我是靠谱客的博主 自由芝麻,这篇文章主要介绍分布式日志分析系统构建实战(一)——概述日志分析Elastic Stack(ELK)Flume+Kafka+Storm相关文章,现在分享给大家,希望可以做个参考。
日志分析
日志分析是每个互联网公司业务流中不可缺少的一部分,从海量数据中,可以分析用户的行为,从而运用到智能预测或者异常检测当中去。相比与传统的大数据分析(如用户物品评分预测),日志分析具有这么几个特征:
- 数据是动态的。传统的大数据分析,往往是基于已有的数据去进行处理,这些数据都是固定不变的。而对于日志分析,只要产品还在运营,日志就会源源不断的产生,很难去规定一个节点去进行静态的处理分析。因此,以hadoop为代表的批量式处理的分布式系统是无法运用的。对应的,流式系统才是日志分析的首选。
- 数据是多方面的。公司的产品往往不止一个,同一个产品也可以分为web,android和IOS。因此,所需要处理的日志往往是从多个端口同时产生的。如何对这些日志去进行集中处理,统一分析,同时又要做好防灾备份处理,也是日志分析的一个关键点。
当然,日志分析已经是一个相对成熟的业务,针对以上特性,行业内已经总结出了几套较为成熟的解决方案:
Elastic Stack(ELK)
Elastic是为了实时搜索和分析海量所设计的。它是由多个开源框架组合而成。
- Elasticsearch是一个搜索和分析引擎。它提供的查询语句,可以对各种各样结构化或者无结构化的数据进行实时的处理。
- Logstash是一个日志收集和分发系统。
- Kibana是一个图形化的数据分析平台。通过友好的WEB接口,可以提高数据处理的效率。
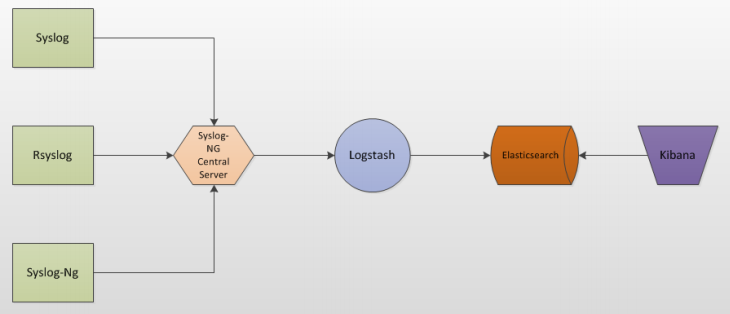
目前我尚未对这套系统做过深入的研究,在此就不做具体的评论了。以后有机会一定补充。
Flume+Kafka+Storm
这是目前比较流行的一套组合。值得一提的是,这三个开源框架目前都是apache的孵化项目,品质值得保证。
- Flume是一个日志收集和分发系统。在这个系统中,Flume会将各个入口产生的日志进行汇总。
- Kafka是一个消息传递平台。基于Kafka,可以同时存在多个消息生产者和订阅者,这样就可以为并行处理提供一个方便的入口。而Kafka则会自己构建起一个集群,用来保证消息的完整性。Kafka提供了topic用来对消息进行分类,可以根据需要对不同类的消息做不同的处理。
- Storm是一个流式处理的分布式处理框架。Storm引入了拓扑(topology)的概念,数据会沿着拓扑流过每一层的节点。因此,进入storm的数据,都可以确保经过了相同的处理过程。这个特性还使得Storm可以从同时开设多个数据入口,根据具体的业务和机群进行调配,提高数据处理的效率。
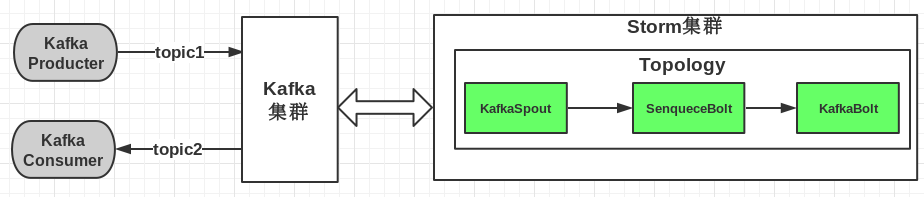
和ELF类似,Flume负责日志收集,kafka负责消息传递,storm负责对数据进行处理。不同的是,这三个框架的耦合性较低,全部通过各自的接口来进行整合。但功能衔接的十分恰当,同时,各个平台本身都支持不同语言进行开发,提供了高度的扩展性和可定制性。Flume和Storm都属于实时的数据处理,比较适合日志分析这个业务。至于和ELK的优劣,暂时没能找到一个详细的分析,在此先不作评论。
这个组合是我目前正在开发的部分,其中日志收集由另一部门进行负责,因此对flume没有接触。接下来的部分我会对这个组合进行详细的讲解。在实践中遇到的一些难点也会进行总结。
相关文章
- Elastic Stack
- 开源实时日志分析ELK平台部署
- Storm集成Kafka编程模型
- Kafka+Storm+HDFS整合实践
最后
以上就是自由芝麻最近收集整理的关于分布式日志分析系统构建实战(一)——概述日志分析Elastic Stack(ELK)Flume+Kafka+Storm相关文章的全部内容,更多相关分布式日志分析系统构建实战(一)——概述日志分析Elastic内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复