ClickHouse API 使用
08-Java 操作 CK之JDBC Client 概述
目标
ClickHouse提供JDBC方式访问数据库,进行DDL和DML操作。
路径
- ClickHouse 提供访问方式
- ClickHouse JDBC Client 说明
实施
ClickHouse 客户端提供多种方式:https://clickhouse.tech/docs/zh/interfaces/,其中JDBC 驱动使用较多:https://clickhouse.tech/docs/zh/interfaces/jdbc/。
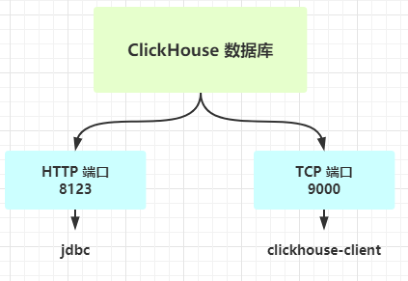
JDBC驱动:https://clickhouse.tech/docs/zh/interfaces/jdbc/
1)、官方驱动:建议使用
https://github.com/ClickHouse/clickhouse-jdbc
添加依赖:
<dependency> <groupId>ru.yandex.clickhouse</groupId> <artifactId>clickhouse-jdbc</artifactId> <version>0.2.6</version> </dependency>
- JDBC 驱动连接地址和驱动类
- JDBC Driver Class:
ru.yandex.clickhouse.ClickHouseDriver- URL syntax:
jdbc:clickhouse://<host>:<port>[/<database>]- 获取连接
Connection,获取Statement对象,进行查询和执行更新操作ClickHouseJDBC Client API步骤与MySQL JDBC 基本一致,都实现Java JDBC API接口。
- 2)、第三方,都是基于官方提供驱动进行优化修改的
- ClickHouse-Native-JDBC
- clickhouse4j
小结
ClickHouse提供JDBC Client方式进行访问,有官方的和第三方的,方便对数据库进行DDL和DML操作。
09-Java 操作 CK之工程环境准备
目标
创建Maven Project工程,添加ClickHouse JDBC依赖。
路径
- 创建Maven Project,基本配置
- 添加POM依赖
- 扩展:数据库面试题
实施
在前面创建好的Maven Projet工程中,创建Maven Module模块,添加依赖:
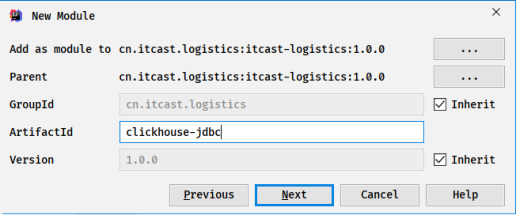
创建相关包,再添加MAVEn依赖
<!-- 指定仓库位置,依次为aliyun、cloudera和jboss仓库 -->
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>jboss</id>
<url>http://repository.jboss.com/nexus/content/groups/public</url>
</repository>
</repositories>
<!-- 版本属性 -->
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<clickhouse>0.2.4</clickhouse>
</properties>
<dependencies>
<!-- Clickhouse -->
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>${clickhouse}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
导入依赖以后,查看clickhouse-jdbc相关jar包结构如下:
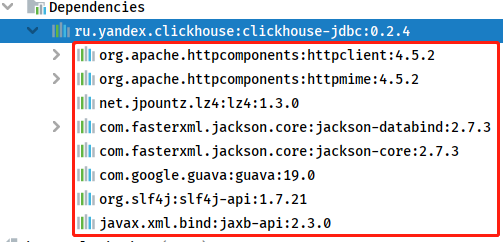
面试题:
- 1)、手写MySQL JDBC 插入数据,整合Spark进行操作
- 将DataFrame数据保存到MySQL表中,考虑数据可以被更新
- MySQL表中,如果主键存在更新数据,如果不存在就是插入数据
- 使用Scala语言
- 2)、手写MySQL JDBC方式查询数据
- 使用Java语言
小结
使用ClickHouse JDBC Client 操作CK表(DDL操作和DML操作),首先创建Maven Project,添加相关依赖。
10-Java 操作 CK之查询代码案例
目标
基于ClickHouse JDBC Client API实现,从CK表中查询数据。
路径
- clickhouse-client 连接,确定查询数据SQL需求
- 创建Java类,编写查询代码并运行
实施
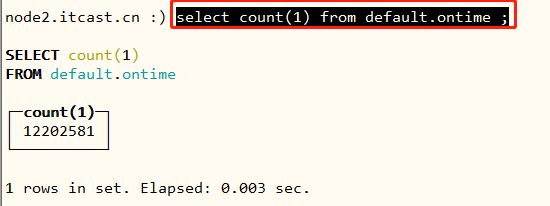
使用CK命令行客户端:clickhouse-client,连接CK服务,从ClickHouse表中读取数据,执行SQL语句:
select count(1) from default.ontime ;
使用Java语言,创建类:ClickHouseJDBCDemo,编写JDBC代码,查询数据,演示代码如下:
package cn.itcast.clickhouse;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
/**
* 编写JDBC代码,从ClickHouse表查询分析数据
* step1. 加载驱动类
* step2. 获取连接Connection
* step3. 创建PreparedStatement对象
* step4. 查询数据
* step5. 获取数据
* step6. 关闭连接
*/
public class ClickHouseJDBCDemo {
public static void main(String[] args) throws Exception{
// 定义变量
Connection conn = null ;
PreparedStatement pstmt = null ;
ResultSet result = null ;
try {
//step1. 加载驱动类
Class.forName("ru.yandex.clickhouse.ClickHouseDriver");
//step2. 获取连接Connection
conn = DriverManager.getConnection(
"jdbc:clickhouse://node2.itcast.cn:8123", "root", "123456"
) ;
//step3. 创建PreparedStatement对象
pstmt = conn.prepareStatement("select count(1) from default.ontime");
//step4. 查询数据
result = pstmt.executeQuery();
//step5. 获取数据
while (result.next()){
System.out.println(result.getLong(1));
}
}catch (Exception e){
e.printStackTrace();
}finally {
//step6. 关闭连接
if(null != result) result.close();
if(null != pstmt) pstmt.close();
if(null != conn) conn.close();
}
}
}
小结
使用ClickHouseJDBC Client API查询CK表的数据,代码几乎与MySQL JDBC API使用一样的,仅仅Driver类名称和URL不同而已。
11-Spark 操作 CK之工程环境准备
目标
明确案例业务需求,创建Maven Module模块,添加CK JDBC和SparkSQL 依赖。
路径
- Spark操作CK需求说明
- 创建Maven Module,添加相关依赖
- 测试创建Maven Module模块
实施
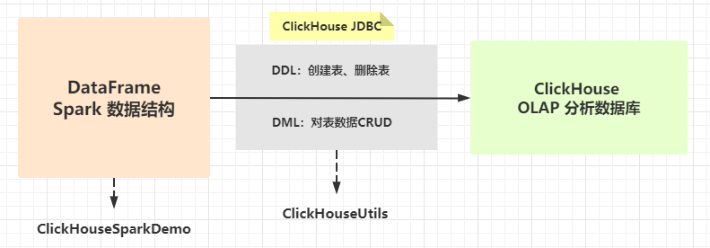
当使用Spark操作Clickhouse数据库时,本质上还是调用ClickHouse JDBC Client API,只不过讲数据封装到DataFrame中,依据DataFrame在CK中创建表、删除表、插入数据、更新数据和删除数据。
任务说明:编写Spark程序,构建数据集DataFrame,调用ClickHouse JDBC API,进行DML操作和DDL操作
创建Maven Module模块,添加依赖
<repositories>
<repository>
<id>mvnrepository</id>
<url>https://mvnrepository.com/</url>
<layout>default</layout>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>elastic.co</id>
<url>https://artifacts.elastic.co/maven</url>
</repository>
</repositories>
<properties>
<!--- Scala -->
<scala.version>2.11.12</scala.version>
<scala.binary.version>2.11</scala.binary.version>
<!-- Spark -->
<spark.version>2.4.0-cdh6.2.1</spark.version>
<!-- Hadoop -->
<hadoop.version>3.0.0-cdh6.2.1</hadoop.version>
<!-- ClickHouse -->
<clickhouse.version>0.2.4</clickhouse.version>
</properties>
<dependencies>
<!-- 依赖Scala语言 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- Spark Core 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Hadoop Client 依赖 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- Clickhouse -->
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>${clickhouse.version}</version>
<exclusions>
<exclusion>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</exclusion>
<exclusion>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<outputDirectory>target/classes</outputDirectory>
<testOutputDirectory>target/test-classes</testOutputDirectory>
<resources>
<resource>
<directory>${project.basedir}/src/main/resources</directory>
</resource>
</resources>
<!-- Maven 编译的插件 -->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
日志属性文件:
log4j.properties
log4j.rootLogger=${root.logger}
root.logger=WARN,console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n
shell.log.level=WARN
log4j.logger.org.spark-project.jetty=WARN
log4j.logger.org.spark-project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO
log4j.logger.org.apache.parquet=ERROR
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
log4j.logger.org.apache.spark.repl.Main=${shell.log.level}
log4j.logger.org.apache.spark.api.python.PythonGatewayServer=${shell.log.level}
小结
至此Spark 操作CK工程构建完成,按照分析业务需求,创建2个对象:
ClickHouseSparkDemo和ClickHouseUtils,具体实现对CK的DDL和DML操作。
12-Spark 操作 CK之编写代码框架
目标
编写Scala对象,读取JSON格式交易订单数据,完成DDL和DML操作框架编写
路径
- 创建对象object,定义业务逻辑步骤
- 编写代码,加载JSON数据
- DDL和DML步骤编写
实施
创建Spark程序,模拟产生业务数据(比如交易订单数据),依据DataFrame数据操作ClickHouse数据库:DDL和DML操作。

package cn.itcast.clickhouse
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* SparkSQL加载JSON格式文件数据,依据Schema信息在ClickHouse中创建表,并进行数据CUD操作
*/
object ClickHouseSparkDemo {
def main(args: Array[String]): Unit = {
// 1. 构建SparkSession实例对象
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
.config("spark.sql.shuffle.partitions", "2")
.getOrCreate()
import spark.implicits._
import org.apache.spark.sql.functions._
// 2. 加载JSON数据:交易订单数据
val ordersDF: DataFrame = spark.read.json("datas/order.json")
/*
root
|-- areaName: string (nullable = true)
|-- category: string (nullable = true)
|-- id: long (nullable = true)
|-- money: string (nullable = true)
|-- timestamp: string (nullable = true)
*/
//ordersDF.printSchema()
/*
+--------+--------+---+-----+--------------------+
|areaName|category|id |money|timestamp |
+--------+--------+---+-----+--------------------+
|北京 |平板电脑|1 |1450 |2019-05-08T01:03.00Z|
|北京 |手机 |2 |1450 |2019-05-08T01:01.00Z|
|北京 |手机 |3 |8412 |2019-05-08T01:03.00Z|
|上海 |电脑 |4 |1513 |2019-05-08T05:01.00Z|
+--------+--------+---+-----+--------------------+
*/
// ordersDF.show(10, truncate = false)
// 3. 依据DataFrame数据集,在ClickHouse数据库中创建表和删除表
// 4. 保存DataFrame数据集到ClickHouse表中
// 5. 更新数据到ClickHouse表中
val updateDF: DataFrame = Seq(
(3, 9999, "2020-12-08T01:03.00Z"),
(4, 9999, "2020-12-08T01:03.00Z")
).toDF("id", "money", "timestamp")
// 6. 删除ClickHouse表中数据
val deleteDF: DataFrame = Seq( Tuple1(1), Tuple1(2), Tuple1(3)).toDF("id")
// 应用结束,关闭资源
spark.stop()
}
}
13-Spark 操作 CK之工具类【基本方法】
目标
创建工具类对象,编写DML操作方法声明和执行DDL语句公共方法及获取Connection连接方法
路径
- 创建对象
- 获取ClickHouse数据连接Connection,编写方法
- 编写对CK表进行CUD操作方法
- 编写公共方法,实现只写DDL语句,创建表和删除表
实施
创建对象:
ClickHouseUtils,后续在其中实现创建表、删除表、插入数据、更新数据集删除数据代码。
无论进行DDL操作还是进行DML操作,都需要进行获取ClickHouse数据库连接,所以定义一个方法,专门获取连接Connection对象。
package cn.itcast.clickhouse
import org.apache.spark.sql.DataFrame
/**
* ClickHouse 工具类,创建表、删除表及对表数据进行CUD操作
*/
object ClickHouseUtils extends Serializable {
/**
* 创建ClickHouse的连接实例,返回连接对象,通过连接池获取连接对象
*
* @param host ClickHouse 服务主机地址
* @param port ClickHouse 服务端口号
* @param username 用户名称,默认用户:default
* @param password 密码,默认为空
* @return Connection 对象
*/
def createConnection(host: String, port: String,
username: String, password: String): ClickHouseConnection = {
// 加载驱动类
Class.forName("ru.yandex.clickhouse.ClickHouseDriver")
// TODO: 使用ClickHouse中提供ClickHouseDataSource获取连接对象
val datasource: ClickHouseDataSource = new ClickHouseDataSource(s"jdbc:clickhouse://${host}:${port}")
// 获取连接对象
val connection: ClickHouseConnection = datasource.getConnection(username, password)
// 返回对象
connection
}
}
ClickHouse 工具类,创建表、删除表及对表数据进行CUD操作
/**
* 插入数据:DataFrame到ClickHouse表
*/
def insertData(dataframe: DataFrame,
dbName: String, tableName: String): Unit = {
}
/**
* 更新数据:依据主键,更新DataFrame数据到ClickHouse表
*/
def updateData(dataframe: DataFrame, dbName: String,
tableName: String, primaryField: String = "id"): Unit = {
}
/**
* 删除数据:依据主键,将ClickHouse表中数据删除
*/
def deleteData(dataframe: DataFrame, dbName: String,
tableName: String, primaryField: String = "id"): Unit = {
}
需要依据DataFrame中Schema信息,要在ClickHouse中创建表和删除表操作,进行DDL操作时,就是执行DDL 语句即可,此时可以编写方法,专门执行DDL 语句即可。
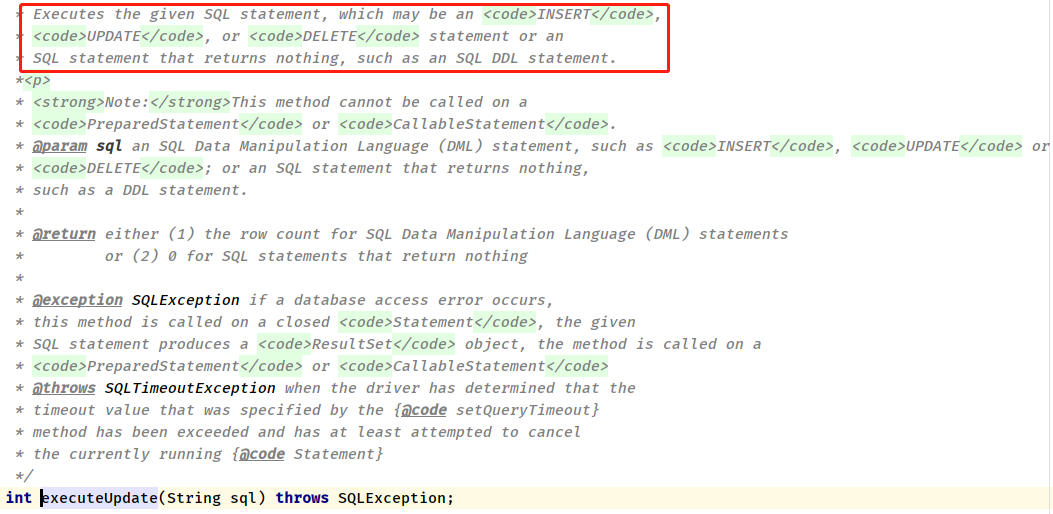
/**
* 传递Connection对象和SQL语句对ClickHouse发送请求,执行更新操作
*
* @param sql 执行SQL语句或者DDL语句
*/
def executeUpdate(sql: String): Unit = {
// 声明变量
var conn: ClickHouseConnection = null
var pstmt: ClickHouseStatement = null
try{
// a. 获取ClickHouse连接对象
conn = ClickHouseUtils.createConnection("node2.itcast.cn", "8123", "root", "123456")
// b. 获取PreparedStatement实例对象
pstmt = conn.createStatement()
// c. 执行更新操作
pstmt.executeUpdate(sql)
}catch {
case e: Exception => e.printStackTrace()
}finally {
// 关闭连接
if (null != pstmt) pstmt.close()
if (null != conn) conn.close()
}
}
工具类中ClickHouseUtils中,进行基本功能封装方法,完整代码如下所示:
package cn.itcast.clickhouse.spark
import org.apache.spark.sql.DataFrame
import ru.yandex.clickhouse.{ClickHouseConnection, ClickHouseDataSource, ClickHouseStatement}
/**
* 工具类,对ClickHouse数据库进行DDL(创建表和删除表)和DML(CUD)操作方法封装。
*/
object ClickHouseUtils extends Serializable {
/**
* 创建ClickHouse的连接实例,返回连接对象,通过连接池获取连接对象
*
* @param host ClickHouse 服务主机地址
* @param port ClickHouse 服务端口号
* @param username 用户名称,默认用户:default
* @param password 密码,默认为空
* @return Connection 对象
*/
def createConnection(host: String, port: String,
username: String, password: String): ClickHouseConnection = {
// 加载驱动类
Class.forName("ru.yandex.clickhouse.ClickHouseDriver")
// TODO: 使用ClickHouse中提供ClickHouseDataSource获取连接对象
val datasource: ClickHouseDataSource = new ClickHouseDataSource(s"jdbc:clickhouse://${host}:${port}")
// 获取连接对象
val connection: ClickHouseConnection = datasource.getConnection(username, password)
// 返回对象
connection
}
/* ================ TODO: DML操作,封装方法 =============================== */
/**
* 插入数据:DataFrame到ClickHouse表
*/
def insertData(dataframe: DataFrame, dbName: String, tableName: String): Unit = {
}
/**
* 更新数据:依据主键,更新DataFrame数据到ClickHouse表
*/
def updateData(dataframe: DataFrame, dbName: String, tableName: String, primaryField: String = "id"): Unit = {
}
/**
* 删除数据:依据主键,将ClickHouse表中数据删除
*/
def deleteData(dataframe: DataFrame, dbName: String, tableName: String, primaryField: String = "id"): Unit = {
}
/* ================ TODO: DDL操作,封装方法 =============================== */
// 在数据库ClickHouse或者MySQL中,创建表和删除表,执行DDL语句即可(CREATE 语句和DROP 语句)
/**
* 传递Connection对象和SQL语句对ClickHouse发送请求,执行更新操作
*
* @param sql 执行SQL语句或者DDL语句
*/
def executeUpdate(sql: String): Unit = {
// 声明变量
var conn: ClickHouseConnection = null
var pstmt: ClickHouseStatement = null
try{
// a. 获取ClickHouse连接对象
conn = ClickHouseUtils.createConnection("node2.itcast.cn", "8123", "root", "123456")
// b. 获取PreparedStatement实例对象
pstmt = conn.createStatement()
// c. 执行更新操作:可以是DDL语句
pstmt.executeUpdate(sql)
}catch {
case e: Exception => e.printStackTrace()
}finally {
// 关闭连接
if (null != pstmt) pstmt.close()
if (null != conn) conn.close()
}
}
}
小结
基于DataFrame数据集,操作CK数据库时,进行DDL和DML操作,封装到不同方法中,后期只要实现即可。
14-Spark 操作 CK之工具类【创建表】
目标
依据DataFrame中Schema信息,构建创建表DDL语句,并在ClickHouse数据库创建表。
路径
- 创建表DDL语句
- 依据Schema构建DDL语句思路
- 编程实现构建DDL语句
实施
需要构建
创建表DDL语句,依据DataFrame中Schema信息,如下为创建表语句模板:
CREATE TABLE IF NOT EXISTS test.tbl_order (
areaName String,
category String,
id Int64,
money String,
timestamp String,
sign Int8,
version Int8
)
ENGINE=VersionedCollapsingMergeTree(sign, version)
ORDER BY id ;
分析思路:创建ClickHouse表的关键就是构建创建表的DDL语句
核心点:依据DataFrame中Schema信息(字段名称和字段类型)转换为ClickHouse中列名称和列类型,拼凑字符串即可。

编程实现语句构建,代码如下:
/**
* 依据DataFrame数据集中约束Schema信息,构建ClickHouse表创建DDL语句
*
* @param dbName 数据库的名称
* @param tableName 表的名称
* @param schema DataFrame数据集约束Schema
* @param primaryKeyField ClickHouse表主键字段名称
* @return ClickHouse表创建DDL语句
*/
def createTableDdl(dbName: String, tableName: String,
schema: StructType, primaryKeyField: String = "id"): String = {
/*
areaName String,
category String,
id Int64,
money String,
timestamp String,
*/
val fieldStr: String = schema.fields.map{field =>
// 获取字段名称
val fieldName: String = field.name
// 获取字段类型
val fieldType: String = field.dataType match {
case StringType => "String"
case IntegerType => "Int32"
case FloatType => "Float32"
case LongType => "Int64"
case BooleanType => "UInt8"
case DoubleType => "Float64"
case DateType => "Date"
case TimestampType => "DateTime"
case x => throw new Exception(s"Unsupported type: ${x.toString}")
}
// 组合字符串
s"${fieldName} ${fieldType}"
}.mkString(",n")
// 构建创建表DDL语句
val createDdl: String = s"""
|CREATE TABLE IF NOT EXISTS ${dbName}.${tableName} (
|${fieldStr},
|sign Int8,
|version UInt64
|)
|ENGINE=VersionedCollapsingMergeTree(sign, version)
|ORDER BY ${primaryKeyField}
|""".stripMargin
// 返回DDL语句
createDdl
}
小结
依据Schema信息,构建Create Table创建表的DDL语句,核心在于获取字段名称和类型,拼凑字符串即可。
15-Spark 操作 CK之工具类【删除表】
目标
依据表名称构建删除表DDL语句,执行删除ClickHouse中表。
路径
- 删除表的DDL语句
- 依据表名称构建DDL语句,封装到方法中
- 代码测试,删除表是否成功
实施
当删除ClickHouse中表时,只要执行如下DDL语句即可:
DROP TABLE IF EXISTS test.tbl_orders ;
在工具类中,编写一个方法,构建删除表的DDL语句,代码如下:
/**
* 依据数据库名称和表名称,构建ClickHouse中删除表DDL语句
*
* @param dbName 数据库名称
* @param tableName 表名称
* @return 删除表的DDL语句
*/
def dropTableDdl(dbName: String, tableName: String): String = {
s"DROP TABLE IF EXISTS ${dbName}.${tableName}"
}
小结
无论创建表还是删除表,核心在于首先
构建出DDL语句,再executeUpdate执行即可。
16-Spark 操作 CK之工具类【插入SQL】
目标
依据DataFrame中每行数据Row构建
插入INSERT语句
路径
- 插入数据INSERT语句
- Row数据构建INSERT语句思路
- 编程实现INSERT语句构建
实施
实现将DataFrame数据集中数据保存到ClickHouse表中,其中需要将DataFrame中每条数据Row,构建一条插入INSERT语句:
INSERT INTO test.tbl_order (areaName, category, id, money, timestamp, sign, version) VALUES ('北京', '平板电脑', 1, '1450', '2019-05-08T01:03.00', 1, 1);
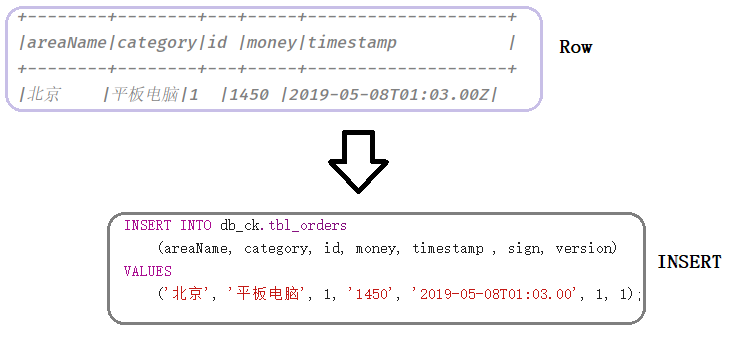
实现代码,据图如下所示:
/**
* 构建数据插入ClickHouse中SQL语句
*
* @param dbName 数据库名称
* @param tableName 表的名称
* @param columns 列名称
* @return INSERT 插入语句
*/
def createInsertSQL(dbName: String, tableName: String, columns: Array[String] ): String = {
// 所有列名称字符串 -> areaName, category, id, money, timestamp
val fieldsStr: String = columns.mkString(", ")
// 所有列对应值的占位符 -> ?, ?, ?, ?, ?
val valuesStr: String = columns.map(_ => "?").mkString(", ")
// 插入INSERT SQL语句
s"""
|INSERT INTO ${dbName}.${tableName} (${fieldsStr}, sign, version) VALUES (${valuesStr}, 1, 1);
|""".stripMargin
}
小结
当构建插入数据语句时,核心点在于获取所有列名称,INSERT语句中使用占位符【?】代替具体的值,后期再进行设置,目的防止SQL注入。
17-Spark 操作 CK之工具类【插入数据】
目标
编程实现方法:
insertData,将DataFrame数据插入至ClickHouse表。
路径
- DataFrame数据集针对分区进行插入
- 优化代码,每分区数据批量插入
- 运行程序测试,clickhouse-client查看表数据
实施
将DataFrame数据转换为INSERT语句,并且对INSERT语句中占位符进行赋值操作,尤其注意,针对DataFrame每个分区数据进行操作,最后批量插入到表中。
/**
* 插入数据:DataFrame到ClickHouse表
*/
def insertData(dataframe: DataFrame, dbName: String, tableName: String): Unit = {
// 获取DataFrame中Schema信息
val schema: StructType = dataframe.schema
// 获取DataFrame中所有列名称
val columns: Array[String] = dataframe.columns
// 构建INSERT语句
val insertSql: String = createInsertSQL(dbName, tableName, columns)
// TODO:针对每个分区数据进行操作,每个分区的数据进行批量插入
dataframe.foreachPartition{iter =>
// 声明变量
var conn: ClickHouseConnection = null
var pstmt: PreparedStatement = null
try{
// a. 获取ClickHouse连接对象
conn = ClickHouseUtils.createConnection("node2.itcast.cn", "8123", "root", "123456")
// b. 构建PreparedStatement对象
pstmt = conn.prepareStatement(insertSql)
// TODO: c. 遍历每个分区中数据,将每条数据Row值进行设置
var counter: Int = 0
iter.foreach{row =>
// 从row中获取每列的值,和索引下标 -> 通过列名称 获取 Row中下标索引 , 再获取具体值
columns.foreach{column =>
// 通过列名称 获取 Row中下标索引
val index: Int = schema.fieldIndex(column)
// 依据索引下标,从Row中获取值
val value: Any = row.get(index)
// 进行PreparedStatement设置值
pstmt.setObject(index + 1, value)
}
pstmt.setObject(columns.length + 1, 1)
pstmt.setObject(columns.length + 2, 1)
// 加入批次
pstmt.addBatch()
counter += 1
// 判断counter大小,如果大于1000 ,进行一次批量插入
if(counter >= 1000) {
pstmt.executeBatch()
counter = 0
}
}
// d. 批量插入
pstmt.executeBatch()
}catch {
case e: Exception => e.printStackTrace()
}finally {
// e. 关闭连接
if(null != pstmt) pstmt.close()
if(null != conn) conn.close()
}
}
}
运行Spark程序,查看ClickHouse表中数据,如下图所示:
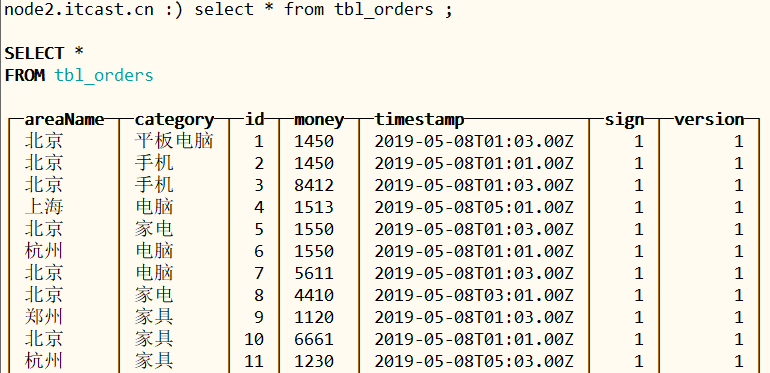
小结
将DataFrame数据插入保存到CK表中时,首先针对分区进行操作,每个分区中数据进行批量插入,此外批量插入时需要考虑数据量,可以设置每批次最大数据量,满足即批量插入。
18-Spark 操作 CK之工具类【更新数据】
目标
将更新数据集DataFrame更新到ClickHouse表中,方法
updateData编程实现。
路径
- 使用ALTER实现更新Update语句
- 更新数据集DataFrame构建Update语句思路
- 数据更新方法:updateData,编程实现
实施
对ClickHouse表的数据进行更新操作,在ClickHouse数据库中,更新数据,使用
ALTER语法实现。
ALTER TABLE test.tbl_order UPDATE money = '9999', timestamp = '2020-12-08T01:03.00Z' WHERE id = 3 ;
更新订单数据,如下所示:
val updateDF: DataFrame = Seq(
(3, 9999, "2020-12-08T01:03.00Z"),
(4, 9999, "2020-12-08T01:03.00Z")
).toDF("id", "money", "timestamp")
将要更新的数据Row,转换为ALTER UPDATE 更新语句。

首先完成更新数据方法整体结构代码,如下所示:
/**
* 将DataFrame数据集更新至ClickHouse表中,依据主键进行更新
*
* @param dbName 数据库名称
* @param tableName 表名称
* @param dataframe 数据集DataFrame,更新的数据,其中要包含主键
*/
def updateData(dataframe: DataFrame, dbName: String,
tableName: String, primaryField: String = "id"): Unit = {
// 对DataFrame每个分区数据进行操作
dataframe.foreachPartition{iter =>
// 声明变量
var conn: ClickHouseConnection = null
var pstmt: ClickHouseStatement = null
try{
// a. 获取ClickHouse连接对象
conn = ClickHouseUtils.createConnection("node2.itcast.cn", "8123", "root", "123456")
// b. 构建PreparedStatement对象
pstmt = conn.createStatement()
// TODO: 遍历分区中每条数据Row,构建更新Update语句,进行更新操作
iter.foreach{row =>
// b. 依据Row对象,创建更新SQL语句
// ALTER TABLE db_ck.tbl_orders UPDATE money = '9999', timestamp = '2020-12-08T01:03.00Z' WHERE id = 3 ;
val updateSql: String = createUpdateSQL(dbName, tableName, row)
// d. 执行更新操作
pstmt.executeUpdate(updateSql)
}
}catch {
case e: Exception => e.printStackTrace()
}finally {
// e. 关闭连接
if(null != pstmt) pstmt.close()
if(null != conn) conn.close()
}
}
}
小结
将更新数据集DataFrame中每条数据更新到CK表中时,同样调用PraparedStatement对象中executeUpdate方法,核心在于如何将每条数据Row转换为update更新语句。
19-Spark 操作 CK之工具类【更新语句】
目标
将更新数据集DataFrame中每条数据Row,转换为update语句
路径
- Row数据构建更新Update语句思路
- 编程实现Update语句构建
- 运行程序测试,clickhouse-client查看表数据
实施
依据Row对象(每条数据)构建UPDATE更新语句,思路如下所示:
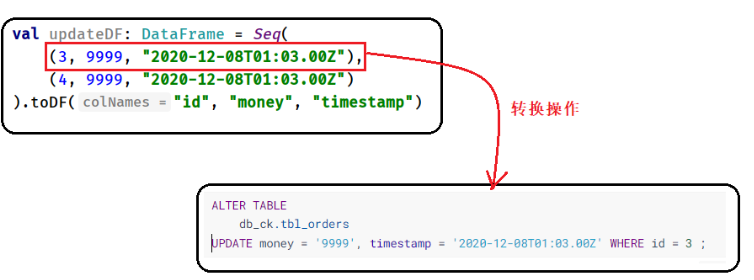
具体代码实现,如下所示:
/**
* 构建数据更新ClickHouse表中SQL语句
*
* @param dbName 数据库名称
* @param tableName 表名称
* @param row DataFrame中每行数据
* @param primaryKeyField 主键列
* @return update更新SQL语句
*/
def createUpdateSQL(dbName: String, tableName: String,
row: Row, primaryKeyField: String = "id"): String = {
/*
id money timestamp
Row: 3, 9999, "2020-12-08T01:03.00Z"
|
money = '9999', timestamp = '2020-12-08T01:03.00Z'
*/
val updatesStr: String = row.schema.fields
.map(field => field.name) // 获取所有列名称
// 过滤主键列名称
.filter(columnName => ! primaryKeyField.equals(columnName))
// 依据列名称获取对应的值
.map{columnName =>
val columnValue: Any = getFieldValue(row, columnName)
s"${columnName} = '${columnValue}'"
}.mkString(", ")
// 获取主键的值
val primaryKeyValue: Any = getFieldValue(row, primaryKeyField)
// 构建UPDATE更新SQL语句
s"""
|ALTER TABLE ${dbName}.${tableName}
| UPDATE ${updatesStr} WHERE ${primaryKeyField} = ${primaryKeyValue} ;
|""".stripMargin
}
小结
在将Row数据转换为Update更新语句时,核心在于依据列名称获取对应值,拼凑字符串。
20-Spark 操作 CK之工具类【删除数据】
目标
依据主键primaryKey删除ClickHouse表中数据。
路径
- 删除数据Delete语句
- 实现方法:
deleteData,依据主键删除数据- 运行程序测试,clickhouse-client查看表数据
实施
在ClickHouse数据库中,如果对表中数据进行删除时,主要依据主键进行删除,依然与更新数据类似使用
ALTER语法实现删除操作
ALTER TABLE test.tbl_order DELETE WHERE id = "3" ;
构建出要删除DataFrame,只包含一个字段信息,就是主键id,代码如下所示:
val deleteDF: DataFrame = Seq( Tuple1(1), Tuple1(2), Tuple1(3)).toDF("id")
实现删除数据代码,方法:
deleteData,如下所示:
/**
* 删除数据:依据主键,将ClickHouse表中数据删除
*/
def deleteData(dataframe: DataFrame, dbName: String,
tableName: String, primaryField: String = "id"): Unit = {
// 对DataFrame每个分区数据进行操作
dataframe.foreachPartition{iter =>
// 声明变量
var conn: ClickHouseConnection = null
var pstmt: ClickHouseStatement = null
try{
// a. 获取ClickHouse连接对象
conn = ClickHouseUtils.createConnection("node2.itcast.cn", "8123", "root", "123456")
// b. 构建PreparedStatement对象
pstmt = conn.createStatement()
// TODO: 遍历分区中每条数据Row,构建更新Update语句,进行更新操作
iter.foreach{row =>
// b. 依据Row对象,创建删除SQL语句
// ALTER TABLE db_ck.tbl_orders DELETE WHERE id = "3" ;
val deleteSql: String = s"ALTER TABLE ${dbName}.${tableName} DELETE WHERE ${primaryField} = ${getFieldValue(row, primaryField)} ;"
// d. 执行更新操作
pstmt.executeUpdate(deleteSql)
}
}catch {
case e: Exception => e.printStackTrace()
}finally {
// e. 关闭连接
if(null != pstmt) pstmt.close()
if(null != conn) conn.close()
}
}
}
小结
删除ClickHouse表的数据时,依据主键primaryKey删除,构建Delete删除语句为核心。
最后
以上就是忧郁鸵鸟最近收集整理的关于ClickHouse API 使用ClickHouse API 使用的全部内容,更多相关ClickHouse内容请搜索靠谱客的其他文章。








发表评论 取消回复