。。。。
explain
show profile
sleep(1),搜出的结果,1行睡1秒。
mysql性能分析工具 - 张啊咩 - 博客园
MySQL性能分析方法小结_东晨雨的博客-CSDN博客_mysql 性能分析
场景:
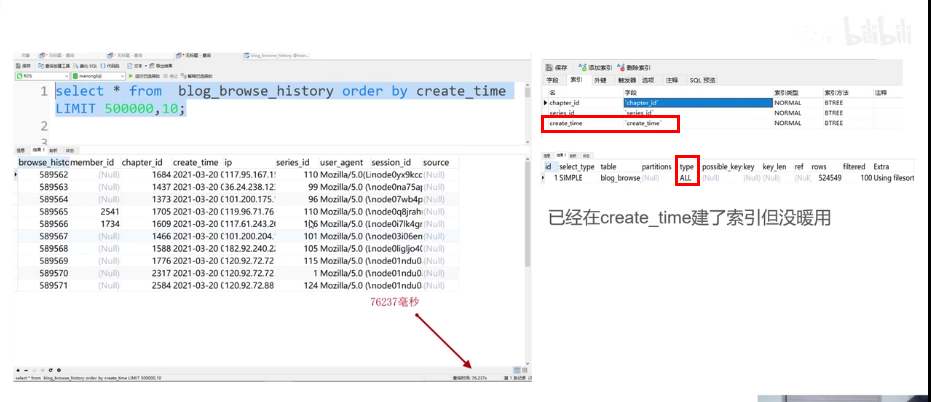
表里记录了用户在一些时间内看过的页面。表里有50万+的数据,每页10条,有5万多页。
现在想查某个ip在某个时间查看的页面。一般会以create_time排序,给create_time加索引。
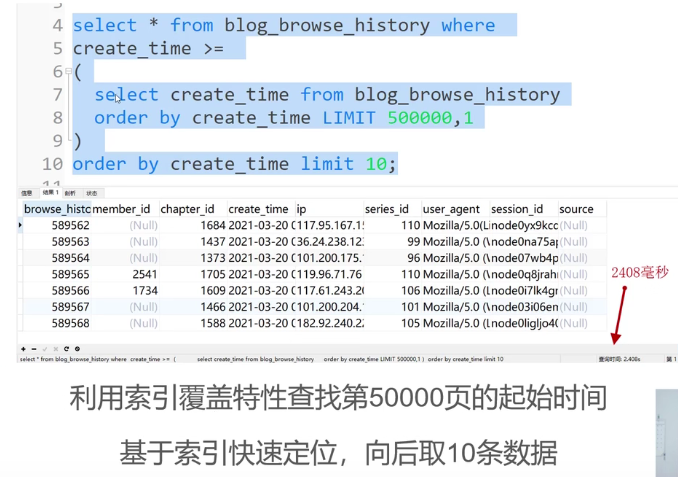
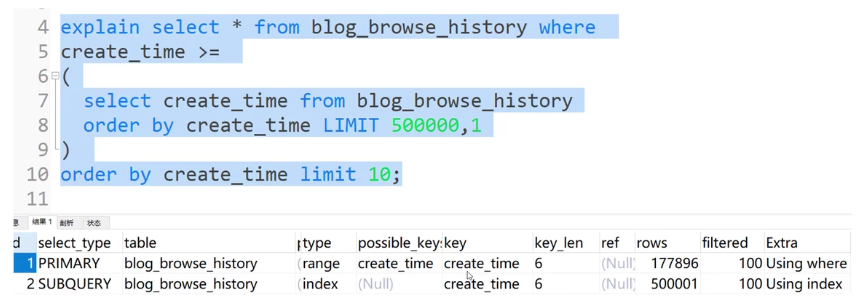
现在想看第50000页,一般sql语句如下,但很慢,create_time索引也没用上,type是all,依然全表扫描。因为没有where条件。
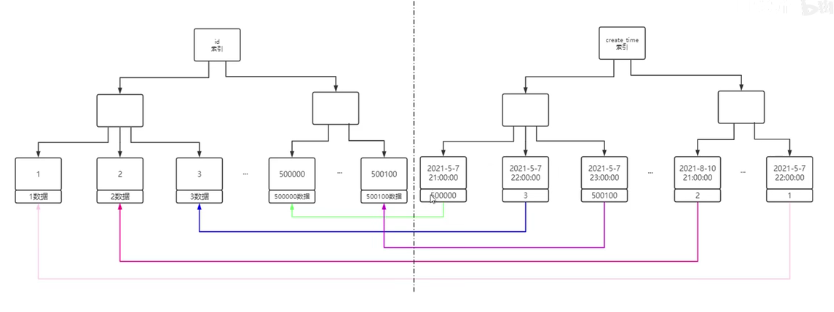
只有主键索引才会绑定数据,非主键索引的叶子节点关联到主键,
查询时只使用索引字段叫索引覆盖。
优化2:连续分页
一般用户点击下一页,用他当前页最后一条数据的时间作为条件,查询。即,当用户点击下一页,前端传时间过来。
由于这是阿里云最低配云服务器,如果是标准商用服务器,能在100ms以内。
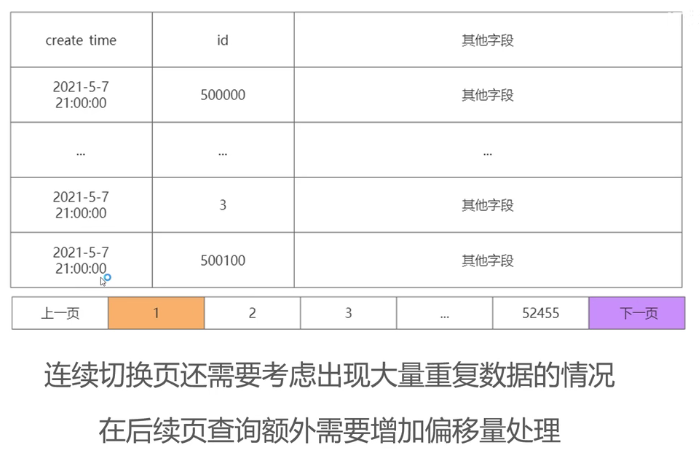
没有页码,只有上一页下一页,省去了count(*)。对于count(*),InnoDB不像myisam采用计数器,它是实时计算。分库分表的话,count(*)也很慢。
所以现在大规模的互联网应用,都不显示页码。
考虑点:
在高并发的情况下,会出现同一时间点多条数据,这时候,再用 create_time>xxx limit 10,就会一直查出同一条数据。需要增加偏移量。其实还有个方法,增加id作为条件。
select * from t1 where create_time>xxx and id>xxx limit 10;
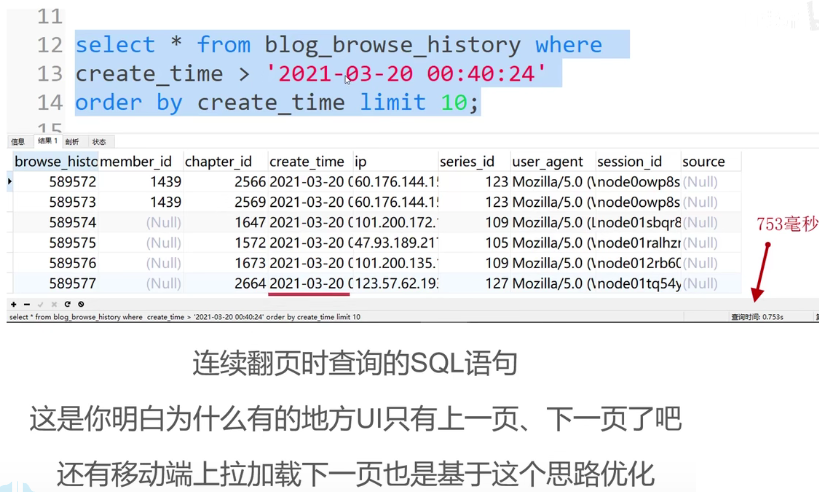
【IT老齐074】从76237到753毫秒,海量数据大页码MySQL查询该如何优化?_哔哩哔哩_bilibili
方式1:
select * from table order by id limit m, n;
但m越大,查询性能就越低,因为MySQL需要扫描全部m+n条记录。例如第50万条,捞10条,就要扫描50万零10条数据。
方式2:
select * from table where id > #max_id# order by id limit n;
不会像方式1扫描前m条记录,但必须在每次查询时拿到上一次查询(上一页)的最大id(或最小id),是比较常用的方式。
当然该查询的问题也在于我们不一定能拿到这个id,比如当前在第3页,需要查询第5页的数据,就不行了。
方式3:
为了避免方式2不能实现的跨页查询,就需要结合方式1。
性能需要,m得尽量小。比如当前在第3页,需要查询第5页,每页10条。#max_id#是第3页最后一条的id,则:
select * from table where id > #max_id# order by id limit 10, 10;
但如果当前在第2页,要查第1000页,性能仍然较差。不过前端做控制,最多选5页。
参考bing(5页),google(20多页),百度(几十页)。
方式4:
select * from table as a inner join (select id from table order by id limit m, n) as b on a.id = b.id order by a.id;
该查询同方式1一样,m的值可能很大,但由于内部的子查询只扫描了id字段,而非全表,所以性能要强于方式1,并且能够解决跨页查询问题。
方式5:
select * from table where id > (select id from table order by id limit m, 1) limit n;
该查询同样是通过子查询扫描字段id,效果同方式4。但方式5的性能会略好于方式4,因为它不需要进行表的关联,而是一个简单的比较,在不知道上一页最大id的情况下,是比较推荐的用法。
MySQL分页查询的5种方法 - 知乎
通过业务来解决技术问题 :
不让分页太多,淘宝也只是100页。
分布式,主键,字符串
面试被问到mysql调优如何回答_哔哩哔哩_bilibili
01 数字类型:避免自增踩坑.md
隔离级别RR,RC
MySQL 中隔离级别 RC 与 RR 的区别 - digdeep - 博客园
MySQL 默认隔离级别是RR,为什么阿里这种大厂会改成RC?-HollisChuang's Blog
最后
以上就是鲜艳蛋挞最近收集整理的关于mysql 性能 优化的全部内容,更多相关mysql内容请搜索靠谱客的其他文章。








发表评论 取消回复