学习总结
(1)明确课程时间安排和task概况。
(2)简单复习:word2vec通过滑动窗口截取词构成样本,输入向量矩阵的行向量即所需的单词embedding;另外为了优化训练,还有负采样和SGD等方法。另外manning老爷子木有讲分层 softmax(Hierarchical Softmax),这个后续跟进。
文章目录
- 学习总结
- 一、课程安排
- 二、Word2vec算法
- 2.1 引子
- 2.2 滑动窗口
- 2.3 目标函数
- 2.4 预测函数
- 三、训练
- 3.1 激活函数
- 3.2 梯度下降
- 3.3 负采样
- 四、代码实现
- Reference
一、课程安排
CS224n 课程介绍:

课程主页
课程资料
课程国内观看链接
课程油管观看地址
答疑平台
总时长:12周
(1)week1-4: 词向量,分类,神经网络,分词
(2)week5-8: RNN和语言模型,梯度消失和seq2seq,机器翻译、注意力和子词模型
(3)week9-12: Transformers,预训练模型,自然语言生成(可选),基于知识的语言模型(可选)
要求:
(1)观看视频,笔记输出,要有自己的思考;
(2)完成课后的quiz(不多,共8个,大概10道选择题);
(3)一起组队做一个项目(自选一个NLP任务);
ddl打卡安排如下:
| Week | Due | Lecture | Quiz | Projects |
|---|---|---|---|---|
| 1 | Sun 11/21 24:00 | P11 - Introduction and Word Vectors 1:24:28 | 1-2周后选题 | |
| 2 | Sun 11/28 24:00 | P22 - Neural Classifiers 1:15:19 | ||
| 3 | Sun 12/05 24:00 | P33 - Backprop and Neural Networks 1:22:29 | Quiz 1 | |
| 4 | Sun 12/12 24:00 | P44 - Dependency Parsing 1:21:22 | ||
| 5 | Sun 12/19 24:00 | P55 - Language Models and RNNs 1:19:18 P66 - Simple and LSTM RNNs 1:21:38 | Quiz 2 | |
| 6 | Sun 12/26 24:00 | P77 - Translation, Seq2Seq, Attention 1:18:55 | Quiz 3 | |
| 7 | Sun 01/02 24:00 | P99 - Self- Attention and Transformers 1:16:57 P1010 - Transformers and Pretraining 1:21:46 (可选) P20 BERT and Other Pre-trained Language Models 54:29 (可选) | Quiz 4 | |
| 8 | Sun 01/09 24:00 | P1111 - Question Answering 1:51:53 (二选一) P1212 - Natural Language Generation1:17:27 (二选一) | Quiz 5 Quiz 6 | |
| 9 | Sun 01/16 24:00 | P1414 - T5 and Large Language Models 1:35:14 | ||
| 10 | Sun 01/23 24:00 | P1515 - Add Knowledge to Language Models 1:17:26 | Quiz 7 | |
| 11 | Sun 01/30 24:00 | P1818 - Future of NLP + Deep Learning 1:20:06 | Quiz 8 | |
| 12 | Sun 02/05 24:00 |
作业简要介绍:

课程项目:
- N-Gram Language Models (Lectures 1-4) (语音识别)
- Word Alignment Models for Machine Translation (Lectures 5-9)(机器翻译)
- Maximum Entropy Markov Models & Treebank Parsing (Lectures 10-3)(命名实体识别和句法分析)
二、Word2vec算法
2.1 引子
理解单词意思的最常见的语言方式:语言符号与语言符号的意义的转化。

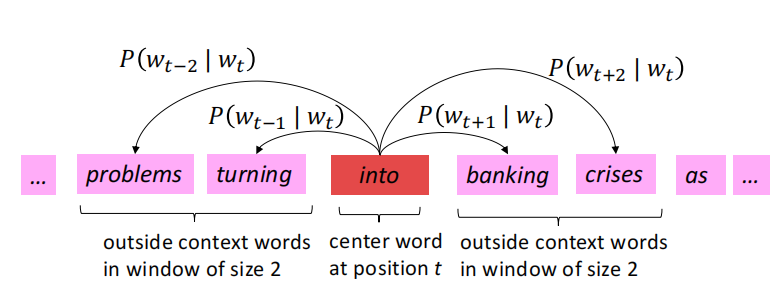
2.2 滑动窗口
为了得到每个单词的高质量稠密embedding(相似上下文的单词的vector应该相似),word2vec是通过一个滑动窗口的滑动,同时计算
P
(
w
t
+
j
∣
w
t
)
Pleft(w_{t+j} mid w_{t}right)
P(wt+j∣wt)。下面就是一个栗子,window_size=2。
2.3 目标函数
(1)一开始我们将刚才得到的一坨
P
(
w
t
+
j
∣
w
t
)
Pleft(w_{t+j} mid w_{t}right)
P(wt+j∣wt)相乘,并且是对于每个t,所以有2个累乘:

(2)因为一般我们是最小化目标函数,所以进行了取log和负平均的操作,修改后的目标函数:
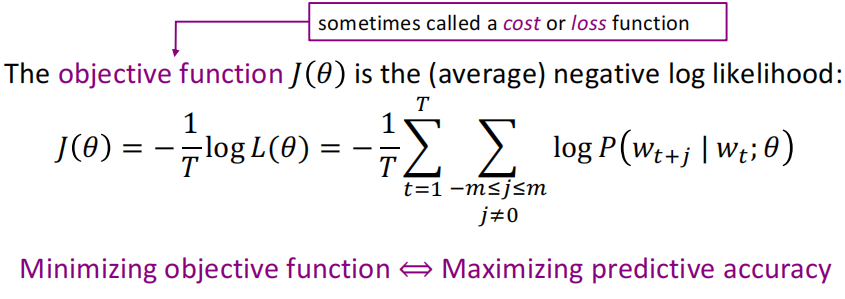
为了求出上面损失函数最里面的概率
P
(
w
t
+
j
∣
w
t
;
θ
)
Pleft(w_{t+j} mid w_{t} ; thetaright)
P(wt+j∣wt;θ),对于每个单词都用2个vector表示:
- 当w是中心词时,表示为 v w v_w vw
- 当w是上下文词时,表示为 u w u_w uw
但是为啥要用两个vector表示每个单词呢,manning给出的解释是:更容易optimization。
2.4 预测函数
所以对于一个中心词c和一个上下文次c有:
P
(
o
∣
c
)
=
exp
(
u
o
T
v
c
)
∑
w
∈
V
exp
(
u
w
T
v
c
)
P(o mid c)=frac{exp left(u_{o}^{T} v_{c}right)}{sum_{w in V} exp left(u_{w}^{T} v_{c}right)}
P(o∣c)=∑w∈Vexp(uwTvc)exp(uoTvc)将任意值
x
i
x_i
xi映射到概率分布中,即如下:
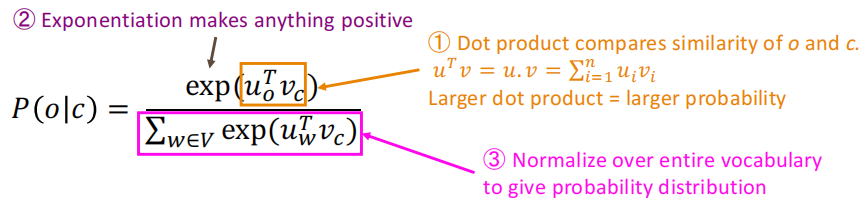
分子的点积用来表示o和c之间相似程度,分母这坨东西就是基于整个词表,给出归一化后的概率分布。
三、训练
3.1 激活函数
用softmax函数,使大的更大,小的更小:
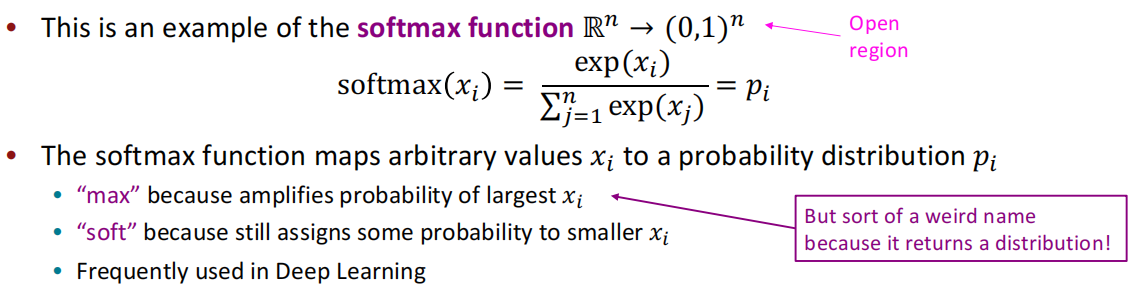
3.2 梯度下降
又是熟悉的通过minimize loss来优化更新参数,注意一开始说了每个单词都有2个vector表示,其中vector是d维度的,一共有V个单词,我们想要得到的模型参数:
θ
=
[
v
a
a
r
d
v
a
r
k
v
a
⋮
v
z
e
b
r
a
u
a
a
r
d
v
a
r
k
u
a
⋮
u
z
e
b
r
a
]
∈
R
2
d
V
theta=left[begin{array}{l} v_{a a r d v a r k} \ v_{a} \ vdots \ v_{z e b r a} \ u_{a a r d v a r k} \ u_{a} \ vdots \ u_{z e b r a} end{array}right] in mathbb{R}^{2 d V}
θ=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡vaardvarkva⋮vzebrauaardvarkua⋮uzebra⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤∈R2dV
梯度下降就是通过链式求导法则,这里我们对里面那项概率求导:
log
p
(
o
∣
c
)
=
log
exp
(
u
o
T
v
c
)
∑
w
=
1
V
exp
(
u
w
T
v
c
)
log p(o mid c)=log frac{exp left(u_{o}^{T} v_{c}right)}{sum_{w=1}^{V} exp left(u_{w}^{T} v_{c}right)}
logp(o∣c)=log∑w=1Vexp(uwTvc)exp(uoTvc)
在每个窗口中,我们通过梯度下降求出当前窗口的所有参数,我们上面是用的CBOW,即根据上下文预测中心词。
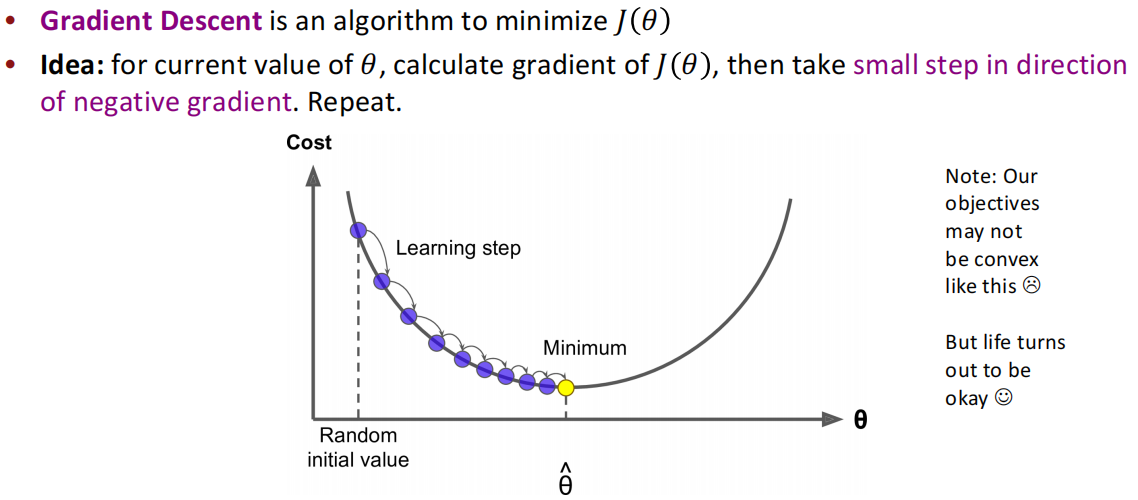
并且在更新参数时,是要设定超参数——学习率:

上面的梯度下降实际上需要对语料库(corpus)的所有窗口都计算后才更新参数。所以为了训练更高效,可以使用SGD,SGD是对一个窗口进行更新参数,并且重复采样窗口。
while True:
window = sample_window(corpus)
theta_grad = evaluate_gradient(J, window, theta)
theta = theta - alpha * theta_grad
3.3 负采样
CBOW或者skip-gram这类模型的训练,在当词表规模较大且计算资源有限时,这类多分类模型会因为输出层概率的归一化计算效率的影响,训练龟速。
所以负采样提供了另一个角度:给定当前词与上下文,任务是最大化两者的共现概率。
也即将多分类问题简化为:针对(w, c)的二分类问题(即共现or不共现),从而避免了大词表上的归一化复杂计算量。
如 P ( D = 1 ∣ w , c ) P(D=1 mid w, c) P(D=1∣w,c)表示c和w共现的概率 P ( D = 1 ∣ w , c ) = σ ( v w ⋅ v c ′ ) P(D=1 mid w, c)=sigmaleft(v_{w} cdot v_{c}^{prime}right) P(D=1∣w,c)=σ(vw⋅vc′)
四、代码实现
这里的数据集我们用了nltk库的reuters数据集:
reuters = LazyCorpusLoader(
"reuters",
CategorizedPlaintextCorpusReader,
"(training|test).*",
cat_file="cats.txt",
encoding="ISO-8859-2",
)

这里我们的损失函数选用nn.NLLLoss(),可以回顾上次学习pytorch图片多分类时的图:
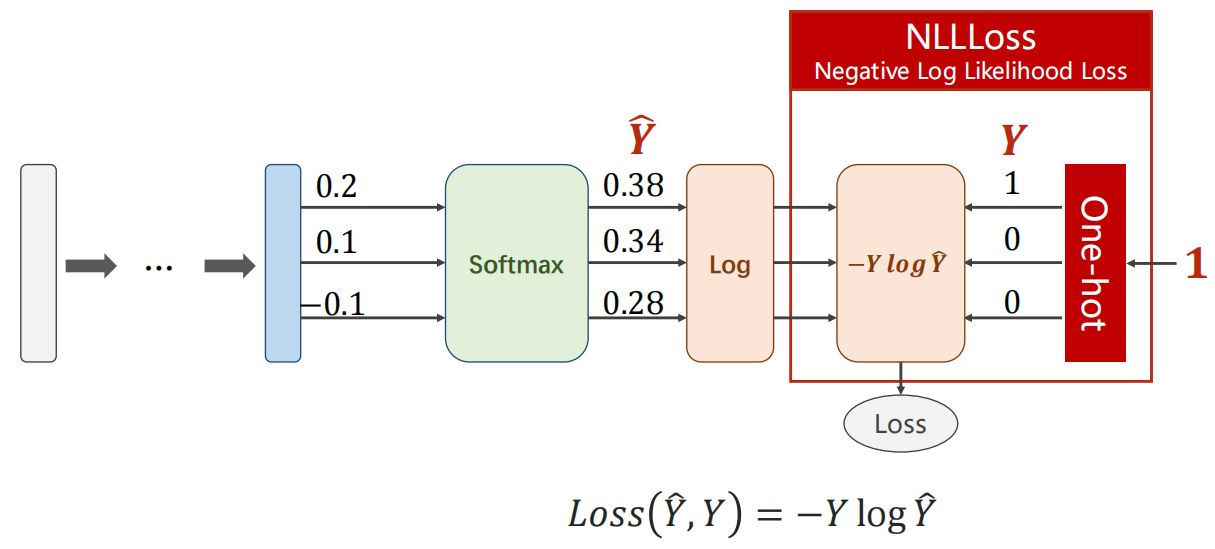
我们之前经常使用的torch.nn.CrossEntropyLoss如下(将下列红框计算纳入)。注意右侧是由类别生成独热编码向量。
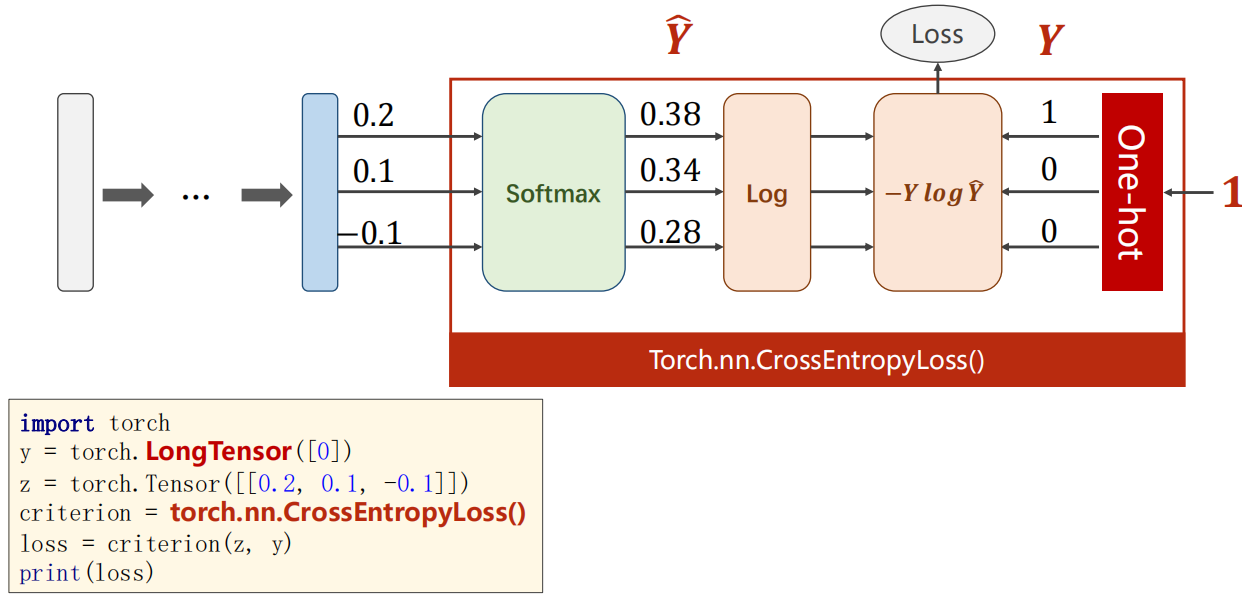
具体细节见代码注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset
from torch.nn.utils.rnn import pad_sequence
from tqdm.auto import tqdm
from utils import BOS_TOKEN, EOS_TOKEN, PAD_TOKEN
from utils import load_reuters, save_pretrained, get_loader, init_weights
# 构建数据集类
class CbowDataset(Dataset):
def __init__(self, corpus, vocab, context_size=2):
self.data = []
self.bos = vocab[BOS_TOKEN]
self.eos = vocab[EOS_TOKEN]
for sentence in tqdm(corpus, desc="Dataset Construction"):
sentence = [self.bos] + sentence+ [self.eos]
# 如句子长度不足以构建(上下文、目标词)训练样本,则跳过
if len(sentence) < context_size * 2 + 1:
continue
for i in range(context_size, len(sentence) - context_size):
# 模型输入:左右分别取context_size长度的上下文
context = sentence[i-context_size:i] + sentence[i+1:i+context_size+1]
# 模型输出:当前词
target = sentence[i]
self.data.append((context, target))
def __len__(self):
return len(self.data)
def __getitem__(self, i):
return self.data[i]
def collate_fn(self, examples):
inputs = torch.tensor([ex[0] for ex in examples])
targets = torch.tensor([ex[1] for ex in examples])
return (inputs, targets)
# CBOW模型部分
class CbowModel(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super(CbowModel, self).__init__()
# 词嵌入层
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
# 线性变换:隐含层->输出层
self.output = nn.Linear(embedding_dim, vocab_size)
init_weights(self)
def forward(self, inputs):
embeds = self.embeddings(inputs)
# 计算隐含层:对上下文词向量求平均,得到Wt的上下文表示
hidden = embeds.mean(dim=1)
# 线性变换层
output = self.output(hidden)
log_probs = F.log_softmax(output, dim=1)
return log_probs
# 参数设定
embedding_dim = 64
context_size = 2
hidden_dim = 128
batch_size = 1024
num_epoch = 10
# 读取文本数据,构建CBOW模型训练数据集
corpus, vocab = load_reuters()
dataset = CbowDataset(corpus, vocab, context_size=context_size)
data_loader = get_loader(dataset, batch_size)
nll_loss = nn.NLLLoss()
# 构建CBOW模型,并加载至device
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = CbowModel(len(vocab), embedding_dim)
model.to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 模型训练
model.train()
for epoch in range(num_epoch):
total_loss = 0
for batch in tqdm(data_loader, desc=f"Training Epoch {epoch}"):
# 1.准备数据
inputs, targets = [x.to(device) for x in batch]
# 梯度清零
optimizer.zero_grad()
# 向前传递
log_probs = model(inputs)
# 损失函数
loss = nll_loss(log_probs, targets)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
total_loss += loss.item()
print(f"Loss: {total_loss:.2f}")
# 保存词向量(model.embeddings)
save_pretrained(vocab, model.embeddings.weight.data, "cbow.vec")
Reference
(1)课程ppt:https://web.stanford.edu/class/cs224n/slides/
(2)Speech and Language Processing :https://web.stanford.edu/~jurafsky/slp3/
(3)课程官网:https://see.stanford.edu/Course/CS224N#course-details
(4)https://datawhale.feishu.cn/docs/doccncx2cwCD9jtZCp6kKhlKdee#
(5)pytorch损失函数之nn.CrossEntropyLoss()、nn.NLLLoss()
最后
以上就是重要夕阳最近收集整理的关于【CS224n】(lecture1)课程介绍和word2vec学习总结一、课程安排二、Word2vec算法三、训练四、代码实现Reference的全部内容,更多相关【CS224n】(lecture1)课程介绍和word2vec学习总结一、课程安排二、Word2vec算法三、训练四、代码实现Reference内容请搜索靠谱客的其他文章。








发表评论 取消回复