- BS4介绍
- BS4的官方文档教程
- 安装BeautifulSoup包
-
-
- Windows安装BeautifulSoup环境
- Ubuntu下安装BS4
-
-
- Eclipse下配置Python环境
-
- Windows下
- Step1添加pydev插件
- Step2配置工程python编译器
- Step3Eclipse下创建Python工程
- Ubuntu下
- Step1添加pydev插件
- Windows下
-
- 安装BeautifulSoup解析器
- 使用BS4过滤器
- BeautifulSoup载入文档方法如下
- BS4的一次可靠的网络连接
- 较为安全可靠的网络请求代码
- 使用BS4快速定位标签
- BS4中常用方法介绍
-
- find定位第一次出现的标签
- find_all定位多次出现的标签
- 使用标签和属性组合定位标签
- 处理子标签兄弟标签父标签
- 获取标签的属性值和内容值
- 也可以配合Lambda表达式
-
- BS4应用实例
- 获取属性和内容
- 子标签兄弟标签父标签实例代码
- 子标签遍历代码
- 兄弟标签遍历代码
- 父标签遍历代码
- BS4中常用方法介绍
- BS4实战-获取百度贴吧内容
- 任务目标
- 网页分析
- URL分析
- 可以看出页数增加1对于的pn参数值增加50
- URL里指定了ieutf-8 kw后跟的参数应该就是权力的游戏的UTF-8码
- 数据分析
- URL分析
- 工程实现
- 创建工程
- 定义log模块用于调试记录操作数据
- 定义getCommentInfo模块用于实现页面的数据抓取
- mylog类
- getCommemntInfo类
- 执行结果
- 创建工程
- BS4实战-获取双色球中奖信息
- 任务目标
- 网页分析
- URL分析
-
- 可以看出URL的规律在于list_x
- 分析请求的地址的最大页
-
- 数据分析
- 将记录的数据存储到Excel
- 导入工具包
- 操作程序示例如下
- URL分析
- 工程实现
- 创建工程
- 定义log模块用于调试记录操作数据
- 定义save2excel模块用于将数据存储到excel中
- 定义completeBook模块
- mylog类同上
- 操作excel的save2excel类
- getWinningNum类
- 执行结果
- 创建工程
- BS4实战-获取起点小说信息
- 任务目标
- 网页分析
- URL分析
- 分析请求的地址的最大页
- 数据分析
- 将记录的数据保存到MySQL
- 保存到本地mysql
- 在Linux上安装MySQL使用指令
- 操作数据库
- 安装MySQLdb模块
- 连接到数据库程序示例
- 保存到同网段的其他装有mysql的服务机
- 分析网络
- 操作数据库同上
- 连接到数据库同上
- 保存到本地mysql
- URL分析
- 工程实现
- 创建工程
- 定义log模块用于调试记录操作数据
- 定义save2mysql模块用于将数据存储到mysql中
- 定义completeBook模块
- mylog类同上
- 操作mysql的save2mysql类
- completeBook类
- 执行结果
- 创建工程
- BS4实战-获取电影信息
- 任务目标
- 网页分析
- URL分析
- 可以看出不同页数区别在于后面的2016xhtml的x参数
- 分析请求的地址的最大页
- 数据分析
- 反爬虫处理
- 修改爬虫程序的Headers
- 使用代理更改访问的IP地址
- URL分析
- 工程实现
- 创建工程
- 定义log模块用于调试记录操作数据
- 定义get2016movie模块用于实现页面的数据抓取
- mylog类同上
- get2016movie类
- 执行结果
- 创建工程
- BS4实战-获取音悦台榜单
- 任务目标
- 网页分析
- URL分析
- 可以看出同一榜单的URL区别在于page参数
- 分析不同的榜单发现区别在于area参数
- 数据分析
- URL分析
- 工程实现
- 创建工程
- 定义log模块用于调试记录操作数据
- 定义resource模块用于存储headers和proxy资料
- 定义getTrendsMV模块用于实现页面的数据抓取
- 反爬虫处理
- mylog类同上
- resource类
- getTrendsMV类
- 执行结果
- 创建工程
- 参考资料
BS4介绍
BeautifulSoup是Python的第三方库,它通过定位HTML标签来格式化和组织复杂的网络信息,用简单的Python对象展现XML结构信息.
BS4的官方文档教程
地址:点这里
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
安装BeautifulSoup包
Windows安装BeautifulSoup环境
pip install beautifulsoup4Ubuntu下安装BS4
sudo apt-get install python-bs4Eclipse下配置Python环境
Windows下
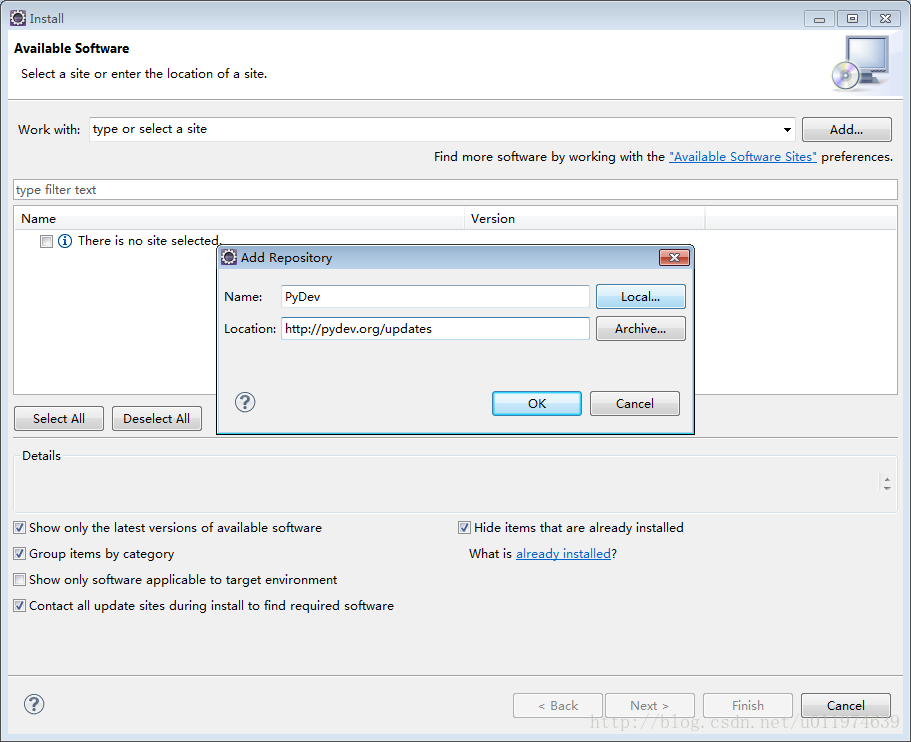
Step1:添加pydev插件
菜单Help|Install New Software选项|Add..里
- Name:插件的名称(自定义)
- Location:下载地址
可以先下载离线包安装
如果本地的JAVA环境为1.7则pydev配置地址为:
http://www.pydev.org/update_sites/4.5.5/
如果已经误装了高版本的软件包,在Help|About Eclipse|Installation Details内找到已安装的插件包删除即可)
JAVA环境为1.8则如图配置即可.
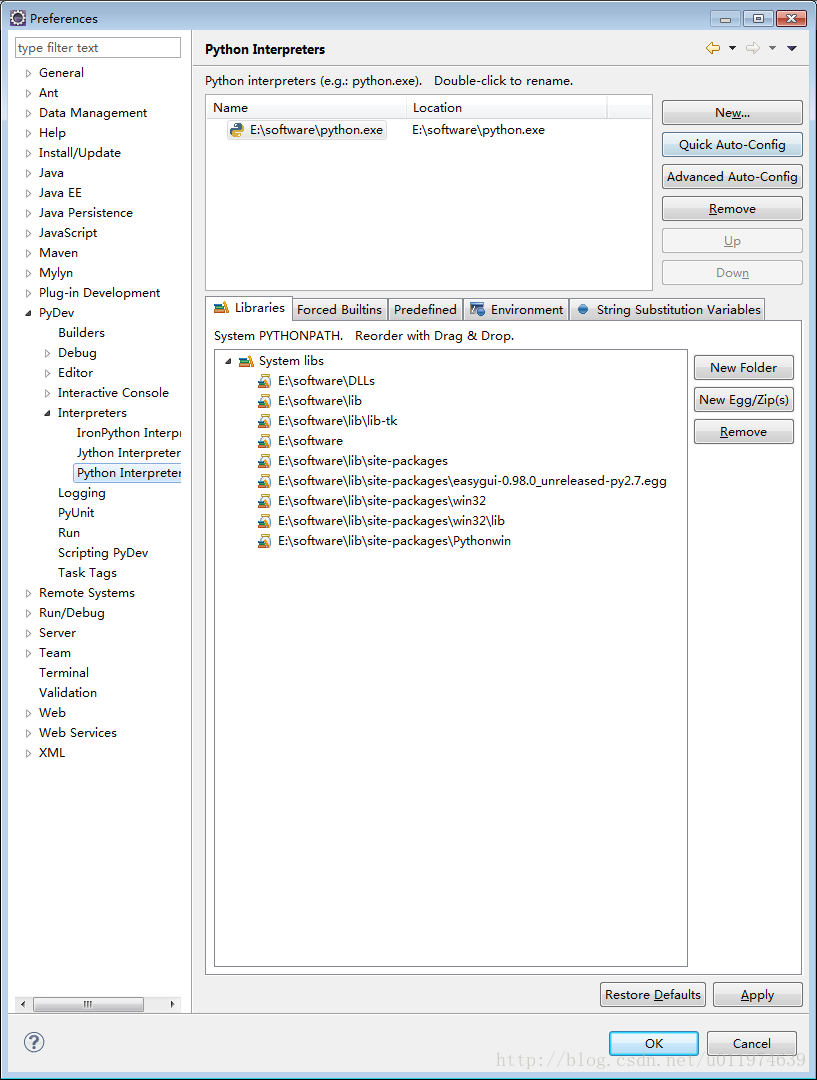
Step2:配置工程python编译器
选项Windows|Preferences|左侧pyDev|Interpreter|Python Interpreter
将本地的python.exe安装路径添加进来.
Step3:Eclipse下创建Python工程
File|Project…|PyDev|PyDev Project 配置项目名称即可。
选择demo工程右键New选择创建Python Module|Python Package.
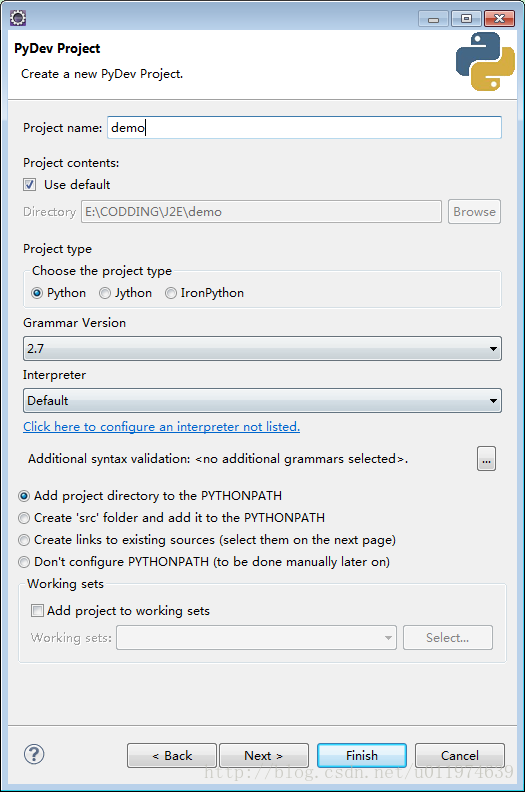
如果创建文件或文件夹,一般选择Module或者Package选项,因为这两个比创建一般的File和Folder多了预设模板.
Ubuntu下
Step1:添加pydev插件
菜单Help|Install New Software选项|Add..里
这里与Windows不同的是,插件只选择一个
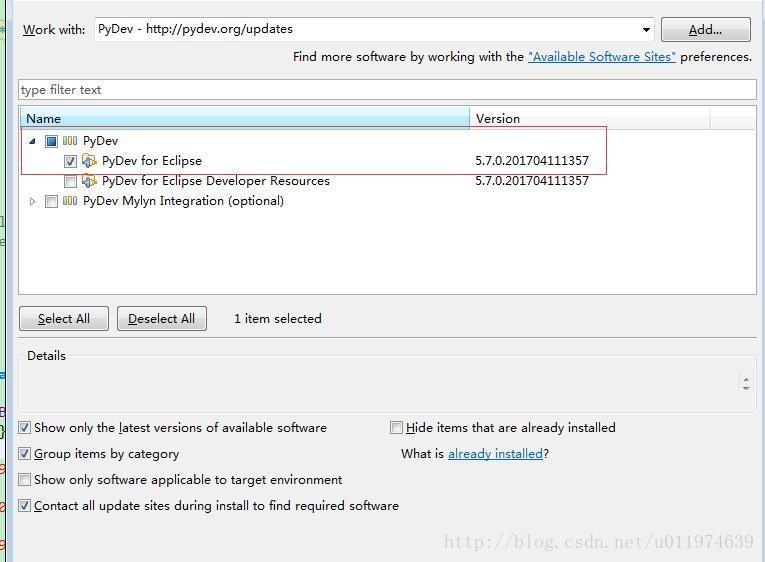
#### Step2:其他的与windows类似
安装BeautifulSoup解析器
与Scrapy相比,bs4则在接受数据和进行过滤之间多了一道解析的过程,根据解析器不同,最终处理的数据也不同.
bs4支持的常用解析器如下:
| 解析器 | 使用方法 | 优点 | 缺点 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(makeup,”html.parser”) | 标准库、速度中、容错强 | 中文容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(makeup,”lxml”) | 速度快、容错能力强 | 需要C语言库 |
| Lxml XML解析器 | BeautifulSoup(makeup,[“lxml-xml”]) BeautifulSoup(makeup,”xml”) | 速度快、唯一支持XML解析器 | 需要C语言库 |
| html5lib | BeautifulSoup(makeup,”html5lib”) | 容错强、以浏览器方式解析文档 生成HTML5格式文档 | 速度慢、不依赖外部扩展 |
使用pip安装
pip install lxml #lxml在使用Scrapy时候已经安装过使用BS4过滤器
Scrapy有CSS和XPath过滤器,BS4有BeautifulSoup过滤器.
BeautifulSoup载入文档方法如下:
__init__(self, markup="",
features=None, builder=None,parse_only=None,
from_encoding=None,exclude_encodings=None,
**kwargs)
# builder:指定的解析器
# exclude_encoding:是排除编码格式
# from_encoding:是指定编码格式
BeautifulSoup(exclude_encoding=['utf-16','gb2313'],from_encoding='utf-8')
一般BeautifulSoup函数会自己尝试解析编码格式,使用BeautifulSoup方法指定lxml解析器:
soup = BeautifulSoup(open('scenery.html'),'lxml') #指定lmxl解析器得到soup这个bs4的类对象,bs4将网页节点解析成一个个Tag.
BS4的一次可靠的网络连接:
BS4常配合urllib库使用,在网络访问中,urlopen(url)可能会发生两种情况:
- 网页在服务器不存在
- 服务器不存在
这样可能会抛出HTTPError,URLError.有时urlopen会返回一个None,如果后续代码对urlopen返回对象有操作,可能会抛出AttributeError异常.
对于这些情况要做好处理.
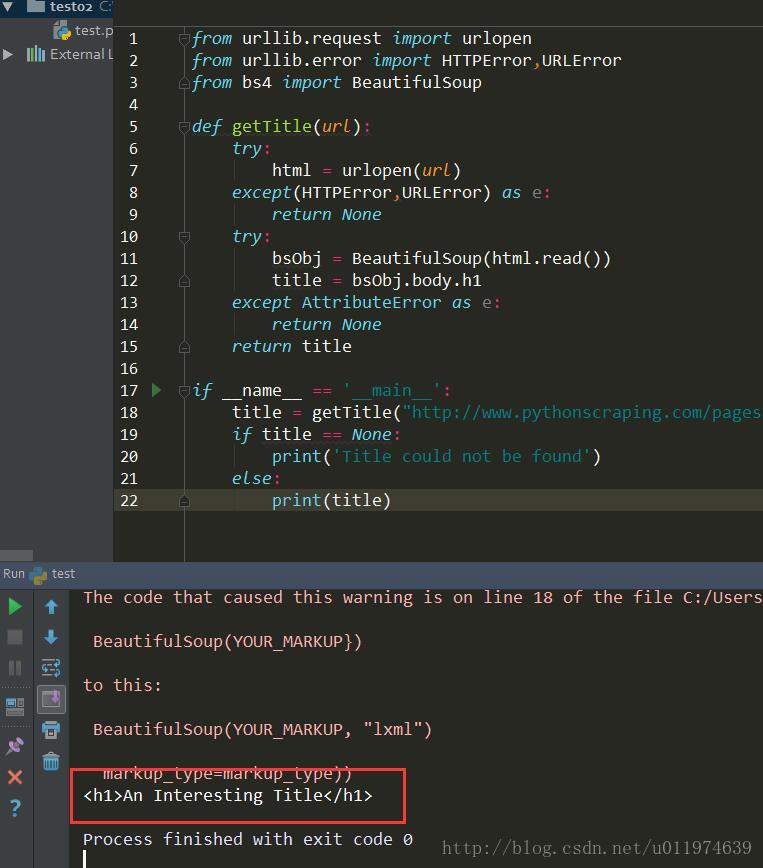
较为安全可靠的网络请求代码
针对http://www.pythonscraping.com/pages/page1.html网站获取标题.(需要科学上网)
from urllib.request import urlopen
from urllib.error import HTTPError,URLError
from bs4 import BeautifulSoup
def getTitle(url):
try:
html = urlopen(url)
except(HTTPError,URLError) as e:
return None
try:
bsObj = BeautifulSoup(html.read())
title = bsObj.body.h1
except AttributeError as e:
return None
return title
if __name__ == '__main__':
title = getTitle("http://www.pythonscraping.com/pages/page1.html")
if title == None:
print('Title could not be found')
else:
print(title)运行结果
使用BS4快速定位标签
大多数网站都会有层叠样式表(CSS),CSS让HTML元素呈现差异化,有利于网络爬虫的快速定位。
BS4中常用方法介绍
soup.find(tag, attrs={}, recursive=True, text=None,keywords)
soup.find_all(tag, attrs={}, recursive=True, text=None,limit=None, keywords)
#tag为标签名称
#attrs为一个列表,为属性的列表:例如{'class':'v_page'}表示class='v_page'
#recursive表示是否递归查找,默认为True
#text表示查找以内容查找
#keywords是一个键值对,选择具有指定属性的标签 例如find_all(id='text')找到id='text'的标签,等价于find_all("",{'id':'text'})
find()定位第一次出现的标签
如果某个标签只出现一次,比如head/title标签。常使用soup.head和soup.title方式获取标签内容。
使用soup.find(Tag,[attrs])获取第一次出现的标签的内容
soup.find('ul') #找出第一次出现的标签内容find_all()定位多次出现的标签
使用soup.find_all(Tag,[attrs])获取所有符合条件的标签列表.
soup.find_all('ul') #返回标签列表
soup.find_all('ul')[0]
soup.find_all('ul')[1]这样方法在列表元素过多时候以列表下标的形式获取节点内容不太方便.
使用标签和属性组合定位标签
可以注意到soup.find_all(Tag,[attrs])和soup.find(Tag,[attrs])都有一个可选的参数[attrs],这意味着这两个方法支持用Tag和attrs组合定位标签.
例如要
soup.find('li',attrs={'nu':'3'}) #寻找到标签为li,属性nu为3的标签节点。
soup.find({'li','h1','h2'}) #寻找第一次出现的标签为li|h1|h2
soup.find('li',attrs={'nu':{'3','4','5'}}) #第一次出现的标签为li,nu属性为3|4|5
soup.find_all({'li','h1',{'id'={'text','submit'}}})处理子标签兄弟标签父标签
在处理标签同时,可以处理与之相关的标签
#子标签
tag.children() #找出所有子标签
tag.descendants() #找出所有后代标签
#兄弟标签
tag.next_siblings() #找出同级的后序标签
tag.previous_siblings() #找出同级的前序标签
#父标签
tag.parent() #找出父标签获取标签的属性值和内容值
对于定位好的标签,可以使用get_text()标签内容,attrs[‘xxx’]获取指定的xxx属性内容.
tag.attrs #代表一个标签的所有属性字典
tag.attrs['src'] #获取到tag标签内的src的属性值
tag.get_text() #获取tag标签内容也可以配合Lambda表达式
例如:
soup.find_all(lambda tag:len(tag.attrs==2)) #找出有两个属性值的标签BS4应用实例
scenery.html页面
<html>
<head>
<meta charset="utf-8">
<title>合肥旅游景点</title>
<meta name="descrption" content="合肥旅游景点 精简版" />
<meta name="author" content="hstking">
</head>
<body>
<div id="content">
<div class="title">
<h3>合肥景点 </h3>
</div>
<ul class="table">
<li>景点 <a>门票价格</a></li>
</ul>
<ul class="content">
<li nu="1">斛兵塘 <a class="price">60</a></li>
<li nu="1">合肥 <a class="price">10</a></li>
<li nu="1">万达 <a class="price">20</a></li>
<li nu="1">城隍庙 <a class="price">30</a></li>
<li nu="1">合工大 <a class="price">40</a></li>
</ul>
</div>
</body>
</html>获取属性和内容
from bs4 import BeautifulSoup
soup = BeautifulSoup(open('scenery.html'))
ContentTag = soup.find('ul',attrs={'class':'content'})
#找到<li>合肥这个标签,获取属性值
hfTag = ContentTag.find_all('li')[1]
print(hfTag.get_text())
print(hfTag.attrs['nu'])
print('n')
输出
合肥 10
1子标签/兄弟标签/父标签实例代码
子标签遍历代码
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
soup = BeautifulSoup(open('scenery.html'))
ContentTag = soup.find('ul',attrs={'class':'content'})
print('children text:')
for children in ContentTag.children:
print(children)
print('n')
print('descendants text:')
for children in ContentTag.descendants:
print(children)
print('n')输出:
children text:
<li nu="1">斛兵塘 <a class="price">60</a></li>
<li nu="1">合肥 <a class="price">10</a></li>
<li nu="1">万达 <a class="price">20</a></li>
<li nu="1">城隍庙 <a class="price">30</a></li>
<li nu="1">合工大 <a class="price">40</a></li>
descendants text:
<li nu="1">斛兵塘 <a class="price">60</a></li>
斛兵塘
<a class="price">60</a>
60
<li nu="1">合肥 <a class="price">10</a></li>
合肥
<a class="price">10</a>
10
<li nu="1">万达 <a class="price">20</a></li>
万达
<a class="price">20</a>
20
<li nu="1">城隍庙 <a class="price">30</a></li>
城隍庙
<a class="price">30</a>
30
<li nu="1">合工大 <a class="price">40</a></li>
合工大
<a class="price">40</a>
40兄弟标签遍历代码
print('next_siblings text:')
for brother in ContentTag.next_siblings:
print(brother)
print('n')
print('previous_siblings text:')
for brother in ContentTag.previous_siblings:
print(brother)
print('n') 输出:
next_siblings text:
previous_siblings text:
<ul class="table">
<li>景点 <a>门票价格</a></li>
</ul>
<div class="title">
<h3>合肥景点 </h3>
</div>父标签遍历代码
print('parent text:')
print(ContentTag.parent)
print('n')
print('parents text:')
for parent in ContentTag.parents:
print(parent)
print('n')输出:
parent text:
<div id="content">
<div class="title">
<h3>合肥景点 </h3>
</div>
<ul class="table">
<li>景点 <a>门票价格</a></li>
</ul>
<ul class="content">
<li nu="1">斛兵塘 <a class="price">60</a></li>
<li nu="1">合肥 <a class="price">10</a></li>
<li nu="1">万达 <a class="price">20</a></li>
<li nu="1">城隍庙 <a class="price">30</a></li>
<li nu="1">合工大 <a class="price">40</a></li>
</ul>
</div>
parents text:
<div id="content">
<div class="title">
<h3>合肥景点 </h3>
</div>
<ul class="table">
<li>景点 <a>门票价格</a></li>
</ul>
<ul class="content">
<li nu="1">斛兵塘 <a class="price">60</a></li>
<li nu="1">合肥 <a class="price">10</a></li>
<li nu="1">万达 <a class="price">20</a></li>
<li nu="1">城隍庙 <a class="price">30</a></li>
<li nu="1">合工大 <a class="price">40</a></li>
</ul>
</div>
<body><p># -*- coding: utf-8 -*-
</p>
<meta charset="utf-8"/>
<title>合肥旅游景点</title>
<meta content="合肥旅游景点 精简版" name="descrption"/>
<meta content="hstking" name="author"/>
<div id="content">
<div class="title">
<h3>合肥景点 </h3>
</div>
<ul class="table">
<li>景点 <a>门票价格</a></li>
</ul>
<ul class="content">
<li nu="1">斛兵塘 <a class="price">60</a></li>
<li nu="1">合肥 <a class="price">10</a></li>
<li nu="1">万达 <a class="price">20</a></li>
<li nu="1">城隍庙 <a class="price">30</a></li>
<li nu="1">合工大 <a class="price">40</a></li>
</ul>
</div>
</body>
<html><body><p># -*- coding: utf-8 -*-
</p>
<meta charset="utf-8"/>
<title>合肥旅游景点</title>
<meta content="合肥旅游景点 精简版" name="descrption"/>
<meta content="hstking" name="author"/>
<div id="content">
<div class="title">
<h3>合肥景点 </h3>
</div>
<ul class="table">
<li>景点 <a>门票价格</a></li>
</ul>
<ul class="content">
<li nu="1">斛兵塘 <a class="price">60</a></li>
<li nu="1">合肥 <a class="price">10</a></li>
<li nu="1">万达 <a class="price">20</a></li>
<li nu="1">城隍庙 <a class="price">30</a></li>
<li nu="1">合工大 <a class="price">40</a></li>
</ul>
</div>
</body></html>
<html><body><p># -*- coding: utf-8 -*-
</p>
<meta charset="utf-8"/>
<title>合肥旅游景点</title>
<meta content="合肥旅游景点 精简版" name="descrption"/>
<meta content="hstking" name="author"/>
<div id="content">
<div class="title">
<h3>合肥景点 </h3>
</div>
<ul class="table">
<li>景点 <a>门票价格</a></li>
</ul>
<ul class="content">
<li nu="1">斛兵塘 <a class="price">60</a></li>
<li nu="1">合肥 <a class="price">10</a></li>
<li nu="1">万达 <a class="price">20</a></li>
<li nu="1">城隍庙 <a class="price">30</a></li>
<li nu="1">合工大 <a class="price">40</a></li>
</ul>
</div>
</body></html>BS4实战-获取百度贴吧内容
任务目标
获取贴吧帖子的名称和发帖人等信息
以《权力的游戏》贴吧为例.
网页分析
URL分析
选择“权力的游戏”,查看url
第一页URL地址为:
http://tieba.baidu.com/f?kw=%E6%9D%83%E5%8A%9B%E7%9A%84%E6%B8%B8%E6%88%8F&ie=utf-8&pn=0
第二页URL为
http://tieba.baidu.com/f?kw=%E6%9D%83%E5%8A%9B%E7%9A%84%E6%B8%B8%E6%88%8F&ie=utf-8&pn=50
第三页URL为
http://tieba.baidu.com/f?kw=%E6%9D%83%E5%8A%9B%E7%9A%84%E6%B8%B8%E6%88%8F&ie=utf-8&pn=100
可以看出页数增加1对于的pn参数值增加50
URL里指定了ie=utf-8 ,kw后跟的参数应该就是权力的游戏的UTF-8码
网上找一个utf8转中文的工具,校验后确实如此:
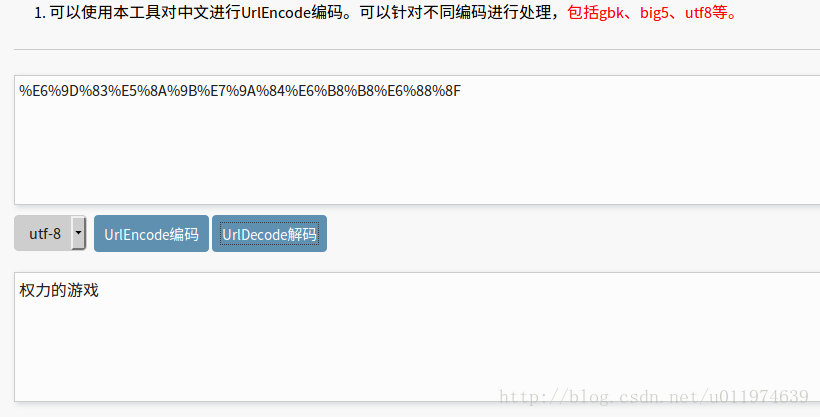
到这里URL分析完毕了~
数据分析
使用浏览器工具查看网页的源代码
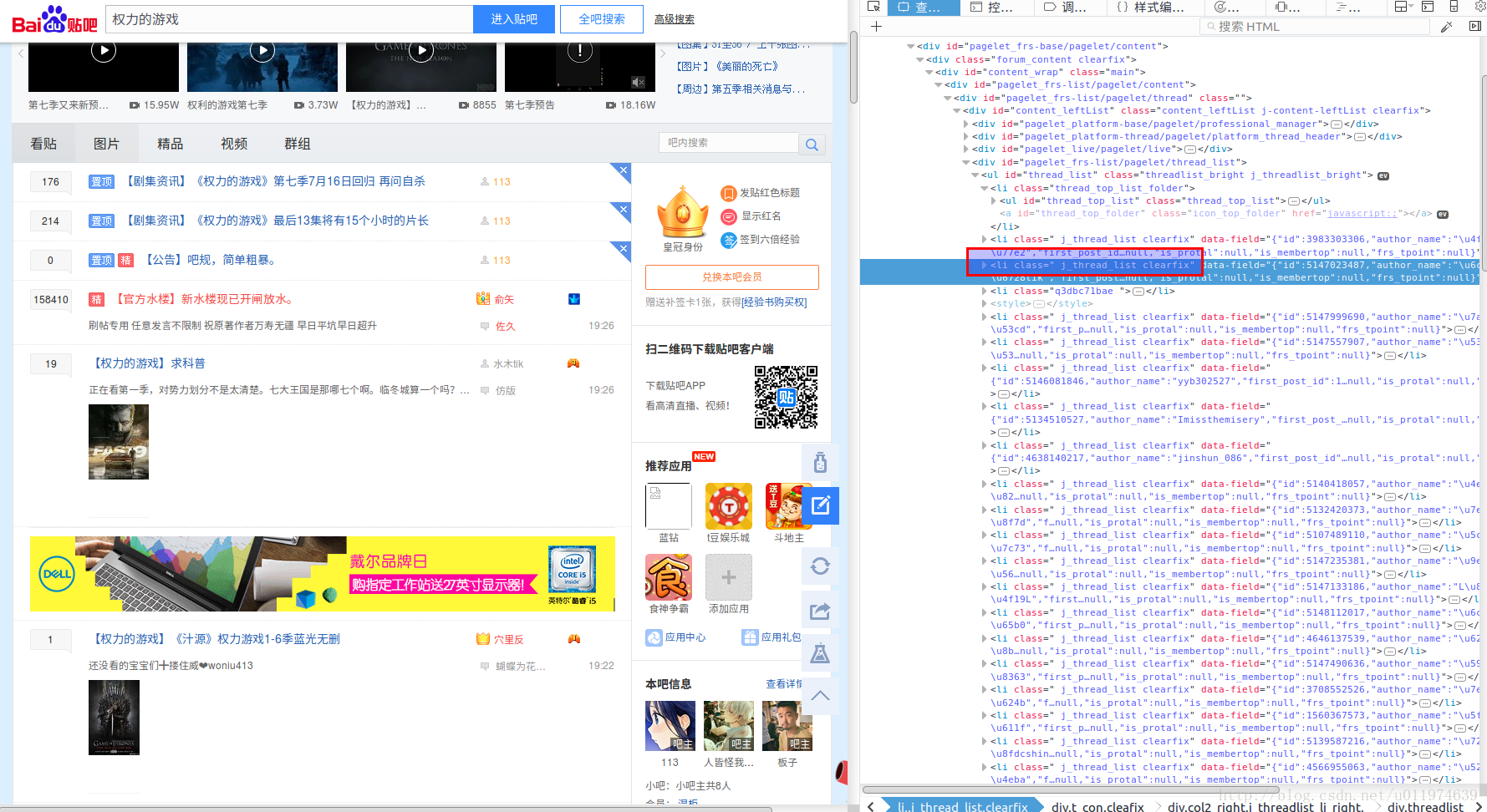
可以看出每一个帖子都是包裹在标签为
<li class=" j_thread_list clearfix" />只需要使用bs4过滤器的find_all方法找到所有符合条件的标签,然后再捞出想要的数据即可.
工程实现
创建工程
定义log模块用于调试记录操作数据
- 提供五个等级的打log方法
- 根据调用者名创建对应的log文件存储log记录
定义getCommentInfo模块,用于实现页面的数据抓取
- 模仿Scrapy框架,创建爬取内容Item
- 创建getUrls方法获取Url地址元组
- 创建getResponseContent方法用户获取页面数据
- 创建spider方法用于爬虫代码的具体编写
- 创建pipelines方法用于处理爬取的数据
mylog类
用于输出日志文档,记录信息
# -*- coding:utf-8 -*-
'''
Created on 2017年6月5日
@author: root
'''
import logging
import getpass
import sys
#### 定义MyLog类
class MyLog(object):
#### 类MyLog的构造函数
def __init__(self):
self.user = getpass.getuser() #获取当前登录名
self.logger = logging.getLogger(self.user)
self.logger.setLevel(logging.DEBUG)
#### 日志文件名
self.logFile = sys.argv[0][0:-3] + '.log' #sys.argv[0]表示代码文件本身的路径 [0:-3]即获取除了末尾三个字符.py的文件名
#log格式 当前时间-日志级别-Logger名称-用户输出信息
self.formatter = logging.Formatter('%(asctime)-12s %(levelname)-8s %(name)-10s %(message)-12srn')
#### 日志显示到屏幕上并输出到日志文件内
self.logHand = logging.FileHandler(self.logFile, encoding='utf8') #创建日志文件流
self.logHand.setFormatter(self.formatter) #输出文件格式
self.logHand.setLevel(logging.DEBUG) #log等级
self.logHandSt = logging.StreamHandler() #创建输出到sys.stdout流,stdout在Eclipse里就是Console
self.logHandSt.setFormatter(self.formatter) #输出流格式
self.logHandSt.setLevel(logging.DEBUG)
self.logger.addHandler(self.logHand) #添加文件输出流
self.logger.addHandler(self.logHandSt) #添加stdout输出流
#### 日志的5个级别对应以下的5个函数
def debug(self,msg):
self.logger.debug(msg)
def info(self,msg):
self.logger.info(msg)
def warn(self,msg):
self.logger.warn(msg)
def error(self,msg):
self.logger.error(msg)
def critical(self,msg):
self.logger.critical(msg)
if __name__ == '__main__':
mylog = MyLog()
mylog.debug(u"I'm debug 测试中文")
mylog.info("I'm info")
mylog.warn("I'm warn")
mylog.error(u"I'm error 测试中文")
mylog.critical("I'm critical")测试输出:
2017-06-05 22:15:16,203 DEBUG root I'm debug 测试中文
2017-06-05 22:15:16,203 INFO root I'm info
2017-06-05 22:15:16,203 WARNING root I'm warn
2017-06-05 22:15:16,203 ERROR root I'm error 测试中文
2017-06-05 22:15:16,203 CRITICAL root I'm criticalmylog类可用,下面工程使用该类就不单独列出了~
getCommemntInfo类
#-*- coding: utf-8 -*-
'''
Created on 2017年6月5日
@author: root
'''
import urllib2
from bs4 import BeautifulSoup
from mylog import MyLog as mylog
class Item(object):
'''爬取内容,类似于Scrapy的架构'''
title = None #帖子标题
firstAuthor = None #帖子创建者
firstTime = None #帖子创建时间
reNum = None #总回复数
content = None #最后回复内容
lastAuthor = None #最后回复者
lastTime = None #最后回复时间
class GetTiebaInfo(object):
'''获取网页内容,并记录到txt文件中'''
def __init__(self,url):
self.url = url
self.log = mylog()
self.pageSum = 5
self.urls = self.getUrls(self.pageSum) #生成爬取地址
self.items = self.spider(self.urls) #爬数据
self.pipelines(self.items) #处理数据
'''getUrls是为spider生成一个urls元组'''
def getUrls(self,pageSum):
urls = []
pns = [str(i*50) for i in range(pageSum)]
ul = self.url.split('=')
for pn in pns:
ul[-1] = pn
url = '='.join(ul)
urls.append(url)
self.log.info(u'获取URLS成功')
return urls
'''类似于Scrapy,spider是爬虫代码的具体编写'''
def spider(self, urls):
items = []
for url in urls:
htmlContent = self.getResponseContent(url)
soup = BeautifulSoup(htmlContent, 'lxml')
tagsli = soup.find_all('li',attrs={'class':' j_thread_list clearfix'})
for tag in tagsli:
item = Item()
item.title = tag.find('a', attrs={'class':'j_th_tit'}).get_text().strip()
item.firstAuthor = tag.find('span', attrs={'class':'frs-author-name-wrap'}).a.get_text().strip()
item.firstTime = tag.find('span', attrs={'title':u'创建时间'.encode('utf8')}).get_text().strip()
item.reNum = tag.find('span', attrs={'title':u'回复'.encode('utf8')}).get_text().strip()
item.content = tag.find('div', attrs={'class':'threadlist_abs threadlist_abs_onlyline '}).get_text().strip()
item.lastAuthor = tag.find('span', attrs={'class':'tb_icon_author_rely j_replyer'}).a.get_text().strip()
item.lastTime = tag.find('span', attrs={'title':u'最后回复时间'.encode('utf8')}).get_text().strip()
items.append(item)
self.log.info(u'获取标题为<<%s>>的项成功 ...' %item.title)
return items
'''类似于Scrapy,piplines是对摘取下来的Items操作'''
def pipelines(self, items):
fileName = u'百度贴吧_权利的游戏.txt'.encode('utf-8')
with open(fileName, 'w') as fp:
for item in items:
fp.write('title:%s t author:%s t firstTime:%s n content:%s n return:%s n lastAuthor:%s t lastTime:%s nnnn'
%(item.title.encode('utf8'),item.firstAuthor.encode('utf8'),item.firstTime.encode('utf8'),item.content.encode('utf8'),item.reNum.encode('utf8'),item.lastAuthor.encode('utf8'),item.lastTime.encode('utf8')))
self.log.info(u'标题为<<%s>>的项输入到"%s"成功' %(item.title, fileName.decode('utf-8')))
def getResponseContent(self, url):
'''这里单独使用一个函数返回页面返回值,是为了后期方便的加入proxy和headers等
'''
try:
response = urllib2.urlopen(url.encode('utf8'))
except:
self.log.error(u'Python 返回URL:%s 数据失败' %url)
else:
self.log.info(u'Python 返回URUL:%s 数据成功' %url)
return response.read()
if __name__ == '__main__':
url = u'http://tieba.baidu.com/f?kw=权利的游戏&ie=utf-8&pn=50'
GTI = GetTiebaInfo(url)执行结果
查看工程目录下的输出文件:
- myCommentInfo.log
- 百度贴吧_权利的游戏.txt文件
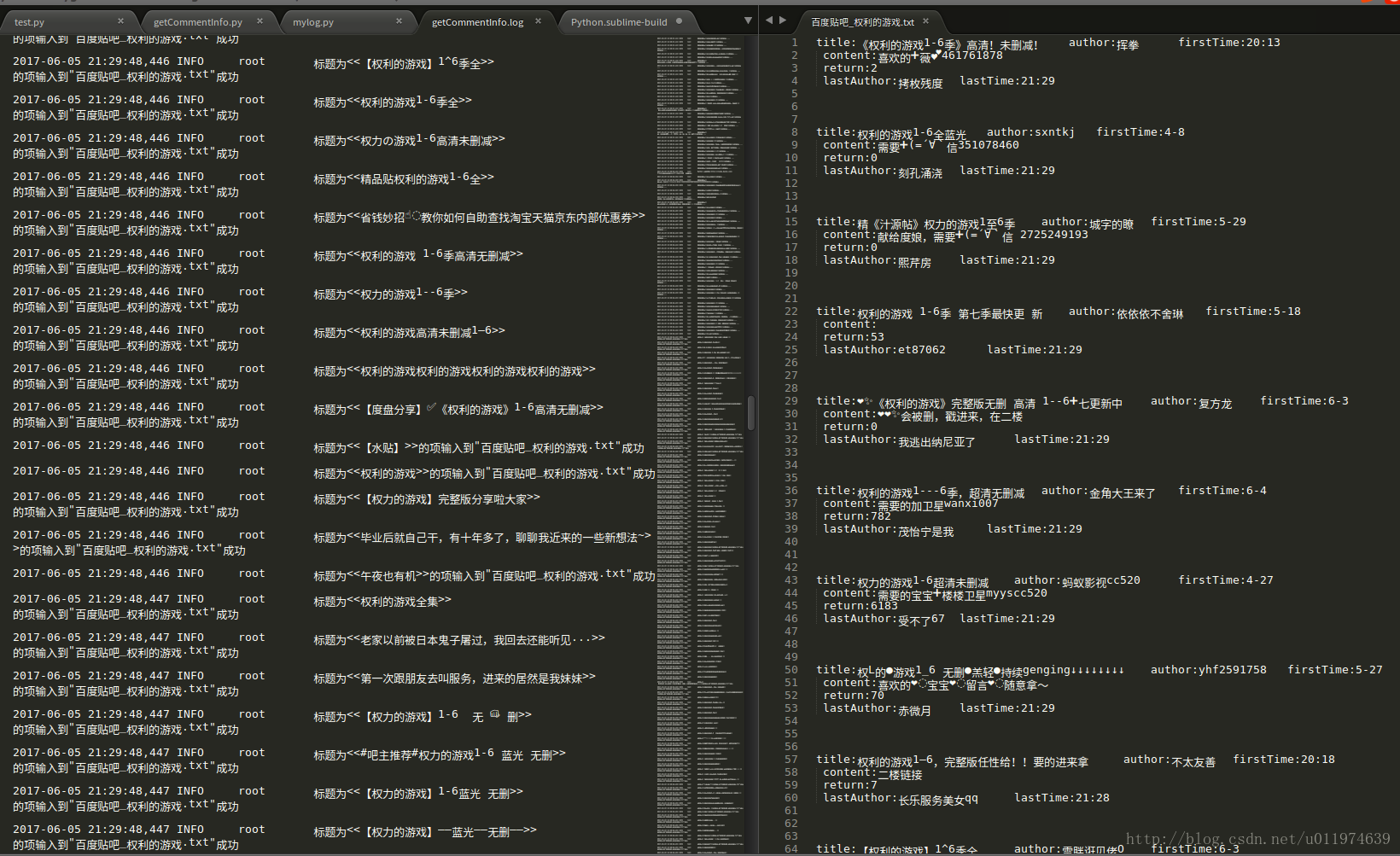
运行成功~
BS4实战-获取双色球中奖信息
任务目标
获取http://www.zhcw.com/ssq/kaijiangshuju/index.shtml?type=0的中奖双色球信息
网页分析
URL分析
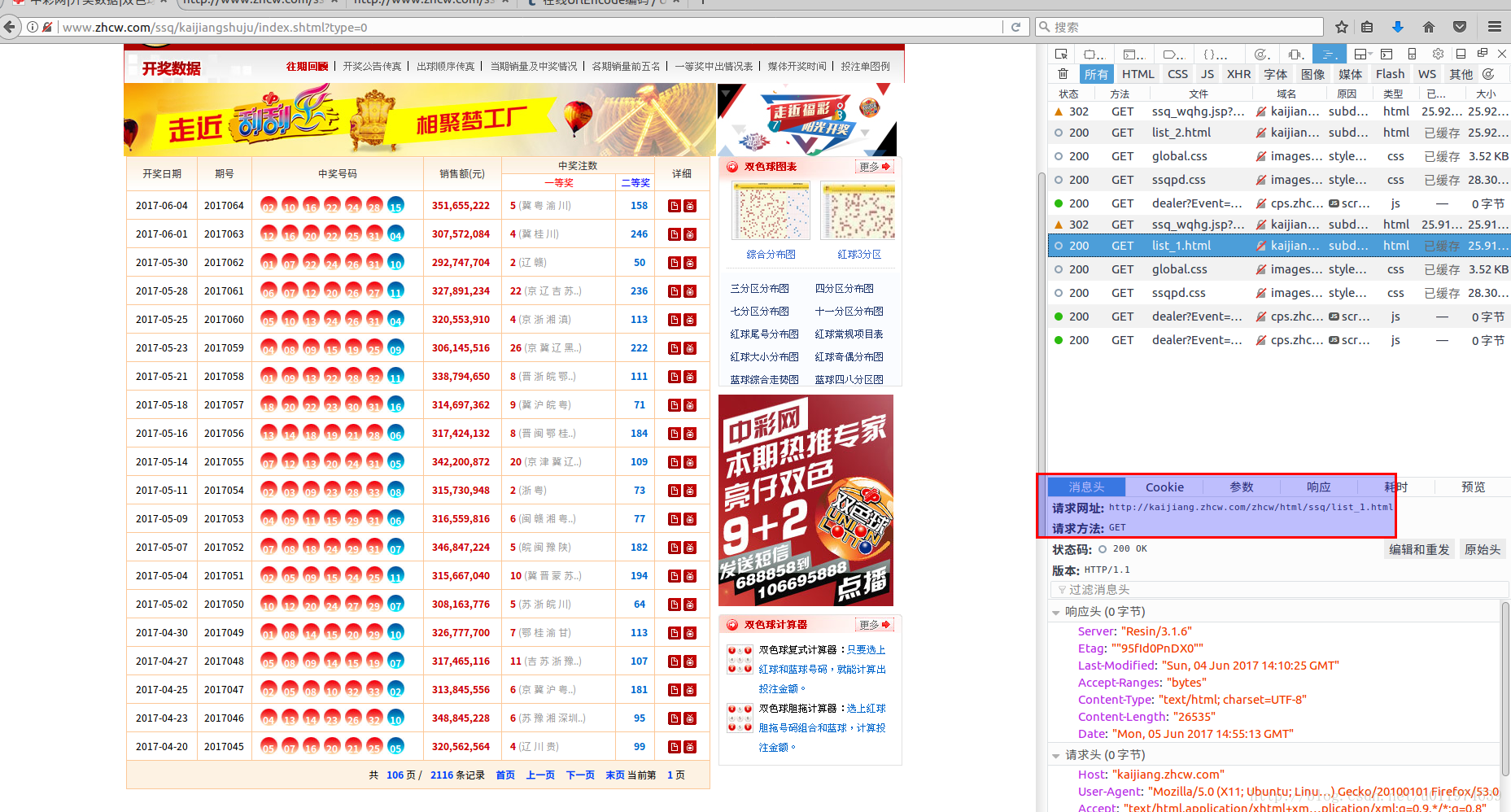
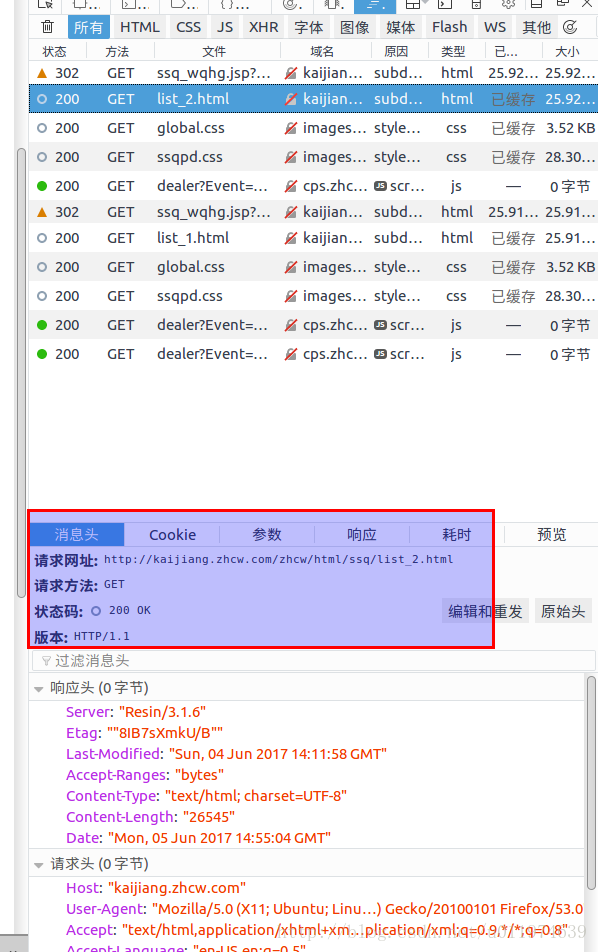
前两个网页请求地址为:
http://kaijiang.zhcw.com/zhcw/html/ssq/list_1.html
http://kaijiang.zhcw.com/zhcw/html/ssq/list_2.html
可以看出URL的规律在于list_x
分析请求的地址的最大页
使用浏览器工具查看网页的源代码
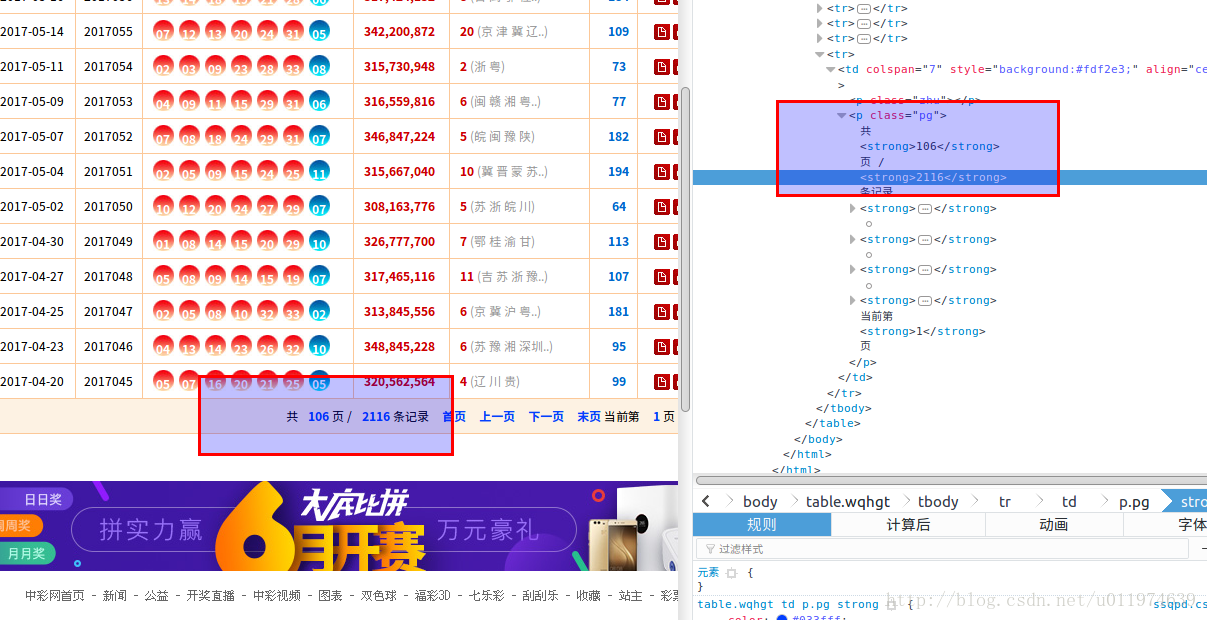
可以看出最大页的信息是标签p下的strong子标签
到这里URL分析完毕了~
数据分析
使用浏览器工具查看网页的源代码
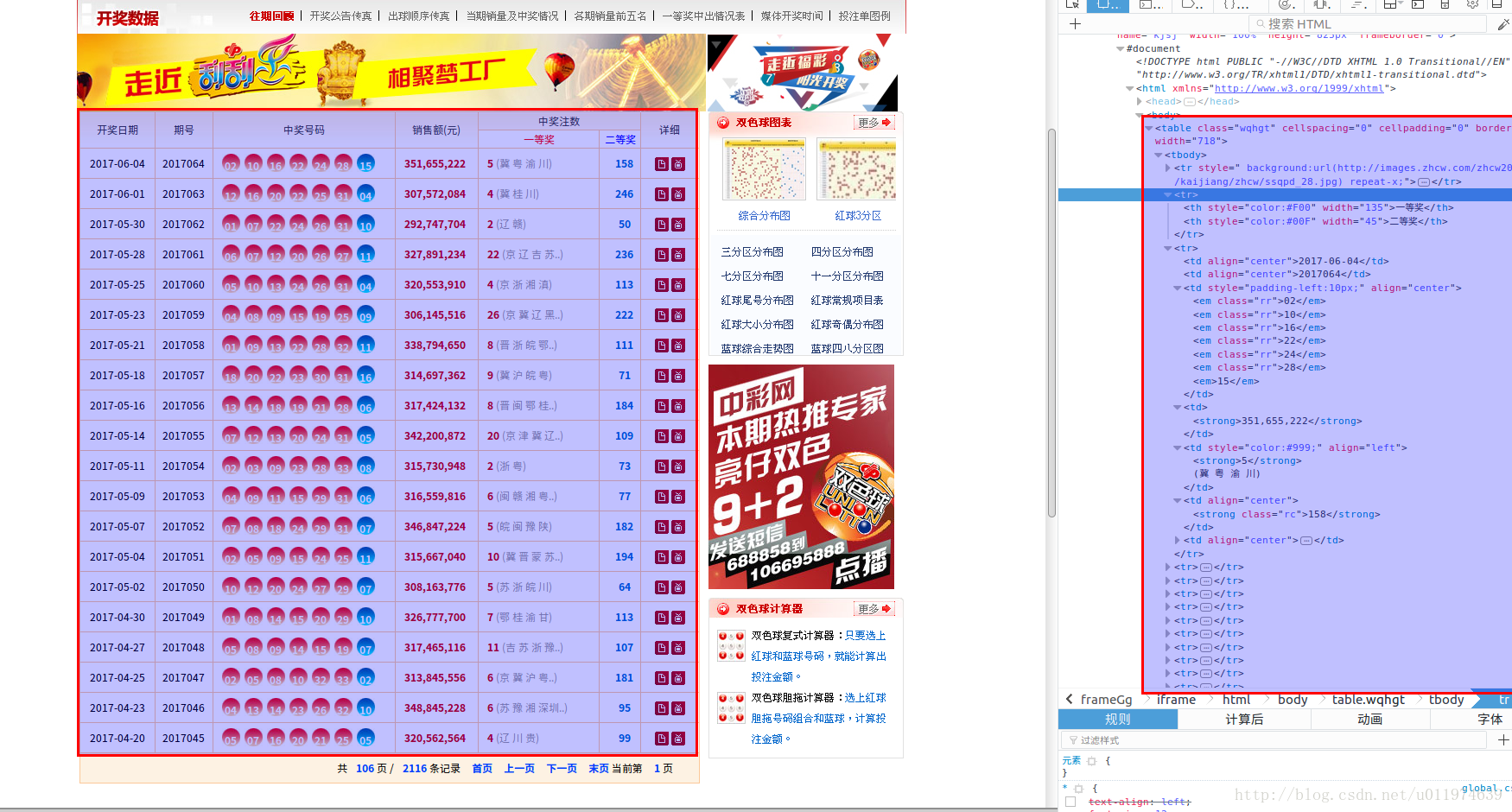
页面的核心数据都在class=”wqhgt”的表格内.只要根据不同的页面找到该表格,然后遍历所有tr元素即可
将记录的数据存储到Excel
导入工具包
pip install xlwt操作程序示例如下:
book = xlwt.Workbook(encoding='utf8') #创建workbook对象
sheet=book.add_sheet('sheetname', cell_overwrite_ok=True) #添加sheet
sheet.wirte(row,col,content) #写数据
book.save(fileName) #将数据存储到excel中工程实现
创建工程
定义log模块用于调试记录操作数据
定义save2excel模块用于将数据存储到excel中
定义completeBook模块
- 模仿Scrapy框架,创建爬取内容Item
- 创建getUrls方法获取Url地址元组
- 创建getResponseContent方法用户获取页面数据
- 创建spider方法用于爬虫代码的具体编写
- 创建pipelines方法用于处理爬取的数据
mylog类(同上)
操作excel的save2excel类
#-*- coding: utf-8 -*-
'''
Created on 2017年6月6日
@author: root
'''
import xlwt
class SaveBallDate(object):
def __init__(self, items):
self.items = items #已经获取到的数据
self.run(self.items)
def run(self,items):
fileName = u'双色球.xls'.encode('utf8')
book = xlwt.Workbook(encoding='utf8') #This is a class representing a workbook and all its contents
sheet=book.add_sheet('ball', cell_overwrite_ok=True)# This method is used to create Worksheets in a Workbook
sheet.write(0, 0, u'开奖日期'.encode('utf8')) #sheet.wirte(row,col,content)
sheet.write(0, 1, u'期号'.encode('utf8'))
sheet.write(0, 2, u'红1'.encode('utf8'))
sheet.write(0, 3, u'红2'.encode('utf8'))
sheet.write(0, 4, u'红3'.encode('utf8'))
sheet.write(0, 5, u'红4'.encode('utf8'))
sheet.write(0, 6, u'红5'.encode('utf8'))
sheet.write(0, 7, u'红6'.encode('utf8'))
sheet.write(0, 8, u'蓝'.encode('utf8'))
sheet.write(0, 9, u'销售金额'.encode('utf8'))
sheet.write(0, 10, u'一等奖'.encode('utf8'))
sheet.write(0, 11, u'二等奖'.encode('utf8'))
i = 1
while i <= len(items):
item = items[i-1]
sheet.write(i, 0, item.date)
sheet.write(i, 1, item.order)
sheet.write(i, 2, item.red1)
sheet.write(i, 3, item.red2)
sheet.write(i, 4, item.red3)
sheet.write(i, 5, item.red4)
sheet.write(i, 6, item.red5)
sheet.write(i, 7, item.red6)
sheet.write(i, 8, item.blue)
sheet.write(i, 9, item.money)
sheet.write(i, 10, item.firstPrize)
sheet.write(i, 11, item.secondPrize)
i += 1
book.save(fileName) # This method is used to save the Workbook to a file in native Excel format.
if __name__ == '__main__':
passgetWinningNum类
#-*- coding: utf-8 -*-
'''
Created on 2017年6月6日
@author: root
'''
import re
import urllib2
from bs4 import BeautifulSoup
from mylog import MyLog as mylog
from save2excel import SaveBallDate
class DoubleColorBallItem(object):
date = None
order = None
red1 = None
red2 = None
red3 = None
red4 = None
red5 = None
red6 = None
blue = None
money = None
firstPrize = None
secondPrize = None
class GetDoubleColorBallNumber(object):
'''这个类用于获取双色球中奖号码, 返回一个txt文件'''
def __init__(self):
self.urls = []
self.log = mylog()
self.getUrls()
self.items = self.spider(self.urls)
self.pipelines(self.items)
self.log.info('beging save data to excel rn')
self.log.info('save data to excel end ...rn')
def getUrls(self):
'''获取数据来源网页'''
URL = r'http://kaijiang.zhcw.com/zhcw/html/ssq/list_1.html'
htmlContent = self.getResponseContent(URL)
soup = BeautifulSoup(htmlContent, 'lxml')
tag = soup.find_all(re.compile('p'))[-1] #找到最大页数
pages = tag.strong.get_text()
for i in xrange(1, int(pages)+1):
url = r'http://kaijiang.zhcw.com/zhcw/html/ssq/list_' + str(i) + '.html'
self.urls.append(url)
self.log.info(u'添加URL:%s 到URLS rn' %url)
def getResponseContent(self, url):
'''这里单独使用一个函数返回页面返回值,是为了后期方便的加入proxy和headers等'''
try:
response = urllib2.urlopen(url.encode('utf8'))
except:
self.log.error(u'Python 返回URL:%s 数据失败 rn' %url)
else:
self.log.info(u'Python 返回URUL:%s 数据成功 rn' %url)
return response.read()
def spider(self,urls):
'''这个函数的作用是从获取的数据中过滤得到中奖信息
'''
items = []
for url in urls:
htmlContent = self.getResponseContent(url)
soup = BeautifulSoup(htmlContent, 'lxml')
tags = soup.find_all('tr', attrs={})
for tag in tags:
if tag.find('em'):
item = DoubleColorBallItem()
tagTd = tag.find_all('td')
item.date = tagTd[0].get_text()
item.order = tagTd[1].get_text()
tagEm = tagTd[2].find_all('em')
item.red1 = tagEm[0].get_text()
item.red2 = tagEm[1].get_text()
item.red3 = tagEm[2].get_text()
item.red4 = tagEm[3].get_text()
item.red5 = tagEm[4].get_text()
item.red6 = tagEm[5].get_text()
item.blue = tagEm[6].get_text()
item.money = tagTd[3].find('strong').get_text()
item.firstPrize = tagTd[4].find('strong').get_text()
item.secondPrize = tagTd[5].find('strong').get_text()
items.append(item)
self.log.info(u'获取日期为:%s 的数据成功' %(item.date))
return items
def pipelines(self,items):
SaveBallDate(self.items)
fileName = u'双色球.txt'.encode('utf8')
with open(fileName, 'w') as fp:
for item in items:
fp.write('%s %s t %s %s %s %s %s %s %s t %s t %s %s n'
%(item.date,item.order,item.red1,item.red2,item.red3,item.red4,item.red5,item.red6,item.blue,item.money,item.firstPrize,item.secondPrize))
self.log.info(u'将日期为:%s 的数据存入"%s"...' %(item.date, fileName.decode('utf8')))
if __name__ == '__main__':
GDCBN = GetDoubleColorBallNumber()执行结果
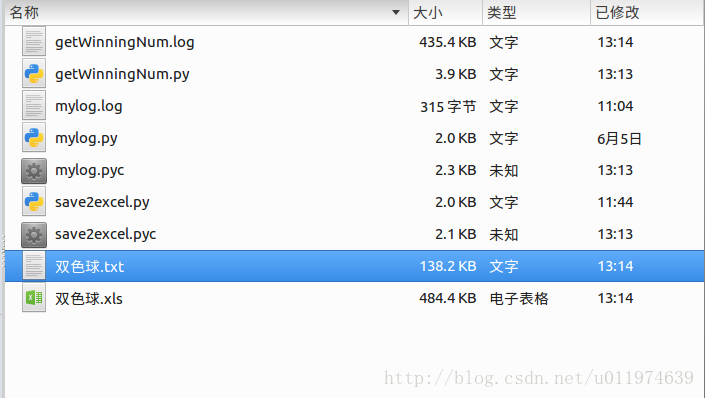
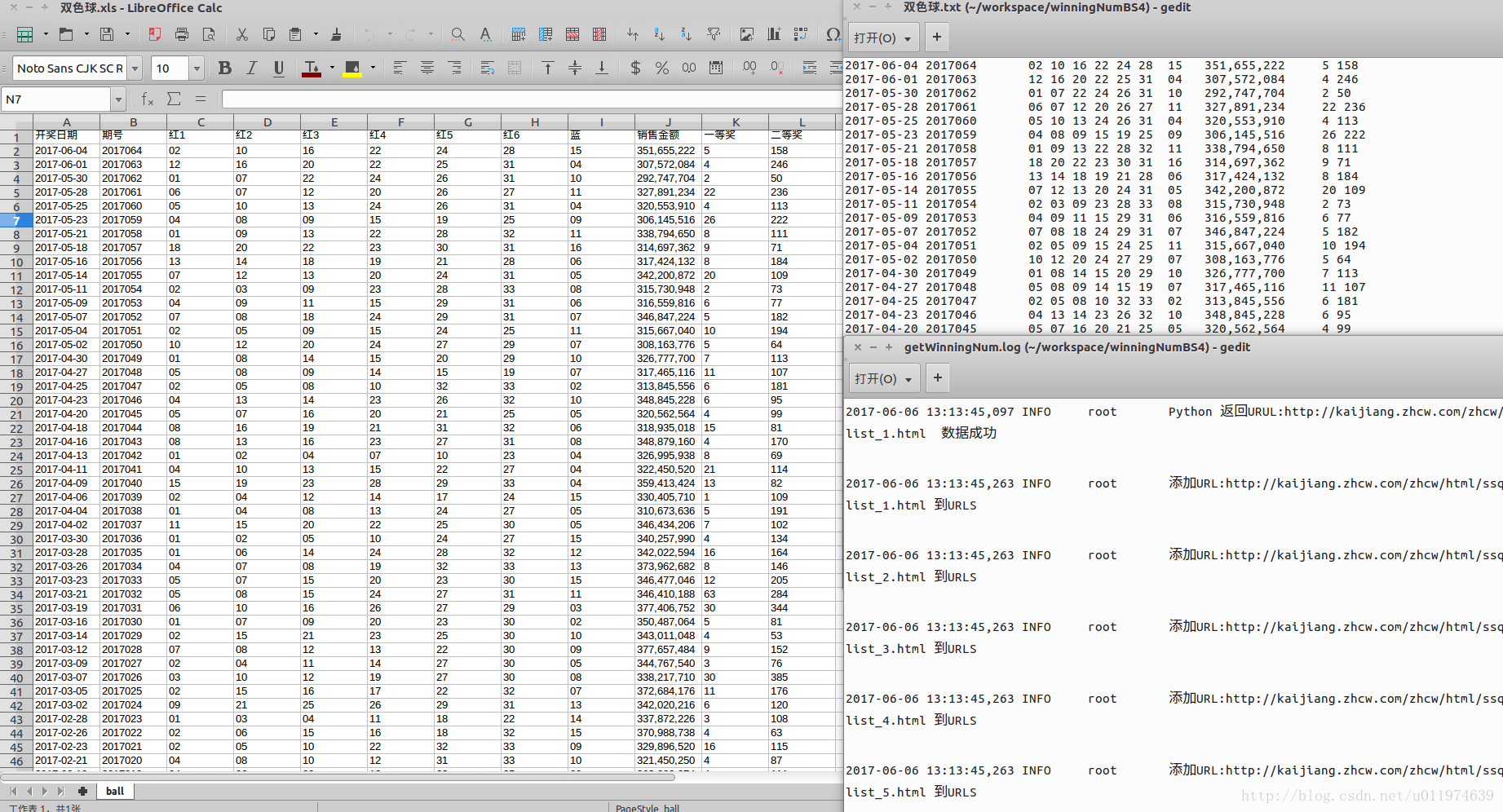
成功~
BS4实战-获取起点小说信息
任务目标
获取http://www.qidian.com/的所有完本小说的信息
网页分析
URL分析
选择选择“完本”,查看url中
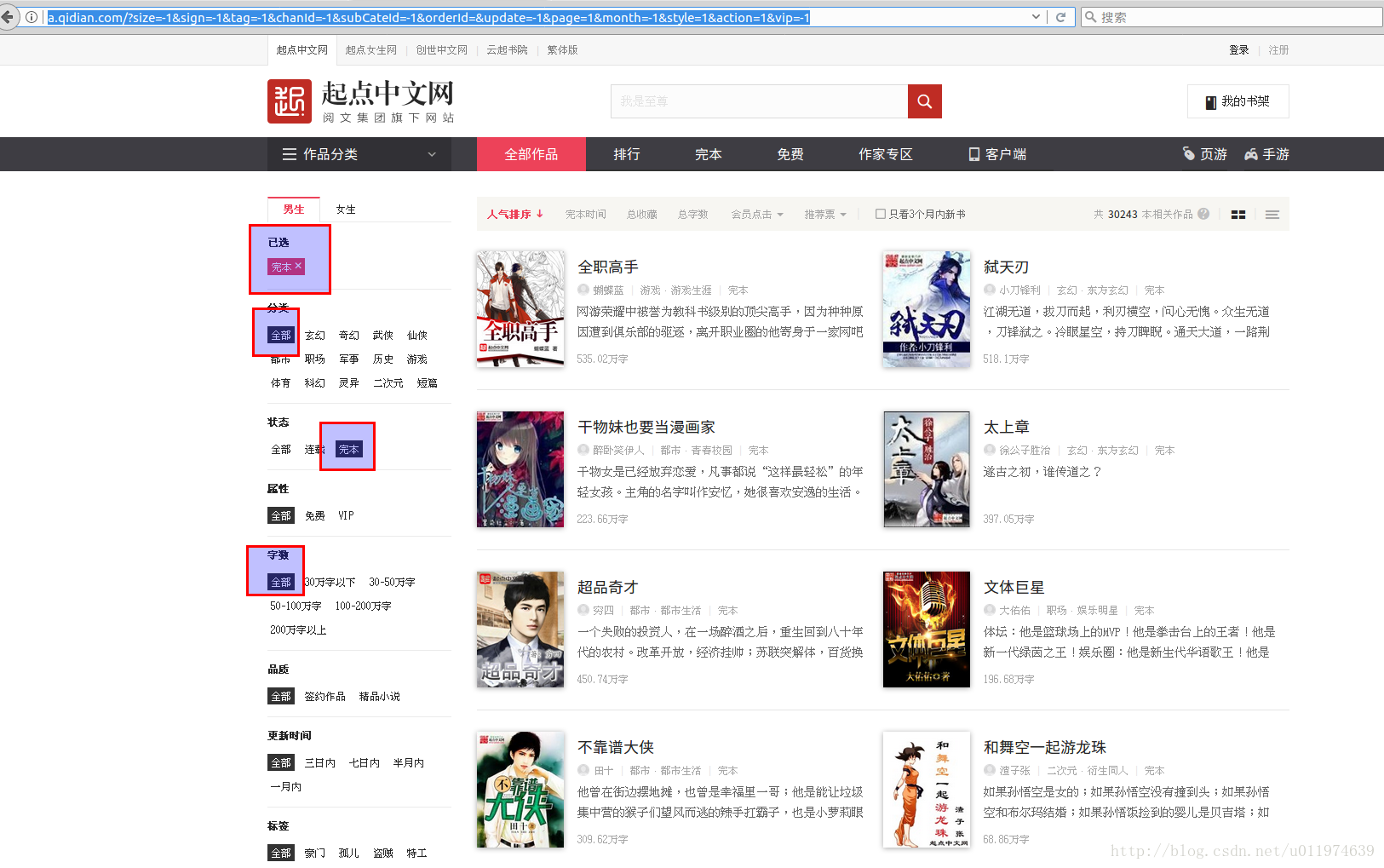
本页地址为:
http://a.qidian.com/?size=-1&sign=-1&tag=-1&chanId=-1&subCateId=-1&orderId=&update=-1&page=1&month=-1&style=1&action=1&vip=-1这里面有大量的参数,应该是对其他查询条件的限制,这里我们适当的去除一些参数,经过检验:
http://a.qidian.com/?tag=-1&page=1&action=1 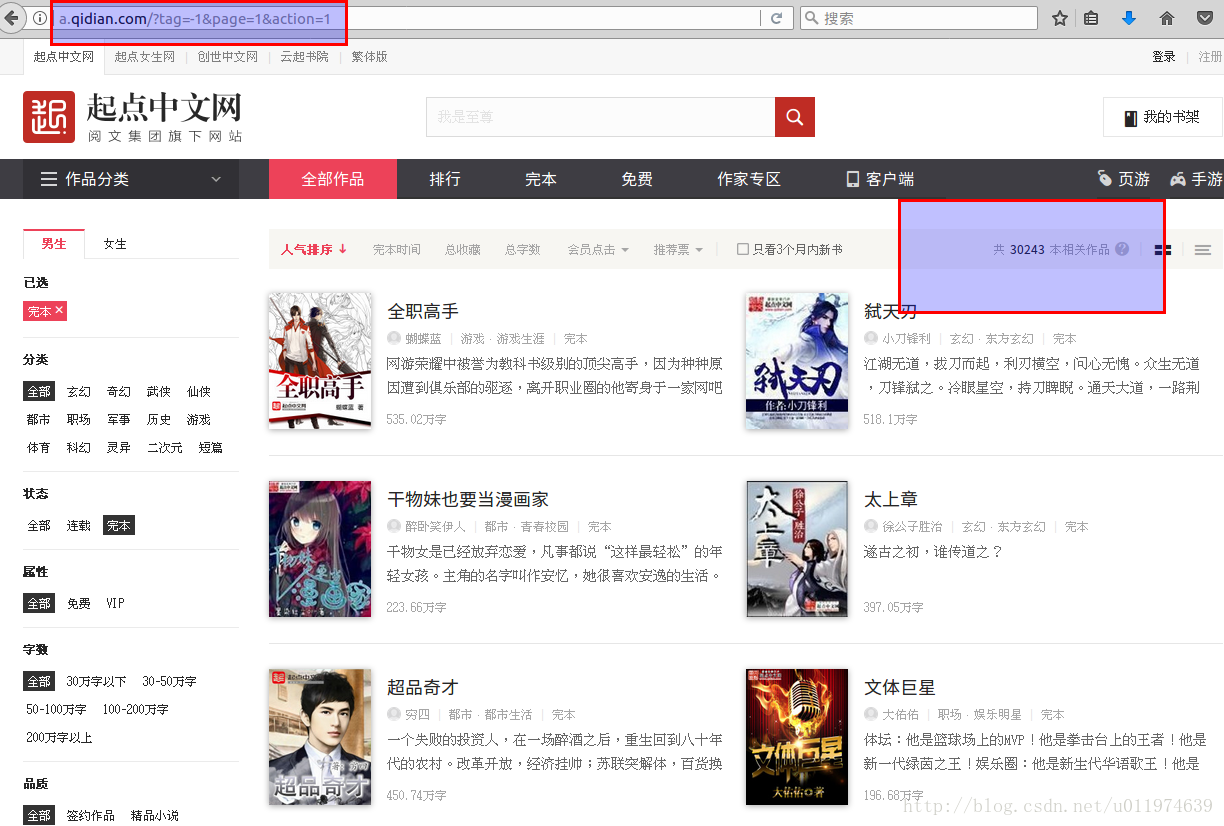
可以看出此网页与上面的内容相同,故使用这个新地址
分析请求的地址的最大页
使用浏览器工具查看网页的源代码
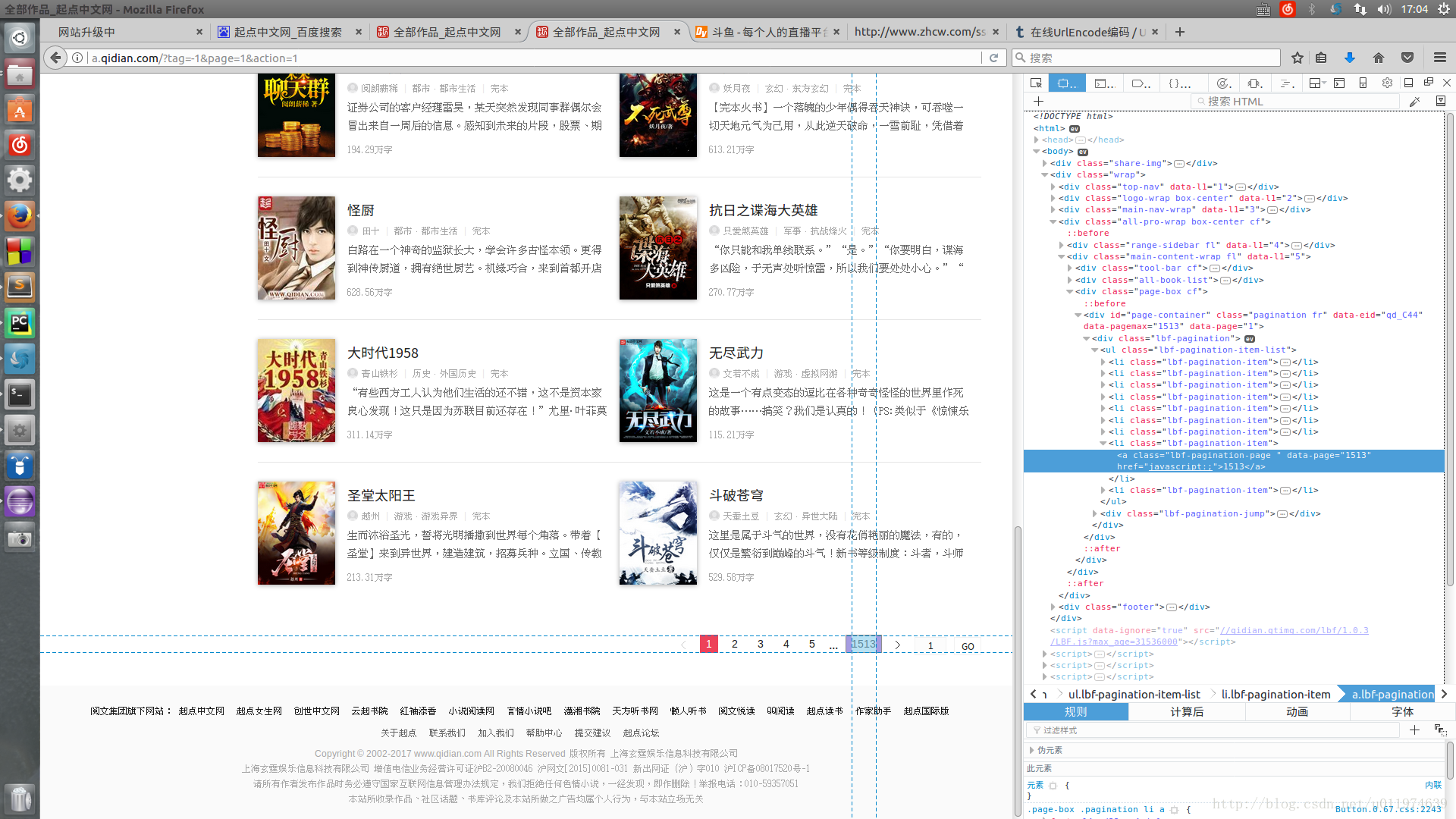
这里需要注意的是 BS4指定解析器要使用html.parser 因为lxml和lxml-xml解析都会缺少网页内容,这里就不过多讨论了,在此简化操作,默认最大页数1000
到这里URL分析完毕了~
数据分析
使用浏览器工具查看网页的源代码
可以看出每一本书籍信息都包裹在属性class=”all-img-list cf”的ul标签内..
将记录的数据保存到MySQL
保存到本地mysql
在Linux上安装MySQL,使用指令
sudo apt-get install mysql-server mysql-client
sudo apt-get install libmysqlclient-dev libmysqld-dev操作数据库
- 登录数据库
- 创库–>创表–>创建用户
#创建数据库
create database bs4db;
use bs4db;
#创建对应的数据表
CREATE TABLE qidianbooks(
id INT AUTO_INCREMENT,
categoryName char(20),
bookName char(16),
wordsNum char(16),
authorName char(20),
PRIMARY KEY(id)
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
#创建用户,并给客户机分配访问权限
INSERT INTO mysql.user(Host,User,passwd) VALUES("%","crawlUSER",password("crawl123"));
INSERT INTO mysql.user(Host,User,Password) VALUES("localhost","crawlUSER",password("crawl123"));
GRANT all privileges ON bs4DB.* to crawlUSER@all IDENTIFIED BY 'crawl123';
GRANT all privileges ON bs4DB.* to crawlUSER@localhost IDENTIFIED BY 'crawl123';
GRANT all privileges ON bs4DB.* to crawlUSER@210.45.251.238 IDENTIFIED BY 'crawl123';
flush PRIVILEGES;安装MySQLdb模块
MySQLdb模块是Python操作MySQL的桥梁
sudo apt-get install python-mysqldb
sudo apt-get install python-dev
sudo pip install mysql-python连接到数据库(程序示例)
MySQLdb.connect(host,port,user,passwd,db,charset='utf8')
#host即服务器段的地址,这里host='210.45.251.150'
#port = 3306 mysql的默认端口
#user = 'crawlUSER',passwd = 'crawl123' 服务器端已配置好的用户名和密码
#db = 'bs4DB' 服务器段配置好的数据库名称
#获取
cur = conn.cursor()
#执行SQL语句
cur.execute("INSERT INTO qiDianBooks(categoryName, bookName, wordsNum,authorName) values(%s, %s, %s,%s)", (item.categoryName, item.bookName, item.wordsNum, item.authorName))
#关闭cus,提交事务,关闭数据库连接
cur.close()
conn.commit()
conn.close()保存到同网段的其他装有mysql的服务机
分析网络
本机的网络信息
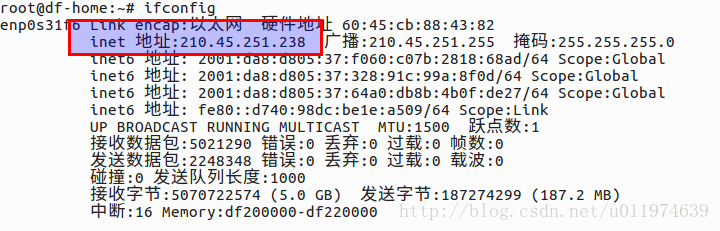
本地的IP地址为:210.45.251.238
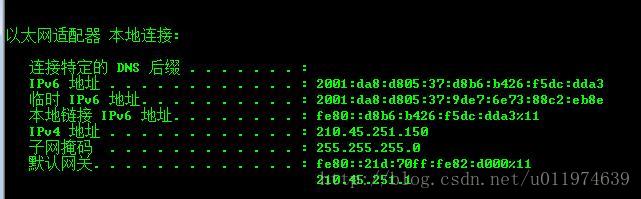
服务机的网络信息(mysql机)
服务机的IP地址为:210.45.251.150
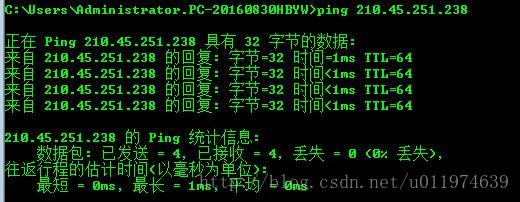
本机和服务器之间是可以ping通的。说明网络没问题
操作数据库(同上)
连接到数据库(同上)
工程实现
创建工程
定义log模块用于调试记录操作数据
定义save2mysql模块用于将数据存储到mysql中
定义completeBook模块
- 模仿Scrapy框架,创建爬取内容Item
- 创建getUrls方法获取Url地址元组
- 创建getResponseContent方法用户获取页面数据
- 创建spider方法用于爬虫代码的具体编写
- 创建pipelines方法用于处理爬取的数据
mylog类(同上)
操作mysql的save2mysql类
#-*- coding: utf-8 -*-
'''
Created on 2017年6月6日
@author: root
'''
import MySQLdb
#from completeBook import BookItem
class SavebooksData(object):
def __init__(self,items):
self.host = '210.45.251.150' #远程操作mysql的IP地址
self.port = 3306 #mysql的端口
self.user = 'crawlUSER' #配置好的用户名和密码
self.passwd = 'crawl123'
self.db = 'bs4DB' #要操作的表所在的数据库
self.run(items)
def run(self, items):
conn = MySQLdb.connect(host=self.host,
port=self.port,
user=self.user,
passwd=self.passwd,
db=self.db,
charset='utf8')
cur = conn.cursor()
for item in items:
cur.execute("INSERT INTO qiDianBooks(categoryName, bookName, wordsNum,authorName) values(%s, %s, %s,%s)", (item.categoryName, item.bookName, item.wordsNum, item.authorName))
cur.close()
conn.commit()
conn.close()
if __name__ == '__main__':
#use to test connection####
# item = BookItem()
# item.categoryName = 'test-type'
# item.bookName = 'TESTbookname'
# item.wordsNum = '23942W'
# item.authorName = 'testfan'
# items = []
# items.append(item)
# SavebooksData(items)
passcompleteBook类
#-*- coding: utf-8 -*-
'''
Created on 2017年6月6日
@author: root
'''
import time
import codecs
import urllib2
from bs4 import BeautifulSoup
from mylog import MyLog as mylog
from savet2mysql import SavebooksData
class BookItem(object):
categoryName = None
bookName = None
wordsNum = None
authorName = None
class GetBookName(object):
def init(self):
self.log = mylog()
self.urls = self.getUrls()
self.booksList = []
self.items = self.spider(self.urls)
def getUrls(self):
urls = []
pages=100
for i in xrange(1, pages+1):
url = r'http://a.qidian.com/?tag=-1&page=' + str(i) + '&action=1'
urls.append(url)
self.log.info(u'添加URL:%s 到URLS rn' %url)
return urls
def getResponseContent(self, url):
try:
response = urllib2.urlopen(url.encode('utf8'))
except:
self.log.error(u'Python 返回URL:%s 数据失败' %url)
else:
self.log.info(u'Python 返回URUL:%s 数据成功' %url)
return response.read()
def spider(self,urls):
items = []
for url in urls:
htmlContent = self.getResponseContent(url)
soup = BeautifulSoup(htmlContent,'lxml')
all_book_tags = soup.find_all('div', attrs={'class':'all-book-list'})
books_tag = all_book_tags[0].find_all('div',attrs={'class':'book-mid-info'})
for book in books_tag:
item = BookItem()
item.categoryName = book.find('p',attrs={'class':'author'}).find_all('a')[1].get_text()+'-'+book.find('p',attrs={'class':'author'}).find_all('a')[2].get_text()
item.bookName = book.find('h4').a.get_text()
item.authorName = book.find('p',attrs={'class':'author'}).find('a',attrs={'class':'name'}).get_text()
item.wordsNum = book.find('p',attrs={'class':'update'}).get_text()
items.append(item)
return items
def pipelines(self,bookList):
self.log.info('begin save data to mysqlrn')
SavebooksData(bookList)
self.log.info('save data to mysql end ...rn')
bookName = u'起点完本小说.txt'.encode('utf8')
nowTime = time.strftime('%Y-%m-%d %H:%M:%Srn', time.localtime())
with codecs.open(bookName, 'w', 'utf8') as fp:
fp.write('run time: %s' %nowTime)
for item in self.booksList:
fp.write('%s t %s tt %s t %s t %s rn'
%(item.categoryName, item.bookName, item.wordsNum,item.authorName))
self.log.info(u'将书名为<<%s>>的数据存入"%s"...' %(item.bookName, bookName.decode('utf8')))
if __name__ == '__main__':
GBN = GetBookName()执行结果
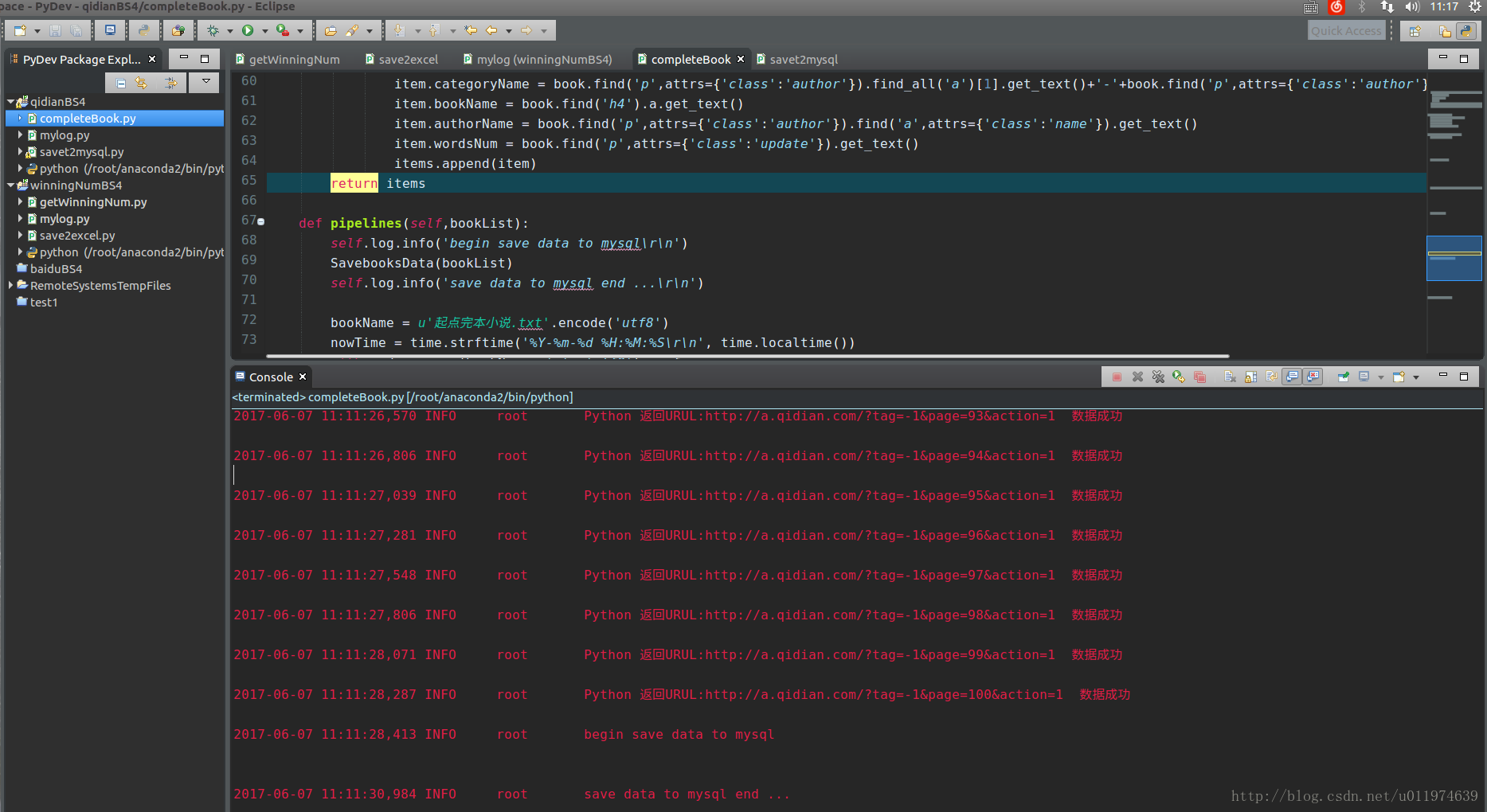
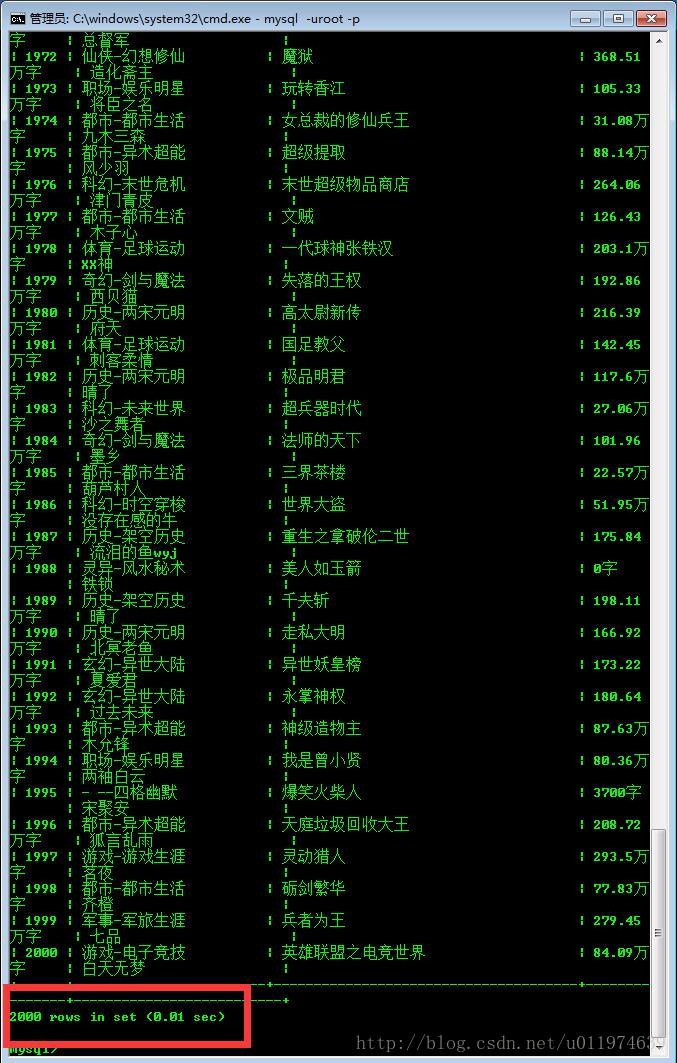
成功~
BS4实战-获取电影信息
任务目标
获取http://dianying.2345.com/的喜剧片内2016年所有电影信息
网页分析
URL分析
选择喜剧片-2016 查看榜单的所有URL
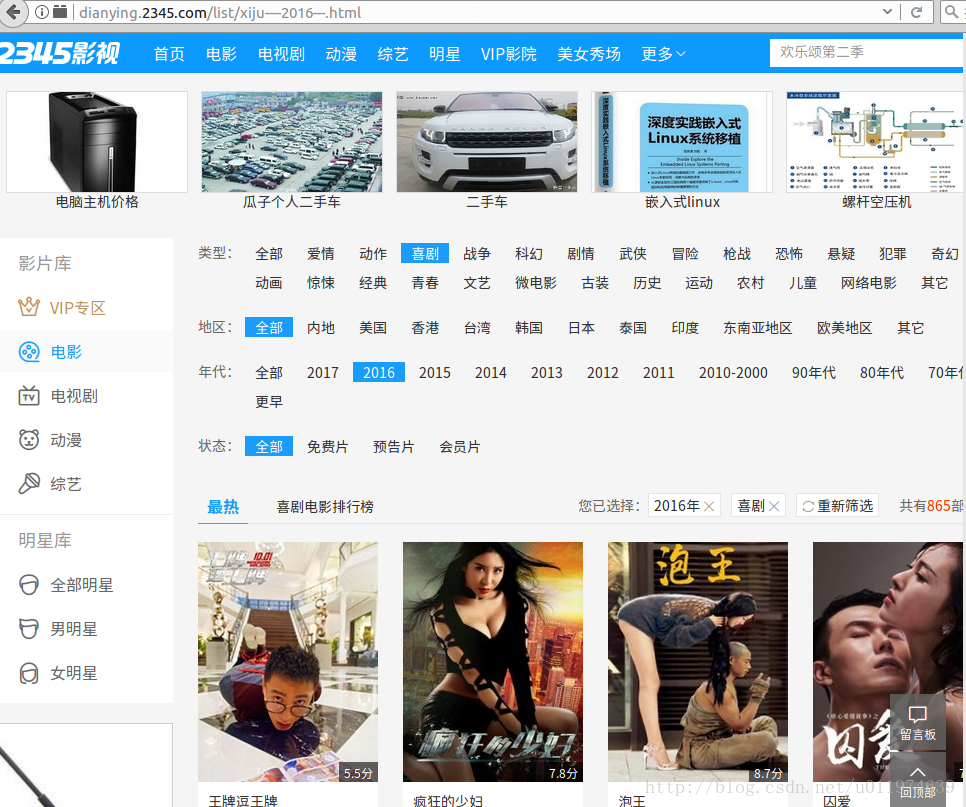
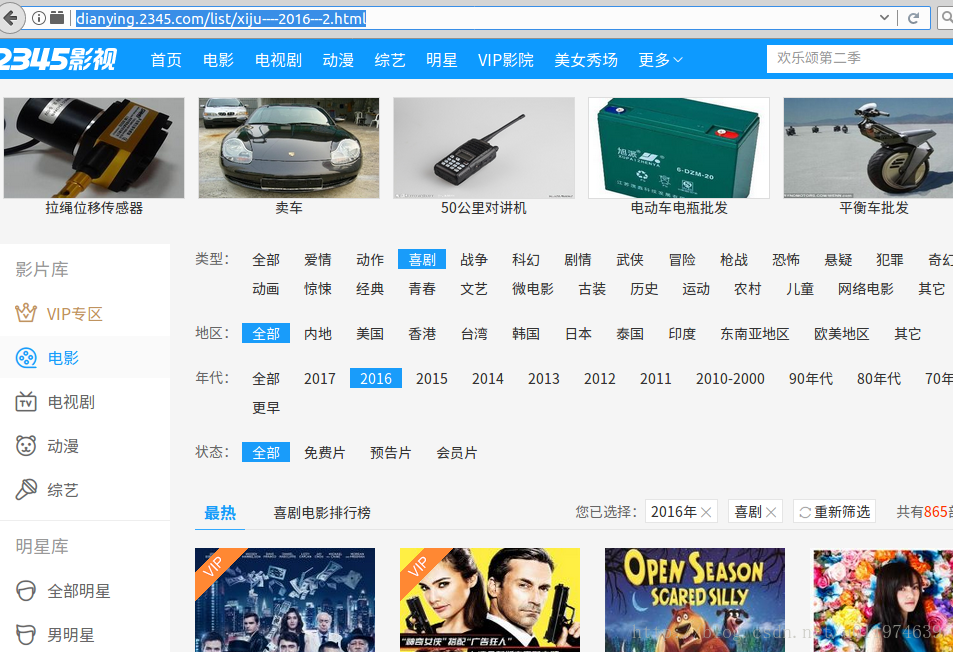
地址分别为:
第一页:http://dianying.2345.com/list/xiju—-2016—1.html
第二页:http://dianying.2345.com/list/xiju—-2016—2.html
可以看出,不同页数区别在于后面的2016—x.html的x参数
分析请求的地址的最大页
使用浏览器工具查看网页的源代码
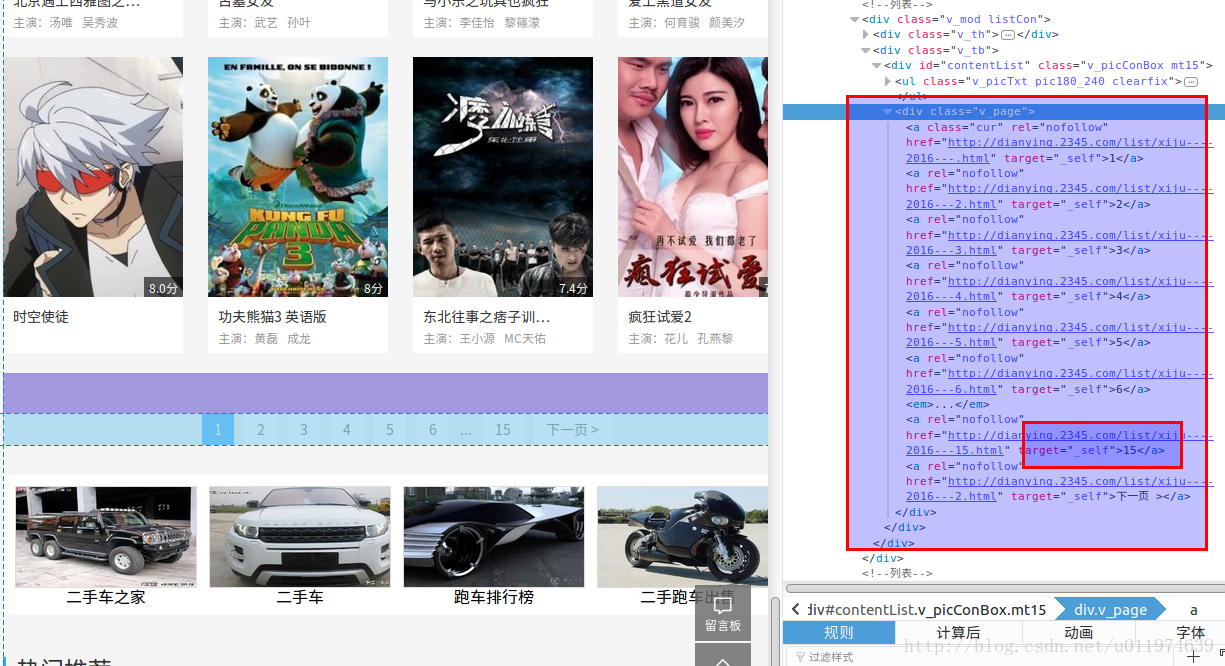
在一个class=’v_page’的div内,找到这个tag遍历出倒数第二个a标签值即可.
这里需要注意的是 使用解析器要使用html.parser 因为lxml和lxml-xml解析都会缺少网页内容
到这里URL的规律已经很明显了~
数据分析
使用浏览器工具查看网页的源代码
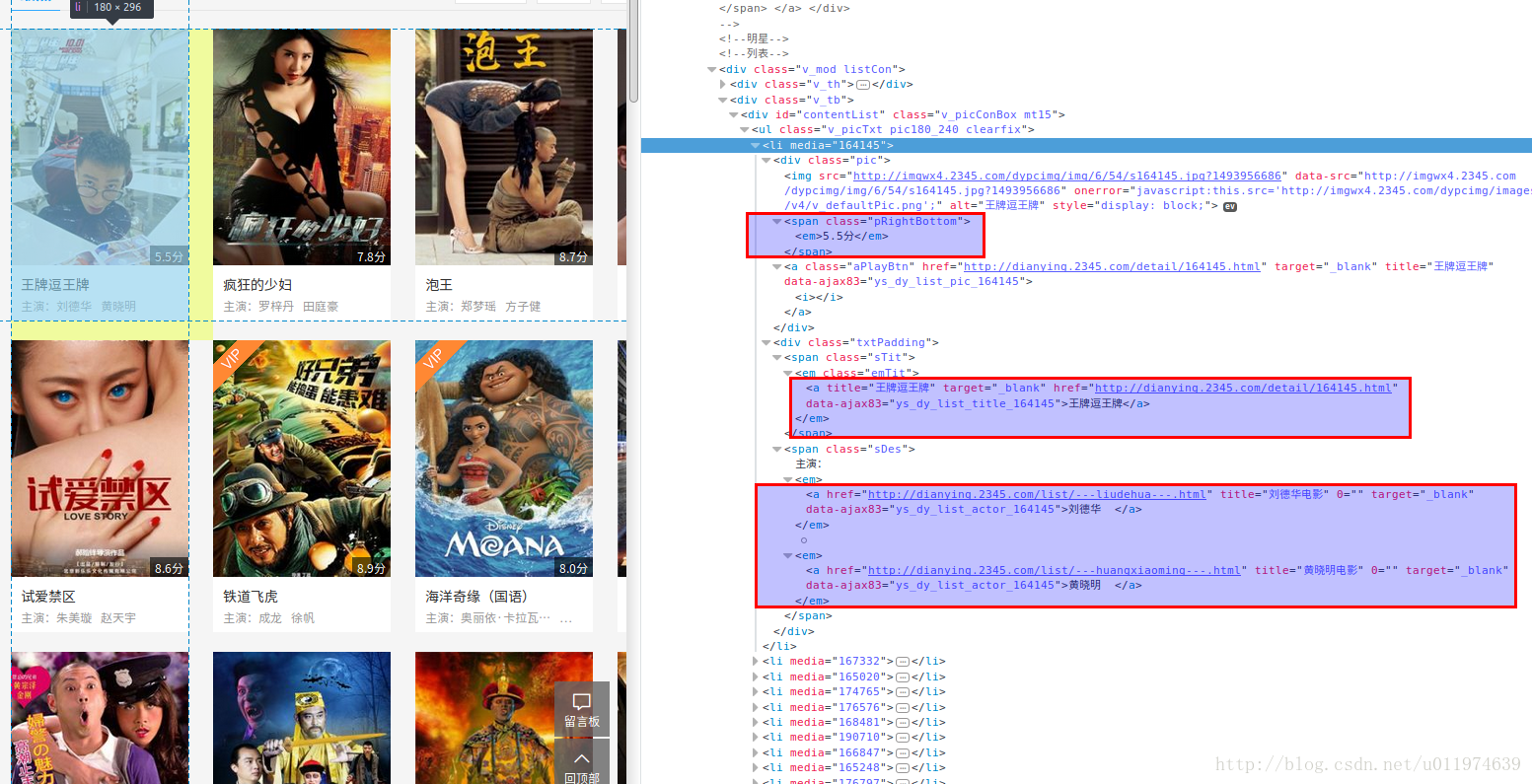
所有的电影信息都在class=”v_tb”的div标签内..
反爬虫处理
整体程序是模仿Scrapy来编写的,所以在做反爬虫处理中,直接操作getResponseContent方法即可.
修改爬虫程序的Headers
在getResponseContent方法中,添加
fakeHeaders= {'User-Agent':'Mozilla/5.0 (Windows NT 6.2; rv:16.0) Gecko/20100101 Firefox/16.0'}
#使用
request = urllib2.Request(url.encode('utf8'), headers=fakeHeaders)
#然后再使用
response = urllib2.urlopen(url)使用代理更改访问的IP地址
找到可以用的代理服务器,例如http协议,IP为192.168.2.99,端口为1080的代理服务器
#使用
proxy = urllib2.ProxyHandler({'http':'192.168.2.99:1080'})
opener = urllib2.build_opener(proxy)
urllib2.install_opener(opener)
#然后
response = urllib2.urlopen(request)
工程实现
创建工程
定义log模块用于调试记录操作数据
定义get2016movie模块,用于实现页面的数据抓取
- 模仿Scrapy框架,创建爬取内容Item
- 创建getUrls方法获取Url地址元组
- 创建getResponseContent方法用户获取页面数据,添加代理和修改Header方法
- 创建spider方法用于爬虫代码的具体编写
- 创建pipelines方法用于处理爬取的数据
mylog类(同上)
get2016movie类
#-*- coding: utf-8 -*-
'''
Created on 2017年6月7日
@author: root
'''
import codecs
import urllib2
from bs4 import BeautifulSoup
from mylog import MyLog as mylog
from anaconda_navigator.utils.py3compat import request
class MovieItem(object):
movieName = None
movieScore = None
movieStarring = None
class GetMovie(object):
'''获取电影信息 '''
def __init__(self):
self.urlBase = 'http://dianying.2345.com/list/xiju----2016---.html'
self.log = mylog()
self.pages = self.getPages()
self.urls = [] #url池
self.items = []
self.getUrls(self.pages) #获取抓取页面的url
self.spider(self.urls)
self.pipelines(self.items)
def getPages(self):
'''获取总页数 '''
self.log.info(u'开始获取页数')
htmlContent = self.getResponseContent(self.urlBase)
soup = BeautifulSoup(htmlContent, 'html.parser')
tag = soup.find('div', attrs={'class':'v_page'})
self.log.info(u'获取页数成功')
return (int)(tag.find_all('a')[-2].get_text())
def getResponseContent(self, url):
'''获取页面返回的数据 '''
# fakeHeaders= {'User-Agent':'Mozilla/5.0 (Windows NT 6.2; rv:16.0) Gecko/20100101 Firefox/16.0'}
# request = urllib2.Request(url.encode('utf8'), headers=fakeHeaders)
# request = urllib2.urlopen(url)
# proxy = urllib2.ProxyHandler({'http':'http://192.168.2.99:1080'}) 选用可用的代理
# opener = urllib2.build_opener(proxy)
# urllib2.install_opener(opener)
try:
response = urllib2.urlopen(url)
#response = urllib2.urlopen(request) #如果修改header或者使用代理,则传入request
except:
self.log.error(u'Python 返回URL:%s 数据失败' %url)
else:
self.log.info(u'Python 返回URUL:%s 数据成功' %url)
return response.read()
def getUrls(self, pages):
urlHead = 'http://dianying.2345.com/list/xiju----2016---'
urlEnd = '.html'
for i in xrange(1,pages + 1):
url = urlHead + str(i) + urlEnd
self.urls.append(url)
self.log.info(u'添加URL:%s 到URLS列表' %url)
def spider(self, urls):
for url in urls:
htmlContent = self.getResponseContent(url)
soup = BeautifulSoup(htmlContent, 'lxml') #lxml留下的数据包含电影的所有信息
anchorTag = soup.find('div', attrs={'class':'v_tb'})
tags = anchorTag.find_all('li')
for tag in tags:
item = MovieItem()
item.movieName = tag.find('span', attrs={'class':'sTit'}).em.get_text()
item.movieScore = tag.find('span', attrs={'class':'pRightBottom'}).em.get_text().replace(u'分', '')
item.movieStarring = tag.find('span', attrs={'class':'sDes'}).get_text().replace(u'主演:', '')
self.items.append(item)
self.log.info(u'获取电影名为:<<%s>>成功' %(item.movieName))
def pipelines(self, items):
fileName = u'2016热门电影.txt'.encode('utf8')
with codecs.open(fileName, 'w', 'utf8') as fp:
for item in items:
fp.write('%s t %s t %s rn' %(item.movieName, item.movieScore, item.movieStarring))
self.log.info(u'电影名为:<<%s>>已成功存入文件"%s"...' %(item.movieName, fileName.decode('utf8')))
if __name__ == '__main__':
GM = GetMovie()执行结果
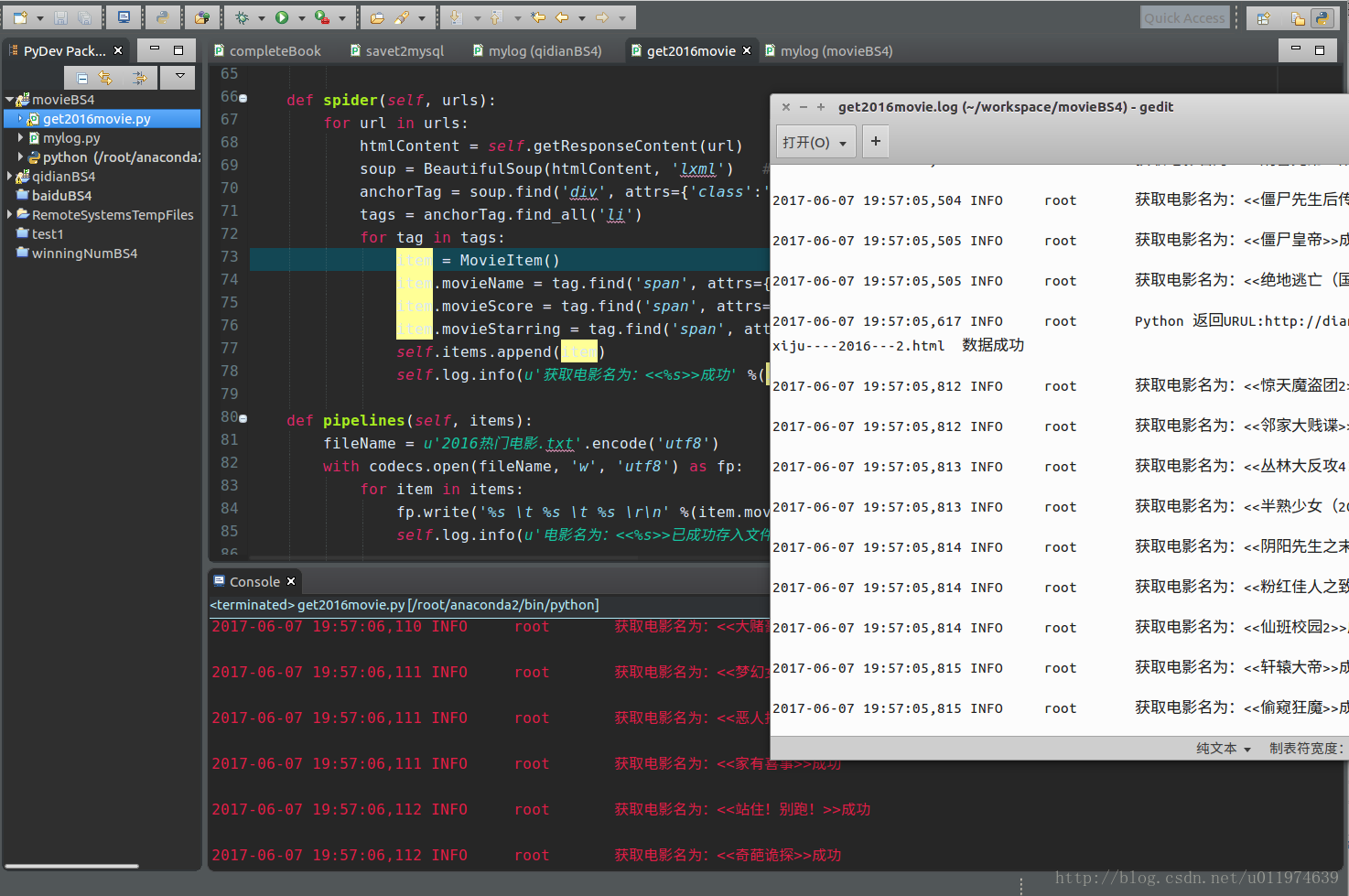
大概到第三页会有错误,仔细看第三页的网页代码布局是另一种,解决方法可以分别讨论,也可以使用正则表达式.
BS4实战-获取音悦台榜单
任务目标
获取音悦台http://www.yinyuetai.com/公布的MV榜单信息.
网页分析
URL分析
在音悦台网站选择MV榜单-内地篇
查看榜单的所有URL
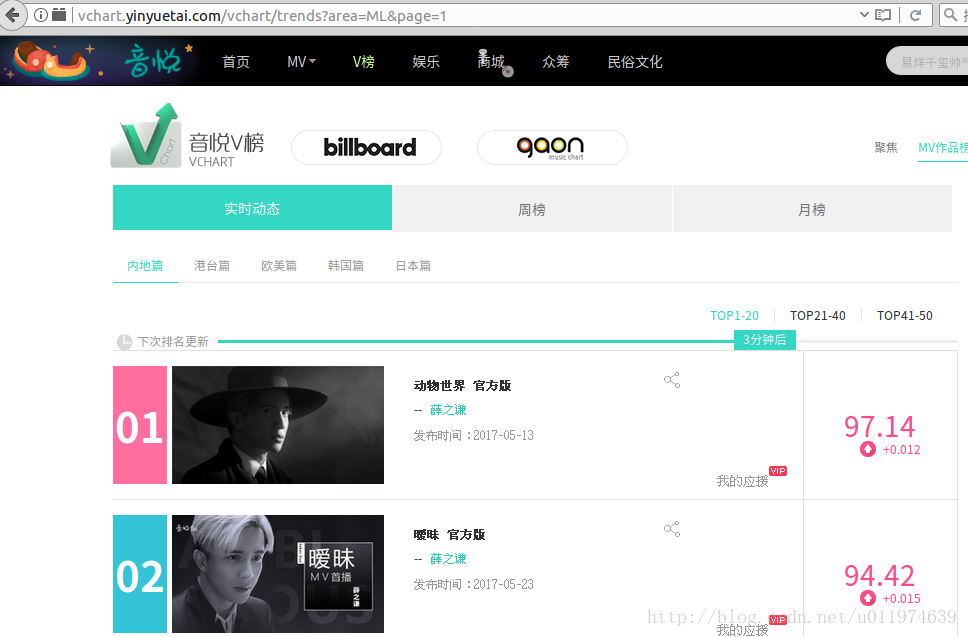
第一页:http://vchart.yinyuetai.com/vchart/trends?area=ML&page=1
下一页 :http://vchart.yinyuetai.com/vchart/trends?area=ML&page=2
最后一页:http://vchart.yinyuetai.com/vchart/trends?area=ML&page=3
可以看出,同一榜单的URL区别在于page参数
查看其它榜单的URL:
- 港台榜:http://vchart.yinyuetai.com/vchart/trends?area=HT&page=1
- 欧美榜单:http://vchart.yinyuetai.com/vchart/trends?area=US&page=1
- 韩国榜:http://vchart.yinyuetai.com/vchart/trends?area=KR&page=1
- 日本榜:http://vchart.yinyuetai.com/vchart/trends?area=JP&page=1
分析不同的榜单,发现区别在于area参数
到这里URL的规律已经很明显了~
数据分析
使用浏览器工具查看网页的源代码
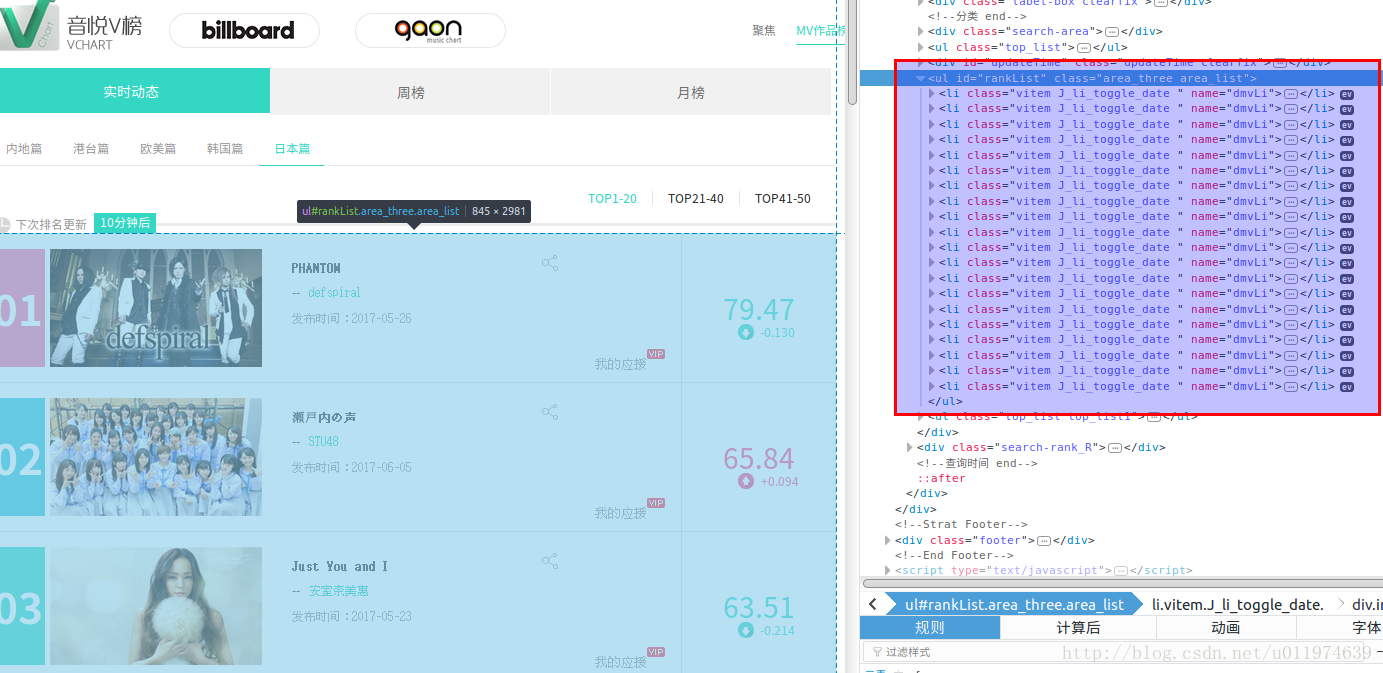
所有的榜单MV信息都在属性id=”rankList”的ul标签内.
工程实现
创建工程
定义log模块用于调试记录操作数据
定义resource模块用于存储headers和proxy资料
- 建立UserAgents元组存储多个UserAgent
- 建立PROXIES元组存储多个Proxy(可使用Scrapy内那个获取代理的程序动态维护)
定义getTrendsMV模块,用于实现页面的数据抓取
- 模仿Scrapy框架,创建爬取内容Item
- 创建getUrls方法获取Url地址元组
- 创建getResponseContent方法用户获取页面数据,添加代理和修改Header方法
- 创建spider方法用于爬虫代码的具体编写
- 创建pipelines方法用于处理爬取的数据
反爬虫处理
整体程序是模仿Scrapy来编写的,所以在做反爬虫处理中,直接操作getResponseContent方法即可.
修改爬虫程序的Headers,在getResponseContent方法中添加
fakeHeaders= {'User-Agent':self.getRandomHeaders()} #建立headers的库,随机挑选一个.使用代理更改IP地址,找到可以用的代理服务器
例如http协议,IP为192.168.2.99,端口为1080的代理服务器。
proxy = urllib2.ProxyHandler({'http':self.getRandomProxy()}) #建立proxy库,随机挑选一个proxy.mylog类(同上)
resource类
resource内的UserAgents数据信息会根据版本迭代而改变,代理可能会不可用,要检查
#-*- coding: utf-8 -*-
'''
Created on 2017年6月7日
@author: root
'''
UserAgents = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
]
PROXIES = [
'58.20.238.103:9797',
'123.7.115.141:9797',
'121.12.149.18:2226',
'176.31.96.198:3128',
'61.129.129.72:8080',
'115.238.228.9:8080',
'124.232.148.3:3128',
'124.88.67.19:80',
'60.251.63.159:8080',
'118.180.15.152:8102'
]getTrendsMV类
#-*- coding: utf-8 -*-
'''
Created on 2017年6月7日
@author: root
'''
import time
import codecs
import random
import urllib2
import resource
from bs4 import BeautifulSoup
from mylog import MyLog as mylog
class Item(object):
top_num = None #排名
score = None #打分
mvName = None #MV名字
singer = None #演唱者
releasTime = None #释放时间
class GetMvList(object):
'''The all data from www.yinyuetai.com
所有数据都来自www.yinyuetai.com
'''
def __init__(self):
self.urlBase = 'http://vchart.yinyuetai.com/vchart/trends?'
self.areasDic = {'ML':'Mainland','HT':'Hongkong&Taiwan','US':'Americ','KR':'Korea','JP':'Japan'}
self.log = mylog()
self.getUrls()
def getUrls(self):
'''获取url池 '''
areas = ['ML','HT','US','KR','JP']
pages = [str(i) for i in range(1,4)]
for area in areas:
urls = []
for page in pages:
urlEnd = 'area=' + area + '&page=' + page
url = self.urlBase + urlEnd
urls.append(url)
self.log.info(u'添加URL:%s 到URLS' %url)
self.spider(area, urls)
def getResponseContent(self, url):
'''从页面返回数据 '''
'''考虑到resource的proxy资源存活期太短,如果要使用代理,使用注释内的代码即可'''
# fakeHeaders = {'User-Agent':self.getRandomHeaders()}
# request = urllib2.Request(url.encode('utf8'), headers=fakeHeaders)
# proxy = urllib2.ProxyHandler({'http':'http://'+self.getRandomProxy()})
# opener = urllib2.build_opener(proxy)
# urllib2.install_opener(opener)
try:
# response = urllib2.urlopen(request)
response = urllib2.urlopen(url)
time.sleep(1)
except:
self.log.error(u'Python 返回URL:%s 数据失败' %url)
return ''
else:
self.log.info(u'Python 返回URUL:%s 数据成功' %url)
return response.read()
def spider(self,area,urls):
items = []
for url in urls:
responseContent = self.getResponseContent(url)
if not responseContent:
continue
soup = BeautifulSoup(responseContent, 'lxml')
tags = soup.find_all('li', attrs={'name':'dmvLi'})
for tag in tags:
item = Item()
item.top_num = tag.find('div', attrs={'class':'top_num'}).get_text()
if tag.find('h3', attrs={'class':'desc_score'}):
item.score = tag.find('h3', attrs={'class':'desc_score'}).get_text()
else:
item.score = tag.find('h3', attrs={'class':'asc_score'}).get_text()
item.mvName = tag.find('img').get('alt')
item.singer = tag.find('a', attrs={'class':'special'}).get_text()
item.releaseTime = tag.find('p', attrs={'class':'c9'}).get_text()
items.append(item)
self.log.info(u'添加mvName为<<%s>>的数据成功' %(item.mvName))
self.pipelines(items, area)
def getRandomProxy(self): #随机选取proxy代理
return random.choice(resource.PROXIES)
def getRandomHeaders(self): #随机选取文件头
return random.choice(resource.UserAgents)
def pipelines(self, items, area): #处理获取的数据
fileName = 'mvTopList.txt'
nowTime = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
with codecs.open(fileName, 'a', 'utf8') as fp:
fp.write('%s -------%srn' %(self.areasDic.get(area), nowTime))
for item in items:
fp.write('%s %s t %s t %s t %s rn'
%(item.top_num, item.score, item.releaseTime, item.singer, item.mvName))
self.log.info(u'添加mvName为<<%s>>的MV到%s...' %(item.mvName, fileName))
fp.write('rn'*4)
if __name__ == '__main__':
GML = GetMvList()执行结果
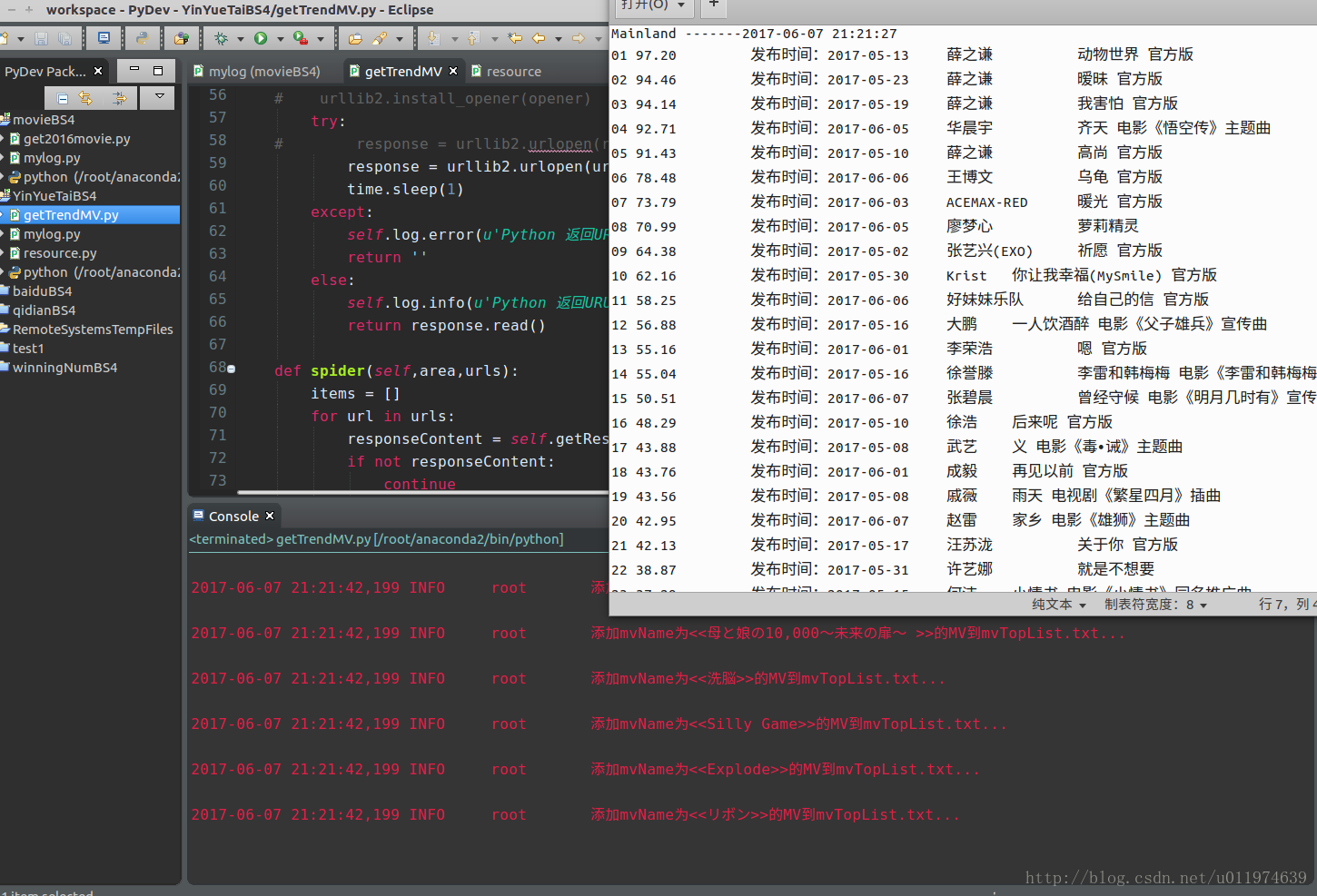
榜单获取有缺失,考虑到页面布局有不同,这里不详细考虑了
参考资料
《Python网络爬虫实战》 -胡松涛
最后
以上就是朴素犀牛最近收集整理的关于BeautifulSoup-爬虫实战BS4介绍BS4的官方文档教程安装BeautifulSoup包Eclipse下配置Python环境安装BeautifulSoup解析器使用BS4过滤器使用BS4快速定位标签BS4实战-获取百度贴吧内容BS4实战-获取双色球中奖信息BS4实战-获取起点小说信息BS4实战-获取电影信息BS4实战-获取音悦台榜单参考资料的全部内容,更多相关BeautifulSoup-爬虫实战BS4介绍BS4内容请搜索靠谱客的其他文章。








发表评论 取消回复