文章目录
- 前言
- 一、字符串
- 二、哈希
- 三、 列表
- 四、集合
- 五、有序集合
- 六、位图 Redis Bitmap
- 七、基数统计 HyperLogLog
- 八、Geo 地理位置
- 九、Streams 流
- 应用场景总结
前言
Redis 数据库支持的数据类型。
- 最基本的5种
- 字符串(string)
- 哈希(hash)
- 列表(list)
- 集合(set)
- 有序集合(sorted set)
- 新版本
- 位图 BitMap(2.2)
- 基数统计 ( HyperLogLog) # 2.8.9新增
- Geo:地理位置信息储存起来, 并对这些信息进行操作 # 3.2新增
- 流(Stream)# 5.0新增
一、字符串
String 是一组字节。在 Redis 数据库中,字符串是二进制安全的。这意味着它们具有已知长度,并且不受任何特殊终止字符的影响。可以在一个字符串中存储最多 512 兆字节的内容。
例
使用 SET 命令在 name 键中存储字符串 redis.com.cn,然后使用 GET 命令查询 name。
SET name "abc"
OK
GET name
"abc"
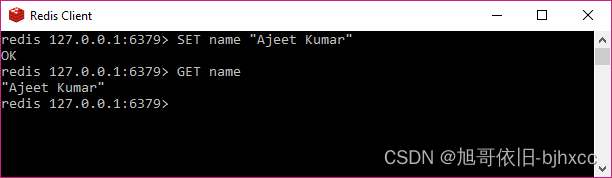
在上面的例子中,SET 和 GET 是 Redis 命令,name 是 Redis 中使用的 key,abc 是存储在 Redis 中的字符串值。
二、哈希
哈希是键值对的集合。在 Redis 中,哈希是字符串字段和字符串值之间的映射。因此,它们适合表示对象。
例
让我们存储一个用户的对象,其中包含用户的基本信息。
HMSET user:1 username ajeet password javatpoint alexa 2000
OK
HGETALL user:1
"username"
"ajeet"
"password"
"javatpoint"
"alexa"
"2000"
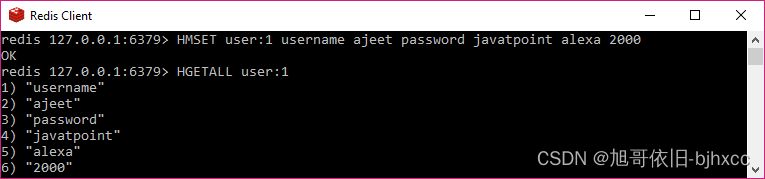
这里,HMSET 和 HGETALL 是 Redis 的命令,而 user:1 是键。
每个哈希可以存储多达 2的32– 次方 1 个字段-值对。
三、 列表
Redis 列表定义为字符串列表,按插入顺序排序。可以将元素添加到 Redis 列表的头部或尾部。
例
lpush javatpoint java
(integer) 1
lpush javatpoint java
(integer) 1
lpush javatpoint java
(integer) 1
lpush javatpoint java
(integer) 1
lrange javatpoint 0 10
"cassandra"
"mongodb"
"sql"
"java"
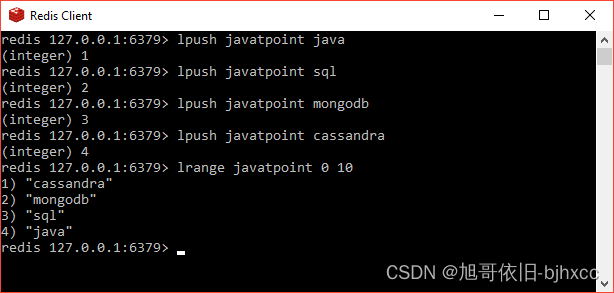
列表的最大长度为 232 – 1 个元素(超过 40 亿个元素)。
四、集合
集合(set)是 Redis 数据库中的无序字符串集合。在 Redis 中,添加,删除和查找的时间复杂度是 O(1)。
例
sadd tutoriallist redis
(integer) 1
redis 127.0.0.1:6379> sadd tutoriallist sql
(integer) 1
redis 127.0.0.1:6379> sadd tutoriallist postgresql
(integer) 1
redis 127.0.0.1:6379> sadd tutoriallist postgresql
(integer) 0
redis 127.0.0.1:6379> sadd tutoriallist postgresql
(integer) 0
redis 127.0.0.1:6379> smembers tutoriallist
1) "redis"
2) "postgresql"
3) "sql"
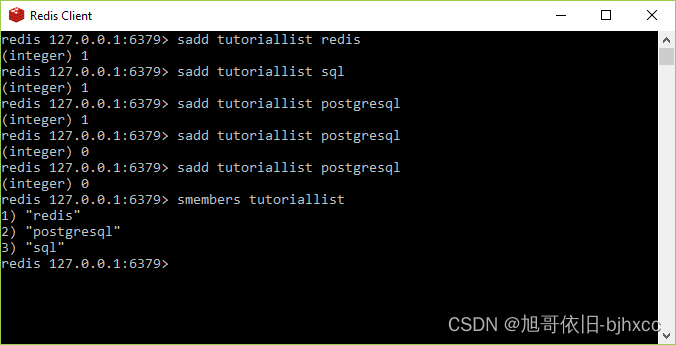
在上面的示例中,您可以看到 postgresql 被添加了三次,但由于该集的唯一属性,它只添加一次。
集合中的最大成员数为 232-1 个元素(超过 40 亿个元素)。
五、有序集合
Redis 有序集合类似于 Redis 集合,也是一组非重复的字符串集合。但是,排序集的每个成员都与一个分数相关联,该分数用于获取从最小到最高分数的有序排序集。虽然成员是独特的,但可以重复分数。
例
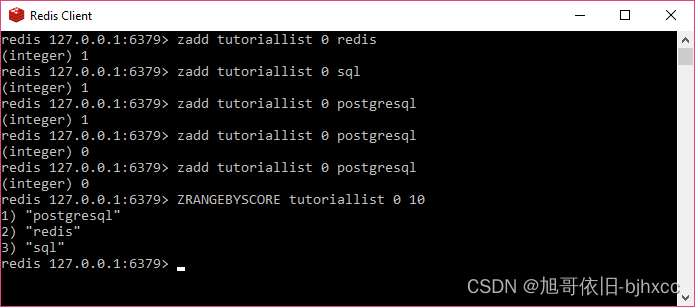
redis 127.0.0.1:6379> zadd tutoriallist 0 redis
(integer) 1
redis 127.0.0.1:6379> zadd tutoriallist 0 sql
(integer) 1
redis 127.0.0.1:6379> zadd tutoriallist 0 postgresql
(integer) 1
redis 127.0.0.1:6379> zadd tutoriallist 0 postgresql
(integer) 0
redis 127.0.0.1:6379> zadd tutoriallist 0 postgresql
(integer) 0
redis 127.0.0.1:6379> ZRANGEBYSCORE tutoriallist 0 10
1) "postgresql"
2) "redis"
3) "sql"
六、位图 Redis Bitmap
Redis Bitmap 通过类似 map 结构存放 0 或 1 ( bit 位 ) 作为值。
Redis Bitmap 可以用来统计状态,如日活是否浏览过某个东西。
Redis setbit 命令
Redis setbit 命令用于设置或者清除一个 bit 位。
*Redis setbit 命令语法格式
SETBIT key offset value
*范例
127.0.0.1:6379> setbit aaa:001 10001 1 # 返回操作之前的数值
(integer) 0
127.0.0.1:6379> setbit aaa:001 10002 2 # 如果值不是0或1就报错
(error) ERR bit is not an integer or out of range
127.0.0.1:6379> setbit aaa:001 10002 0
(integer) 0
127.0.0.1:6379> setbit aaa:001 10003 1
(integer) 0
七、基数统计 HyperLogLog
Redis HyperLogLog 可以接受多个元素作为输入,并给出输入元素的基数估算值
-
基数
集合中不同元素的数量,比如 {‘apple’, ‘banana’, ‘cherry’, ‘banana’, ‘apple’} 的基数就是 3 -
估算值
算法给出的基数并不是精确的,可能会比实际稍微多一些或者稍微少一些,但会控制在合 理的范围之内
HyperLogLog 的优点是:即使输入元素的数量或者体积非常非常大,计算基数所需的空间总是固定的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 264 个不同元素的基数。
这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
-
Redis PFADD 命令
Redis PFADD 命令将元素添加至 HyperLogLogRedis PFADD 命令语法格式
PFADD key element [element …] -
范例
127.0.0.1:6379> PFADD unique::ip::counter '192.168.0.1'
(integer) 1
127.0.0.1:6379> PFADD unique::ip::counter '127.0.0.1'
(integer) 1
127.0.0.1:6379> PFADD unique::ip::counter '255.255.255.255'
(integer) 1
127.0.0.1:6379> PFCOUNT unique::ip::counter
(integer) 3
八、Geo 地理位置
Redis 的 GEO 特性在 Redis 3.2 版本中推出, 这个功能可以将用户给定的地理位置信息储存起来, 并对这些信息进行操作。GEO的数据结构总共有六个命令:geoadd、geopos、geodist、georadius、georadiusbymember、gethash,GEO使用的是国际通用坐标系WGS-84。
- GEOADD:添加地理位置
- GEOPOS:查询地理位置(经纬度),返回数组
- GEODIST:计算两位位置间的距离
- GEORADIUS:以给定的经纬度为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素。
- GEORADIUSBYMEMBER:以给定的地理位置为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素。
127.0.0.1:6379> geoadd kcityGeo 116.405285 39.904989 "beijing"
(integer) 1
127.0.0.1:6379> geoadd kcityGeo 121.472644 31.231706 "shanghai"
(integer) 1
127.0.0.1:6379> geodist kcityGeo beijing shanghai km
"1067.5980"
127.0.0.1:6379> geopos kcityGeo beijing
1) 1) "116.40528291463851929"
2) "39.9049884229125027"
127.0.0.1:6379> geohash kcityGeo beijing
1) "wx4g0b7xrt0"
127.0.0.1:6379> georadiusbymember kcityGeo beijing 1200 km withdist withcoord asc count 5
1) 1) "beijing"
2) "0.0000"
3) 1) "116.40528291463851929"
2) "39.9049884229125027"
2) 1) "shanghai"
2) "1067.5980"
3) 1) "121.47264629602432251"
2) "31.23170490709807012"
- 内部编码
但是,需要说明的是,Geo本身不是一种数据结构,它本质上还是借助于Sorted Set(ZSET),并且使用GeoHash技术进行填充。Redis中将经纬度使用52位的整数进行编码,放进zset中,score就是GeoHash的52位整数值。在使用Redis进行Geo查询时,其内部对应的操作其实就是zset(skiplist)的操作。通过zset的score进行排序就可以得到坐标附近的其它元素,通过将score还原成坐标值就可以得到元素的原始坐标。
总之,Redis中处理这些地理位置坐标点的思想是:二维平面坐标点 --> 一维整数编码值 --> zset(score为编码值) --> zrangebyrank(获取score相近的元素)、zrangebyscore --> 通过score(整数编码值)反解坐标点 --> 附近点的地理位置坐标。
- 应用场景
- 比如现在比较火的直播业务,我们需要检索附近的主播,那么GEO就可以很好的实现这个功能。
一是主播开播的时候写入主播Id的经纬度,
二是主播关播的时候删除主播Id元素,这样就维护了一个具有位置信息的在线主播集合提供给线上检索。 - 滴滴叫车:
- 记录车位置:GEOADD cars:locations 116.034579 39.030452 33
- 用户读取附近的车:GEORADIUS cars:locations 116.054579 39.030452 5 km ASC COUNT 10
- 比如现在比较火的直播业务,我们需要检索附近的主播,那么GEO就可以很好的实现这个功能。
九、Streams 流
这是Redis5.0引入的全新数据结构,用一句话概括Streams就是Redis实现的内存版kafka。支持多播的可持久化的消息队列,用于实现发布订阅功能,借鉴了 kafka 的设计。Redis Stream的结构有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的ID和对应的内容。消息是持久化的,Redis重启后,内容还在。
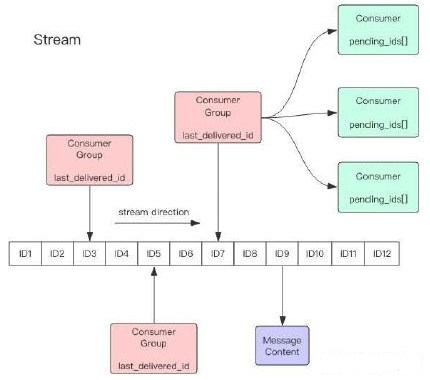
每个Stream都有唯一的名称,它就是Redis的key,在我们首次使用xadd指令追加消息时自动创建。
每个Stream都可以挂多个消费组,每个消费组会有个游标last_delivered_id在Stream数组之上往前移动,表示当前消费组已经消费到哪条消息了。每个消费组都有一个Stream内唯一的名称,消费组不会自动创建,它需要单独的指令xgroup create进行创建,需要指定从Stream的某个消息ID开始消费,这个ID用来初始化last_delivered_id变量。
每个消费组(Consumer Group)的状态都是独立的,相互不受影响。也就是说同一份Stream内部的消息会被每个消费组都消费到。
同一个消费组(Consumer Group)可以挂接多个消费者(Consumer),这些消费者之间是竞争关系,任意一个消费者读取了消息都会使游标last_delivered_id往前移动。每个消费者者有一个组内唯一名称。
消费者(Consumer)内部会有个状态变量pending_ids,它记录了当前已经被客户端读取的消息,但是还没有ack。如果客户端没有ack,这个变量里面的消息ID会越来越多,一旦某个消息被ack,它就开始减少。这个pending_ids变量在Redis官方被称之为PEL,也就是Pending Entries List,这是一个很核心的数据结构,它用来确保客户端至少消费了消息一次,而不会在网络传输的中途丢失了没处理。
- 消息ID:消息ID的形式是timestampInMillis-sequence,例如1527846880572-5,它表示当前的消息在毫米时间戳1527846880572时产生,并且是该毫秒内产生的第5条消息。消息ID可以由服务器自动生成,也可以由客户端自己指定,但是形式必须是整数-整数,而且必须是后面加入的消息的ID要大于前面的消息ID。
- 消息内容:消息内容就是键值对,形如hash结构的键值对,这没什么特别之处。
127.0.0.1:6379> XADD mystream * field1 value1 field2 value2 field3 value3
"1588491680862-0"
127.0.0.1:6379> XADD mystream * username lisi age 18
"1588491854070-0"
127.0.0.1:6379> xlen mystream
(integer) 2
127.0.0.1:6379> XADD mystream * username lisi age 18
"1588491861215-0"
127.0.0.1:6379> xrange mystream - +
1) 1) "1588491680862-0"
2) 1) "field1"
2) "value1"
3) "field2"
4) "value2"
5) "field3"
6) "value3"
2) 1) "1588491854070-0"
2) 1) "username"
2) "lisi"
3) "age"
4) "18"
3) 1) "1588491861215-0"
2) 1) "username"
2) "lisi"
3) "age"
4) "18"
127.0.0.1:6379> xdel mystream 1588491854070-0
(integer) 1
127.0.0.1:6379> xrange mystream - +
1) 1) "1588491680862-0"
2) 1) "field1"
2) "value1"
3) "field2"
4) "value2"
5) "field3"
6) "value3"
2) 1) "1588491861215-0"
2) 1) "username"
2) "lisi"
3) "age"
4) "18"
127.0.0.1:6379> xlen mystream
(integer) 2
内部编码
streams底层的数据结构是radix tree:Radix Tree(基数树) 事实上就几乎相同是传统的二叉树。仅仅是在寻找方式上,以一个unsigned int类型数为例,利用这个数的每个比特位作为树节点的推断。能够这样说,比方一个数10001010101010110101010,那么依照Radix 树的插入就是在根节点,假设遇到0,就指向左节点,假设遇到1就指向右节点,在插入过程中构造树节点,在删除过程中删除树节点。如下是一个保存了7个单词的Radix Tree:
应用场景总结
实际上,所谓的应用场景,其实就是合理的利用Redis本身的数据结构的特性来完成相关业务功能,可参考我我之前写的文章:学了redis不会实战?看这篇就够了
最后
以上就是自觉学姐最近收集整理的关于【缓存中间件】redis 支持的数据类型的全部内容,更多相关【缓存中间件】redis内容请搜索靠谱客的其他文章。








发表评论 取消回复