Hinge loss
In machine learning, the hinge loss is a loss function used for training classifiers. The hinge loss is used for "maximum-margin" classification, most notably for support vector machines (SVMs).[1] For an intended output t = ±1 and a classifier score y, the hinge loss of the prediction y is defined as
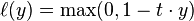
Note that y should be the "raw" output of the SVM's decision function, not the predicted class label. E.g., in linear SVMs,  .
.
It can be seen that when  and
and  have the same sign (meaning predicts the right class) and
have the same sign (meaning predicts the right class) and  ,
,  (one-sided error), but when they have opposite sign,
(one-sided error), but when they have opposite sign, increases linearly with .
increases linearly with .
Extensions[edit]
While SVMs are commonly extended to multiclass classification in a one-vs.-all or one-vs.-one fashion,[2] there exists a "true" multiclass version of the hinge loss due to Crammer and Singer,[3] defined for a linear classifier as[4]

In structured prediction, the hinge loss can be further extended to structured output spaces. Structured SVMs use the following variant, where w denotes the SVM's parameters, φ the joint feature function, and Δ the Hamming loss:[5]

Optimization[edit]
The hinge loss is a convex function, so many of the usual convex optimizers used in machine learning can work with it. It is not differentiable, but has asubgradient with respect to model parameters 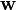 of a linear SVM with score function
of a linear SVM with score function 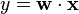 that is given by
that is given by
-
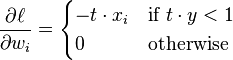
-
-
https://groups.google.com/forum/#!topic/theano-users/Y8lQqOzXC0A
- 由于hinge loss不是处处可导的。
-
Quick question: since hinge loss isn't differentiable, are there any
standard practices / suggestions on how to implement a loss function
that might incorporate a max{0,something} in theano that can still be automatically differentiable? I'm thinking maybe evaluate a scalar
cost on the penultimate layer of the network and *hack* a loss function to arrive at a scalar loss?
-
I know of two differentiable functions that approximate the behavior
of max{0,x}. One is:{log(1 + e^(x*N)) / N} -> max{0,x} as N->inf
The other is the activation function Geoff Hinton uses for rectified
As a side note, in case anyone is curious where the crossover is:
linear units.log(1 + e^(x)) is the anti-derivative of the logistic function,
whereas RLUs are a form of integration that when carried out
infinitely will asymptotically approach the same behavior as log(1 +
e^(x)). That's the link between them.-Brian
Thanks Brian, I actually ended up switching to a log-loss...
log(1 + exp( (m - x) * N)) / (m * N)
as an approximation to the margin loss I wanted,
max(0, m - x)
and everything's looking good / behaving nicely.
-Eric
-
最后
以上就是积极香水最近收集整理的关于Hinge loss Hinge loss的全部内容,更多相关Hinge内容请搜索靠谱客的其他文章。








发表评论 取消回复