文章目录
- 1. 意犹未尽的诗词大会
- 2. Python + ElasticSearch的环境搭建
- 2.1 安装ElasticSearch
- 2.2 安装Python的Elasticsearch客户端
- 3. 使用Python爬取诗词数据
- 3.1 创建索引
- 3.2 爬取诗词(以唐诗为例)
- 3.3 索引诗词数据
- 3.4 完整的爬取代码
- 4. 诗词数据分析
- 4.1 牛刀小试
- 4.2 诗词作品收录排行榜
- 4.3 最热门词牌排行榜
- 4.4 文字频率排行榜
- 4.5 飞花令
1. 意犹未尽的诗词大会
正月十六,中国诗词大会第五季落下帷幕。从2016年2月12日第一季于开播,迄今恰好四周年。在这个舞台上,时年16岁的才女武亦姝、雨无阻的外卖小哥雷海为、端庄美丽的北京大学博士生陈更,不留遗憾的三季老将彭敏,都以精彩表现给我们留下了深刻印象。中国诗词大会潜移默化地影响了一大批中国人,激发了很多人对诗词的热爱。

因为喜欢,就想到了用 Python + ElasticSearch 这个大数据的手段搞一个“诗词大会”。如果你也喜欢,就请跟我一起来体验一下吧。读完了文末的飞花令,相信你一定会萌生出足够的勇气和信心报名参加下一季的中国诗词大会!
2. Python + ElasticSearch的环境搭建
2.1 安装ElasticSearch
ElasticSearch是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用ElasticSearch的水平伸缩性,能使数据在生产环境变得更有价值。
ElasticSearch采用的是NoSql数据库,其基本概念与传统的关系型数据库的概念有所不同。我们先了解一下这两个概念:
-
文档
NoSql数据库又叫做文档型数据库。文档就相当于关系型数据库的记录(行)。 -
索引
在关系数据库中的索引,是为了加速查询设置的一种数据结构。不同于关系数据库的索引,Elasticsearch会为每个字段创建这个含义的索引,而且Elasticsearch中的索引是透明的,因此Elasticsearch不再谈论这个含义的索引,而是赋予索引两个含义:- 名词:一个索引类似于传统关系数据库中的一个数据库,是一个存储关系型文档的地方
- 动词:索引一个文档,就是存储一个文档到一个索引(名词)中以便它可以被检索和查询到,相当于关系数据库的insert
ElasticSearch是使用java编写的,安装ElasticSearch之前,首先要安装java运行环境。为了减轻电脑的负担,可以不安装JDK,只安装JRE即可。
安装完成后,需要设置环境变量。我安装的是jre1.8.0_241,安装路径在C:Program FilesJava,如果你安装的版本路和路径有所不同,请根据实际安装情况填写:
- JAVAHOME:C:Program FilesJavajre1.8.0_241
- CLASSPATH:.;%JAVA_HOME%lib
- PATH: %JAVA_HOME%bin
环境变量设置好后,就可以安装ElasticSearch了。ElasticSearch安装很简单,从官方网站下载下载以后解压, 在其解压路径下的bin文件中运行elasticsearch.bat,即可启动ElasticSearch服务。
2.2 安装Python的Elasticsearch客户端
万能的pip:
pip install elasticsearch
安装成功后,即可使用该客户端连接Elasticsearch服务器。
>>> from elasticsearch import Elasticsearch
>>> es = Elasticsearch()
>>> es.info()
{'name': 'LAPTOP-8507OGEN', 'cluster_name': 'elasticsearch', 'cluster_uuid': 'OwrXmbSwTk6LB-q9lFDV0w', 'version': {'number': '7.5.2', 'build_flavor': 'default', 'build_type': 'zip', 'build_hash': '8bec50e1e0ad29dad5653712cf3bb580cd1afcdf', 'build_date': '2020-01-15T12:11:52.313576Z', 'build_snapshot': False, 'lucene_version': '8.3.0', 'minimum_wire_compatibility_version': '6.8.0', 'minimum_index_compatibility_version': '6.0.0-beta1'}, 'tagline': 'You Know, for Search'}
3. 使用Python爬取诗词数据
这次我爬取的目标是古诗文网,这里面很多诗词的分类方法。我要爬取的是有唐诗三百首和宋词三百首。
3.1 创建索引
ElasticSearch可以不创建索引直接索引数据,不过,要使用一些高级聚合功能,自动创建的索引并不理想,而索引在创建之后不能更改。最好在索引数据之前,先创建索引。
>>> from elasticsearch import Elasticsearch, client
>>> es = Elasticsearch()
>>> ic = client.IndicesClient(es)
>>> doc = {
"mappings": {
"properties": {
"title": { # 题目
"type": "keyword"
},
"epigraph": { # 词牌名
"type": "keyword"
},
"dynasty": { # 朝代
"type": "keyword"
},
"author": { # 作者
"type": "keyword"
},
"content": { # 内容
"type": "text"
}
}
}
}
>>> ic.create(index='poetry', body=doc)
{'acknowledged': True, 'shards_acknowledged': True, 'index': 'poetry'}
3.2 爬取诗词(以唐诗为例)
Python访问http的库有很多,使用最方便的是requests,我就用requests来获取网页的内容,用bs4来解析网页的内容。
-
取得唐诗三百首列表
取得唐诗三百首列表页面的html:>>> import requests >>> html = requests.get('https://so.gushiwen.org/gushi/tangshi.aspx').text然后使用BeautifulSoup模块对html代码进行解析,得到诗名和诗文地址的列表:
>>> from bs4 import BeautifulSoup >>> import lxml >>> soup = BeautifulSoup(html, "lxml") >>> typecont = soup.find_all(attrs={"class":"typecont"}) >>> index = 1 >>> for div in typecont: for ch in div.children: if ch.name == 'span': print(index, ch.a.text, ch.a.attrs['href']) index += 1这样,就取到了唐诗的地址列表,共320首
-
取得唐诗的内容
访问https://so.gushiwen.org/shiwenv_c90ff9ea5a71.aspx,取到《登鹳雀楼》的页面,并用bs4解析:>>> html = requests.get('https://so.gushiwen.org/shiwenv_c90ff9ea5a71.aspx').text >>> soup = BeautifulSoup(html, "lxml") -
取得唐诗标题:
>>> cont = soup.select('.main3 .left .sons .cont')[0] >>> title = cont.h1.text >>> title '登鹳雀楼' -
取得朝代和作者:
>>> al = cont.p.select('a') >>> dynasty = al[0].text >>> dynasty '唐代' >>> author = al[1].text >>> author -
取得诗文内容:
>>> content = cont.select('.contson')[0].text >>> content 'n白日依山尽,黄河入海流。欲穷千里目,更上一层楼。n' >>> content.strip() '白日依山尽,黄河入海流。欲穷千里目,更上一层楼。'
3.3 索引诗词数据
数据拿到了,我们就可以将它们保存到ElasticSearch中了。用ElasticSearch的术语,这叫做“索引诗词数据”。
>>> from elasticsearch import Elasticsearch
>>> es = Elasticsearch()
>>> doc = {
'title':title,
'dynasty':dynasty,
'author':author,
'content':content
}
>>> ret = es.index(index='poetry', body=doc)
>>> print(json.dumps(ret, indent=4, separators=(',', ': '), ensure_ascii=False))
{
"_index": "test",
"_type": "test",
"_id": "bp3tNnABnXfYifgM_GRI",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
根据返回的id,查询一下刚才保存的数据:
>>> ret = es.get(index='poetry', id='bp3tNnABnXfYifgM_GRI')
>>> print(json.dumps(ret, indent=4, separators=(',', ': '), ensure_ascii=False))
{
"_index": "test",
"_type": "test",
"_id": "bp3tNnABnXfYifgM_GRI",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"title": "登鹳雀楼",
"dynasty": "唐代",
"author": "王之涣",
"content": "白日依山尽,黄河入海流。欲穷千里目,更上一层楼。"
}
}
3.4 完整的爬取代码
全部爬取代码不足100行,可直接复制保存为本地文件。只要环境安装没问题,ElasticSearch服务正常启动,代码可直接运行。
#!/usr/bin/env python
# coding:utf-8
import lxml
import requests
from bs4 import BeautifulSoup
from elasticsearch import Elasticsearch, client
def create_index():
es = Elasticsearch()
ic = client.IndicesClient(es)
# 判断索引是否存在
if not ic.exists(index="poetry"):
# 创建索引
doc = {
"mappings": {
"properties": {
"title": {
"type": "keyword"
},
"epigraph": {
"type": "keyword"
},
"dynasty": {
"type": "keyword"
},
"author": {
"type": "keyword"
},
"content": {
"type": "text"
}
}
}
}
ic.create(index='poetry', body=doc)
def get_poetry(list_url):
es = Elasticsearch()
# 取得列表页面
html = requests.get(list_url).text
soup = BeautifulSoup(html, "lxml")
typecont = soup.find_all(attrs={"class":"typecont"})
# 遍历列表
for div in typecont:
for ch in div.children:
if ch.name == 'span':
# 取得诗词内容
print('get:', ch.a.text, ch.a.attrs['href'])
html = requests.get('https://so.gushiwen.org' + ch.a.attrs['href']).text
soup = BeautifulSoup(html, "lxml")
cont = soup.select('.main3 .left .sons .cont')[0]
# 标题
title = cont.h1.text
# 词牌
epigraph = ""
if '·' in title:
epigraph = title[:title.index('·')]
al = cont.p.select('a')
# 朝代
dynasty = al[0].text
# 作者
author = al[1].text
# 内容
content = cont.select('.contson')[0].text.strip()
# 索引数据
doc = {
"title": title,
"epigraph": epigraph,
"dynasty": dynasty,
"author": author,
"content": content
}
# ret = es.index(index='poetry', doc_type='poetry', body=doc)
ret = es.index(index='poetry', body=doc)
print(ret)
def main():
create_index()
get_poetry('https://so.gushiwen.org/gushi/tangshi.aspx')
get_poetry('https://so.gushiwen.org/gushi/songsan.aspx')
if __name__ == '__main__':
main()
4. 诗词数据分析
4.1 牛刀小试
有了诗词数据,我们就可以进行统计分析了。先牛刀小试一下,查询我一共收录了多少篇诗词:
>>> from elasticsearch import Elasticsearch
>>> es = Elasticsearch()
>>> ret = es.search(index='poetry')
>>> ret.keys() # 查询结果是一个字典,可以逐一查看其数据
dict_keys(['took', 'timed_out', '_shards', 'hits'])
>>> ret['hits']['total']['value'] # 这是查询到的文档总数
613
>>> for item in ret['hits']['hits']: # 这里是部分查询到的文档(ElasticSearch默认只返回前10条)
print(item['_source']['title'], '--', item['_source']['author'])
早发白帝城 / 白帝下江陵 -- 李白
夜上受降城闻笛 -- 李益
贾生 -- 李商隐
隋宫 -- 李商隐
瑶池 -- 李商隐
芙蓉楼送辛渐 -- 王昌龄
闺怨 -- 王昌龄
春宫曲 -- 王昌龄
九月九日忆山东兄弟 -- 王维
凉州词 -- 王翰
返回结果中的ret[‘hits’][‘total’][‘value’]是我们要的统计结果,ret[‘hits’][‘hits’]是查询到的文档。ElasticSearch默认只返回前10条,可以使用参数指定返回的数量。下面指定返回2个文档:
>>> ret = es.search(index='poetry', body={'size':2})
>>> ret['hits']['total']['value'] # 查询总数任然是613
613
>>> for item in ret['hits']['hits']: # 返回2个文档
print(item['_source']['title'], '--', item['_source']['author'])
print(item['_source']['content'])
print()
早发白帝城 / 白帝下江陵 -- 李白
朝辞白帝彩云间,千里江陵一日还。两岸猿声啼不住,轻舟已过万重山。
夜上受降城闻笛 -- 李益
回乐烽前沙似雪,受降城外月如霜。(回乐烽 一作:回乐峰)不知何处吹芦管,一夜征人尽望乡。
那么这里面有多少是李白写的呢:
>>> condition = {"query":{"match":{"author":"李白"}},"size":0}
>>> ret = es.search(index='poetry', body=condition)
>>> ret['hits']['total']['value']
37
哇,竟然有37篇之多!
4.2 诗词作品收录排行榜
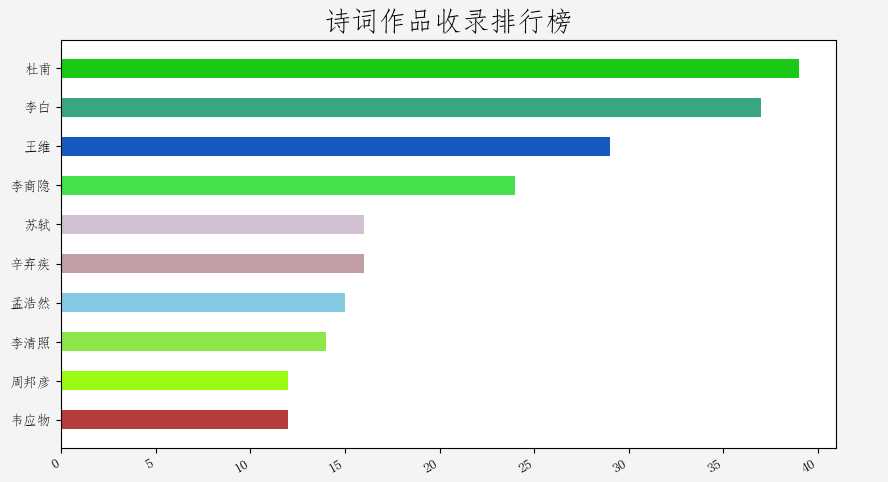
唐宋两代,是中国诗词的鼎盛时期,名篇佳作灿若星河,诗词大家群星璀璨。在这613篇作品中,究竟谁的作品最多呢?是诗仙李白?或者诗圣杜甫?抑或是开一代词风的李清照、苏东坡?让他们来一场PK吧。
>>> ret = es.search(index='poetry', body={'size':0, 'aggs': {'authors':{"terms": { "field": "author"}}}})
>>> for item in ret['aggregations']['authors']['buckets']:
print(item['key'], item['doc_count'])
杜甫 39
李白 37
王维 29
李商隐 24
苏轼 16
辛弃疾 16
孟浩然 15
李清照 14
周邦彦 12
韦应物 12
恭喜以上选手获得了本次比赛前10名。请看大屏幕:
4.3 最热门词牌排行榜
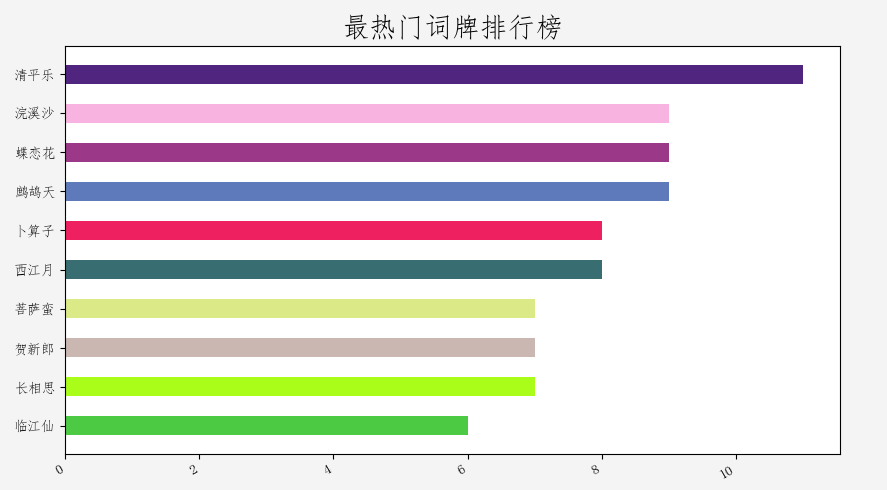
词的特点之一是词牌名,而几乎每一个词牌名的背后,都隐藏着一个故事。在我们的诗词库中,哪些词牌最受诗词达人的欢迎呢?对上面的检索条件略加修改,就可以很快知道结果了。这里检索结果取前11个,因为有些词是没有词牌名的(也许本事就是词牌吧)。
>>> ret = es.search(index='poetry', body={'size':0, 'aggs': {'epigraphs':{"terms": { "field": "epigraph",'size':11 }}}})
>>> for item in ret['aggregations']['epigraphs']['buckets']:
print(item['key'], item['doc_count'])
273
清平乐 11
浣溪沙 9
蝶恋花 9
鹧鸪天 9
卜算子 8
西江月 8
菩萨蛮 7
贺新郎 7
长相思 7
临江仙 6
最热门词牌排行榜为:
4.4 文字频率排行榜
创建索引时,有些朋友应该发现content字段的类型与其他的不一样,其他的都是keyword,而content是text。这么做是因为ElasticSearch有个分词机制,分词机制会将keyword类型的视为一个词,而对于text的字段,英文每个单词是一个词而中文则是每个字为一个词。
对于text字段,ElasticSearch使用了Fielddata缓存技术,要对这样的字段进行聚合,首先要开启字段的Fielddata:
>>> es.index(index='poetry', doc_type='_mapping', body={"properties": {"content": {"type": "text","fielddata": True}}})
{'acknowledged': True}
然后就可以进行聚合操作了:
>>> ret = es.search(index='poetry', body={'size':0, 'aggs': {'content':{"terms": { "field": "content",'size':20 }}}})
>>>
>>> for item in ret['aggregations']['content']['buckets']:
print(item['key'], item['doc_count'])
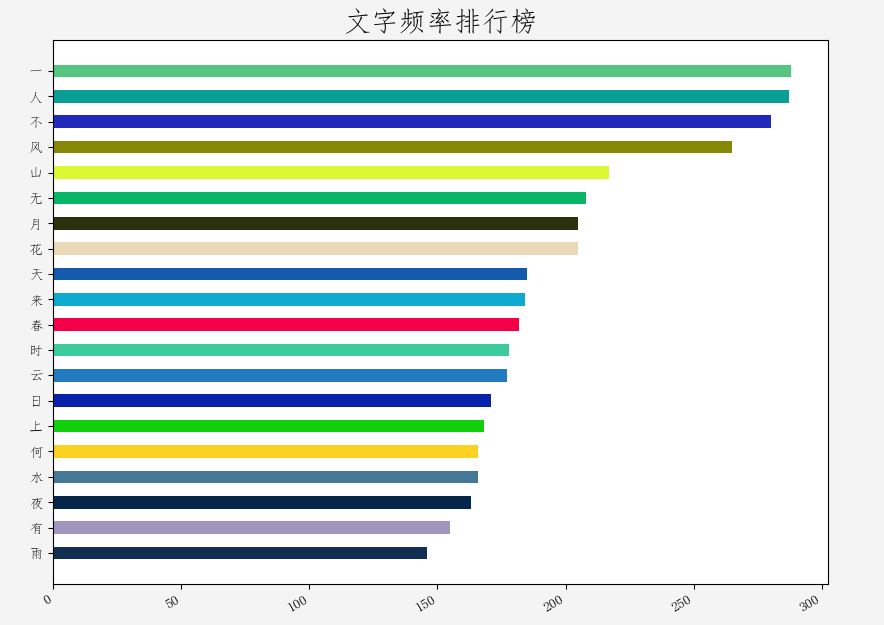
一 288
人 287
不 280
风 265
山 217
无 208
月 205
花 205
天 185
来 184
春 182
时 178
云 177
日 171
上 168
何 166
水 166
夜 163
有 155
雨 146
文字频率TOP20,按照顺序写出来,几乎就是一首五言绝句:
一人不风山,无月花天来。
春时云日上,何水夜有雨。
奇也不奇?难怪!因为每一个汉字,本身就是一幅画、一个故事。有请TOP20出场:
4.5 飞花令
中国诗词大会最精彩的环节莫过于飞花令了。第八场彭敏绝地反击,与百人团进行飞花令的场景让人印象深刻。当时飞的是“江”字,那我们就来看一个包含有“江”字的诗词都有哪些。
上面的实例都是使用的ElasticSearch的聚合分析功能,这个例子则是使得全文检索功能。
>>> ret = es.search(index='poetry', body={"query":{"match":{"content":"江"}}, "highlight":{"fields":{"content":{}}}})
>>> ret['hits']['total']['value']
138
>>> for item in ret['hits']['hits']:
print(item['_source']['title'], item['_source']['author'])
print(item['highlight']['content'])
print()
body增加了高亮选项,“highlight”:{“fields”:{“content”:{}}},可以高亮显示关键词。包含“江”字的诗词,一共138首,这里只显示了前10首。
忆江南 白居易
江南好,风景旧曾谙。日出江花红胜火,春来江水绿如蓝。能不忆江南?
忆江南词三首 白居易
江南好,风景旧曾谙。日出江花红胜火,春来江水绿如蓝。能不忆江南?
江南忆,最忆是杭州。山寺月中寻桂子,郡亭枕上看潮头。何日更重游!
江南忆,其次忆吴宫。吴酒一杯春竹叶,吴娃双舞醉芙蓉。早晚复相逢!
遣怀 杜牧
落魄江南载酒行,楚腰纤细掌中轻。(江南 一作:江湖;纤细 一作:肠断)十年一觉扬州梦,赢得青楼薄幸名。
长干行·家临九江水 崔颢
家临九江水,来去九江侧。同是长干人,生小不相识。
卜算子·我住长江头 李之仪
我住长江头,君住长江尾。日日思君不见君,共饮长江水。
此水几时休,此恨何时已。只愿君心似我心,定不负相思意。
长相思·吴山青 林逋
(谁知离别情 一作:争忍有离情)君泪盈,妾泪盈,罗带同心结未成,江边潮已平。(江边 一作:江头)’]
霜天晓角·仪真江上夜泊 黄机
寒江夜宿。长啸江之曲。水底鱼龙惊动,风卷地、浪翻屋。 诗情吟未足。酒兴断还续。草草兴亡休问,功名泪、欲盈掬。
菩萨蛮·人人尽说江南好 韦庄
人人尽说江南好,游人只合江南老。春水碧于天,画船听雨眠。垆边人似月,皓腕凝霜雪。未老莫还乡,还乡须断肠。
采桑子·恨君不似江楼月 吕本中
恨君不似江楼月,南北东西,南北东西,只有相随无别离。恨君却似江楼月,暂满还亏,暂满还亏,待得团圆是几时?
清平乐·独宿博山王氏庵 辛弃疾
平生塞北江南,归来华发苍颜。布被秋宵梦觉,眼前万里江山。
再来一个超级飞花令,同时包含“江”和“水”的诗词有哪些呢?
>>> condition = {
"query" : {
"match" : {
"content" : {
"query": "江 水",
"operator" : "and"
}
}
},
"highlight": {
"fields" : {
"content" : {}
}
}
}
>>> ret = es.search(index='poetry', body=condition)
>>> ret['hits']['total']['value']
52
>>> for item in ret['hits']['hits']:
print(item['_source']['title'], item['_source']['author'])
print(item['highlight']['content'])
print()
我们的诗词库中,共有52首同时包含“江”和“水”的诗词,这里只显示了前10首。
忆江南 白居易
江南好,风景旧曾谙。日出江花红胜火,春来江水绿如蓝。能不忆江南?
卜算子·我住长江头 李之仪
我住长江头,君住长江尾。日日思君不见君,共饮长江水。 此水几时休,此恨何时已。只愿君心似我心,定不负相思意。
长干行·家临九江水 崔颢
家临九江水,来去九江侧。同是长干人,生小不相识。
竹枝词·山桃红花满上头 刘禹锡
山桃红花满上头,蜀江春水拍山流。花红易衰似郎意,水流无限似侬愁。
忆江南词三首 白居易
江南好,风景旧曾谙。日出江花红胜火,春来江水绿如蓝。能不忆江南?n江南忆,最忆是杭州。山寺月中寻桂子,郡亭枕上看潮头。何日更重游!n江南忆,其次忆吴宫。吴酒一杯春竹叶,吴娃双舞醉芙蓉。早晚复相逢!
霜天晓角·仪真江上夜泊 黄机
寒江夜宿。长啸江之曲。水底鱼龙惊动,风卷地、浪翻屋。 诗情吟未足。酒兴断还续。草草兴亡休问,功名泪、欲盈掬。
菩萨蛮·人人尽说江南好 韦庄
人人尽说江南好,游人只合江南老。春水碧于天,画船听雨眠。垆边人似月,皓腕凝霜雪。未老莫还乡,还乡须断肠。
望江南·梳洗罢 温庭筠
梳洗罢,独倚望江楼。过尽千帆皆不是,斜晖脉脉水悠悠。肠断白蘋洲。
寄扬州韩绰判官 杜牧
青山隐隐水迢迢,秋尽江南草未凋。二十四桥明月夜,玉人何处教吹箫?
泊秦淮 杜牧
烟笼寒水月笼沙,夜泊秦淮近酒家。商女不知亡国恨,隔江犹唱后庭花。
有了这个武器,是不是也想报名参加下一期的诗词大会了?那就赶快去报名吧!
最后
以上就是糟糕冰淇淋最近收集整理的关于Python + ElasticSearch:有了这个超级武器,你也可以报名参加诗词大会了!的全部内容,更多相关Python内容请搜索靠谱客的其他文章。








发表评论 取消回复