文章目录
- 1. partition初体验
- 2. partition原理
- 2.1 postgre的partition
- 2.2 kafka的partition
- 2.3 clickhouse的partition
- 3. 再看partition
1. partition初体验
项目中有张400亿条记录的表,建表时用partition by date_time按天做了分区,同样查一天的数据,对某个字段做汇聚,如果按非partition的字段做范围查询,查询耗时1164秒,见下图:

但如果按分区字段查询,查询时间则缩短到了4秒钟,简直天壤之别~~:

2. partition原理
首先,partition并不是一个新鲜的概念,在很多数据库和分布式应用的设计中都会用到数据分区的思想。本质上partition就是对数据按照某种指定的规则进行切分,相同分区的数据在物理上往往会写入同一个文件或目录下,其目的是为了缩小查询范围,加快查询的速度。当然都叫partition,但是大家其实在实现的时候还是有一些差异的。
2.1 postgre的partition
因为公司项目中经常的用DB是PG,所以就以PG为例来说吧。PG本身并没有直接提供partition by的语法,而是通过父子表继承的方式来实现的。我们在实际使用的时候,往往会定义一张空的父表,然后数据在插入的时候通过触发器的方式来将数据路由到对应的子表进行存储,参考之前的文章:https://blog.csdn.net/weixin_40104766/article/details/119066691 。这样做的收益显而易见:
- 比如该表按天分区,那么在查询某天的数据的时候,可以直接在该分区对应的文件上进行检索,大大提高了查询效率;
- 删除某一天的数据变的很容易,无需对整个库表进行删除,只需要把对应的分区表删掉即可。
当然PG在这方面也有可以改进的地方:
- 创建分区表的方法还是比较麻烦,需要自己编写一些触发器函数;
- 没有自动删除过期分区数据的方式,也需要自己写代码实现。
2.2 kafka的partition
kafka的partition虽然也叫partition,但是更类似于clickhouse里sharding的概念,是为了提高读写的并行度设计的。详见前文:浅谈kafka之partition
2.3 clickhouse的partition
clickhouse分区的目的是为了尽可能的减少读取的数据量,那么与上面的那些分区技术相比,它有哪些特点呢?
- 创建分区的方法比较简单,只需要在建表时通过partition by语法指定即可;
- 不止可以按某个字段做partition by,还可以支持按任意合法的表达式进行分区操作,比如toYYYYMM()按月做分区;
- 支持对partition进行TTL管理,淘汰过期的分区数据。
- 插入数据到分区表中时,先会将数据写入到分区目录下的segment文件中,后台程序会自动进行合并,当然也可以通过
optimize命令手动触发合并。
3. 再看partition
对于Everything is table(万物皆表)的clickhouse来说,有专门一张表对partition进行管理,那就是system.parts。
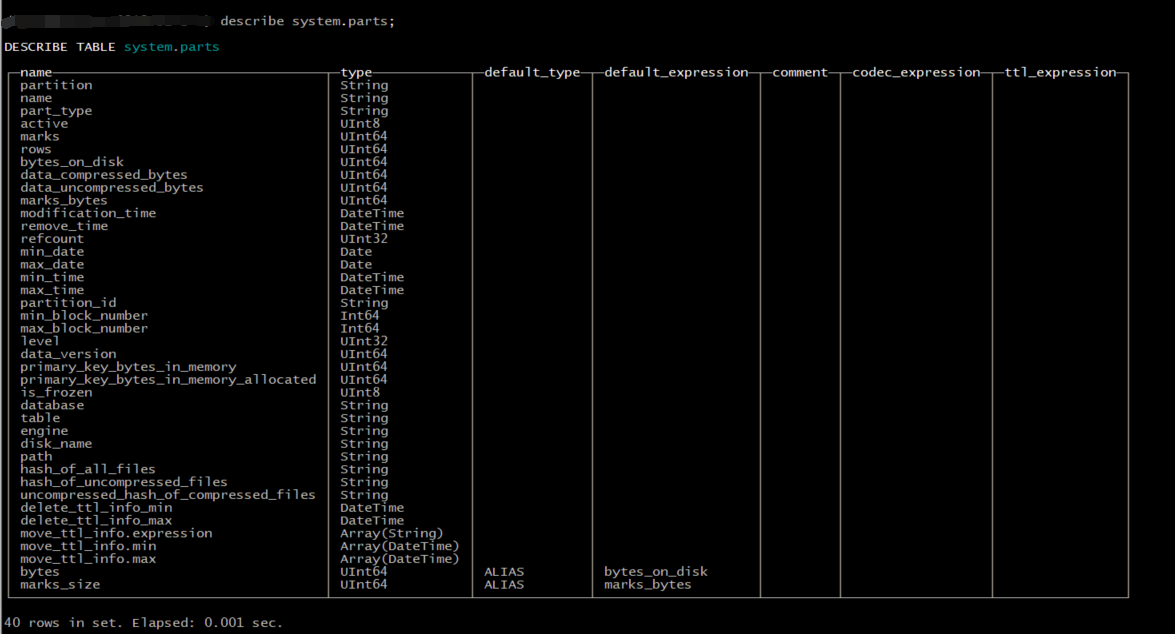
常见的一些字段说明:
- database:数据库名称
- table:表名
- partition:分区键
- name:分区名称
- path:分区对应的目录
- disk_name:分区所在的磁盘
- engine:该数据库表的引擎
其它的诸如分区包含的记录数、压缩大小、存储周期等信息都可以在这张表中进行查询。
最后
以上就是香蕉橘子最近收集整理的关于clickhouse之partition1. partition初体验2. partition原理3. 再看partition的全部内容,更多相关clickhouse之partition1.内容请搜索靠谱客的其他文章。








发表评论 取消回复