成01-决策树脑图从LR到决策树写作不易,求电费的全部内容,更多相关【机器学习】决策树与树模型集成01-决策树脑图从LR到决策树写作不易内容请搜索靠谱客的其他文章。








发表评论 取消回复