一、网络爬虫及requests库
# 网络爬虫
import requests
def gethtml(url):
try:
r = requests.get(url,timeout=300)
#r.raise_for_status() #如果不是200则产生异常,页面状态返回304,也会异常,所以暂时注释
r.encoding = 'utf-8'
return r.text
except:
return "error"
print(gethtml("https://www.xxxx.edu.cn/yxsz/jsjxy.htm"))直接调用gethtml()函数可能会被防火墙拦截,导致无法访问
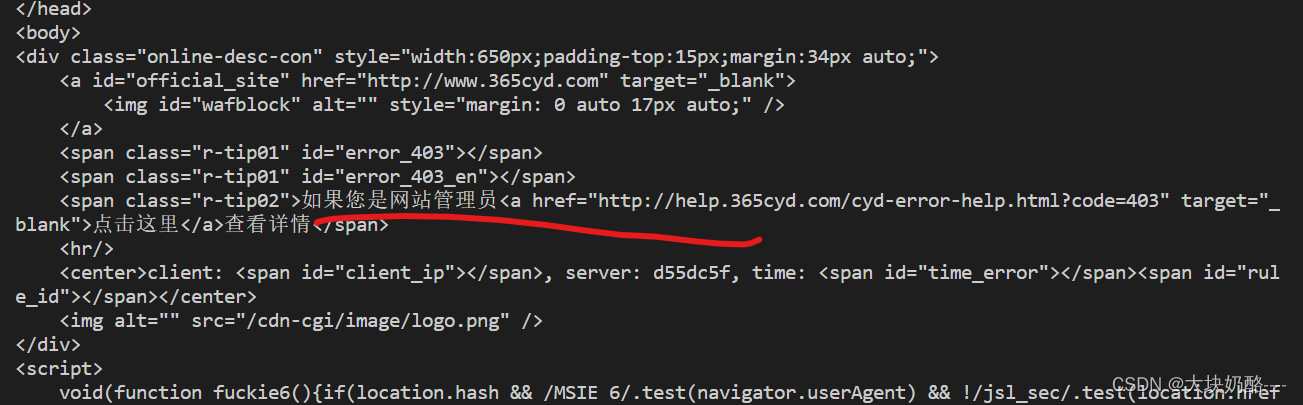
1.解决办法:添加请求标头
# 网络爬虫天添加使用请求标头访问
import requests
def gethtml(url,headers):
try:
r = requests.get(url,headers=headers,timeout=300)
#r.raise_for_status() #如果不是200则产生异常,页面状态返回304,也会异常,所以暂时注释
r.encoding = 'utf-8'
return r.text
except:
return "error"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.134 Safari/537.36 Edg/103.0.1264.77",
"Cookie":"__jsluid_s=68e5061305a17f63a83b50893c264a29; JSESSIONID=D7C74F0B47831552FAD50EFF5AFCB159"
}
soup = gethtml("https://www.xxx.edu.cn/yxsz/jsjxy.htm",headers)
print(soup)绕过限制成功访问

2.请求标头的通用方法:
headers = """Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
Cache-Control: max-age=0
Connection: keep-alive
Cookie: __jsluid_s=68e5061305a17f63a83b50893c264a29; JSESSIONID=D7C74F0B47831552FAD50EFF5AFCB159
Host: www.xxx.edu.cn
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.134 Safari/537.36 Edg/103.0.1264.77
"""
pattern = re.compile(r"([a-z.-]+):s*(.+)",re.I)#查找:英文+空格+字符串+n
dt=pattern.findall(headers)
headers = dict(dt)
使用正则表达式,需引入re库。
第30行生成正则表达式,用“冒号:将每一行分割出两部分,re.I忽略大小写。更详细的正则参考
Python 正则表达式 | 菜鸟教程 (runoob.com)
第31行使用findall()函数将headers变量转换为列表,每行为键值对的元组。

使用浏览器访问网站,使用F12打开开发人员工具,复制请求标头到代码headers变量中,即可模拟浏览器访问
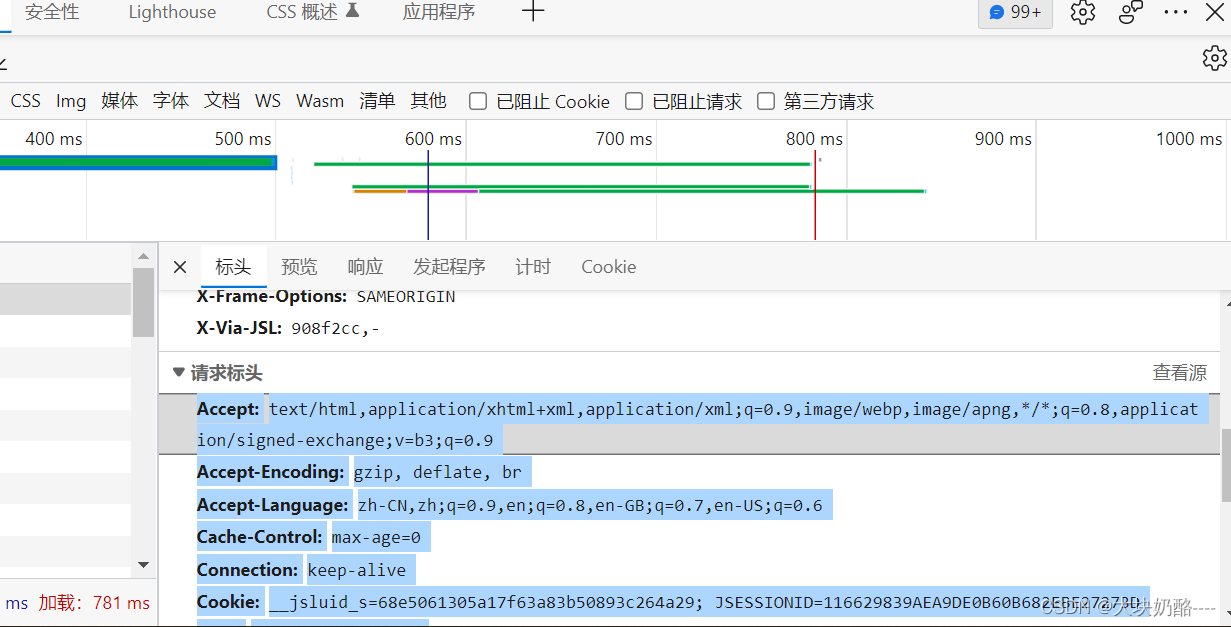
3.使用python变量时候,一定要注意变量的类型,例如:m=‘{1:2,3:4}’,尽管m变量内容与字典一致,但仍为字符串变量,不能使用dict(m)转换为字典。而使用eval(m)转换为字典。
m = '{1:2,3:4}'
print(dict(m))
list()将字符串的每个字符都作为元素,创建一个列表
m = '[1,2,3,4]'
print(list(m))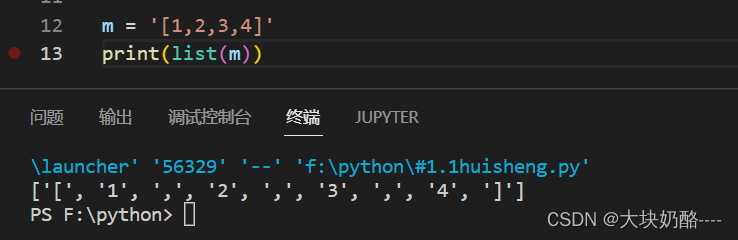
结论:值或内容符合列表、字典等数据内容的字符串变量,可以使用eval()函数转换为相应的python数据类型。
m = '{1:2,3:4}'
n = eval(m)
print(type(n),n)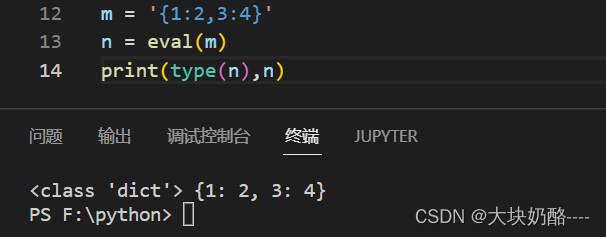
dict()函数可以直接将每个元素为双元素元组的列表直接转为字典。
m = [(1,2),('a','b')]
n = dict(m)
print(type(n),n)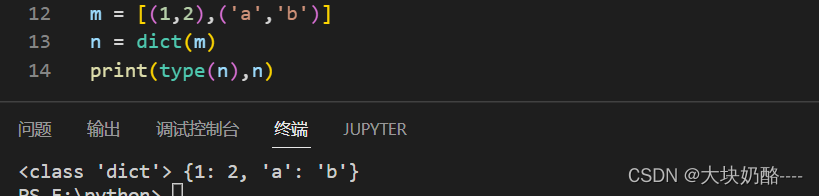
还可以使用正则表达式的findall()函数将headers变量转换为元素为元组的列表,再用dict()转为字典类型。 参见前文。
二、beautifulsoup4库解析和处理HTML
# 网络爬虫
import requests
from bs4 import BeautifulSoup
def gethtml(url,headers):
try:
r = requests.get(url,headers=headers,timeout=300)
#r.raise_for_status() #如果不是200则产生异常,页面状态返回304,也会异常,所以暂时注释
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text)
return soup
except:
return "error"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.134 Safari/537.36 Edg/103.0.1264.77",
"Cookie":"__jsluid_s=68e5061305a17f63a83b50893c264a29; JSESSIONID=D7C74F0B47831552FAD50EFF5AFCB159"
}
soup = gethtml("https://www.xxx.edu.cn/yxsz/jsjxy.htm",headers)
dd = soup.find_all("dd")
print(dd)
link = {}
for a in dd:
aa = a.find_all("a")
for s in aa:
link[s.string] = s.attrs["href"]
#print(link)1.使用BeautifulSoup()函数创建一个BeautifulSoup对象,BeautifulSoup对象是一个树形结构,它包含HTML页面中的每一个Tag标签(元素),如<head>,<body>,可以使用<a>.<b>,<a>为对象名称,<b>为HTML标签的名字,直接调用soup.b只能返回一个b标签,要访问多个则使用find_all(b)。
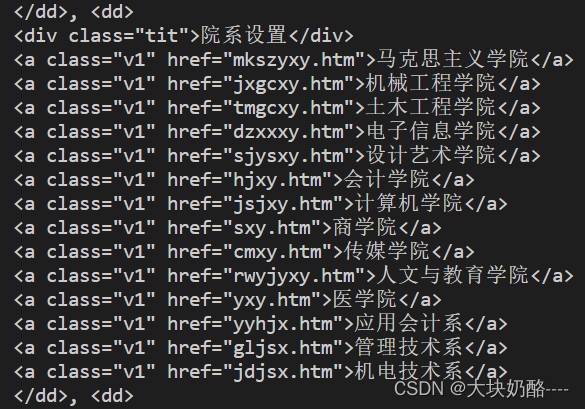
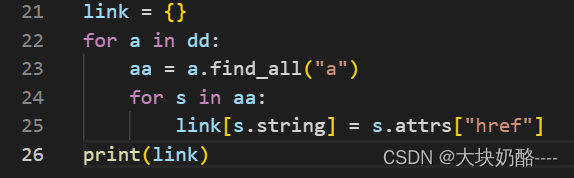
第22行,循环dd,第23行,获取每个<dd>.<a>,第24循环aa,将HTML中的<a>的string及属性attrs中的href分别作为键值写入字典link中。
2.BeautifulSoup对象的常用属性有:name(字符串)、attrs(字典)、contents(列表)、string(字符串)
对应Tag标签结构
<a class="v1" href="mkszyxy.htm">马克思主义学院</a>其中尖括号<>中标签的名字a为name,尖括号内其他项“class="v1" href="mkszyxy.htm"”都是attrs,尖括号之间“马克思主义学院”为string,这个Tag下的所有子Tag的内容为contents
3、爬取页面table
soup = gethtml("https://zhaosh.xijing.edu.cn/zhaosheng/search?year=2021&cengci=3&shengfen=&kelei=",headers)
table = soup.find_all("table")
print(table)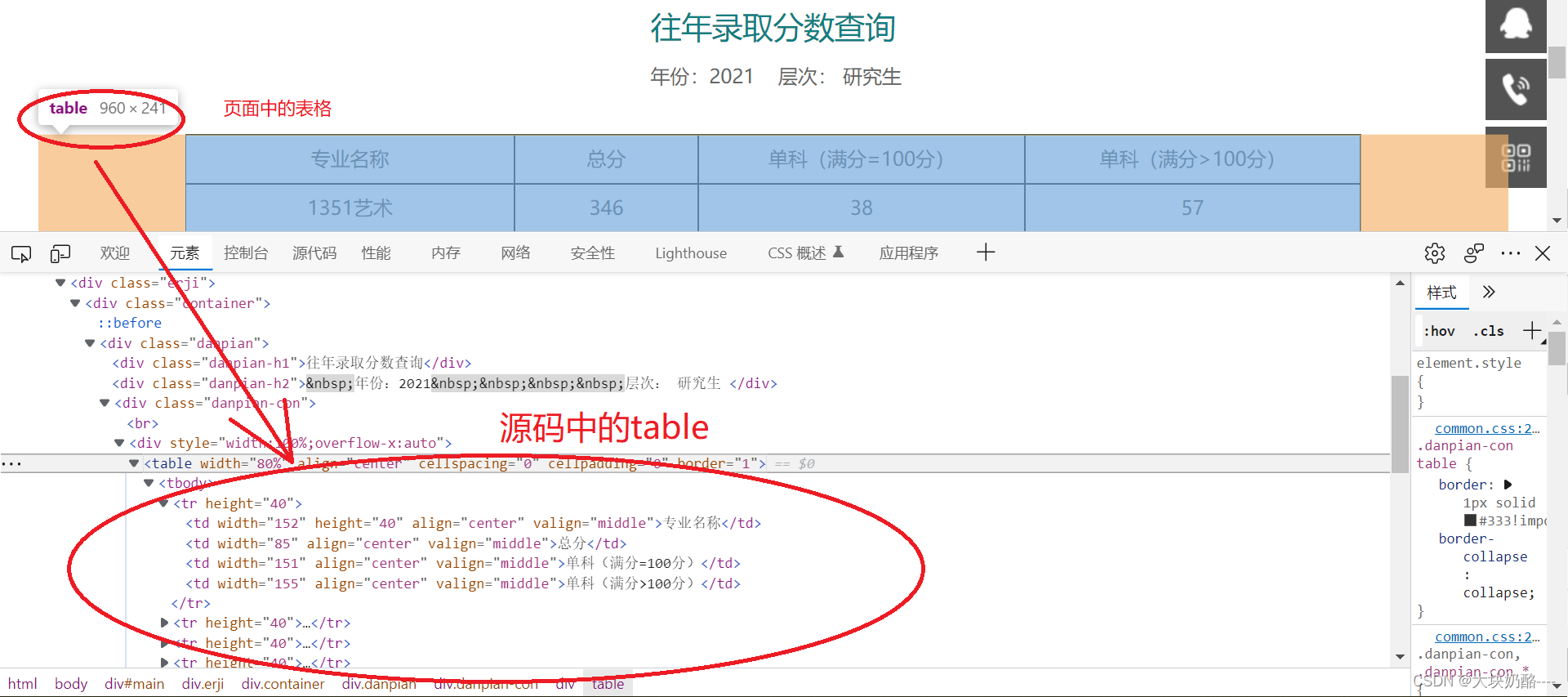
Python执行结果:
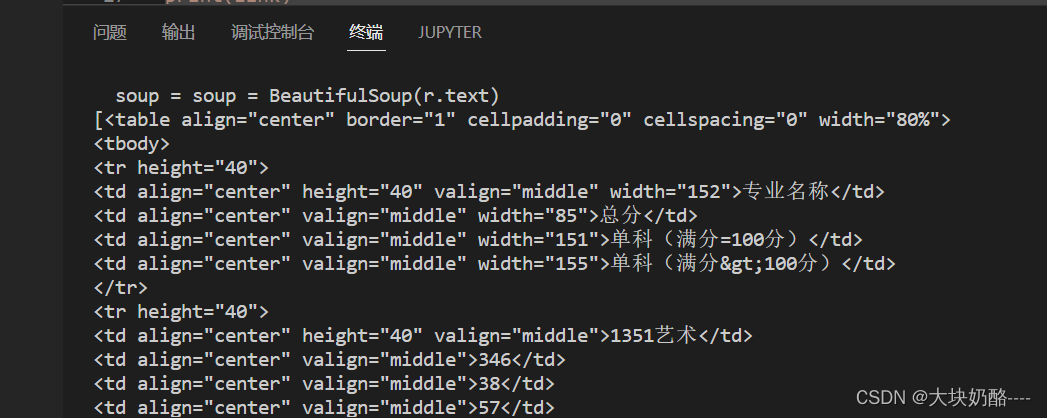
BeautifulSoup对象table
3.find_all()函数
find_all(tag, attributes, recursive, text, limit, keywords)
find(tag, attributes, recursive, text, keywords)
一般只用前2个参数:tag,attributes
tag
可以传一个标签的名称或多个标签名称组成的 Python列表做标签参数。例如:.find_all({"h1","h2","h3","h4","h5","h6"})
attributes
属性参数 attributes 是用一个 Python 字典封装一个标签的若干属性和对应的属性值。例如,下面这个函数会返回 HTML 文档里红色与绿色两种颜色的 span 标签:
.find_all("span", {"class":{"green", "red"}})
如果只返回一种颜色的,如绿色:
.find_all("span", {"class": "green"})
recursive
递归参数 recursive 是一个布尔变量。你想抓取 HTML 文档标签结构里多少层的信息?如果recursive 设置为 True , find_all 就会根据你的要求去查找标签参数的所有子标签,以及子标签的子标签。如果 recursive 设置为 False , find_all 就只查找文档的一级标签。 find_all默认是支持递归查找的( recursive 默认值是 True );一般情况下这个参数不需要设置。
text
文本参数 text 有点不同,它是用标签的文本内容去匹配,而不是用标签的属性。假如我们想查找前面网页中包含“the prince”内容的标签数量,我们可以把之前的 find_all 方法换成下面的代码:
nameList = bsObj.find_all(text="the prince")
print(len(nameList))
limit
范围限制参数 limit ,显然只用于 find_all 方法。 find 其实等价于 find_all 的 limit 等于1 时的情形。如果你只对网页中获取的前 x 项结果感兴趣,就可以设置它。
keywords
可以让你选择那些具有指定属性的标签,属于冗余的技术,如下所示:第一行采用keywords,第二行采用前两个参数:tag、attributes
bsObj.find_all(id="text")
bsObj.find_all("", {"id":"text"})
用 keyword 偶尔会出现问题,尤其是在用 class 属性查找标签的时候,因为 class 是 Python 中受保护的关键字。所以一般只采用前2个参数tag、attributes即可。
最后
以上就是外向小松鼠最近收集整理的关于Python笔记九:网络爬虫及requests库、beautifulsoup4库解析和处理HTML的全部内容,更多相关Python笔记九内容请搜索靠谱客的其他文章。








发表评论 取消回复