如何使用
将一段文档传入BeautifulSoup 的构造方法,就能得到一个文档的对象, 可以传入一段字符串或一个文件句柄.
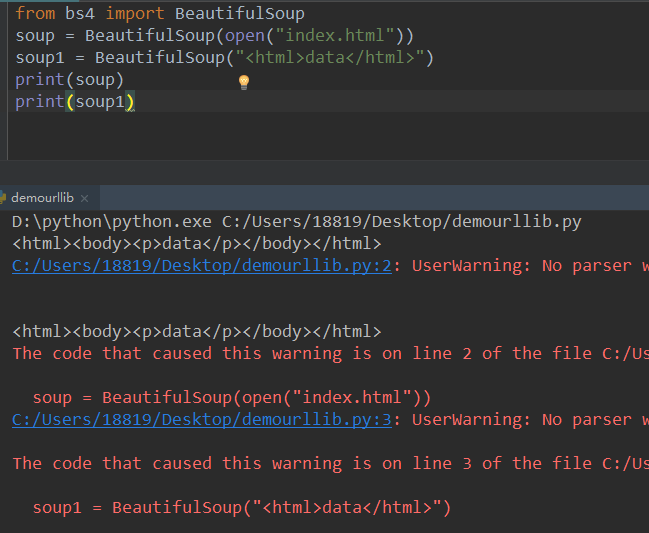
from bs4 import BeautifulSoup
soup = BeautifulSoup(open("index.html"))
soup1 = BeautifulSoup("<html>data</html>")
print(soup)
print(soup1)
打印虽让会有结果,然是会一些提示:
提示说的是建议我们指定一个解析器,像这样:
from bs4 import BeautifulSoup
soup = BeautifulSoup(open("index.html"),features="lxml")
soup1 = BeautifulSoup("<html>data</html>",features="lxml")
print(soup)
print(soup1)
如果不指定的话,Beautiful Soup会选择最合适的解析器来解析这段文档,具体可参考 解析成XML
对象的种类
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种: Tag , NavigableString , BeautifulSoup , Comment .
Tag
Tag 对象与XML或HTML原生文档中的tag相同:
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>')
tag = soup.b
type(tag)
# <class 'bs4.element.Tag'>
Tag有很多方法和属性,现在介绍一下tag中最重要的属性: name和attributes
Name
每个tag都有自己的名字,通过 .name 来获取:
tag.name
# b
如果改变了tag的name,那将影响所有通过当前Beautiful Soup对象生成的HTML文档:
tag.name = "blockquote"
tag
# <blockquote class="boldest">Extremely bold</blockquote>
Attributes
一个tag可能有很多个属性. tag 有一个 “class” 的属性,值为 “boldest” . tag的属性的操作方法与字典相同:
tag['class']
# boldest
也可以直接”点”取属性, 比如: .attrs :
tag.attrs
# {class: boldest}
tag的属性可以被添加,删除或修改. 再说一次, tag的属性操作方法与字典一样
tag['class'] = 'verybold'
tag['id'] = 1
tag
# <blockquote class="verybold" id="1">Extremely bold</blockquote>
del tag['class']
del tag['id']
tag
# <blockquote>Extremely bold</blockquote>
tag['class']
# KeyError: 'class'
print(tag.get('class'))
# None
多值属性
HTML 4定义了一系列可以包含多个值的属性.在HTML5中移除了一些,却增加更多.最常见的多值的属性是 class (一个tag可以有多个CSS的class). 还有一些属性 rel , rev , accept-charset , headers , accesskey . 在Beautiful Soup中多值属性的返回类型是list:
css_soup = BeautifulSoup('<p class="body strikeout"></p>')
css_soup.p['class']
# ["body", "strikeout"]
css_soup = BeautifulSoup('<p class="body"></p>')
css_soup.p['class']
# ["body"]
如果某个属性看起来好像有多个值,但在任何版本的HTML定义中都没有被定义为多值属性,那么Beautiful Soup会将这个属性作为字符串返回
id_soup = BeautifulSoup('<p id="my id"></p>')
id_soup.p['id']
# 'my id'
将tag转换成字符串时,多值属性会合并为一个值
rel_soup = BeautifulSoup('<p>Back to the <a rel="index">homepage</a></p>')
rel_soup.a['rel']
# ['index']
rel_soup.a['rel'] = ['index', 'contents']
print(rel_soup.p)
# <p>Back to the <a rel="index contents">homepage</a></p>
如果转换的文档是XML格式,那么tag中不包含多值属性
xml_soup = BeautifulSoup('<p class="body strikeout"></p>', 'xml')
xml_soup.p['class']
# body strikeout
可以遍历的字符串
字符串常被包含在tag内.Beautiful Soup用 NavigableString 类来包装tag中的字符串:
tag.string
# u'Extremely bold'
type(tag.string)
# <class 'bs4.element.NavigableString'>
tag中包含的字符串不能编辑,但是可以被替换成其它的字符串,用 replace_with() 方法:
tag.string.replace_with("No longer bold")
tag
# <blockquote>No longer bold</blockquote>
一个 NavigableString 字符串与Python中的Unicode字符串相同,通过 unicode() 方法可以直接将 NavigableString 对象转换成Unicode字符串:
unicode_string = unicode(tag.string)
unicode_string
# u'Extremely bold'
type(unicode_string)
# <type 'unicode'>
注释及特殊字符串
Tag , NavigableString , BeautifulSoup 几乎覆盖了html和xml中的所有内容,但是还有一些特殊对象.容易让人担心的内容是文档的注释部分:
markup = "<b><!--Hey, buddy. Want to buy a used parser?--></b>"
soup = BeautifulSoup(markup)
comment = soup.b.string
type(comment)
# <class 'bs4.element.Comment'>
Comment 对象是一个特殊类型的 NavigableString 对象:
comment
# Hey, buddy. Want to buy a used parser
最后
以上就是调皮发带最近收集整理的关于python3爬虫(八)--BeautifulSoup4的基本使用的全部内容,更多相关python3爬虫(八)--BeautifulSoup4内容请搜索靠谱客的其他文章。








发表评论 取消回复