表引擎
MergeTree
主键
clickhouse主键特点:可以重复不是唯一的。
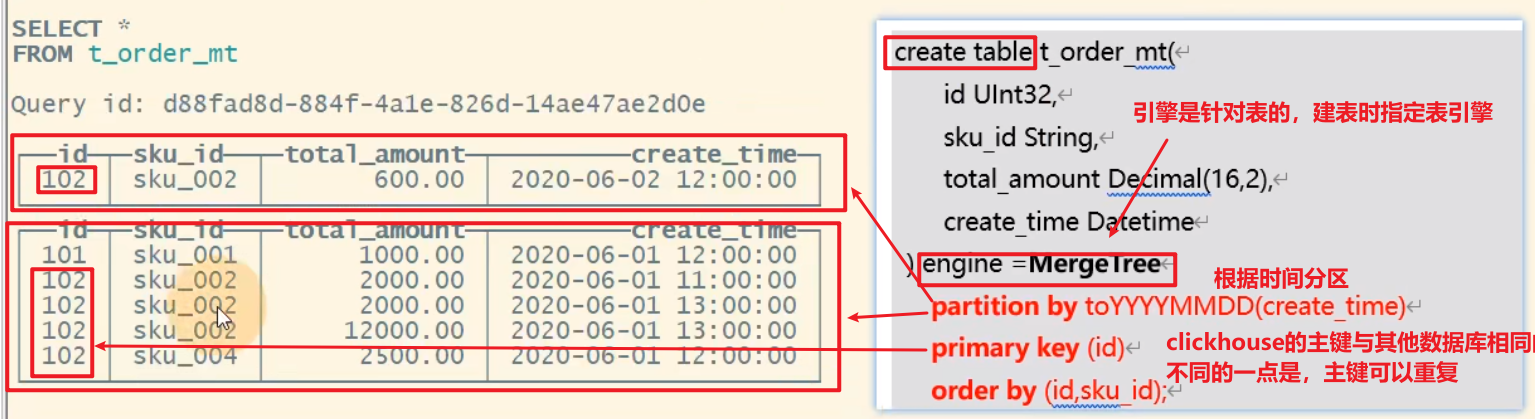
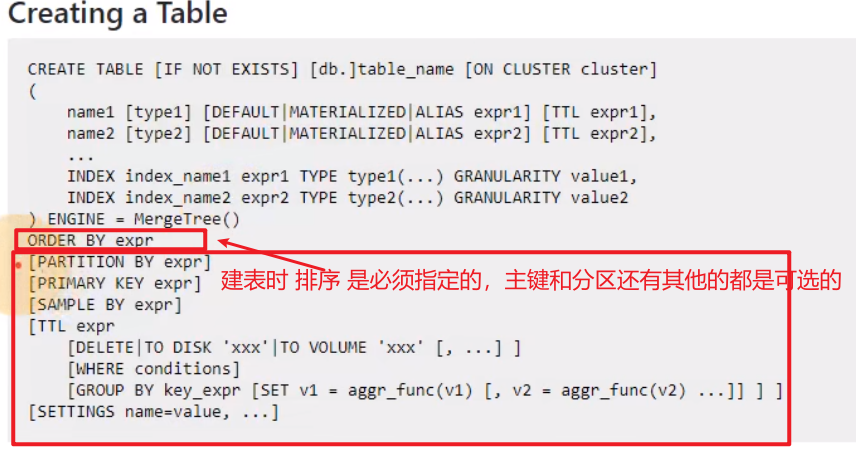
partition by 分区(可选)
1)作用
分区的目的主要是降低扫描的范围,优化查询速度
2)如果不填
只会使用一个分区。
3)分区目录
MergeTree 是以列文件+索引文件+表定义文件组成的,但是如果设定了分区那么这些文
件就会保存到不同的分区目录中。
4)并行
分区后,面对涉及跨分区的查询统计,ClickHouse 会以分区为单位并行处理。
5)数据写入与分区合并
任何一个批次的数据写入都会产生一个临时分区,不会纳入任何一个已有的分区。写入
后的某个时刻(大概 10-15 分钟后),ClickHouse 会自动执行合并操作(等不及也可以手动
通过 optimize 执行),把临时分区的数据,合并到已有分区中。
optimize table xxxx final;
MergeTree表引擎的文件结构
ClickHouse各文件目录:
bin/ ===> /usr/bin/
conf/ ===> /etc/clickhouse-server/
lib/ ===> /var/lib/clickhouse
log/ ===> /var/log/clickhouse-server
PartitionId_MinBlockNum_MaxBlockNum_Level
分区值_最小分区块编号_最大分区块编号_合并层级
=》PartitionId
数据分区ID生成规则
数据分区规则由分区ID决定,分区ID由PARTITION BY分区键决定。根据分区键字段类型,ID生成规则可分为:
未定义分区键
没有定义PARTITION BY,默认生成一个目录名为all的数据分区,所有数据均存放在all目录下。
整型分区键
分区键为整型,那么直接用该整型值的字符串形式做为分区ID。
日期类分区键 (直接存储为日期类型效率更高)
分区键为日期类型,或者可以转化成日期类型。
其他类型分区键
String、Float类型等,通过128位的Hash算法取其Hash值作为分区ID。
=》MinBlockNum
最小分区块编号,自增类型,从1开始向上递增。每产生一个新的目录分区就向上递增一个数字。
=》MaxBlockNum
最大分区块编号,新创建的分区MinBlockNum等于MaxBlockNum的编号。
=》Level
合并的层级,被合并的次数。合并次数越多,层级值越大。
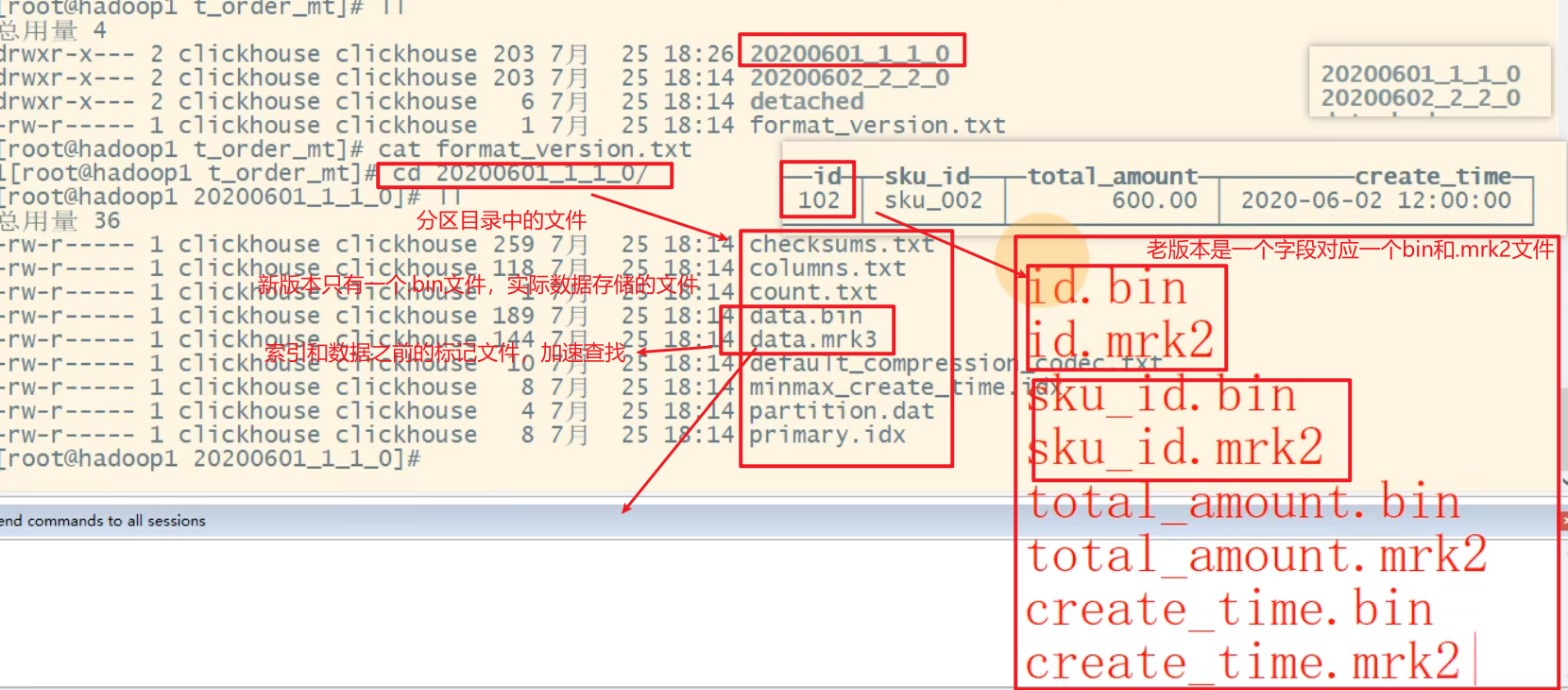
bin文件:数据文件
mrk文件:标记文件
标记文件在 idx索引文件 和 bin数据文件 之间起到了桥梁作用。
以mrk2结尾的文件,表示该表启用了自适应索引间隔。
primary.idx文件:主键索引文件,用于加快查询效率。
minmax_create_time.idx:分区键的最大最小值。
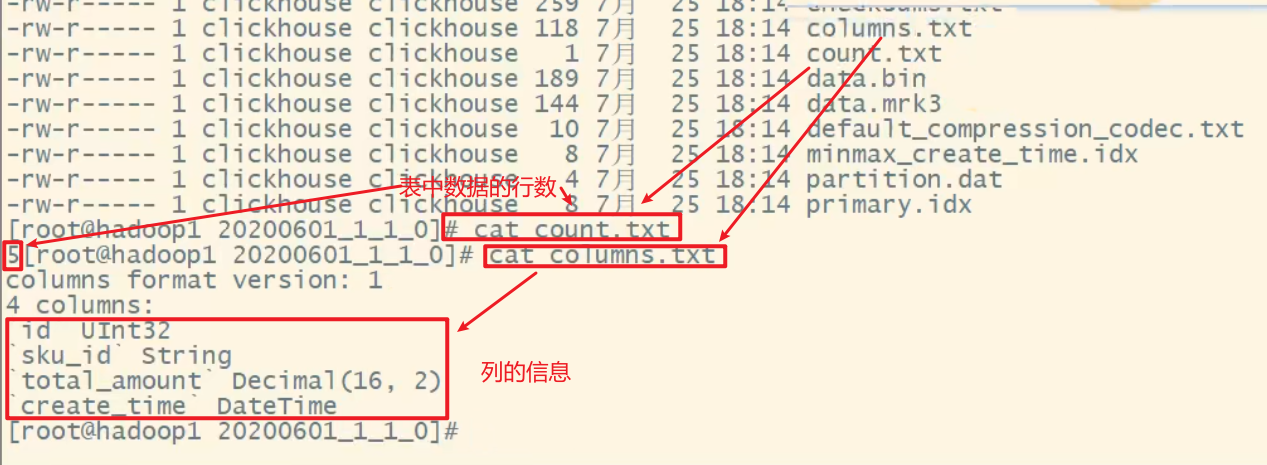
checksums.txt:校验文件,用于校验各个文件的正确性。存放各个文件的size以及hash值。
数据库数据默认存储目录:
/var/lib/clickhouse/data

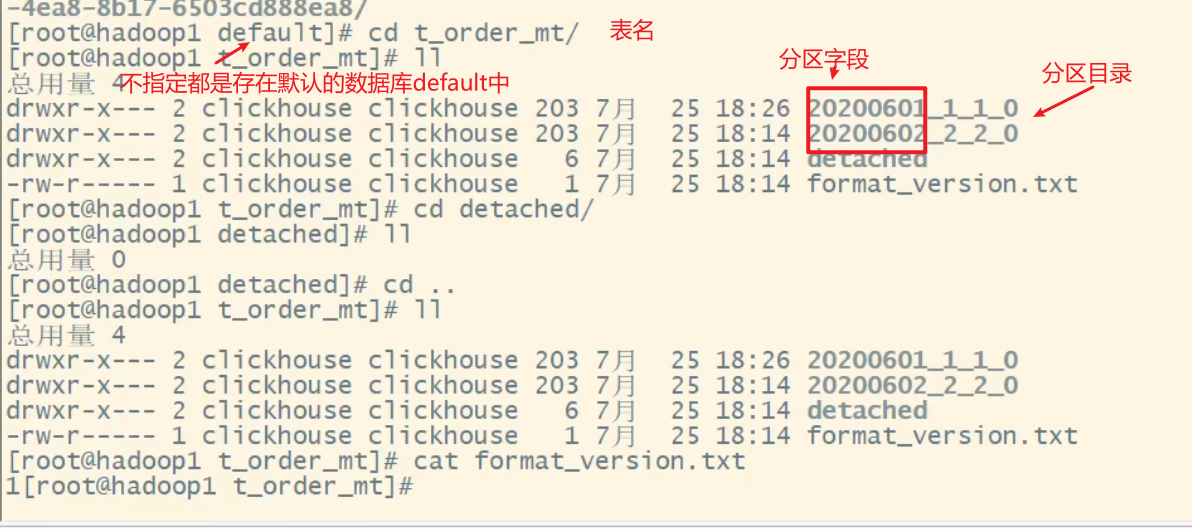
不指定分区都存在一个目录里面,名字为all

分区目录中的文件:
data.bin文件:数据文件
data.mrk文件:标记文件
标记文件在 idx索引文件 和 bin数据文件 之间起到了桥梁作用。
以mrk2结尾的文件,表示该表启用了自适应索引间隔。
primary.idx文件:主键索引文件,用于加快查询效率。
minmax_create_time.idx:分区键的最大最小值。
checksums.txt:校验文件,用于校验各个文件的正确性。存放各个文件的size以及hash值。
集群模式
clickHouse集群多副本模式,数据同步重度依赖zk, kafka 副本数据同步不依赖zk
最后
以上就是暴躁小懒猪最近收集整理的关于尚硅谷 clickHouse表引擎集群模式的全部内容,更多相关尚硅谷内容请搜索靠谱客的其他文章。








发表评论 取消回复