文章目录
- 案例分析
- 前言
- 数据分析流程
- 环境准备
- 软件要求
- 硬件要求
- 环境搭建
案例分析
前言
通过本案例,你可以:
- 熟悉在
Linux系统中安装Hadoop集群、安装Mysql数据库,安装Sqoop数据迁移工具,安装Spark,安装Hive数据仓库。 - 在
HDFS分布式文件系统中创建文件夹、上传文件。 - 在
Hive中建立表,使用Hive对HDFS中的文件进行操作,使用HQL进行业务查询。 - 使用
Sqoop将Hive中的数据迁移到Mysql中。 - 了解
Spark的MLlib自带的工具,使用Spark-Shell编程。使用Spark读取csv文件,并分析数据。 Web项目整合ECharts,可视化展示数据分析结果。
数据分析流程
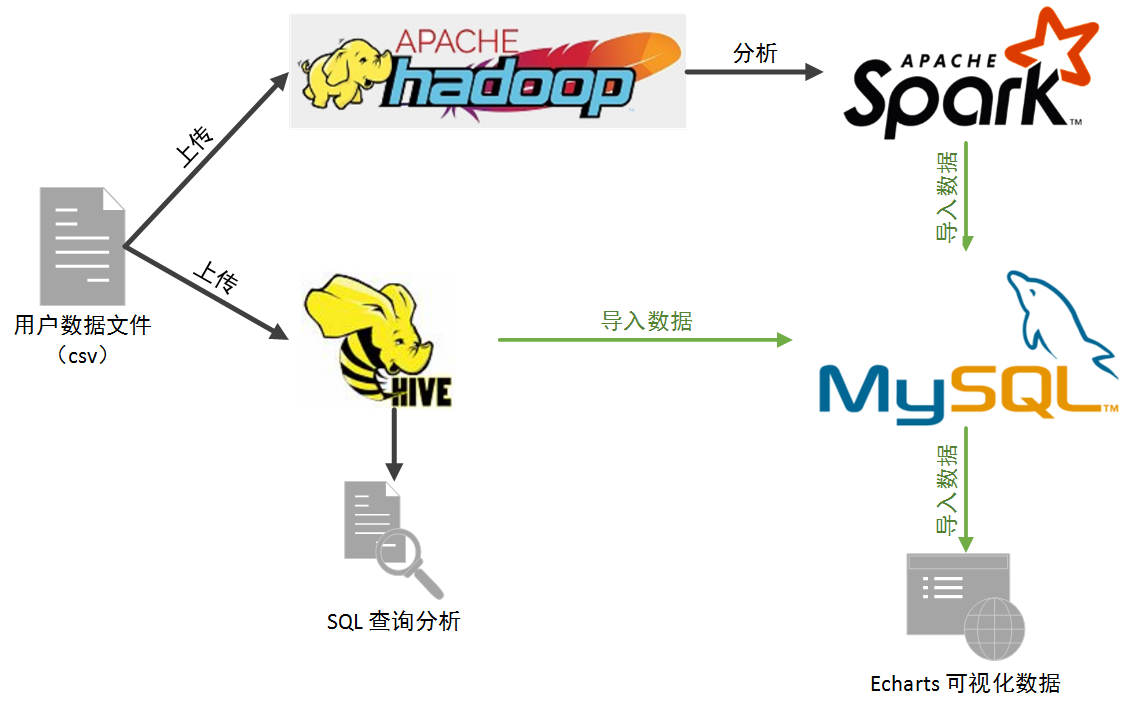
环境准备
软件要求
| 软件/插件/编程语言等 | 版本 |
|---|---|
| Linux 系统 | CentOS 7 |
| JDK | 1.8.0_161 |
| MySQL | 5.7.26 |
| Hadoop | 2.7.7 |
| Scala | 2.11 |
| Spark | 2.4.4 |
| Hive | 2.3.6 |
| Sqoop | 1.4.7 |
| Idea | 2018版 |
| ECharts | 3.4.0 |
硬件要求
本案例可以在单机上完成(即伪分布式环境),也可以在集群环境下完成。**由于硬件限制,我的所有操作均在伪分布式环境下完成。**单机的要求, 8 G 以上内存,500 G 磁盘存储。
环境搭建
- 安装
Linux系统。(参考本人博客:VMware 安装 Linux 系统(CentOS 7 图文教程)) - Linux 安装 JDK。(参考本人博客:Linux 安装 JDK(图文教程))
Hadoop伪分布式搭建。(参考本人博客:Hadoop 集群搭建详细步骤)另:本次使用的是仅主机模式,主机名为centos2020(使用命令:hostnamectl set-hostname centos2020)。- MySQL 安装。(参考本人博客:Linux 安装 MySQL)
- Linux 安装 Hive 。(参考本人博客:Linux 安装 Hive)
- Linux 安装 Sqoop。(参考本人博客:Linux 安装 Sqoop)
- Linux 安装 Spark(单机版,参考本人博客:Linux 安装 Spark)
- echarts 下载
最后
以上就是朴素音响最近收集整理的关于淘宝双11大数据分析(环境篇)案例分析的全部内容,更多相关淘宝双11大数据分析(环境篇)案例分析内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复