Human language and word meaning
语言是一个低带宽的信息传输方式,相比于5G,这决定了语言的熵会很高。
How do we have usable meaning in a computer?
one-hot的字词表示:
- 词语维度是很高的,而且有很多衍生的词语,接近于无限的维度。
- 词语之间没有相似度,即one-hot向量是正交的,相似词语和不相似词语之间都是正交关系。
WordNet
一个工具,来获取词语的同义词、hypernyms ( is a relation, eg. panda is a procyonid, ), 缺点:
- 缺少细微差别
- 例如,某些情况下,proficient才是good的同义词,即特定的上下文。
- 缺少新词,难以实时更新:
- 主观、需要人力创建和修改,不能计算词语相似度。
分布式表达
使用词语周围的词语来表示其的意义。
Distributional semantics: A word’s meaning is given by the words that frequently appear close-by 、
使用此种方式训练神经网络得到词向量表达,并将其降维到2D,可视化的效果:
可以看到,are, is, were距离很近,向量相似度较高,而实际也是如此。

那么,问题来,怎么训练词向量呢?
Word2vec introduction
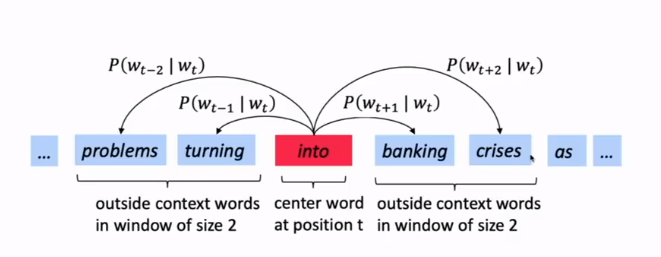
skip-gram:使用中心词语,来预测周围的词语。
最大化似然,目标是对于正确的上下文的词语,给出概率最大,
θ
theta
θ是参数:
L
i
k
e
l
i
h
o
o
d
=
L
(
θ
)
=
∏
t
=
1
T
∏
−
m
≤
j
≤
m
j
≠
0
P
(
w
t
+
j
∣
w
t
;
θ
)
Likelihood = L(theta) = prod_{t=1}^{T} prod_{-m leq j leq m atop j neq 0} Pleft(w_{t+j} | w_{t} ; thetaright)
Likelihood=L(θ)=t=1∏Tj̸=0−m≤j≤m∏P(wt+j∣wt;θ)
目标函数,注意加了负号,所以是最小化目标函数 :
J
(
θ
)
=
−
1
T
log
L
(
θ
)
=
−
1
T
∑
t
=
1
T
∑
−
m
≤
j
≤
m
j
≠
0
log
P
(
w
t
+
j
∣
w
t
;
θ
)
J(theta)=-frac{1}{T} log L(theta)=-frac{1}{T} sum_{t=1}^{T} sum_{-m leq j leq m atop j neq 0} log Pleft(w_{t+j} | w_{t} ; thetaright)
J(θ)=−T1logL(θ)=−T1t=1∑Tj̸=0−m≤j≤m∑logP(wt+j∣wt;θ)
那么如何计算概率
P
(
w
i
+
j
∣
w
t
;
θ
)
P(w_{i+j}|w_t;theta)
P(wi+j∣wt;θ)?
- 对于每个词语都有两个向量:
- w作为中心词的向量 v w v_w vw
- w作为上下文的向量 u w u_w uw
- 对于中心词语c,上下文词语o:
P ( o ∣ c ) = exp ( u o T v c ) ∑ w ∈ V exp ( u w T v c ) P(o | c)=frac{exp left(u_{o}^{T} v_{c}right)}{sum_{w in V} exp left(u_{w}^{T} v_{c}right)} P(o∣c)=∑w∈Vexp(uwTvc)exp(uoTvc)
那么,参数空间为 θ ∈ R 2 d ∗ v theta in R^{2d*v} θ∈R2d∗v,其实就是词向量。v是单词个数,v是词向量维度。 含义是中心词的词向量和上下文的词向量越相似,其概率就越大。那么想同上下文的词语,他们的词向量也就越相似(因为他们的中心词向量都和上下文词向量相似,他们之间也就相似)。
那么如何通过梯度下降优化呢,
∂
∂
v
c
J
(
θ
)
=
−
1
T
∑
t
=
1
T
∑
−
m
≤
j
≤
m
j
≠
0
∂
∂
v
c
log
P
(
w
t
+
j
∣
w
t
;
θ
)
frac{partial}{partial v_{c}} J(theta)=-frac{1}{T} sum_{t=1}^{T} sum_{-m leq j leq m atop j neq 0} frac{partial}{partial v_{c}} log Pleft(w_{t+j} | w_{t} ; thetaright)
∂vc∂J(θ)=−T1t=1∑Tj̸=0−m≤j≤m∑∂vc∂logP(wt+j∣wt;θ)
其中:
∂
∂
v
c
log
P
(
o
∣
c
)
=
∂
∂
v
c
log
exp
(
u
o
T
v
c
)
∑
w
∈
V
exp
(
u
w
T
v
c
)
=
∂
∂
v
c
logexp
(
u
o
T
v
c
)
−
∂
∂
v
c
log
∑
w
∈
V
exp
(
u
w
T
v
c
)
begin{array}{c}{frac{partial}{partial v_{c}} log P(o | c)=frac{partial}{partial v_{c}} log frac{exp left(u_{o}^{T} v_{c}right)}{sum_{w in V} exp left(u_{w}^{T} v_{c}right)}} \ {=frac{partial}{partial v_{c}} operatorname{logexp}left(u_{o}^{T} v_{c}right)-frac{partial}{partial v_{c}} log sum_{w in V} exp left(u_{w}^{T} v_{c}right)}end{array}
∂vc∂logP(o∣c)=∂vc∂log∑w∈Vexp(uwTvc)exp(uoTvc)=∂vc∂logexp(uoTvc)−∂vc∂log∑w∈Vexp(uwTvc)
对两项分别求偏导:
第一项: ∂ ∂ v c logexp ( u o T v c ) = u o frac{partial}{partial v_{c}} operatorname{logexp}left(u_{o}^{T} v_{c}right)=u_{o} ∂vc∂logexp(uoTvc)=uo
第二项复杂一些,需要用到链式法则,将log(x)看做一个整体展开:
∂
∂
v
c
log
∑
w
∈
V
exp
(
u
w
T
v
c
)
=
1
∑
w
∈
V
exp
(
u
w
T
v
c
)
∗
∂
∂
v
c
(
∑
x
∈
V
exp
(
u
x
T
v
c
)
)
=
1
∑
w
∈
V
exp
(
u
w
T
v
c
)
∗
∑
x
∈
V
∂
∂
v
c
(
exp
(
u
x
T
v
c
)
)
=
1
∑
w
∈
V
exp
(
u
w
T
v
c
)
∗
∑
x
∈
V
exp
(
u
x
T
v
c
)
∂
∂
v
c
(
u
x
T
v
c
)
=
∑
x
∈
V
exp
(
u
x
T
v
c
)
u
x
∑
w
∈
V
exp
(
u
w
T
v
c
)
=
∑
x
∈
V
P
(
x
∣
c
)
u
x
frac{partial}{partial v_{c}} log sum_{w in V} exp left(u_{w}^{T} v_{c}right) = frac{1}{sum_{w in V} exp left(u_{w}^{T} v_{c}right)} * frac{partial}{partial v_{c}} ( sum_{x in V} exp left(u_{x}^{T} v_{c}right)) \ = frac{1}{sum_{w in V} exp left(u_{w}^{T} v_{c}right)} * sum_{x in V} frac{partial}{partial v_{c}} ( exp left(u_{x}^{T} v_{c}right) ) \ = frac{1}{sum_{w in V} exp left(u_{w}^{T} v_{c}right)} * sum_{x in V} exp left(u_{x}^{T} v_{c}right) frac{partial}{partial v_{c}} ( u_{x}^{T} v_{c} ) \ = frac{sum_{x in V} exp left(u_{x}^{T} v_{c}right) u_{x}}{sum_{w in V} exp left(u_{w}^{T} v_{c}right)} \ = sum_{x in V} P(x | c) u_{x}
∂vc∂logw∈V∑exp(uwTvc)=∑w∈Vexp(uwTvc)1∗∂vc∂(x∈V∑exp(uxTvc))=∑w∈Vexp(uwTvc)1∗x∈V∑∂vc∂(exp(uxTvc))=∑w∈Vexp(uwTvc)1∗x∈V∑exp(uxTvc)∂vc∂(uxTvc)=∑w∈Vexp(uwTvc)∑x∈Vexp(uxTvc)ux=x∈V∑P(x∣c)ux
最终:
∂
∂
v
c
log
P
(
o
∣
c
)
=
u
o
−
∑
x
∈
V
P
(
x
∣
c
)
u
x
frac{partial}{partial v_{c}} log P(o | c) = u_o - sum_{x in V} P(x | c) u_{x}
∂vc∂logP(o∣c)=uo−x∈V∑P(x∣c)ux
理解为在中心词c的情况下,预测的上下文单词和实际上下文单词向量(
u
o
u_o
uo)的差异,
reference
- http://web.stanford.edu/class/cs224n/
- https://www.bilibili.com/video/av46216519?t=4557
最后
以上就是发嗲冰棍最近收集整理的关于斯坦福CS224n课程笔记1-introduction and Word vectors 2019Human language and word meaningWord2vec introductionreference的全部内容,更多相关斯坦福CS224n课程笔记1-introduction内容请搜索靠谱客的其他文章。








发表评论 取消回复